
تبدیل متن به گفتار با Tacotron-2 و FastSpeech با استفاده از ESPnet
تیم تحریریه
- ۴ مرداد ۱۴۰۰
همانطور که از نامش پیداست، تبدیل متن به گفتار Text to speech (TTS)، با صدای بلند به خوانش متن میپردازد. سامانه متن به گفتار، متن را به عنوان ورودی دریافت و به صوت تبدیل مینماید. افرادی که حوصله خواندن کتاب، وبلاگ یا مقاله را ندارند، میتوانند از سامانه «تبدیل متن به گفتار» استفاده کنند. با فرض اینکه هیچ اطلاعاتی درباره سامانه تبدیل متن به گفتار نداریم، مقاله حاضر به بررسی راهکارهای ساخت موتور تبدیل متن به گفتار خواهد پرداخت.
معماری تبدیل متن به گفتار

نمودار فوق، معماری مد نظر ما را به شکل ساده نشان میدهد. هر کدام از مولفهها به طور جامع مورد بررسی قرار گرفته و از چارچوب ESPnet به منظور پیادهسازیها استفاده خواهد شد.
Front-end

این معماری سه مولفه دارد:
- برچسبزننده POS Part-of-speech Tagger: این بخش، برچسبزنی جزء کلام متن ورودی را انجام میدهد.
- توکنکردن: جمله به قطعات کوچکتر واژگان شکسته میشود.
- تلفظ: این بخش متن ورودی را بر اساس تلفظ به واجها تقسیم میکند؛ به این مثال توجه کنید:
- Hello, how are you → HH AH0 L OW, HH AW1 AA1 R Y UW1
- این کار با ابزاری موسوم به «مبدل نویسه به واج Grapheme-to-Phoneme » انجام میشود. ما در این مورد از یک مدل عصبی از پیش آموزش دیده استفاده میکنیم که (G2P(Grapheme to Phoneme نام دارد. این مدل با هدف تبدیل نویسهها (املای کلمات) به واج (تلفظ) طراحی گردیده است. برای اینکه سازوکار این مدل G2P را بدانید، اشاره به این نکته ضروری است که این مدل نقش مشاور را برای فرهنگ واژگان ایفا میکند. اگر واژهای در فرهنگ واژگان ذخیره نشده باشد، این مدل با تکیه بر تنسور فلو و استفاده از مدل «seq2seq» واجها را پیشبینی میکند.
رگرسور «seq2seq»

ما از رگرسور از پیش آموزش دیده «seq-to-seq» استفاده کردهایم؛ بر این اساس، ویژگیهای زبانشناسی (واجها) به عنوان ورودی به کار گرفته شده و در قالب ویژگیهای آکوستیک ( طیفنگاره Mel Mel Spectrogram) به خروجی تبدیل میشوند. در این بخش کماکان از Tacotron-2 (محصول شرکت گوگل) و Fastspeech (محصول شرکت فیسبوک) استفاده خواهیم کرد. اکنون، هر دو مورد را بررسی میکنیم:
Tacotron-2
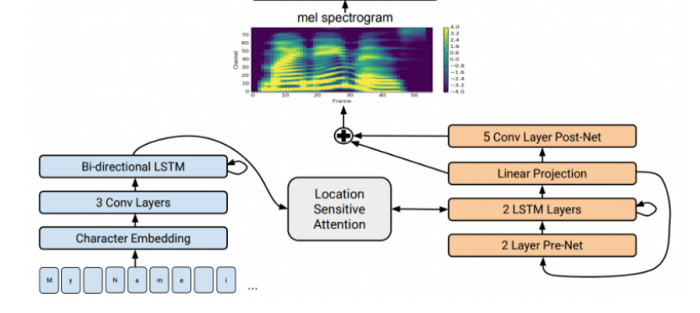
Tacotron یک سیستم سنتز گفتار متکی بر هوش مصنوعی است که میتواند متن را به گفتار تبدیل کند. معماری شبکه عصبی Tacotron-2 میتواند گفتار را به طور مستقیم از متن تولید کند. این سیستم بر اساس ترکیب شبکه عصبی پیچشی Convolutional neural network (CNN) و شبکه عصبی بازگشتی Recurrent neural network (RNN) عمل میکند.
FastSpeech

