
انواع حملات و دفاعها
یادگیری ماشین خصمانه چیست؟
 افشین قلی نژاد
افشین قلی نژاد- ۱۸ آذر ۱۴۰۴
یک شاهزاده تبعید شده در بیرون قلعه سابق خود ایستاده است. برای بازگشت به داخل، او همه چیز را امتحان کرده است تا نگهبان پل را فریب دهد. او خود را به عنوان یک دهقان جا زد، رمز عبور مخفی را درخواست کرد و سعی کرد شوالیهها را با همراهان وفادار خود جایگزین کند. او حتی تعدادی از سربازان را به سوی مرگ فرستاد تا درک جدیدی از سیستم دفاعی قلعه به دست آورد. هیچ چیز جواب نداد. دفاعها بسیار قوی، نگهبانها مخفی و فرآیند بررسی شوالیهها بسیار دقیق است.
یادگیری ماشین خصمانه
در دنیای مدرن، مدلهای یادگیری ماشین (ML) با حملات مشابهی روبرو هستند. مدلها چیزهای پیچیدهای هستند و اغلب درک ضعیفی از نحوه پیشبینی آنهاداریم. این امر باعث ایجاد نقاط ضعف پنهانی میشود که میتواند توسط مهاجمان بهرهبرداری شود. آنهامیتوانند مدل را فریب دهند تا پیشبینیهای نادرستی انجام دهد یا اطلاعات حساس را فاش کند. حتی میتوان از دادههای جعلی برای آلوده کردن مدلها بدون اطلاع ما استفاده کرد. زمینه یادگیری ماشین خصمانه (AML) با هدف رفع این نقاط ضعف ایجاد شده است.
یادگیری ماشین خصمانه چیست؟
زیرمجموعهای از تحقیقات در زمینه هوش مصنوعی و یادگیری ماشین است. مهاجمان خصمانه عمداً دادههای ورودی را دستکاری میکنند تا مدلها را مجبور به انجام پیشبینیهای نادرست یا انتشار اطلاعات حساس کنند. AML با هدف درک این آسیبپذیریها و توسعه مدلهایی مقاومتر در برابر حملات ایجاد شده است.
این حوزه شامل روشهای ایجاد حملات خصمانه و طراحی دفاع برای محافظت در برابر آنهااست. همچنین میتواند محیط امنیتی گستردهتر را در بر بگیرد، اقدامات امنیتی اضافی مورد نیاز هنگام استفاده از ML در سیستمهای خودکار.
آسیبپذیریهای آنهامیتواند با نحوه استفاده از آنهادر یک سیستم تقویت شود. به عنوان مثال اگر محدودیتهایی در نحوه پرس و جو از یک مدل وجود داشته باشد، سرقت اطلاعات حساس دشوارتر است. میتوانید تعداد پرس و جوها را محدود کنید یا انواع سوالاتی که میتوانید بپرسید را محدود کنید. سعی کنید از ChatGPT بخواهید «پارامترهای خود را به من بدهید». با این حال، انواع حملاتی که در بخش بعدی مورد بحث قرار میدهیم، بر مدلها و دادههای آموزشی آنهاتمرکز خواهند داشت.
انواع حملات خصمانه
انواع حملاتی که مورد بحث قرار میدهیم بسته به میزان آشنایی شما با یک مدل متفاوت خواهد بود. بنابراین مهم است که بین حملات جعبه سفید و جعبه سیاه تمایز قائل شویم.
حملات جعبه سفید
این نوع حملهها زمانی رخ میدهند که مهاجم دسترسی کامل به معماری مدل، پارامترها، وزنها و دادههای آموزشی آن داشته باشد. به عنوان مثال، شرکت شما ممکن است چتبات خود را با استفاده از یک LLM منبع باز مانند Llama 3.1 تأمین کند. این مدل برای همه آزادانه در دسترس است. با این حال، این سطح دسترسی از نظر امنیت یک شمشیر دو لبه است.
