
یادگیری انتقالی در پردازش زبان طبیعی – بخش اول
به اولین بخش از پردازش زبان طبیعی مدرن خوش آمدید. پردازش زبان طبیعی پیشرفت سریع خود را مرهون انتقال یادگیری است و به همین دلیل پیش از هر چیز به معرفی یادگیری انتقالی میپردازیم.
به اولین بخش از پردازش زبان طبیعی مدرن خوش آمدید. پردازش زبان طبیعی پیشرفت سریع خود را مرهون انتقال یادگیری است و به همین دلیل پیش از هر چیز به معرفی یادگیری انتقالی میپردازیم.

بهتازگی پیش بینی موقعیت های چندعاملی توسط خودروهای هوشمند، محقق شده است؛ خودروهای خودران، با کمک سیستم جدید یادگیری ماشینی، میتوانند حرکات بعدی رانندگان خودروهای اطراف، عابران پیاده و دوچرخه/موتورسواران را در لحظه پیشبینی کنند. برجستهترین مانعی که پیش روی حرکت خودروهای تماماً خودران در سطح شهر وجود دارد، انسانها

میدانید چطور باید یک مدل یادگیری عمیق ساخته و آنرا ارتقا دهید؟ یا میدانید چطور باید توابع Callback سفارشی ایجاد کنید؟ توابع Callback مجموعه توابعی هستند که در مراحل خاصی از فرآیند آموزش مدل اجرا میشوند. از توابع Callback میتوان برای شناخت حالات و آمار درونی مدل طی آموزش استفاده

تحولات دیجیتالی علیرغم گسترش کسبوکارها، چالشهایی را نیز شکل داده است. داستان دیپفیک چالش جدید دیگری است که سایۀ آن این سالها بر بسیاری از صنایع سنگینی میکند. در واقع چالش های دیپ فیک، پاشنه آشیل تحولات دیجیتال محسوب میشود. دیپفیک چیست؟ همانطور که از نامش پیداست، دیپفیک همان تصاویر،

یکی از باورهای مشترک در دنیای امروز و در حوزه کسب و کار این است که هوش مصنوعی قدرت ارائه مزایای رقابتی تعیینکنندهای دارد. در واقع 91% از مدیران سطح C که از هفتصد شرکت در نظرسنجی Forbes Insights شرکت کردند، موافقند که استفاده از هوش مصنوعی در کنار زدن
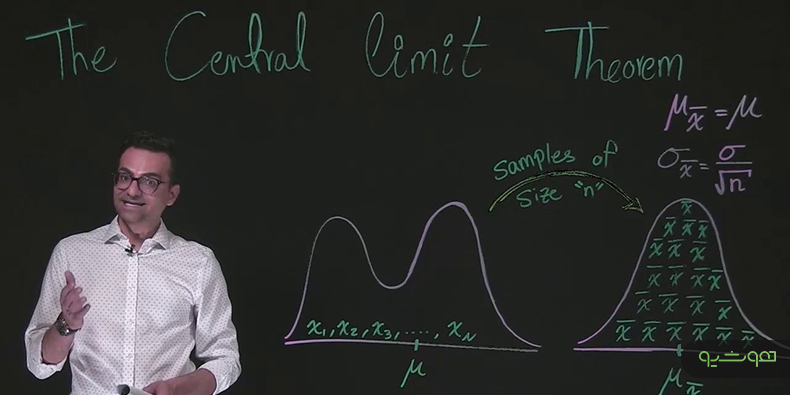
قضیه حد مرکزی Central Limit Theorem در کانون استنباط آماری Statistical inference قرار دارد که متخصصین علوم داده و تحلیلگران داده هر روز با آن سر و کار دارند. در مقاله پیشرو به مطالعه و بررسی قضیه حد مرکزی و چیستی آن میپردازیم؟ دلایل اهمیت آن چیست؟ قضیه حد مرکزی

نرخ دقت (Accuracy) معیار مهمی برای ارزیابی عملکرد مدل است، اما کافی نیست. از این روی، معیارهای دیگری برای ارزیابی عملکرد مدل و مسائل طبقه بندی معرفی شدهاند که به کمک آنها میتوانیم درک جامعتر و کلیتری نسبت به عملکرد مدل داشته باشیم. برخی از این معیارها عبارتند از: صحت،

