مواظب باشید وقتی هوش مصنوعی این آزمون را رد کند؛ «آزمون پایانی بشریت»
 تیم تحریریه
تیم تحریریه- ۴ دی ۱۴۰۴
خالقان یک تست جدید با نام «آزمون پایانی بشریت» استدلال میکنند که ممکن است بهزودی توانایی طراحی آزمونهایی که بهاندازه کافی برای مدلهای هوش مصنوعی دشوار باشند را از دست بدهیم.
اگر به دنبال دلیل جدیدی برای عصبی شدن در مورد هوش مصنوعی هستید، این را در نظر بگیرید: برخی از باهوشترین انسانهای جهان در تلاش برای طراحی آزمونهایی هستند که سیستمهای هوش مصنوعی نتوانند از سد آنها عبور کنند.
سالهاست که سیستمهای هوش مصنوعی با دادن انواع مختلفی از آزمونهای استانداردِ معیار به مدلهای جدید، سنجیده میشوند. بسیاری از این آزمونها شامل مسائل چالشبرانگیز در سطح آزمونهای SAT و در حوزههایی مانند ریاضیات، علوم و منطق بودهاند. مقایسه نمرات مدلها در طول زمان، بهعنوان یک معیار تقریبی برای سنجش پیشرفت هوش مصنوعی عمل میکرد. اما سیستمهای هوش مصنوعی در نهایت در آن آزمونها بسیار خوب عمل کردند؛ بنابراین آزمونهای جدید و دشوارتری طراحی شد، اغلب با انواع سوالاتی که دانشجویان تحصیلات تکمیلی ممکن است در امتحانات خود با آنها مواجه شوند.
اما حتی آن آزمونهای پیشرفته نیز دیگر چالشبرانگیز نیستند. مدلهای جدید از شرکتهایی مانند «OpenAI»، «گوگل» و «آنتروپیک» (Anthropic) در بسیاری از چالشهای سطح دکترا (PhD) نمرات بالایی کسب کردهاند. این موضوع کاربرد آن آزمونها را محدود کرده و منجر به طرح یک پرسش هشداردهنده شده است:
آیا سیستمهای هوش مصنوعی دارند بیشازحد باهوش میشوند، بهطوریکه دیگر نتوانیم آنها را اندازهگیری کنیم؟
رونمایی از سختترین آزمون تاریخ
پژوهشگران در «مرکز ایمنی هوش مصنوعی» (Center for AI Safety) و شرکت «اسکیل ایآی» (Scale AI) در حال انتشار یک پاسخ ممکن به آن پرسش هستند: یک ارزیابی جدید به نام «آزمون پایانی بشریت» (Humanity’s Last Exam) که ادعا میشود سختترین آزمونی است که تاکنون روی سیستمهای هوش مصنوعی اجرا شده است.
«آزمون پایانی بشریت» حاصل ایده «دن هندریکس»، پژوهشگر شناختهشده ایمنی هوش مصنوعی و مدیر مرکز ایمنی هوش مصنوعی است. (گفتنی است نام اولیه آزمون، «آخرین سنگر بشریت»، به دلیل دراماتیک بودن بیشازحد، کنار گذاشته شد.)
آقای هندریکس با همکاری «اسکیل ایآی» (یک شرکت هوش مصنوعی که در آن مشاور است)، این آزمون را گردآوری کرد. این مجموعه شامل حدود ۳۰۰۰ سوال چهارگزینهای و پاسخ کوتاه است و برای سنجش توانایی سیستمهای هوش مصنوعی در حوزههایی از فلسفه تحلیلی گرفته تا مهندسی موشک طراحی شده است. سوالات توسط کارشناسان برجسته این حوزهها، از جمله اساتید دانشگاه و ریاضیدانان برنده جایزه، طراحی شدهاند؛ کسانی که از آنها خواسته شده بود سوالات فوقالعاده دشواری را طرح کنند که خودشان پاسخ آنها را میدانستند.
نمونه سوالات: از آناتومی پرندگان تا فیزیک محض
در اینجا، میتوانید خودتان را با یک سوال از این آزمون درباره کالبدشناسی مرغ مگسخوار محک بزنید:
«مرغهای مگسخوار در راسته آپودیفورمز (Apodiformes) بهطور منحصربهفردی دارای یک استخوان بیضوی جفتشده دوطرفه هستند؛ یک استخوان کنجدی (سزاموئید) که در بخش دمیِ جانبیِ نیام (آپونوروز) گشادشده محل اتصال عضله “m. depressor caudae” تعبیه شده است. این استخوان کنجدی از چند تاندون جفتشده پشتیبانی میکند؟ پاسخ را با یک عدد بیان کنید.»
