
معرفی معیار جدید OpenAI برای ارزیابی تواناییهای تحقیقاتی عوامل هوش مصنوعی
 تیم تحریریه
تیم تحریریه- ۱۷ فروردین ۱۴۰۴
OpenAI معیار جدیدی به نام PaperBench معرفی کرده است که هدف آن اندازهگیری توانایی عوامل هوش مصنوعی در بازتولید تحقیقات پیشرفته هوش مصنوعی است. این آزمون بررسی میکند که آیا یک هوش مصنوعی میتواند مقالات علمی را درک کند، کدهای مرتبط را بنویسد و آنها را اجرا کند تا نتایج ذکرشده در مقاله را بازتولید کند.
PaperBench چیست؟
این معیار از ۲۰ مقاله برتر کنفرانس بینالمللی یادگیری ماشین (ICML) سال ۲۰۲۴ استفاده میکند که شامل ۱۲ موضوع مختلف است. این مقالات تحقیقاتی شامل ۸,۳۱۶ وظیفه قابل ارزیابی بهصورت جداگانه هستند. برای ارزیابی دقیقتر، سیستم ارزیابی Rubric توسعه داده شده است که هر وظیفه را بهصورت سلسلهمراتبی به زیروظایف کوچکتر تقسیم میکند و معیارهای ارزیابی مشخصی برای آنها ارائه میدهد. این سیستم با همکاری نویسندگان هر مقاله ICML برای حفظ دقت و واقعگرایی توسعه داده شده است.
در این آزمون، هوش مصنوعی باید جزئیات لازم را از مقاله استخراج کرده و تمام کدهای مورد نیاز برای بازتولید مقاله را در یک مخزن (repository) ارائه دهد. همچنین، هوش مصنوعی باید اسکریپتی به نام reproduce.sh ایجاد کند که به اجرای کدها کمک کرده و نتایج مقاله را بازتولید کند.
ارزیابی توسط قاضی هوش مصنوعی
تمام این فرایند توسط یک قاضی هوش مصنوعی ارزیابی میشود. OpenAI ادعا میکند که این قاضی به اندازه یک انسان دقیق عمل میکند. در مقاله تحقیقاتی ذکر شده است: «بهترین قاضی مبتنی بر مدل LLM ما که از o3-mini-high با ساختار سفارشی استفاده میکند، در ارزیابی کمکی به امتیاز F1 معادل ۰.۸۳ دست یافته است، که نشان میدهد این قاضی جایگزین مناسبی برای یک قاضی انسانی است.»
نتایج اولیه
چندین مدل هوش مصنوعی در PaperBench مورد آزمایش قرار گرفتند. بهترین عملکرد متعلق به مدل Claude 3.5 Sonnet از شرکت Anthropic بود که توانست امتیاز بازتولید ۲۱.۰٪ را کسب کند. سایر مدلها، از جمله o1 و GPT-4o از OpenAI، Gemini 2.0 Flash و DeepSeek-R1، امتیازهای پایینتری کسب کردند.
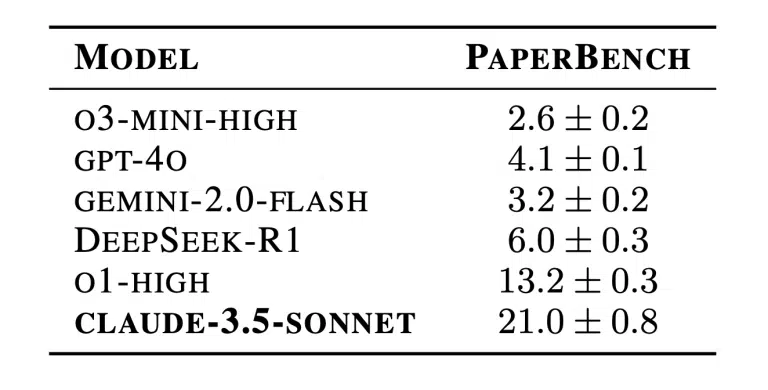
در مقایسه، دانشجویان دکتری (PhD) در حوزه یادگیری ماشین به طور میانگین امتیاز ۴۱.۴٪ کسب کردند، که نشاندهنده فاصله قابلتوجه بین تواناییهای فعلی هوش مصنوعی و تخصص انسانی است.
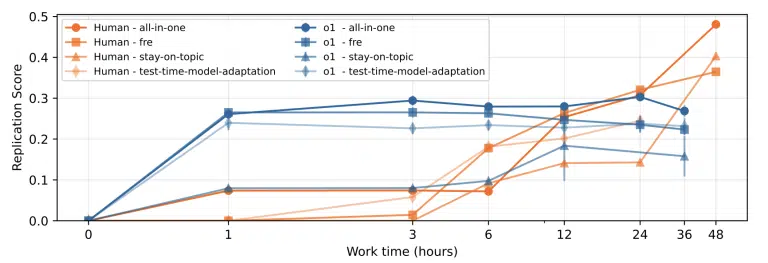
آزمون طولانیمدت
یک آزمون جداگانه نیز با مدل o1 از OpenAI برای مدت زمان طولانیتری انجام شد، اما این مدل همچنان نتوانست به سطح تلاش انسانی برسد.
دسترسی عمومی
کد PaperBench اکنون برای عموم در GitHub در دسترس است. نسخه سبکتر این معیار، به نام PaperBench Code-Dev نیز منتشر شده است تا افراد بیشتری بتوانند از آن استفاده کنند.