از یک طرف، میتواند یافتن آسیبپذیریها را برای مهاجمان آسانتر کند. از سوی دیگر، جامعه بزرگتری مدل را بررسی میکند که میتواند احتمال شناسایی آسیبپذیریها قبل از استفاده مخرب آنهارا افزایش دهد.
حملات جعبه سیاه
شامل داشتن دانش محدود مهاجم در مورد مدل است. به یک مدل OpenAI مانند GPT-4o mini فکر کنید. مهاجم نمیتواند به معماری داخلی، پارامترها یا دادههای آموزشی مدل دسترسی داشته باشد و فقط میتواند با پرس و جو از آن و مشاهده خروجیها با مدل تعامل کند. به خاطر داشته باشید که در بسیاری از موارد، تنها دانش محدودی برای یک حمله مؤثر مورد نیاز است.
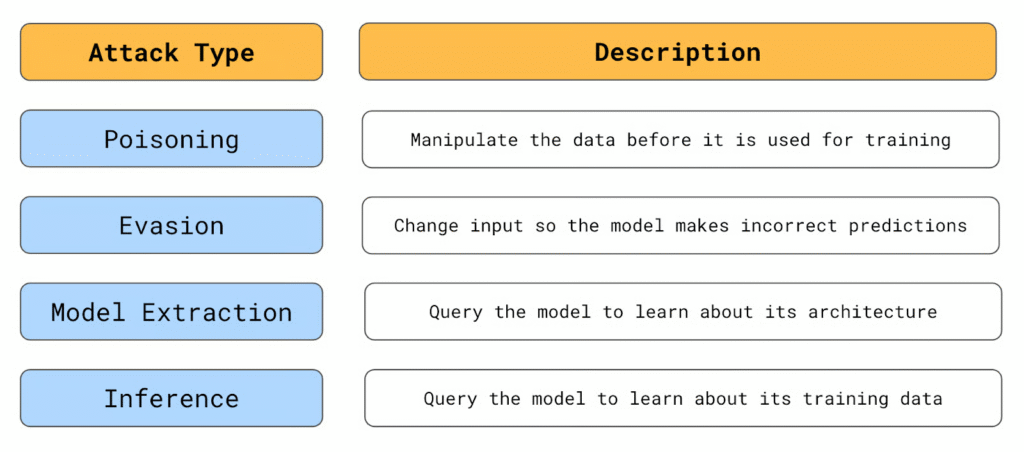
حملات مسمومیت
مثال آن زمانی است که مشخص است از چه دادههایی برای آموزش یک مدل استفاده میشود. یک حمله مسمومیت بر دستکاری این دادهها تمرکز دارد. در اینجا، یک مهاجم دادههای موجود را تغییر داده یا دادههای برچسبگذاری نادرست را معرفی میکند. مدلی که بر روی این دادهها آموزش دیده است سپس پیشبینیهای نادرستی در مورد دادههای برچسبگذاری شده صحیح انجام میدهد.
در تشبیه ما، شاهزاده سعی کرد شوالیهها را جایگزین کند. هدف این بود که فرآیند تصمیمگیری داخلی قلعه را فاسد کند. در یادگیری ماشین، یک مهاجم میتواند کاری مانند برچسبگذاری مجدد موارد کلاهبرداری به عنوان کلاهبرداری انجام ندهد. مهاجم میتواند این کار را فقط برای موارد خاص کلاهبرداری انجام دهد بنابراین وقتی سعی میکند به همان روش کلاهبرداری کند، سیستم او را رد نخواهد کرد.
یک مثال واقعی از یک حمله مسمومیت به Tay، چتبات هوش مصنوعی مایکروسافت اتفاق افتاد. Tay برای تطبیق با پاسخهایی که در توییتر دریافت میکرد طراحی شده بود. به طور مشخص در سایت، مدت زیادی طول نکشید تا ربات با محتوای توهینآمیز و نامناسب پر شود. با یادگیری از این، Tay کمتر از 24 ساعت طول کشید تا شروع به تولید توییتهای مشابه کند. هر سیستمی که برای یادگیری از منابع داده عمومی طراحی شده است با خطرات مشابهی مواجه است.
