مسیر سازمانهای دادهمحور و مبتنی بر هوش مصنوعی تا سال ۲۰۳۰
پریسا سلامتی
- ۱۳ فروردین ۱۴۰۴
پیشرفتهای چشمگیر در زمینۀ هوش مصنوعی مولد (Generative AI) باعث شده است شرکتها به دادهها توجه ویژهای داشته باشند و در مسیر ایجاد تغییرات بنیادین برای تبدیل شدن به سازمانهای واقعاً دادهمحور حرکت کنند.
پتانسیل و هیجان بالای هوش مصنوعی مولد، سازمانها را به بازنگری در شیوههای کسبوکار خود واداشته است. اکنون، آنها به دنبال بهرهبرداری از فرصتهای گستردهای هستند؛ از تولید داروهای جدید و نوآوری در مراقبتهای پزشکی گرفته تا طراحی سیستمهای هوشمندی که بتوانند فرآیندهای پیچیده را بهصورت خودکار مدیریت کنند.
هدف اصلی این تحولات افزایش بهرهوری کارکنان و استفادۀ هرچه بیشتر از قابلیتهای هوش مصنوعی است. البته، این تغییرات با چالشها و ریسکهای جدیدی همراه هستند. در کانون تمامی این تحولات، دادهها قرار دارند. بدون دسترسی به دادههای دقیق و مرتبط، دستیابی به این دنیای جدید از فرصتها و ارزشها ممکن نخواهد بود.
این مقاله، که بر اساس گزارش تعاملی «سازمان دادهمحور در سال ۲۰۲۵» تهیه شده است، به مدیران کمک میکند تا بر هفت اولویت اصلی تمرکز کنند. اولویتهایی که مهمترین تغییرات، چالشهای کلیدی و نقاط تمرکز برای دستیابی به سازمانی دادهمحور تا سال ۲۰۳۰ را مشخص میکنند.
همهچیز، در همهجا، بهطور همزمان
تا سال ۲۰۳۰، بسیاری از شرکتها به مرحلهای خواهند رسید که به آن «فراگیری داده» میگویند. به این معنا که نه تنها کارکنان به جدیدترین دادهها دسترسی فوری خواهند داشت (همانطور که در گزارش «سازمان دادهمحور ۲۰۲۵» اشاره شده است)، بلکه دادهها در سیستمها، فرآیندها، کانالها، تعاملات و نقاط تصمیمگیری نیز گنجانده خواهند شد و بهصورت خودکار اقدامات لازم را انجام میدهند (البته تحت نظارت انسانها).
به عنوان مثال، فناوریهای حسگر کوانتومی دادههای دقیقتر و لحظهایتری از عملکرد محصولات (از خودرو گرفته تا دستگاههای پزشکی) تولید میکنند. این دادهها توسط هوش مصنوعی تجزیه و تحلیل شده و بهروزرسانیهای نرمافزاری هدفمند و خاصی را پیشنهاد و بهصورت خودکار اعمال میکنند.
همچنین، عاملهای هوش مصنوعی مولد که به دادههای دقیق و تاریخی مشتریان دسترسی دارند، با نسخههای دیجیتالی (Digital Twin) همین مشتریان تعامل میکنند تا محصولات، خدمات و پیشنهادهای شخصیسازیشده را پیش از عرضه در دنیای واقعی آزمایش کنند. گروههای مدلهای زبانی بزرگ (LLM) نیز میتوانند دادههای بهداشتی فردی را تحلیل کرده و داروها و درمانهای شخصیسازیشده را شناسایی، توسعه و ارائه کنند.
اقدامات ضروری برای رهبران داده
برای تحقق چشماندازهای فناورانه، رهبران داده باید سازمان را به سمتی هدایت کنند که در هر تصمیمگیری، ابتدا به داده و هوش مصنوعی توجه شود. در واقع، دادهها باید علاوه بر سادگی و دسترسی آسان (با ایجاد استانداردها و ابزارهایی که کاربران و سیستمها بتوانند بهراحتی دادههای مورد نیاز را پیدا کنند)، قابل پیگیری و قابل اعتماد (با استفاده از اقدامات پیشرفتۀ امنیت سایبری و آزمایش مداوم دادهها برای حفظ دقت بالا) باشند.