معماری کلی FastSpeech:
(a) ترنسفورمر پیشخور Feed-Forward Transformer
(b) بلوک FFT
(c) تنظیم کننده طول
(d) پیشبینیگر مدت زمان
خطای MSE به اختلاف میان مدت زمان پیشبینی شده و اجرا شده اشاره میکند که فقط در فرایند آموزش وجود دارد.
[irp posts=”17663″](a، b) ترنسفورمر پیشخور:
FastSpeech از ساختار ترانسفورمر پیشخور نوینی بهره میبرد. همانطور که در شکل فوق ملاحظه میکنید، چارچوب مرسوم «رمزگذار-توجه-رمزگشا» جایگاه خود را در این ساختار از دست میدهد. بلوک ترنسفورمر پیشخور (FFT) به عنوان مولفه اصلی این ترنسفورمر برشمرده میشود. بلوک FFT از کانولوشن یکبعدی و خودتوجهی self-attention تشکیل یافته است. بلوکهای FFT در تبدیل دنباله واجها به دنباله mel-spectrogram مورد استفاده قرار میگیرند؛ همچنین تنظیمگر طولی میان آنها وجود دارد که عدم تناسب طول میان واجها و دنبالههای طیفنگار Mel را برطرف میسازد.
(c) تنظیمگر طول:
تنظیمگر طول مدل در شکل فوق نشان داده شده است. چون طول دنباله واجها کوچکتر از طول دنباله mel-spectrogram است، یک آوا با چند mel-spectrogram نشان داده میشود. تعداد mel-spectrogram هایی که با واج همتراز میشوند، «مدت زمان واج» نامیده میشود. ابزار تنظیمگر طول دنباله پنهان واجها را بر اساس مدت زمان بسط میدهد تا با طول دنباله mel-spectrogram مطابقت داشته باشد. میتوان مدت زمان واج را افزایش یا کاهش داد تا سرعت صوت تنظیم شود. همچنین، امکان تغییر مدت زمان توکنهای خالی برای تنظیم توقف میان واژگان نیز وجود دارد. بنابراین، بخش نوای گفتار نیز کنترل میگردد.
(d) تخمینگر مدت زمان:
ابزار پیشبینی مدتزمان Duration predictor اهمیت بسیار بالایی برای تنظیمگر طول به منظور تخمین مدت زمان هر واج دارد. بر طبق تصویر فوق، تخمینگر مدت زمان از پیچش تکبعدی دولایه و یک لایه خطی برای پیشبینی مدت زمان تشکیل یافته است. این تخمینگر در بلوک FFT در بخش واج قرار دارد و به طور مشترک با FastSpeech و با استفاده از تابع خطای میانگین مربعات آموزش میبیند. برچسب مدت زمان واج از تنظیم attention میان رمزگذار و رمزگشا در مدل آموزش اتورگرسور Autoregressive teacher model استخراج میشود.
Vocoder / مولد شکل موج

ما از مدل از پیش از آموزش دیده «seq-to-seq» استفاده خواهیم کرد؛ در این مدل، از ویژگیهای آکوستیک (Mel-spectogram) به عنوان ورودی استفاده میشود و شکل موج (صوت) به عنوان خروجی تولید میشود. در این بخش، از WaveGAN vocoder موازی استفاده خواهیم کرد. همچنین، از معماری شبکه مولد تخاصمی Generative adversarial network (GAN) برای ایجاد شکل موج از mel-spectrogram استفاده میشود. اطلاعات بیشتر در رابطه با این معماری در لینک زیر قرار داده شده است.
https://arxiv.org/pdf/1910.11480.pdf
پیادهسازی
معماری فوق با استفاده از چارچوب ESPnet به اجرا در آمده است. این چارچوب میتواند ساختار فوقالعادهای برای اجرای آسان همه مدلهای از پیش آموزش دیده فوق ارائه نماید و آنها را در قالبی یکپارچه تحویل دهد. دستورالعمل کامل اجرای سیستم «متن به گفتار» در لینک زیر قابل دسترس است.
https://colab.research.google.com/gist/sayakmisra/2bf6e72fb9eed2f8cfb2fb47143726b6/-e2e-tts.ipynb
نتیجهگیری
ما سیستم عصبی تبدیل گفتار به متن را با استفاده از چند مدل از پیش آموزش دیده Tacotrin-2، Fastspeech، Parallel WaveGAN و غیره پیادهسازی کردهایم. میتوان مدلهای دیگری را نیز امتحان کرد؛ زیرا ممکن است نتایج بهتری به دست آورند.