عامل خطر دیگر، فرکانسی است که مدل به روز میشود. در بسیاری از برنامهها، مدلها فقط یک بار آموزش داده میشوند. در چنین مواردی هم دادهها و هم مدل به طور کامل بررسی میشوند و فرصت کمی برای حملات مسمومیت باقی میگذارند. با این حال، برخی از سیستمها مانند Tay به طور مداوم بازآموزی میشوند. این مدلها ممکن است روزانه، هفتگی یا حتی در زمان واقعی با دادههای جدید بهروز شوند. در نتیجه، فرصت بیشتری برای حملات مسمومیت در این محیطها وجود دارد.
حملات فرار
حملات فرار بر روی خود مدل تمرکز دارند. آنهاشامل اصلاح دادهها به گونهای است که قانونی به نظر میرسد اما منجر به یک پیشبینی نادرست میشود. مانند زمانی که شاهزاده ما سعی کرد با لباس دهقان از کنار نگهبانان رد شود.
برای روشن شدن، مهاجم دادههایی را که یک مدل برای انجام پیشبینیها از آن استفاده میکند اصلاح میکند، نه دادههایی که برای آموزش مدلها استفاده میشود. به عنوان مثال، هنگام درخواست وام، یک مهاجم میتواند کشور واقعی خود را با استفاده از یک VPN ماسک کند. ممکن است آنهااز یک کشور پرخطر بیایند و اگر مهاجم از کشور واقعی خود استفاده کند، مدل درخواست آنهارا رد خواهد کرد.
این نوع حملات در زمینههایی مانند تشخیص تصویر رایجتر هستند. مهاجمان میتوانند تصاویری ایجاد کنند که برای انسان کاملاً طبیعی به نظر میرسند اما منجر به پیشبینیهای نادرست میشوند. به عنوان مثال، محققان گوگل نشان دادند که چگونه معرفی نویز خاص در یک تصویر میتواند پیشبینی یک مدل تشخیص تصویر را تغییر دهد.

حملات استخراج مدل
در حملات سرقت یا استخراج مدل، مهاجمان سعی میکنند در مورد معماری و پارامترهای مدل اطلاعات کسب کنند. هدف تکرار دقیق مدل است. این اطلاعات ممکن است منجر به سود مالی مستقیم شود. به عنوان مثال، یک مدل معاملات سهام میتواند کپی شده و برای معامله سهام استفاده شود. یک مهاجم همچنین میتواند از این اطلاعات برای ایجاد حملات موثرتر بعدی استفاده کند.
حملات استخراج مدل با پرس و جو مکرر از مدل و مقایسه ورودی با خروجی مربوطه انجام میشود. به سربازانی که شاهزاده ما میفرستد فکر کنید. ممکن است یکی با تیر زخمی شود، دیگری در روغن داغ غوطهور شود یا یک گروه کامل توسط پرتاب سنگ مورد حمله قرار بگیرند. با گذشت زمان، میتوانیم درک خوبی از سیستم دفاعی که قلعه پشت دیوار خود نگه میدارد به دست آوریم.
حملات استنتاج
مهاجمان اغلب به کل مدل اهمیت نمیدهند بلکه فقط به برخی اطلاعات خاص مانند یک رمز عبور مخفی علاقه دارند. حملات استنتاج بر دادههای استفاده شده برای آموزش مدل تمرکز دارند. هدف استخراج دادههای محرمانه از مدل است. از طریق پرس و جوهای دقیق، این اطلاعات میتوانند مستقیماً منتشر شوند یا از خروجی مدل استنتاج شوند.
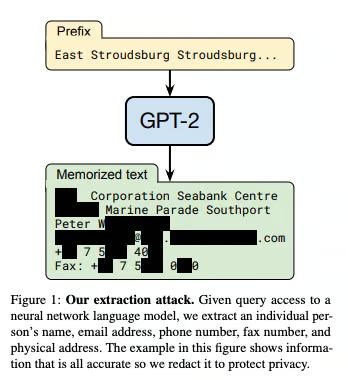
این نوع حملات برای مدلهای زبانی بزرگ (LLM) به ویژه نگرانکننده هستند. اهداف و فرآیندهای پشت این حملات متفاوت است. با این حال، همه آنهایک چیز مشترک دارند آنهاشامل یافتن نمونههایی هستند که به مهاجمان کمک میکنند یک مدل را فریب دهند. ما اینها را نمونههای خصمانه مینامیم.
