
برطرف شدن چالش کمبود داده:
ProVision Salesforce آموزش هوش مصنوعی چندوجهی را با استفاده از گرافهای صحنه تصویری تسریع میکند
 تیم تحریریه
تیم تحریریه- ۴ فروردین ۱۴۰۴
با گسترش پروژههای هوش مصنوعی در سراسر جهان، دسترسی به دادههای آموزشی باکیفیت، به یکی از موانع اصلی تبدیل شده است. در حالی که وب عمومی دیگر منبعی کافی برای دادهها محسوب نمیشود، شرکتهای بزرگی مانند OpenAI و گوگل با عقد شراکتهای انحصاری به گسترش مجموعهدادههای اختصاصی خود میپردازند که این موضوع دسترسی دیگران را محدودتر میکند.
چالش دادهها
برای رفع این چالش، Salesforce گام مهمی در حوزه دادههای آموزشی بصری برداشته است. این شرکت اخیراً از ProVision رونمایی کرده است؛ چارچوبی نوآورانه که به طور برنامهریزیشده، دادههای آموزشی بصری تولید میکند. این مجموعه دادهها بهصورت سازمانیافته و مصنوعی تولید میشوند تا آموزش مدلهای زبانی چندوجهی (MLM) را که قادر به پاسخگویی به سؤالات درباره تصاویر هستند، را بهبود ببخشند.
Salesforce در همین راستا، مجموعهداده ProVision-10M را منتشر کرده و از آن برای افزایش دقت و کارایی مدلهای هوش مصنوعی چندوجهی مختلف استفاده میکند.
برای متخصصان داده، این چارچوب یک پیشرفت چشمگیر محسوب میشود. ProVision با تولید خودکار دادههای آموزشی بصری باکیفیت، وابستگی به مجموعهدادههای محدود و دارای برچسبگذاری نامنظم که چالشی رایج در آموزش مدلهای چندوجهی به شمار میآید را کاهش میدهد.
علاوه بر این، توانایی سنتز سیستماتیک مجموعهدادهها، کنترل بهتر، مقیاسپذیری و یکنواختی را تضمین میکند. این امر چرخههای تکرار را سریعتر کرده و هزینههای مربوط به جمعآوری دادههای خاص حوزه (domain-specific data) را کاهش میدهد.
این پژوهش، مکمل تحقیقات جاری در حوزه تولید دادههای مصنوعی (synthetic data generation) است و تنها یک روز پس از معرفی Cosmos توسط Nvidia ارائه شده است. Cosmos مجموعهای از مدلهای پایهای جهانشمول است که به طور خاص برای تولید ویدیوهای مبتنی بر فیزیک از ترکیب ورودیهایی مانند متن، تصویر و ویدیو طراحی شدهاند. این ویدیوها برای آموزش هوش مصنوعی در حوزههای مرتبط با فیزیک استفاده میشوند.
دادههای آموزشی بصری: عنصر کلیدی هوش مصنوعی چندوجهی
امروزه، مجموعهدادههای آموزشی هستهی اصلی پیشآموزش (pre-training) یا تنظیم دقیق (fine-tuning) مدلهای هوش مصنوعی هستند. این مجموعهها به مدلها کمک میکنند تا دستورالعملهای خاص را دنبال کرده و به طور مؤثر به سؤالات پاسخ دهند.
در هوش مصنوعی چندوجهی، این مدلها پس از یادگیری از انواع مختلف دادهها، میتوانند محتواهایی مانند تصاویر را تحلیل کنند. این فرایند با کمک مجموعه دادههایی که شامل جفتهای پرسش و پاسخ درباره محتوای بصری هستند، انجام میشود.
مشکل اینجاست که تولید این مجموعهدادههای بصری بسیار زمانبر و پرهزینه است. اگر شرکتی بخواهد این دادهها را بهصورت دستی تولید کند، مقدار زیادی زمان و منابع انسانی را هدر میدهد. از سوی دیگر، استفاده از مدلهای زبانی اختصاصی برای این کار، علاوه بر هزینه بالای پردازشی، خطر تولید پاسخهای نادرست یا نامفهوم (hallucination) را نیز به همراه دارد.
علاوه بر این، استفاده از مدلهای اختصاصی معمولاً یک فرایند «جعبه سیاه» است که تفسیر روش تولید داده و کنترل دقیق بر خروجیها را دشوار میکند.