رهبران داده باید ذهنیت «همهچیز، در همهجا، بهطور همزمان» را داشته باشند تا اطمینان حاصل کنند که دادهها در سطح سازمان بهدرستی به اشتراک گذاشته شده و مورد استفاده قرار میگیرند. این رویکرد شامل تعریف و انتقال دقیق ساختارهای داده (مانند سلسلهمراتب و فیلدهای داده) است تا تیمها استانداردهای مورد نیاز برای هر مجموعه داده را درک کنند.
همچنین لازم است قوانین مشخصی برای استفاده از دادهها تعیین شود (مثل استانداردهای نامگذاری و انواع دادههای مجاز برای جمعآوری) و این قوانین باید بهطور منظم با تغییر مدلها، مقررات و اهداف کسبوکار بازبینی شوند.
برخی از شرکتها همین حالا هم به دنبال تحقق این چشمانداز هستند، اما در بسیاری از سازمانها هنوز تعداد کمی از افراد واقعاً درک میکنند که به چه دادههایی برای تصمیمگیری بهتر نیاز دارند یا چگونه میتوانند از قابلیتهای داده برای دستیابی به نتایج مؤثرتر بهرهمند شوند.

نمونه موردی
شرکت MakerVerse، که بازاری برای قطعات صنعتی است، مدلهای داده پیشرفته را در زنجیرۀ ارزش خود ادغام کرده است. به عنوان مثال، وقتی مشتریان نقشههای طراحیشده توسط کامپیوتر (CAD) و مشخصات مورد نیاز برای قطعات را ارسال میکنند، الگوریتمها با تحلیل مدلهای داده تاریخی، بهطور خودکار هزینههای تخمینی تأمینکنندگان، قیمتگذاری قراردادی و زمان تحویل را ارائه میدهند.
پس از تکمیل خرید توسط مشتری، مدلها دادههای مربوط به تأمینکنندگان (مانند هزینهها، سوابق عملکرد و توانایی انجام سفارشات خاص) را تحلیل میکنند تا بهترین گزینهها را انتخاب کرده و بهطور خودکار پیشنهادات ساخت و تحویل قطعه را ارسال و تأیید کنند. سیستمهای متصل به منابع داده تأمینکنندگان به MakerVerse این امکان را میدهند که بهصورت خودکار پیشرفت کار تأمینکنندگان را پیگیری کند (و پایگاه دادههای خود را با اطلاعات جدید بهروزرسانی کند) و در صورت بروز مشکل، آن را به مدیران حساب اطلاع دهد.
آزادسازی «آلفا»
دو ویژگی اصلی بسیاری از فناوریهای اخیر مانند هوش مصنوعی مولد، برنامهنویسی کمکد، برنامهنویسی بدونکد و مدلهای زبانی کوچک (SLMs) این است که استفاده از آنها چقدر آسان است و چقدر سریع در حال گسترش هستند. به عنوان مثال، فروشندگان در حال ادغام هوش مصنوعی مولد در محصولات خود هستند؛ استارتاپها به سرعت ابزارها و مدلهای جدیدی را معرفی میکنند؛ و بخشهای بزرگی از مردم از هوش مصنوعی مولد برای کمک به کارهای خود استفاده میکنند.
طبق یک نظرسنجی اخیر از مککینزی، ۶۵درصد از پاسخدهندگان گفتهاند که سازمانهایشان بهطور منظم در یک یا چند عملکرد کسبوکار از هوش مصنوعی مولد استفاده میکنند، در حالی که این رقم سال گذشته یکسوم بود.
با این حال، پذیرش گستردۀ این فناوریها به معنی مزیت رقابتی نیست. بسیاری از سازمانها از ابزارها و قابلیتهای مشابه استفاده میکنند، به همین دلیل نمیتوانند در بازار تمایز قابل توجهی پیدا کنند. این وضعیت شبیه به این است که همه بخواهند با همان آجرها خانهای بسازند که دقیقاً شبیه خانهٔ همسایه باشد. ارزش واقعی در این نیست که از چه مصالحی استفاده میشود، بلکه به نحوۀ ساخت و طراحی خانه نیز بستگی دارد. برای جلب توجه خریداران، لازم است این آجرها به شیوهای خلاقانه و منحصربهفرد کنار هم قرار گیرند تا خانهای بسازند که برای مردم جذاب باشد و تمایل به خرید آن را داشته باشند.