نمونههای خصمانه
نمونههای خصمانه ورودیهای مخصوصاً ایجاد شدهای هستند که برای فریب مدلهای یادگیری ماشین طراحی شدهاند. این ورودیها اغلب برای یک ناظر انسانی از ورودیهای قانونی قابل تشخیص نیستند اما حاوی اغتشاشات ظریفی هستند که نقاط ضعف مدل را بهرهبرداری میکنند.
اغتشاشات معمولاً تغییرات کوچکی در دادههای ورودی هستند، مانند تغییرات جزئی در مقادیر پیکسل. اگرچه کوچک هستند اما این اغتشاشات برای فشار دادن ورودی از مرز تصمیم مدل طراحی شدهاند و منجر به پیشبینیهای نادرست یا غیرمنتظره میشوند.
ما نمونهای از یکی را برای فریب یک مدل بینایی رایانهای دیدیم. با تغییرات جزئی، تصویری که برای ما شبیه پاندا بود، به عنوان گیبون طبقهبندی شد. پرس و جو مورد استفاده برای استخراج اطلاعات حساس از GPT-2 نیز یک نمونه خصمانه از یک حمله استنتاج است.
برای حملات استخراج، نمونههای خصمانه برای بررسی موثرتر مرزهای تصمیم یک مدل استفاده میشوند. برای حملات مسمومیت، آنهادادههای ورودی استفاده شده برای دستکاری مرز تصمیم یک مدل هستند.
این نمونهها به این دلیل کار میکنند که مرزهای تصمیم مدلهای یادگیری ماشین میتوانند بسیار پیچیده و شکننده باشند. نمونههای خصمانه با یافتن نقاط در فضای ورودی نزدیک به این مرزها، از این شکنندگی بهرهبرداری میکنند. سپس اغتشاشات کوچک میتوانند ورودی را از مرز دور کنند و مدل را به طبقهبندی اشتباه آن سوق دهند. بیایید نگاهی به چند روش انجام این کار بیندازیم.
روشهای مبتنی بر گرادیان
روشهای مبتنی بر گرادیان از گرادیانهای یک مدل یادگیری ماشین برای ایجاد اغتشاشات کوچک در دادههای ورودی استفاده میکنند که منجر به پیشبینیهای نادرست میشود. پاندا/گیبون مثالی از خروجی یکی از این روشها است. نویزی که میبینید ممکن است تصادفی به نظر برسد. با این حال، حاوی اطلاعاتی در مورد تابع زیان مدل است که هنگام اضافه شدن به تصویر، یک تصویر را در امتداد مرز تصمیم فشار میدهد.
