هوش مصنوعی FantasyTalking رونمایی شد: تولید ویدیوهای سخنگو از یک تصویر
 نگار علی
نگار علی- ۲۹ فروردین ۱۴۰۴
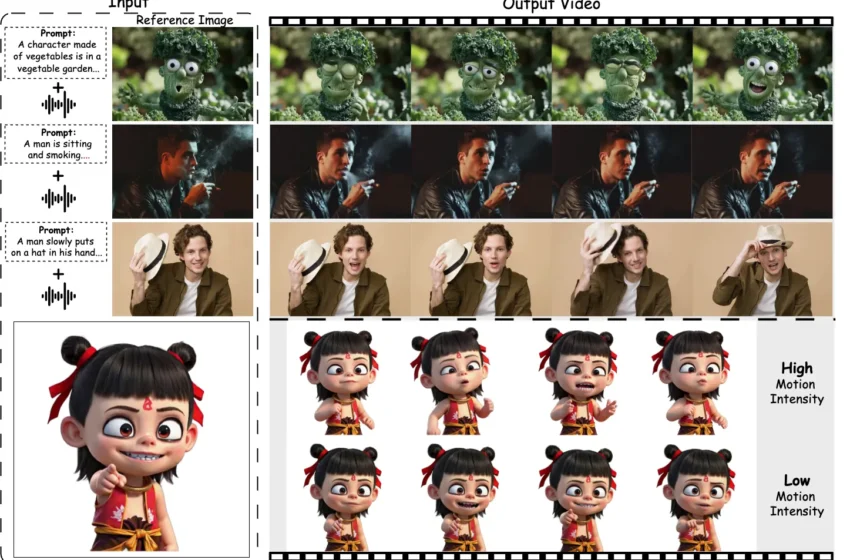
هوش مصنوعی FantasyTalking، توسعهیافته توسط محققان چینی، توانایی تولید ویدیوهای واقعگرایانه از یک تصویر پرتره ثابت و فایل صوتی را دارد.
این مدل با بهرهگیری از معماری Video Diffusion Transformer و استراتژی دو مرحلهای، در مرحله اول حرکات کلی چهره، بدن و پسزمینه را با صدا هماهنگ میکند و در مرحله دوم، با استفاده از ماسکهای خاص، حرکات لبها را فریمبهفریم تنظیم میکند تا هماهنگی دقیقی با صدا داشته باشد.
این ویژگیها باعث شده تا FantasyTalking در تولید آواتارهای سخنگو با کیفیت بالا و حفظ هویت چهره عملکردی برجسته داشته باشد.
این مدل از ماژولهای کنترلی برای تنظیم شدت حرکات چهره و بدن استفاده میکند و امکان تولید ویدیوهایی با زوایای متنوع (نزدیک، نیمتنه، تمامقد)، استایلهای گرافیکی مختلف (واقعگرایانه یا کارتونی) و حتی متحرکسازی حیوانات را فراهم میآورد.
در مقایسه با روشهای پیشرفته مانند OmniHuman-1، FantasyTalking از نظر واقعگرایی، انسجام حرکتی و تطابق صوتی-تصویری برتری دارد و به دلیل استفاده از مکانیزمهای مبتنیبر چهره، نتایجی طبیعیتر ارائه میدهد.
این فناوری گامی بزرگ در حوزه گرافیک و بینایی ماشین محسوب میشود.