اقدامات ضروری برای رهبران داده
برای آزادسازی «آلفا» (اصطلاحی که سرمایهگذاران برای کسب بازدهی بالاتر از سطوح استاندارد استفاده میکنند) با استفاده از هوش مصنوعی مولد و سایر فناوریها، رهبران داده باید بر استراتژیهای دادهای که میتوانند مزیت رقابتی ایجاد کنند، تمرکز روشنی داشته باشند. برخی از این استراتژیها عبارتند از:
- شخصیسازی مدلها با استفاده از دادههای اختصاصی: قدرت مدلهای زبانی بزرگ (LLMs) و مدلهای زبانی کوچک (SLMs) در توانایی شرکتها برای آموزش این مدلها با استفاده از مجموعه دادههای اختصاصی خود و سفارشیسازی آنها از طریق مهندسی دقیق پرسشها نهفته است.
- یکپارچهسازی دادهها، هوش مصنوعی و سیستمها: نحوه ترکیب و یکپارچهسازی دادهها و فناوریها باعث به وجود آمدن ارزش میشود. بهعنوان مثال، یکپارچهسازی هوش مصنوعی مولد و موارد کاربرد هوش مصنوعی عملی میتواند قابلیتهای متمایزی مانند استفاده از هوش مصنوعی برای توسعه مدلهای پیشبینی رفتار کاربران و تغذیه این بینشها به مدلهای هوش مصنوعی مولد برای تولید محتوای شخصیسازیشده ایجاد کند.
- تمرکز بر روی محصولات داده با ارزش بالا: بخش عمدهای از ارزشی که یک شرکت میتواند از دادهها کسب کند، به کمک پنج تا ۱۵ محصول دادهای به دست میآید. این محصولات دادهای شامل دادههای پردازششده و بستهبندیشده هستند که سیستمها و کاربران میتوانند بهراحتی از آنها استفاده کنند.

مسیرهای توانمندی: از واکنش به مقیاس
سادگی و در دسترس بودن ابزارهای پایه، به ظهور موارد استفادۀ متعددی منجر شده است که اغلب با یکدیگر ارتباطی ندارند. هیجان ایجادشده در حوزۀ هوش مصنوعی مولد باعث می شود رهبران داده دیگر نیازی به متقاعد کردن همکاران خود دربارۀ ارزش دادهها ندارند و در عوض با چالش مدیریت تقاضای زیاد مواجهاند.
این وضعیت دو مشکل اصلی به وجود میآورد: نخست، تیمها در سازمان مدلهای آزمایشی و برنامههای مبتنی بر هوش مصنوعی را راهاندازی میکنند که هیچ شانسی برای گسترش و مقیاسپذیری ندارند و در نتیجه در وضعیتی به نام «گودال آزمایشی» گرفتار میشوند. دوم اینکه، افراد مختلف مشغول سرمایهگذاری در موارد استفادۀ متفاوتی هستند که نیاز به اجزای مختلفی از زیرساختهای داده و هوش مصنوعی دارند و برای به دست آوردن ارزش واقعی، باید همۀ اجزا را بهصورت همزمان بسازند.
برای اینکه کسبوکارهای مبتنی بر داده را در سال ۲۰۳۰ بهدرستی راهاندازی کنند، رهبران داده باید رویکردی اتخاذ کنند که به سرعت تأثیرگذاری موارد استفاده را افزایش دهد و در عین حال، مشکل مقیاسپذیری را با استفاده از یک معماری مناسب حل کند. برای این منظور، آنها باید «مسیرهای توانمندی» را ایجاد کنند؛ یعنی مجموعهای از اجزای فناوری که قابلیتهای لازم را فراهم میکنند و میتوانند برای چندین مورد استفاده به کار بروند.