یا اگر به فیزیک بیشتر علاقه دارید، این یکی را امتحان کنید:
«یک بلوک روی یک ریل افقی قرار داده میشود که میتواند بدون اصطکاک در امتداد آن بلغزد. این بلوک به انتهای یک میله صلب و بدون جرم به طول R متصل است. یک جرم در انتهای دیگر میله نصب شده است. هر دو جسم وزن W دارند. سیستم در ابتدا ساکن است، با جرمی که مستقیماً در بالای بلوک قرار دارد. به جرم، یک فشار بینهایت کوچک، موازی با ریل داده میشود. فرض کنید سیستم طوری طراحی شده که میله بتواند بدون وقفه در یک دایره کامل ۳۶۰ درجه بچرخد. وقتی میله افقی است، تنش T1 را تحمل میکند. وقتی میله دوباره عمودی است (با جرمی که مستقیماً در زیر بلوک قرار دارد)، تنش T2 را تحمل میکند. (هر دوی این کمیتها میتوانند منفی باشند که نشاندهنده تحت فشار بودن میله است.) مقدار (T1−T2)/W چقدر است؟»
من پاسخها را اینجا منتشر نمیکنم، چراکه این کار باعث میشود آزمون برای هر سیستم هوش مصنوعی که با این متن آموزش میبیند، لو برود. علاوه بر این، من شخصاً برای تأیید پاسخها دانش کافی ندارم.
فرآیند طراحی و غربالگری سوالات
سوالات «آزمون پایانی بشریت» یک فرایند غربالگری دو مرحلهای را پشت سر گذاشتهاند. نخست، سوالات ارائهشده به مدلهای پیشروی هوش مصنوعی داده شد تا آنها را حل کنند. اگر مدلها نتوانستند به آنها پاسخ دهند یا در مورد سوالات چهارگزینهای، عملکردشان بدتر از حدس زدن تصادفی بود، سوالات به مجموعهای از داوران انسانی سپرده شد تا آنها را اصلاح کرده و پاسخهای صحیح را تأیید کنند. به کارشناسانی که سوالات با بالاترین رتبه را طراحی کرده بودند، مبلغی بین ۵۰۰ تا ۵۰۰۰ دلار به ازای هر سوال پرداخت شد و همچنین برای مشارکت در این پروژه اعتبار علمی دریافت کردند.
«کوین ژو»، پژوهشگر پسادکترا در فیزیک ذرات نظری در دانشگاه کالیفرنیا، برکلی، چندین سوال برای این آزمون ارائه داد. سه سوال از او انتخاب شد که به گفته خودش «در محدوده بالاییِ دشواریِ چیزی بودند که ممکن است در یک امتحان تحصیلات تکمیلی ببینید.»
آقای هندریکس که پیشتر در طراحی یک آزمون پرکاربرد دیگر برای هوش مصنوعی به نام «MMLU» مشارکت داشته است، میگوید که یک گفتگو با «ایلان ماسک» الهامبخش او برای طراحی آزمونهای سختتر بود. به گفته او، آقای ماسک نگرانیهایی را درباره آزمونهای موجود مطرح کرد و معتقد بود آنها بیشازحد آسان هستند.
آقای هندریکس نقل میکند: «ایلان به سوالات MMLU نگاه کرد و گفت:
اینها در سطح کارشناسی هستند. من چیزهایی میخواهم که یک متخصص در سطح جهانی بتواند انجام دهد.»
آزمونهای دیگری نیز برای سنجش قابلیتهای پیشرفته هوش مصنوعی در حوزههای خاص وجود دارد؛ مانند «FrontierMath» که توسط «Epoch AI» توسعه یافته و «ARC-AGI» که توسط پژوهشگر هوش مصنوعی، «فرانسوا شوله» (François Chollet) ایجاد شده است. اما هدف «آزمون پایانی بشریت» تعیین این است که سیستمهای هوش مصنوعی تا چه حد در پاسخ دادن به سوالات پیچیده در طیف گستردهای از موضوعات دانشگاهی مهارت دارند؛ چیزی که میتوان آن را معادل یک «نمره هوش عمومی» در نظر گرفت.
آقای هندریکس میگوید: «ما در تلاش هستیم تا برآورد کنیم که هوش مصنوعی تا چه حد میتواند بخش زیادی از کار فکریِ واقعاً دشوار را خودکار کند.»
شکست مدلهای فعلی و چشمانداز آینده
پس از تدوین فهرست نهایی سوالات، پژوهشگران «آزمون پایانی بشریت» را بر روی شش مدل پیشروی هوش مصنوعی، از جمله «Gemini 1.5 Pro» گوگل و «Claude 3.5 Sonnet» آنتروپیک اجرا کردند. نتیجه؟ همه آنها بهطور فاجعهباری رد شدند. سیستم «o1» شرکت OpenAI بالاترین امتیاز را در بین این گروه کسب کرد که تنها ۸.۳ درصد بود.