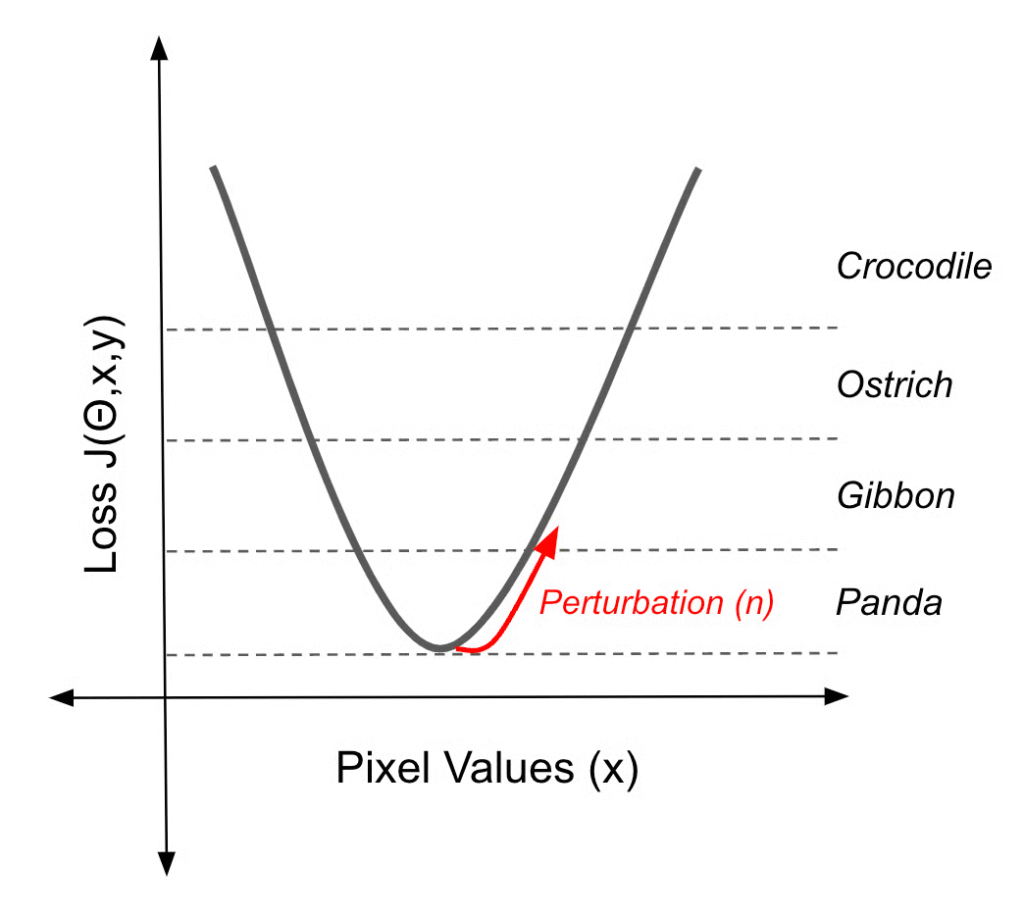
این نمونه خصمانه خاص با استفاده از روش علامت گرادیان سریع (FGSM) ایجاد شده است. نویز (η) با ابتدا گرفتن گرادیان (∇x) تابع زیان (J(θ,x,y) نسبت به دادههای ورودی (x) محاسبه میشود.
این گرادیان نشان میدهد که ورودی باید در چه جهتی تغییر کند تا حداکثر زیان را افزایش دهد. FGSM سپس علامت این گرادیان را میگیرد که جهت تغییر را فقط مثبت یا منفی برای هر پیکسل ساده میکند. در نهایت، این علامت را با یک عامل کوچک (ε) مقیاس میکند. این نویز (η) اغتشاشی است که وقتی به ورودی اصلی اضافه شود، پیشبینی مدل را به سمت طبقهبندی نادرست سوق میدهد.
η = ε sign(∇xJ(θ,x,y)
میتوانید این را به عنوان مقابل انتشار معکوس در نظر بگیرید. این الگوریتم از گرادیانهای تابع زیان برای محاسبه پارامترهای مدل استفاده میکند که پیشبینیهای دقیقی به ما میدهد. نتیجه مرزهای تصمیم هستند که زمانی که مقادیر پیکسل در داخل این مرزها قرار بگیرند، تصاویر را به عنوان کلاس داده شده طبقهبندی میکنند. اکنون ما از گرادیانها برای بازگرداندن تصویر از این مرزها استفاده میکنیم.
FGSM یک راه ساده برای انجام این کار است. همچنین روشهای پیچیدهتر و کارآمدتری برای فشار دادن مرزهای تصمیم وجود دارد. به عنوان مثال، فرود گرادیان پیشبینی شده (PGD) یک روش مبتنی بر گرادیان تکراری برای تولید نمونههای خصمانه است. این روش با اعمال چندین بار FGSM با اندازههای گام کوچکتر، روش علامت گرادیان سریع (FGSM) را گسترش میدهد. با هر گام برداشته شده، علامت گرادیانها ممکن است تغییر کند و جهت ایدهآل برای دور شدن از مرز تصمیم را تغییر دهد. بنابراین با استفاده از بسیاری از گامهای کوچکتر، PGD میتواند نمونههای خصمانه با اغتشاشات کوچکتر از FGSM پیدا کند.