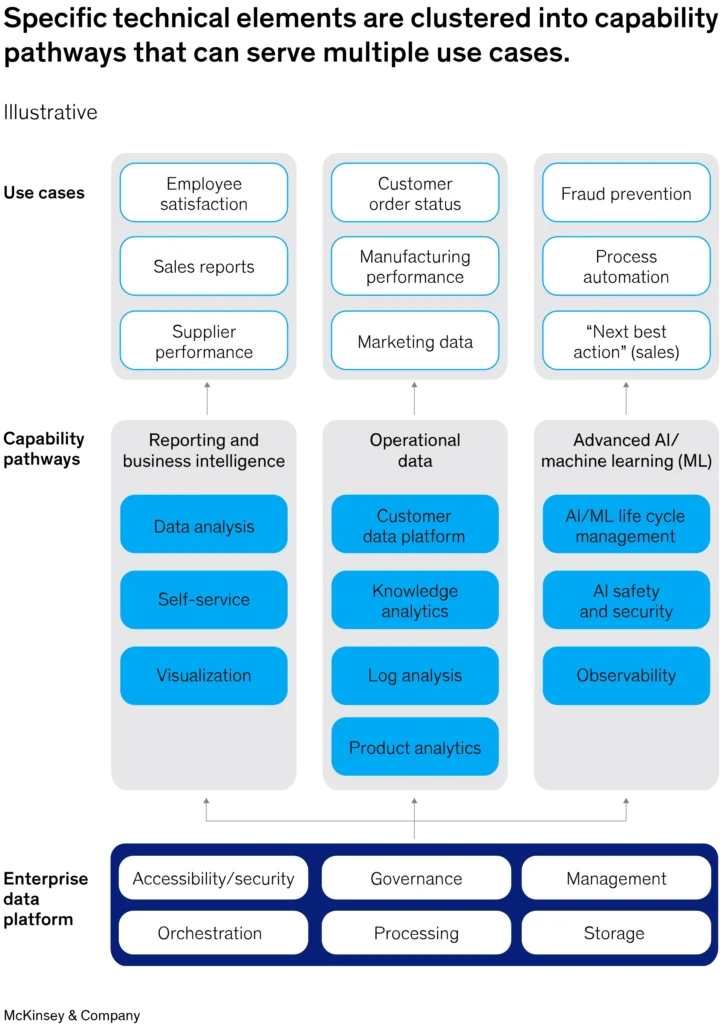
توسعه و نگهداری مسیرهای توانمندی تا حد زیادی به انتخابهای کلیدی در زمینۀ معماری داده بستگی دارد. این انتخابها معمولاً به سه دسته تقسیم میشوند:
- رویکرد متمرکز: مانند استفاده از «دریاچۀ داده» (data lake) بهخوبی مدیریتشده.
- رویکرد غیرمتمرکز: که در آن واحدهای تجاری محلی بهطور کامل مالک دادههای خود هستند.
- رویکرد فدرال: که ممکن است از شبکۀ داده (data mesh) استفاده کند.
استفاده از رویکرد غیرمتمرکز میتواند ایجاد مسیرهای توانمندی قابل استفاده در سطح کل سازمان را دشوار کند. در عوض، رویکرد متمرکز به سرمایهگذاری اضافی در حوزۀ حاکمیت و نظارت نیاز دارد. همچنین، انتخاب ارائهدهنده خدمات ابری (hyperscaler) و مجموعۀ ابزارها و قابلیتهای موجود در آن نیز بر نحوۀ توسعۀ مسیرهای توانمندی تأثیر خواهد گذاشت.
نمونه موردی
یک شرکت خودروسازی قصد داشت قابلیتهایی را ایجاد کند تا خدمات و ارتباطات شخصیسازیشدهای را با مشتریان خود ارائه دهد. برای برآورده کردن این نیاز، تصمیم گرفت دو مسیر توانمندی توسعه دهد.
اولین مسیر، یک مسیر قابلیت هوش مصنوعی و یادگیری ماشین بود که برای انجام تجزیه و تحلیل عمیق و تقسیمبندی مشتریان شرکت طراحی شده بود. برای ساخت این مسیر، شرکت چندین عنصر مختلف از جمله کتابخانۀ یادگیری ماشین PySpark (برای خوشهبندی و تحلیل گرایش)، Databricks برای ذخیرهسازی فایل و Futurescope برای مدیریت مدل با استفاده از MLflow را کنار هم جمعآوری کرد.