بیتردید، GIT هدف غاییِ سیستمهای کنترل نسخه است. GIT عملکرد بسیار خوبی در تهیه نسخههای مختلف از کدهای منبع دارد. اما برخلاف مهندسی نرمافزار، پروژههای «علم داده» دارای فایلهای بسیار حجیمی مثل دیتاست، فایلهای مدل آموزش دیده، رمزگشایی برچسب و غیره هستند. اندازه این دست از فایلها میتواند تا چند

از آنجایی که بهترین راه برای یادگیری هر تکنولوژی جدید استفاده از آن در حل یک مسئله ساده است، برای یادگیری PyTorch از آن در حل یک مسئله ساده استفاده میکنیم. استفاده از یک شبکه عصبی از پیش آموزش دیده در مسئله تشخیص شیء. در این نوشتار، علاوه بر توضیح

چالش داده های مناسب در یادگیری ماشینی، از مهمترین چالشهای ارائه دهندگان این خدمات است. راهحلهای یادگیری ماشین به طور فزاینده ای توسط مشاغل در سراسر جهان مورد بررسی قرار میگیرند تا به آنها کمک کند بر مشکلات تجاری غلبه کنند و راهحلهای نوآورانه برای دستیابی به دادههای صحیح و

چند روز پیش در حال نوشتن مقالهای بودم که به استفاده از فضای رنگی Color spaces متفاوت به عنوان ورودی شبکه های عصبی پیچشی (CNN) میپرداخت و به همین دلیل لازم بود از یک مولد داده برای داده افزایی تصویری استفاده کنم؛ چون نمیتوانستم از مولد داده داخلی تنسورفلو بدین

IDE یا محیط توسعه یکپارچه Integrated Development Environment ابزاری است که امکانات اساسی لازم برای برنامهنویسی را بهصورت یکجا در اختیار برنامهنویس قرار میدهد. اگر IDE نبود برنامهنویسها مجبور بودند نوشتن، تست کردن و عیبیابی کدها (Debugging) را بهصورت جداگانه در برنامههای مختلف انجام دهند. با این توضیح مشخص میشود

در حال حاضر دسترسی پراکنده و متناقض به داده های شهری، باعث شده است تا تلاشها برای مدیریت منصفانه و مؤثر در شهرها با مشکل مواجه شود. اما این مشکل به کمک هوش مصنوعی قابل حل است.

هیچ شکی نیست که یادگیری عمیق تحولات زیادی در جنبههای مختلف زندگی شخصی و حرفهای ما بهوجود آورده است. در مقاله پیش رو میخواهیم به موضوع یادگیری عمیق در دستگاه های تعبیه شده بپردازیم. یادگیری عمیق در مقایسه با علم سنتی یادگیری ماشین، دقت و تطبیقپذیری بیشتری دارد و به

داده کاوی برای موفقیت هر سازمان، تجارت و کسبوکاری ضروری است. از مراقبتهای بهداشتی و پزشکی گرفته تا خرده فروشیهای ریز و درشت و صنایع هوافضا؛ تقریباً همه رشتهها میتوانند از داده کاوی بهره ببرند و با کمک آن به سود برسند. بر اساس مقاله «کشف کنید داده کاوی چگونه

در هر سازمانی روزانه حجم زیادی از دادههای صوتی تولید میشوند. اگر این دادههای صوتی برای راهاندازی موتورهای هوش مصنوعی، انواع سیستم تشخیص گفتار و تجزیهوتحلیل در اختیار متخصص علم داده قرار گیرند، میتوانند اطلاعات راهبردی مهمی تولید کنند. سازمانهایی که به قدرت و اهمیت اطلاعات حاصل از دادههای صوتی

سازندگان Eleuther ابراز امیدواری کردهاند که این محصول میتواند یک جایگزین متن باز برای GPT-3 باشد. لازم به ذکر است که GPT-3 یکی از نرمافزارهای مشهور زبانِ OpenAI میباشد.