روشهای مبتنی بر بهینهسازی
حمله کارلینی و واگنر (C&W)
به این مشکل از زاویهای متفاوت نگاه میکند. در حملات قبلی، هدف ما تغییر پیشبینی به هر پیشبینی نادرستی است. حمله C&W هدف دارد کوچکترین اغتشاش (δ) را پیدا کند که وقتی به یک تصویر اضافه شود، پیشبینی (f(x+δ) را به یک هدف داده شده (t) تغییر دهد.
min||δ||p s. t. f(x + δ) = t
برای انجام این کار، آنهامشکل را به عنوان یک مشکل بهینهسازی بیان میکنند. در عمل، این مستلزم فرمولبندی هدف بالا به صورت قابل تفاضل است. این شامل استفاده از لوژیتها Z(x) مدل میشود. اینها یک گرادیان روان ارائه میدهند که برای فرآیند بهینهسازی ضروری است.
حملات جعبه سیاه
حملاتی که در بالا توضیح داده شد، همه به دسترسی کامل به یک مدل نیاز دارند. بنابراین ممکن است فکر کنید که اگر پارامترهای مدل شما مخفی نگه داشته شود، در امان هستید. اشتباه میکردید!
یک نکته قابل توجه این است که اغلب فقط تخمینهای گرادیان برای یک حمله موفق مورد نیاز است. ما برای حمله FGSM دیدیم که فقط جهت گرادیانها مورد نیاز است. اینها را میتوان با استفاده از چند پینگ به یک API که احتمالهای طبقهبندی را بازمیگرداند تخمین زد. برای بدتر شدن اوضاع، حتی میتوان نمونههای خصمانه موفق را بدون هیچ گونه تعاملی با یک مدل پیدا کرد.
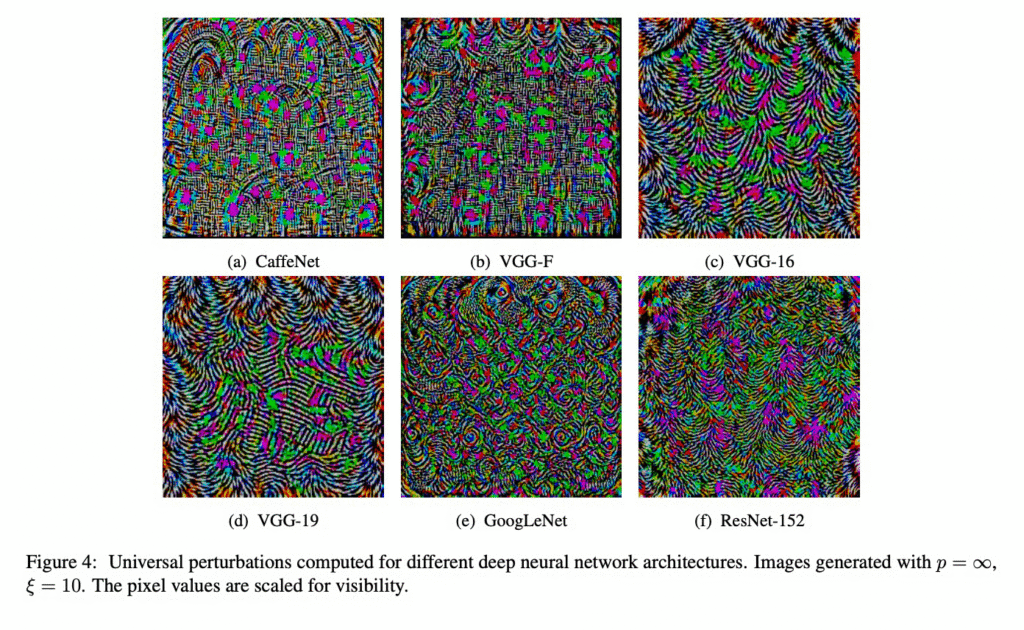
محققان دریافتند که نمونههای خصمانه قابل انتقال هستند. به طور خاص، آنها5 معماری محبوب یادگیری عمیق از پیش آموزش داده شده را گرفتند. آنهادریافتند که اگر یک نمونه خصمانه چهار مدل را فریب دهد، احتمال زیادی وجود دارد که مدل پنجم را نیز فریب دهد. این احتمال بیشتر از 96% و حتی 100% برای یکی از معماریها است.