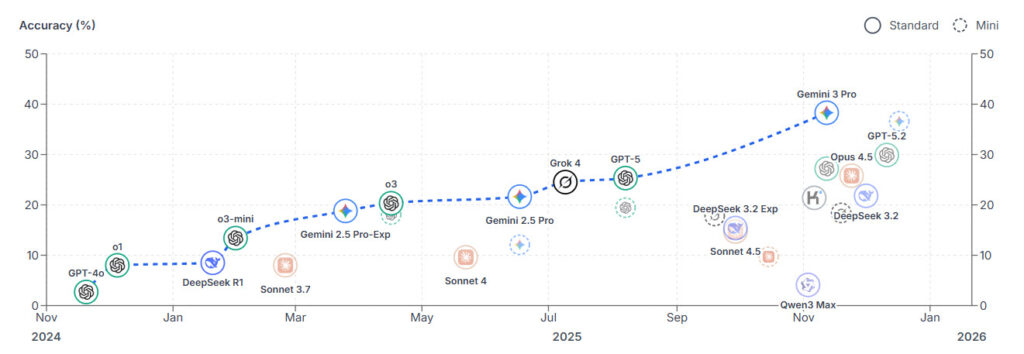
آقای هندریکس پیشبینی میکند که این نمرات بهسرعت افزایش یابند و احتمالاً تا پایان سال از ۵۰ درصد فراتر روند. او بیان میکند در آن مرحله، ممکن است سیستمهای هوش مصنوعی بهعنوان «مشاوران غیبی در سطح جهانی» در نظر گرفته شوند که قادرند در هر موضوعی دقیقتر از کارشناسان انسانی پاسخ دهند. در آن صورت، ممکن است مجبور شویم به دنبال روشهای دیگری برای سنجش تأثیرات هوش مصنوعی باشیم؛ مانند بررسی دادههای اقتصادی یا قضاوت در مورد اینکه آیا هوش مصنوعی میتواند اکتشافات جدیدی در حوزههایی مانند ریاضیات و علوم انجام دهد یا خیر.
«سامر یو» (Summer Yue)، مدیر تحقیقات «اسکیل ایآی» و یکی از سازندگان آزمون میگوید: «میتوانید نسخه بهتری از این آزمون را تصور کنید که در آن بتوانیم سوالاتی بپرسیم که خودمان هنوز پاسخ آنها را نمیدانیم و قادر باشیم تأیید کنیم که آیا مدل میتواند به ما در حل آن کمک کند یا خیر.»
پارادوکس هوشمندی و بیکفایتی همزمان
بخشی از چیزی که این روزها پیشرفت هوش مصنوعی را بسیار گیجکننده میکند، ناهموار بودن آن است. ما مدلهای هوش مصنوعی داریم که قادرند بیماریها را مؤثرتر از پزشکان انسانی تشخیص دهند، در المپیاد بینالمللی ریاضی مدال نقره کسب کنند و برترین برنامهنویسان انسانی را در چالشهای کدنویسی رقابتی شکست دهند. اما همین مدلها گاهی با کارهای اولیه دستوپنج نرم میکنند؛ مانند محاسبات ساده ریاضی یا سرودن شعر عروضی.
این امر به آنها شهرتی دوگانه داده است: در برخی موارد بهطور حیرتانگیزی درخشان و در موارد دیگر کاملاً بیفایده هستند. بسته به اینکه شما به بهترین خروجیها نگاه میکنید یا بدترین آنها، برداشتهای بسیار متفاوتی از سرعت بهبود هوش مصنوعی شکل میگیرد.
این ناهمواری، سنجش این مدلها را نیز دشوار کرده است. من سال گذشته نوشتم که ما به ارزیابیهای بهتری برای سیستمهای هوش مصنوعی نیاز داریم و هنوز به این باور پایبندم. اما همچنین معتقدم که به روشهای خلاقانهتری برای ردیابی پیشرفت هوش مصنوعی نیاز داریم که صرفاً به آزمونهای استاندارد متکی نباشند؛ زیرا بیشترِ آنچه انسانها انجام میدهند (و آنچه میترسیم هوش مصنوعی بهتر از ما انجام دهد) را نمیتوان در قالب یک آزمون کتبی گنجاند.
آقای ژو، پژوهشگر فیزیک ذرات نظری که سوالاتی برای «آزمون پایانی بشریت» ارائه داده است، به من گفت که اگرچه مدلهای هوش مصنوعی اغلب در پاسخ به سوالات پیچیده تحسینبرانگیز عمل میکنند، اما آنها را تهدیدی برای خود و همکارانش نمیداند؛ زیرا شغل آنها بسیار فراتر از صرفاً ارائه پاسخهای صحیح است.
او میگوید: «یک شکاف بزرگ بین معنای امتحان دادن و معنای یک فیزیکدان و پژوهشگر حرفهای بودن وجود دارد. حتی یک هوش مصنوعی که بتواند به این سوالات پاسخ دهد، ممکن است آماده کمک به پژوهش نباشد؛ چراکه پژوهش ذاتاً ساختاریافتگی کمتری دارد.»