مسیر قابلیت دوم برای ارتباطات شخصیسازیشده، شامل مدلهای زبانی بزرگ (LLMs)، یک انبار داده فروش، فناوریهای بازاریابی برای ارسال و پیگیری عملکرد ایمیل و یک مجموعه داده مشتری ۳۶۰ به همراه دادههای خارجی از Experian برای شناسایی علایق و جمعیتشناسی مشتریان بود که به سایر عناصر فنی نیز اضافه شده بود.
با این مسیرهای توانمندی، شرکت موفق شد مشتریان خود را به گروههای بسیار دقیق تقسیمبندی کند و پیشنهادات شخصیسازیشدهای به آنها ارائه دهد. همچنین، توانست دستورالعملهای شخصیسازیشدهای برای پیگیری مشتریان در عملیات خدماتی ارائه کند و اطلاعات رفتاری شخصیسازیشدهای برای کارکنان فروش فراهم آورد.

زندگی در یک دنیای غیرساختارمند
سالهاست که شرکتها با دادههای ساختارمند (مانند SKUها، مشخصات محصولات، تراکنشها و موجودیها که با دادههای اصلی و مرجع سازماندهی شدهاند) کار میکنند. البته این فقط ۱۰ درصد از دادههای موجود است. هوش مصنوعی مولد (Gen AI) توانسته است حدود ۹۰درصد دیگر دادهها را که غیرساختارمند هستند، (مانند ویدئوها، تصاویر، چتها، ایمیلها و نظرات محصولات) به روی شرکتها باز کند.
این حجم زیاد داده میتواند توانمندیهای شرکتها را بهطور قابلتوجهی غنی کند، بهویژه زمانی که با منابع داده دیگر ترکیب یا یکپارچه شود. بهعنوان مثال، میتوان از نظرات، پستهای شبکههای اجتماعی و تاریخچۀ خریدها استفاده کرد تا هوش مصنوعی مولد بتواند پیشنهادات بسیار شخصیسازیشدهای برای مشتریان ایجاد کند.
همچنین میتوان با تجزیه و تحلیل قراردادها و شرایط از معاملات گذشته، به هوش مصنوعی مولد این امکان را داد که مذاکرات با تأمینکنندگان، فرآیندهای ورود و تأمین کالا و بهروزرسانیهای قرارداد را مدیریت کند.
البته مقیاس و تنوع دادههای غیرساختارمند چالشی بسیار پیچیدهتر ایجاد میکند. بهطور کلی، دادههای غیرساختارمند از نظر سازگاری کمتر، در دسترس بودن کمتر و سختی بیشتر در آمادهسازی و پاکسازی شناخته میشوند. به عبارت دیگر، کار با این دادهها به مراتب دشوارتر از دادههای ساختارمند است. برای مثال، مدیریت دادههای غیرساختارمند شبیه به این است که شما برای تأمین آب شرب به منابع آب مدیریتشده وابسته باشید؛ اما ناگهان مجبور شوید با حجم عظیم اقیانوس آب دست و پنجه نرم کنید. باتوجهبه پیشبینیها مبنی بر اینکه حجم دادهها از سال ۲۰۲۰ تا ۲۰۳۰ بیش از ده برابر افزایش خواهد یافت، انتظار نمیرود که این چالش بهزودی حل شود.
اقدامات اساسی برای رهبران داده
ایجاد ارزش از دادههای غیرساختارمند کار پیچیدهای است که به زمان و تلاش زیادی نیاز دارد؛ اما بسیاری از افراد از این چالشها آگاه نیستند. در این مسیر، مشکلات متعددی از جمله نیاز به پاکسازی و برچسبگذاری دادهها، نگرانیهای مربوط به حریم خصوصی و تعصب، هزینههای بالای ذخیرهسازی و انتقال دادهها در فضای ابری و فرآیندهای تبدیل داده (که معمولاً هزینهبر هستند) وجود دارد.