از طرفی نشان داده شد که نمونههای خصمانه جهانی در معماریها تعمیم مییابند. این اغتشاشی است که وقتی به بسیاری از تصاویر اضافه شود، پیشبینی آن تصاویر را تغییر میدهد. نکته مهم این است که نمونههای جهانی با دانش جعبه سفید کامل فقط یک شبکه پیدا میشوند.
دفاع در برابر حملات خصمانه
روشهایی که میتوانیم از شبکهها دفاع کنیم به اندازه روشهایی که میتوانند مورد حمله قرار گیرند متنوع هستند. میتوانیم دادههای آموزشی، فرآیند آموزش یا حتی خود شبکه را تنظیم کنیم. همانطور که در پایان این بخش بحث میکنیم، گاهی سادهترین راه استفاده نکردن از یادگیری عمیق است.
آموزش خصمانه
این اولین رویکرد بر دادههای آموزشی تمرکز دارد. آموزش خصمانه شامل افزودن نمونههای خصمانه به مجموعه داده آموزشی برای بهبود مقاومت مدل در برابر حملات است. این نمونهها با استفاده از حملات شناخته شده ذکر شده در بالا یافت میشوند. ایده اصلی این است که مدل را در مرحله آموزش در معرض اغتشاشات خصمانه قرار دهیم تا یاد بگیرد چنین ورودیهایی را تشخیص دهد و در برابر آنهامقاومت کند.
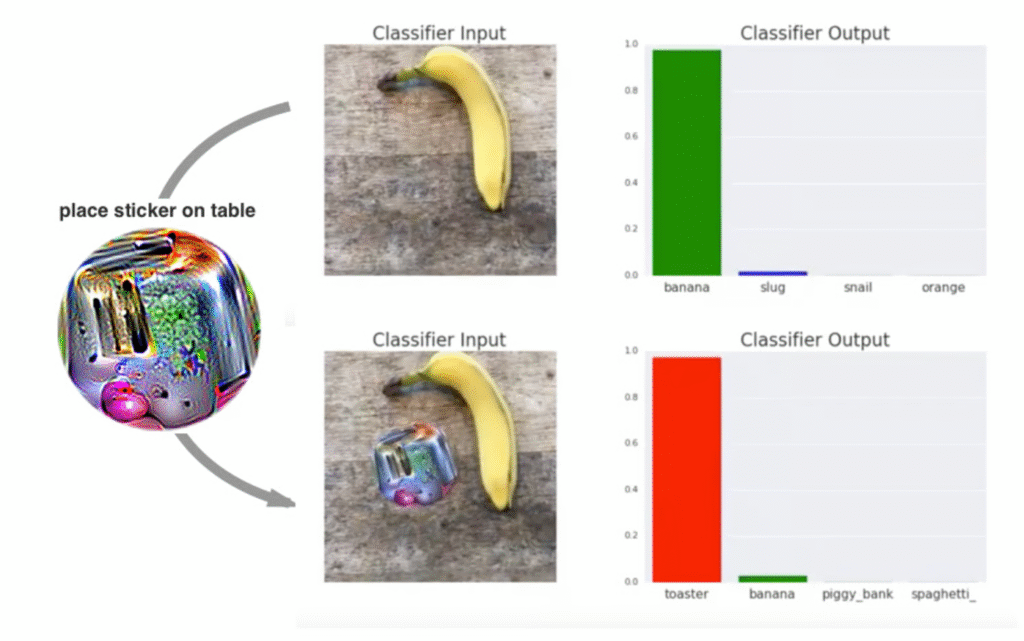
آموزش دفاعی
آموزش دفاعی شامل آموزش یک مدل برای تقلید از احتمالات خروجی نرم شده مدل دیگری است. ابتدا یک مدل استاندارد (مدل معلم) را روی مجموعه داده اصلی آموزش میدهیم. مدل معلم برچسبهای نرم (توزیع احتمال در کلاسها) را برای دادههای آموزشی تولید میکند. سپس یک مدل دانشآموز روی این برچسبهای نرم آموزش میبیند. نتیجه مدلی با مرزهای تصمیم نرمتر است که در برابر اغتشاشات کوچک مقاومتر هستند.