ورود ProVision
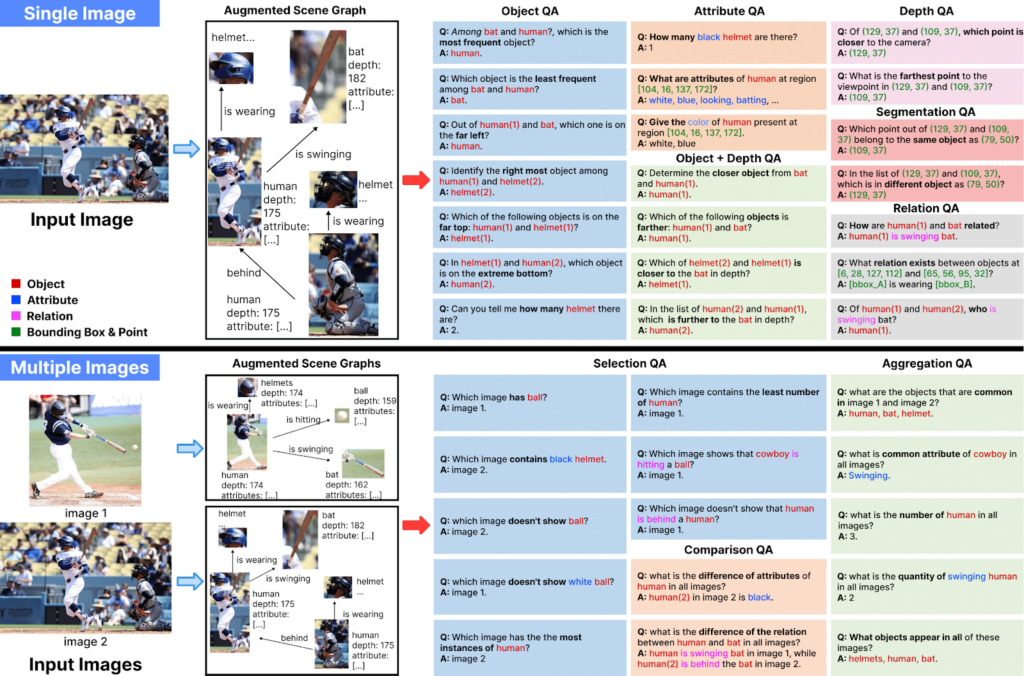
برای حل این چالش، تیم تحقیقاتی هوش مصنوعی Salesforce راهکاری جدید به نام ProVision معرفی کرده است. این چارچوب با استفاده از گرافهای صحنهای (scene graphs) و برنامههای نوشتهشده توسط انسان، دادههای آموزشی بصری را بهصورت سیستماتیک و خودکار تولید میکند.
در سادهترین تعریف، گراف صحنهای یک نمایش ساختاریافته از محتوای یک تصویر است. در این مدل:
- اشیای موجود در تصویر بهعنوان گرهها (nodes) نمایش داده میشوند.
- ویژگیهای هر شیء مانند رنگ یا اندازه به گرههای مرتبط اختصاص داده میشوند.
- روابط بین اشیا مثلاً «سیب روی میز است» بهصورت یالهای جهتدار (directed edges) نمایش داده میشوند که گرههای مرتبط را به هم متصل میکنند.
این گرافهای صحنهای میتوانند از مجموعهدادههای دارای برچسب مانند Visual Genome استخراج شوند یا با استفاده از یک خط پردازش هوشمند تولید شوند. این خط پردازش شامل مدلهای پیشرفته بینایی کامپیوتر است که قادرند اشیا، ویژگیها و حتی عمق تصویر را شناسایی کنند.
پس از آماده شدن گرافهای صحنهای، از آنها در کنار برنامههای نوشتهشده با پایتون و قالبهای متنی استفاده میشود تا مجموعهدادههای آموزشی کاملی برای مدلهای هوش مصنوعی ایجاد شود.
به گفته محققان این پروژه، هر مولد دادهای (data generator) از صدها قالب از پیش تعریفشده استفاده میکند تا به طور سیستماتیک این اطلاعات را ترکیب کرده و مجموعه متنوعی از دادههای آموزشی را تولید کند. این مولدها قادرند تا اطلاعات را مقایسه کنند، بازیابی کنند و درباره مفاهیم بصری پایهای مانند اشیا، ویژگیها و روابط میان آنها استدلال کنند.
این فناوری باعث میشود که فرایند تولید دادههای آموزشی بصری سریعتر، دقیقتر و مقیاسپذیرتر شود. در نتیجه مدلهای هوش مصنوعی چندوجهی میتوانند درک بهتری از تصاویر و روابط میان آنها داشته باشند.
مجموعهداده ProVision-10M برای آموزش هوش مصنوعی
در این پروژه، Salesforce از دو رویکرد برای تولید گرافهای صحنهای استفاده کرده است:
- تقویت گرافهای صحنهای موجود که بهصورت دستی برچسبگذاری شدهاند.
- تولید گرافهای صحنهای از صفر با استفاده از مدلهای پیشرفته بینایی کامپیوتر.
به کمک این روشها، محققان موفق به توسعه ۲۴ مولد داده تک تصویری و ۱۴ مولد داده چند تصویری شدند که میتوانند بهصورت خودکار مجموعههای گستردهای از دادههای آموزشی را تولید کنند. به گفته محققان، ProVision میتواند بر اساس گراف صحنهای یک تصویر، به طور خودکار پرسش و پاسخهای آموزشی تولید کند. مثلاً:
اگر تصویری از یک خیابان شلوغ داشته باشیم، مدل میتواند سؤالاتی مانند «چه رابطهای بین عابر پیاده و ماشین وجود دارد؟» یا «کدام شیء به ساختمان قرمز نزدیکتر است: ماشین یا عابر پیاده؟» تولید کند.