تعمیرات و نگهداری پیش گویانه حاصل از تلفیق اینترنت اشیاء و هوش مصنوعی میتواند کاربرد بسیار کارآمدی داشته باشد. تعمیرات و نگهداری پیش گویانه Predictive maintenance در پنج سال گذشته رشد و توسعه چشمگیری را تجربه کرده و بازگشت سرمایه بالایی به همراه داشته است. این تحولات نشان از قدرت

کاراکتر هال (HAL) را به خاطر دارید؟ او همان کامپیوتر خبیث در فیلم سال 1968 استنلی کوبریک، 2001: ادیسه فضایی، بود که کنترل سیستمهای سفینه فضایی را به دست گرفت. برای بسیاری از ما، این اولین نما از تعامل هوش مصنوعی و اینترنت اشیاء (Internet of Things) بود، که البته

فرض میکنیم یک مدل یادگیری ماشینی (ML) آموزش دادهاید. همه مراحل را نیز به درستی انجام دادهاید. مدل شما از دقت و ثبات بسیار خوبی برخوردار است و میتواند عملکردی بهتر از مدل خطی برجای بگذارد. شما حتی مدلتان را در جعبه «Docker» قرار دادهاید و همه ابزارها و وابستگیهای

درب کاپوت اتومبیلهای مدرن را که باز میکنید، به جای مجموعهای از قطعات مکانیکی و متحرک روغنی، چیزی شبیه به کامپیوتری بزرگ و سیاه میبینید. تکامل خودرو وارد عصر جدیدی شده است. اتومبیل ساده شما دارد، به دستگاهی هوشمند تبدیل میشود که مانند دیگر وسایل هوشمند، فناوری تشخیص گفتار جزء

در مقالات آموزشی قبل به معرفی الگوریتمهای یادگیری ماشین بانظارت و آن دسته از روشهای توسعه مدل پرداختیم که در آنها از دادههای برچسبدار استفاده میشود. به بیانی دیگر در این دسته از روشها، دادهها دارای تعدادی متغیر هدف Target variable با مقادیر مشخص هستند که از آنها برای آموزش

اگر دیتاستتان در Hub نباشد، چه رویکردی در پیش میگیرید؟ میدانید که برای دانلود دیتاستها چگونه از Hugging Face Hub استفاده کنید. اما اغلب با دادههایی سر و کار دارید که یا در لپتاپتان یا در سرور از راه دوری ذخیره شدهاند. در بخش حاضر، نحوهی استفاده از ? Datasets

مزایای علم داده و تجزیه و تحلیل آنها هر روزه به کسبوکارها کمک میکنند، تا کارایی خود را افزایش دهند، بهتدریج نگرشهای کاربردی عمیقتری به دست آورند و در نهایت درآمد بیشتری کسب کنند. با این حال، تأثیر علم داده فراتر از بخش کسبوکار است و به حل برخی از

فصل چهارم از دوره آموزشی پردازش زبان طبیعی با اکوسیستم هاگینگ فیس به پایان رسید و نوبت به آزمون پایانی رسید که در ادامه با سوالات آن مواجه خواهد شد. به زودی با فصل آینده این دوره آموزشی در خدمت شما خواهیم بود. اما ابتدا اندوختههای خود از این فصل

برای آن که جایگاه و کارکرد رشته دیتا ساینس در ایران را بررسی کنیم و بفهمیم دیتا ساینس یا علم داده چیست، ابتدا باید به چیستی این دانش بپردازیم و سپس جایگاه و کارکرد آن را از گوشههای مختلف مورد بررسی قرار دهیم. در سالهای گذشته جامعه جهانی با انفجار

هدف ما در استفاده از هوش مصنوعی، کشف مکانیسمهای سازگاری در یک محیط در حال تغییر با استفاده از هوش است، بهعنوان مثال در توانایی حذف راه حلهای بعید. روشهای هوش مصنوعی کاربرد گستردهای در زمینههای مختلف مانند پزشکی، بازی، حمل و نقل یا صنایع سنگین دارد. این مقاله به

شبکههای عصبی پیچشی یا CNN خانوادهای از معماریهای شبکه عصبی مصنوعی هستند که ویژه مسائل بینایی کامپیوتری و پردازش تصویر ساخته شدهاند. این شبکهها، عصبی و چندلایهای هستند و هدف از ساخت آنها تجزیه و تحلیل ورودیهای دیداری و اجرای مسائلی همچون قطعهبندی تصویر، ردهبندی، حذف نویز (با استفاده از

Pandas یک کتابخانه پایتون همه منظوره و قدرتمند است و عمدتاٌ در تحلیل داده کاربرد دارد و فرایند تحلیل و کشف دادهها را تسریع میبخشد. یکی از مزایای Pandas در این است که برای انجام یک مسئله چندین روش مختلف ارائه میدهد. در طول فرایند تحلیل داده همیشه مجبور میشویم

به جرات میتوان گفت که کارت مدل Model Card به لحاظ اهمیت با فایلهای مدل و توکنکننده یکسان است. کارت مدل میتواند قابلیت استفادهی مجدد اعضاء و تکرار نتایج را تضمین کند. افزون بر این، پلتفرم مفیدی به واسطهی آن ایجاد میشود که سایر اعضا میتوانند آرتیفکت خودشان را در آن