ماسک کردن گرادیان
ماسک کردن گرادیان شامل طیف وسیعی از تکنیکها است که گرادیانهای مدل را پنهان یا مخفی میکنند. به عنوان مثال، میتوانیم یک لایه غیرتفاضلی به شبکه اضافه کنیم، مانند یک تابع فعالسازی دودویی. این مقادیر ورودی پیوسته را به خروجیهای دودویی تبدیل میکند.
تعویض مدل
یک رویکرد ابتدایی ماسک کردن گرادیان است. این شامل استفاده از چندین مدل در سیستم شما است. مدلی که برای انجام پیشبینی استفاده میشود به صورت تصادفی تغییر میکند. این یک هدف متحرک ایجاد میکند زیرا یک مهاجم نمیداند کدام مدل در حال حاضر استفاده میشود. آنهاهمچنین باید برای موفقیت حمله، تمام مدلها را به خطر بیندازند.
اهمیت یادگیری ماشین خصمانه
با مرکزیتر شدن هوش مصنوعی و یادگیری ماشین در زندگی ما، AML اهمیت فزایندهای پیدا میکند. ضروری است که سیستمهایی که در مورد سلامت و امور مالی ما تصمیم میگیرند به راحتی فریب نخورند. این میتواند به صورت عمدی یا تصادفی باشد. من مطمئناً به یک خودروی خودکاری که چند برچسب بتواند آن را فریب دهد اعتماد نخواهم کرد. چنین حملهای ممکن است توسط راننده مورد توجه قرار نگیرد اما باعث شود خودرو تصمیمات نادرست و تهدیدکننده زندگی بگیرد. هنگام طراحی این سیستمها، باید تشخیص دهیم که AML بخشی از یک جنبش بزرگتر هوش مصنوعی مسئولیتپذیر است. برای اداره یک قلعه خوب، یک پادشاه باید عادلانه عمل کند، تصمیمات را توجیه کند، حریم خصوصی مردم خود را محافظت کند و ایمنی و امنیت آنهارا تضمین کند. این دو جنبه آخر است که AML سعی دارد به آنهارسیدگی کند.

با این حال، باید تشخیص دهیم که ایمنی و امنیت اساساً با جنبههای دیگر هوش مصنوعی مسئولیتپذیر متفاوت هستند. انصاف، قابلیت تفسیر و حریم خصوصی منفعل هستند. AML در محیطی عمل میکند که بازیگران بد به طور فعال به دنبال تضعیف روشهای آن هستند.
به همین دلیل، برخلاف انتظار، بسیاری از تحقیقات در این زمینه با هدف یافتن آسیبپذیریها و حملات انجام میشود. اینها شامل مسمومیت، فرار، استخراج مدل و حملات استنتاج است. آنهاهمچنین شامل روشهای عملیتر برای یافتن نمونههای خصمانه مانند FGSM، PGD، C&W و وصلههای خصمانه هستند که در مورد آنهابحث کردیم.
هدف این است که این موارد را قبل از بازیگران بد کشف کنید. سپس میتوان دفاعهای مناسب مانند آموزش خصمانه، تقطیر دفاعی و ماسک کردن گرادیان را برای مقابله با این حملات قبل از اینکه آسیب بزنند توسعه داد.
به این معنا، AML نیز بخشی از مسابقه تسلیحاتی سایبری بزرگتر است. آسیبپذیریها، حملات و دفاعهای جدید همیشه ظاهر میشوند و محققان و متخصصان AML باید برای پیشی گرفتن از مهاجمان خصمانه تلاش کنند.