رهبران داده باید در توسعه قابلیتهایی مانند پردازش زبان طبیعی سرمایهگذاری کنند تا بتوانند دادههای غیرساختارمند را بهگونهای تبدیل کنند که مدلهای زبانی بزرگ (LLM) بتوانند آنها را درک کنند و مورد استفاده قرار دهند. علاوه بر این، آنها باید بهطور مداوم مدلها را آزمایش و تنظیم کنند تا با تغییرات مدلها و منابع داده سازگار شوند.
در نهایت، رهبران داده باید بر «آزادسازی آلفا» در مدیریت حجم بالای دادههای غیرساختارمند تمرکز کنند. این به معنای صرف زمان برای شناسایی بخشهای کلیدی دادههای غیرساختارمند است که برای دستیابی به اهداف تجاری و محصولات اصلی دادهها ضروری هستند. با این کار، میتوانند به بهترین شکل از دادهها بهرهبرداری کنند و به مزیت رقابتی دست پیدا کنند.

رهبری داده: نیاز به همکاری جمعی
توانایی شرکتها برای دستیابی به چشمانداز داده و هوش مصنوعی خود تا سال 2030 بهطور چشمگیری به رهبری مؤثر وابسته است. در حال حاضر، وضعیت در این زمینه چندان رضایتبخش نیست. بهعنوان مثال، تنها نیمی از مدیران ارشد داده و تجزیه و تحلیل احساس میکنند که میتوانند با استفاده از دادهها نوآوری ایجاد کنند. حتی شرکتهای با عملکرد بالا نیز با چالشهایی روبرو هستند. 70درصد از این سازمانها گزارش میدهند که در توسعۀ فرآیندهای حاکمیت داده و ادغام سریع دادهها در مدلهای هوش مصنوعی با دشواریهایی مواجهاند.
این مشکل عمدتاً به دلیل عدم وضوح در وظایف، مهارتهای محدود یا حاکمیت ناکارآمد است. در برخی موارد، رهبران داده بیشتر بر روی ریسکها تمرکز دارند؛ اما از کسبوکارهایی که نیاز دارند از دادهها برای تولید درآمد استفاده کنند، جدا هستند. در موارد دیگر، رهبران دارای اختیارات مشخصی برای تسریع در ایجاد ارزش در حوزههای خاص کسبوکار هستند؛ اما دیدگاه کلی از کل سازمان که به ایجاد قابلیتهای جداگانه و راهحلهای غیرمؤثر منجر می شود را ندارند.
برای قرار گرفتن در مسیر درست، شرکتها نیاز دارند رهبرانی را پیدا کنند که در سه زمینۀ اصلی مهارت دارند:
- حاکمیت و انطباق: این رهبران بر فعالیتهای دفاعی متمرکز هستند و عمدتاً تحت تأثیر مقررات و ریسکهای سایبری فعالیت میکنند. معمولاً چنین رهبرانی بیشتر در صنایع با نیاز به انطباق بالا یا صنایعی که دارای ارزش اطلاعاتی بالایی هستند، یافت میشوند.
- مهندسی و معماری: تمرکز این رهبران بر طراحی فنی است و هر مشکل را به عنوان فرصتی برای خودکارسازی، استفادۀ مجدد و گسترش میبینند.
- ایجاد ارزش تجاری: این رهبران بر تولید درآمد، رشد و کارایی از طریق دادهها متمرکز هستند و معمولاً بهطور نزدیک با بخشهای تجاری همکاری میکنند.
یافتن یک فرد واحد با مهارتها، نگرش و تجربۀ لازم برای پوشش همۀ این سه نقش نادر است. با این حال، رهبران داده توانمند میتوانند تیمهای خود را با افرادی که دارای مهارتهای مناسب هستند، تقویت کنند. علاوه بر این، سازمانها میتوانند کمیتۀ عملیاتی ایجاد کنند که هر یک از حوزههای مرتبط با قابلیتها را نمایندگی کند.
صرفنظر از مدلی که انتخاب میشود، این فرایند به حمایت روشن از سوی مدیریت عالی، گفتوگو با سایر رهبران درباره نقشها و مسئولیتها، ایجاد مسئولیت مشترک و تشویقهای یکسان برای حل چالشها در هر سه حوزه نیاز دارد.