تیم تحقیقاتی از گرافهای صحنهای Visual Genome همراه با اطلاعات عمق و بخشبندی از Depth Anything V2 و SAM-2 استفاده کرده و ۱.۵ میلیون داده آموزشی تک تصویری و ۴.۲ میلیون داده چند تصویری ایجاد کرده است.
در روش دیگر، از ۱۲۰ هزار تصویر باکیفیت از مجموعهداده DataComp و مدلهایی مانند Yolo-World، Coca، Llava-1.5 و Osprey بهره گرفته شده که منجر به تولید ۲.۳ میلیون داده تک تصویری و ۴.۲ میلیون داده چند تصویری شده است.
در مجموع، این چهار مجموعهداده با هم مجموعهداده ProVision-10M را تشکیل میدهند که بیش از ۱۰ میلیون نقطه داده آموزشی منحصربهفرد دارد. این مجموعه اکنون در Hugging Face در دسترس است و در فرآیند آموزش مدلهای هوش مصنوعی عملکرد مؤثری از خود نشان داده است.
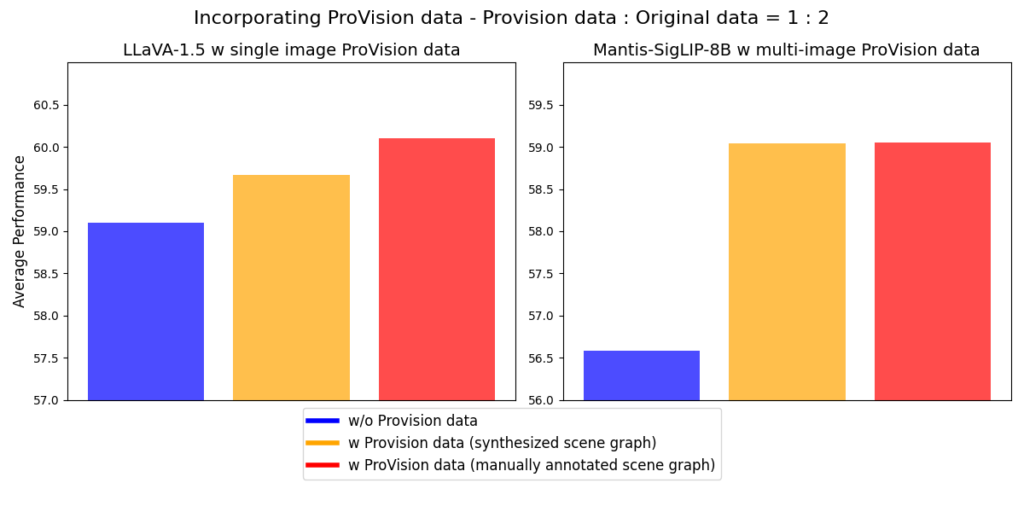
هنگامی که Salesforce این مجموعهداده را برای تنظیم دقیق مدلهای چندوجهی (Multimodal AI) به کار گرفت، نتایج چشمگیری مشاهده شد.
- LLaVA-1.5 با دادههای تک تصویری و Mantis-SigLIP-8B با دادههای چند تصویری تنظیم شد و عملکرد هر دو مدل نسبت به حالت بدون این دادهها بهبود یافت.
- دادههای تک تصویری ProVision-10M باعث افزایش دقت تا ۷٪ در بخش ۲D و ۸٪ در بخش ۳D از CVBench شد و همچنین دقت در QBench2، RealWorldQA و MMMU را ۳٪ افزایش داد.
- دادههای چند تصویری ProVision-10M نیز دقت مدل Mantis-Eval را تا ۸٪ بهبود بخشید.
دادههای مصنوعی ماندگار هستند
امروزه ابزارها و پلتفرمهای مختلفی برای تولید دادههای مصنوعی وجود دارند. بهعنوانمثال، مدلهای Cosmos که اخیراً توسط Nvidia معرفی شدهاند، قادرند انواع دادهها (از تصاویر گرفته تا ویدئوها) را برای آموزش مدلهای چندوجهی (Multimodal AI) ایجاد کنند. البته مشکل اصلی یعنی «تولید مجموعهدادههای دستوری (Instruction Datasets) که این دادهها را همراهی کنند» همچنان باقی است.
Salesforce با ProVision این مشکل را برطرف کرده و به شرکتها راهی ارائه میدهد تا فراتر از برچسبگذاری دستی یا مدلهای زبانی غیرشفاف بروند. رویکرد تولید مجموعهدادههای دستوری بهصورت برنامهریزیشده، امکان تفسیر و کنترل فرآیند تولید را فراهم میکند و در عین حال مقیاسپذیری کارآمد و دقت واقعی را حفظ میکند.
این شرکت امیدوار است که در بلندمدت محققان بتوانند بر اساس این چارچوب، فرآیند تولید گرافهای صحنهای را بهبود داده و مدلهای دادهساز پیشرفتهتری توسعه دهند. این امر میتواند زمینهساز تولید مجموعهدادههای دستوری برای انواع جدیدی از محتوا مانند ویدئوها باشد و کاربردهای گستردهای در آموزش مدلهای هوش مصنوعی آینده ایجاد کند.