در راهحلهای یادگیری ماشین، به ندرت به مسئله مدلسازی و آزمایش مدل پرداخته میشود. مدیریت و خودکارسازیِ چرخه عمر مدلهای یادگیری ماشین (از آموزش گرفته تا بهینهسازی) دشوارترین مسئله در حوزه یادگیری ماشین برشمرده میشود. دانشمندان داده به منظور کنترل چرخه حیات مدل باید قادر به بررسی وضعیت آن در

کتابخانه های نرم افزاری که امروزه برای یادگیری ماشینی استفاده میشوند، نقش بسیار مهمی در موفقیت تحقیقات ما دارند. باید کتابخانه های نرم افزاری با چنان سرعتی بهروزرسانی شوند که تحقیقات یادگیری ماشینی از قافله عقب نماند و به پیشرفت خود ادامه دهد.

آسانترین روش برای اشتراکگذاری مدل از پیش آموزش داده شده این است که از Hugging Face Hub استفاده کنید. ابزارها و امکانات موجود میتواند بستر مناسبی برای اشتراکگذاری و بهروزرسانیِ مستقیم مدلها در Hub فراهم کند. جزئیات آن در بخشهای بعدی مقاله توضیح داده خواهد شد. مشوقهای لازم در اختیار

آیا شما نیز یکی از میلیونها برنامهنویس پایتون هستید که به دنبال کتابخانهای قدرتمند برای یادگیری ماشین میگردند؟ اگر چنین است، باید کتابخانه سایکیت لرن Scikit-Learn را بشناسید. سایکیت لرن در دنیای پایتون نقش مهمی در حوزه یادگیری ماشین دارد و آشنایی با آن برای دریافت مدرک علوم داده ضروری

با رشد اینترنت در دهه ۱۹۹۰ و در دسترس قرار گرفتن مجموعههای زیادی از تصاویر به صورت آنلاین برای تجزیه و تحلیل، مدلهای بینایی ماشین رونق گرفت. همچنین، پیشرفتهای سختافزاری در کنار مجموعهدادههای در حال رشد، باعث شد ماشینها بتوانند اجسام متنوعی را در عکسها و فیلمها شناسایی کنند. در

فناوری هوش مصنوعی امروزه بیش از هر زمان دیگری به خودکار کردن فرآیندهای متنوع در تولید و امور دیگر کمک میکند. یک نظرسنجی که اخیرا توسط Landing AI و Association of Advancing Manufacturing انجام شده نشان میدهد که ۲۶ درصد از کسب و کارهای تولیدی در حال حاضر از سیستم

نسخههای متعددی از «کوبرنتیس» پیشپیکربندی شده وجود دارد که از جمله مهمترینِ آنها میتوان به «Minikube» و «Microk8s» اشاره کرد. مقاله حاضر بر آن است تا فرایند نصب و راهاندازی را از ابتدا توضیح دهد و جزئیات بیشتری را در اختیار خوانندگان قرار دهد. کوبرنتیس یکپارچه نیست و اجزای متعددی

مدلهای یادگیری عمیق برای آموزش به حجم بالایی از دادهها نیاز دارند و به دلیل پیچیدگیهای حافظه Space complexitites عملکرد ضعیفی دارند. انواع تولیدکننده داده برای رفع این مشکل، به جای اینکه دیتاست را در حافظه ذخیره کند، دادهها را در بسته تولید میکنند. در این حالت کاربر میتواند استفاده

انتخاب مدل مناسب با Model Hub به مراتب آسانتر میشود. بنابراین، با چند خط کد میتوان از آن در کتابخانه استفاده کرد. حال، باید دید این مدلها چگونه به کار برده میشوند. فرض کنید به دنبال مدل زبان فرانسوی هستیم که عمل mask filling را انجام میدهد. انجام این کار،

رویکرد جدید «عقل سلیم» به بینایی کامپیوتر، هوش مصنوعی را قادر میسازد که نسبت به دیگر سیستمها، صحنهها را با دقت بیشتری تفسیر کند. سیستمهای بینایی ماشین، گاهی از مواقع صحنهها را دقیقاً بر خلاف عقل سلیم استتناج میکنند. بهعنوان مثال، اگر رباتی در حال پردازش تصویر میز شام باشد،