چرخه جدید جذب استعداد
پروفایلهای نیروی کار در سازمانها تا سال 2030 بهطور چشمگیری تغییر خواهند کرد. فناوریهای هوش مصنوعی مولد و اتوماسیون بهتدریج در حال انجام وظایف پایهای مانند تولید کد، ایجاد مستندات و طبقهبندی و ترکیب دادهها هستند. با پیشرفت این فناوریها، انتظار میرود که هوش مصنوعی مولد و سایر تکنولوژیها به انجام کارهای پیچیدهتری مانند تولید زنجیره دادهها و توسعۀ محصولات دادهای بپردازند. این تغییرات نهایتاً به تغییرات عمدهای در تأمین نیروی کار و ظهور مشاغل جدید منجر خواهد شد.
اقدامات ضروری برای رهبران داده
این تغییرات در نحوۀ انجام کارها، نیازمند آن است که رهبران داده و هوش مصنوعی دید روشنی از مهارتهای جدید مورد نیاز داشته باشند. برخی از این مهارتها به نقشهای موجود افزوده خواهند شد، در حالی که برخی دیگر به ایجاد نقشهای کاملاً جدید نیاز دارند. برای مثال، مهندسان داده باید مهارتهای جدیدی مانند بهینهسازی عملکرد پایگاهداده، طراحی داده، DataOps (ترکیبی از DevOps، مهندسی داده و علم داده) و توسعه پایگاهدادههای برداری را یاد بگیرند. علاوه بر این، نقشهای جدیدی مانند مهندسان پرامپت، ناظران اخلاق هوش مصنوعی و متخصصان دادههای غیرساختارمند نیز به وجود خواهند آمد.
این تغییر در مهارتها نیازمند همکاری رهبران داده با مدیران منابع انسانی است تا نحوه پیدا کردن و آموزش افراد برای مهارتهای مورد نیاز را بازنگری کنند. بهعنوان مثال، شرکتها باید برنامههای کارآموزی ایجاد کنند که در آن کارشناسان ارشد داده، زمان خود را به آموزش استعدادهای جوان اختصاص دهند. همچنین این افراد باید برنامههای آموزشی مبتنی بر ماژولهای مهارتی مشخص توسعه دهند.
در تلاش برای ارتقای مهارتها، رهبران داده نباید فرهنگ سازمانی را فراموش کنند. تحلیلهای مککینزی نشان میدهد که توسعهدهندگان و کاربران پرکار هوش مصنوعی مولد بیشتر از هر چیز دیگری به داشتن افراد قابل اعتماد و حمایتگر و همچنین رهبران دلسوز و الهامبخش اهمیت میدهند. تقریباً دو نفر از هر پنج نفر میگویند که داشتن یک کار معنادار و داشتن جامعهای فراگیر، از مهمترین انگیزههای آنهاست و این عوامل حتی بیشتر از انعطافپذیری برایشان اهمیت دارد.

حفظ اعتماد دیجیتال
با پیشرفت فناوریهای نوین، به ویژه هوش مصنوعی و هوش مصنوعی مولد، نگرانیها در مورد ریسکهای این حوزه بهشدت افزایش یافته است. دولتها به سرعت در حال وضع قوانین جدید هستند و شرکتها نیز به بررسی سیاستهای تازه میپردازند.
برخی از مشکلات مانند خطاهای منطقی (یعنی زمانی که مدلهای هوش مصنوعی مولد پاسخهای نادرست میدهند)، تعصب، حقوق مالکیت معنوی و حریم خصوصی دادهها، از قبل شناخته شدهاند. با این حال، ازآنجاییکه این فناوریها جدید و بهسرعت در حال تحول هستند، اغلب درک کاملی از ریسکهای موجود وجود ندارد. در این میان، سه نوع ریسک مهم وجود دارد که باید مورد توجه قرار گیرند:
- انواع جدید حملات سایبری: ظهور هوش مصنوعی مولد و قدرت آن در یادگیری و تکامل سریع، زمینهساز انواع جدیدی از حملات سایبری شده است. این حملات شامل بدافزارهای خودتکاملیاب است که میتوانند سیستمهای داخلی را شناسایی کرده و برای نفوذ به دفاعها بهطور خودکار بهروزرسانی شوند. همچنین، رباتهای هوشمند که بهطور فزایندهای قادر به تقلید رفتار انسانها هستند و دادههای آلودهای که به مدلهای آموزشی افزوده میشوند، از جملۀ این تهدیدات جدید به شمار میآیند.
- گسترش دامنۀ ریسک: ارتباطات گسترده میان سیستمهای هوش مصنوعی و داده، هم درون سازمانها و هم در بیرون آنها، حوزهای وسیعتر برای آسیبپذیری ایجاد کرده است. این امر امکان خسارتهای بیشتری را فراهم میآورد.
- ناشناختههای جدید: تعاملات با هوش مصنوعی در حال تبدیل شدن به مکالمات طبیعیتر و کمتر وابسته به جستجوهای ساده هستند. این امر شرکتها را وارد یک منطقه مبهم میکند که بر اساس ارزشهای متفاوت تعریف میشود. در این شرایط، گسترش تعداد عوامل هوش مصنوعی که بهنوعی با یکدیگر «گفتگو» میکنند، احتمال ظهور دستههای جدیدی از ریسکها را افزایش میدهد.
اقدامات اساسی برای رهبران داده
رهبران داده، علاوه بر شناخت انواع ریسکهای جدید، باید رویکردهای خود را در مدیریت ریسک بازنگری کنند. بسیاری از آنها هنوز به روشهای سنتی مربوط به کیفیت داده و رعایت مقررات متکی هستند؛ در حالی که تنها تعداد کمی از آنها به انجام آزمایشات پیشرفته در زمینۀ کدنویسی و مسائل اخلاقی پرداختهاند.
رهبران داده باید با درک این نکته که مدیریت ریسک میتواند به یک مزیت رقابتی تبدیل شود، رویکرد جدیدی اتخاذ کنند. این مزیت میتواند از طریق ساخت برندی معتبر به دست آید که بهعنوان حافظ معیشت مشتریان شناخته میشود، یا با اجتناب از مشکلاتی که ممکن است رقبا با آنها مواجه شوند، به دست آید. در این راستا، نگرش رهبران باید به سمت رویکردی پیشگیرانه در مدیریت ریسکها حرکت کند و تنها به دستیابی به معیارهای انطباق محدود نشود.
رهبران داده و بهطور کلی رهبران فناوری میتوانند با بهرهگیری از قابلیتهای هوش مصنوعی و در آینده از فناوریهای کوانتومی، به چالشهای سایبری پاسخ دهند. بهعنوان مثال، آنها میتوانند از مدلهای زبانی مخالف (adversarial LLMs) برای آزمایش ایمیلهای تولید شده توسط مدلهای هوش مصنوعی بهمنظور شناسایی محتوای نامناسب یا غیرقانونی استفاده کنند و همچنین از ابزارهای ارزیابی برای شناسایی تعصبات موجود در دادهها بهره ببرند.
اگرچه ابزارهای تولید شده توسط شرکتهای ثالث میتوانند مفید باشند، اما امنیت پیشرفتۀ هوش مصنوعی نباید بهطور کامل به آنها واگذار شود. رهبران داده باید بر تقویت قابلیتهای داخلی خود تمرکز کنند تا بتوانند با سرعت تغییرات بازار همگام شوند و در برابر تهدیدات جدید واکنش مناسب نشان دهند.
بررسی اجمالی
شرکت Skyflow پلتفرمی به نام Skyflow Data Privacy Vault معرفی کرده است که به سازمانها کمک میکند تا دادههای حساس خود را مدیریت، محافظت و استفاده کنند. این پلتفرم بهعنوان یک مرکز امن برای دادههای حساس عمل کرده و آنها را از سایر سیستمها جدا کرده و با استفاده از تکنیکهای پیشرفته رمزگذاری میکند.
با وجود این سطح بالای امنیت، APIهای ایمن Skyflow به کاربران این امکان را میدهند که بدون نیاز به رمزگشایی اطلاعات اصلی، از این دادهها در فرآیندهای کاری، اشتراکگذاری و تحلیل استفاده کنند.