راهنمای تصویری برای فهم نقش دما در مدلهای زبانی بزرگ
رمزگشایی پارامتر دما در مدلهای زبانی بزرگ
 امین رضا کیفرگیر
امین رضا کیفرگیر- ۱۹ مرداد ۱۴۰۴
یک مدل زبانی بزرگ، مانند GPT-3.5، بر روی حجم عظیمی از دادههای متنی آموزش دیده است که به آن امکان میدهد متنهایی شبیه به انسان تولید کند و الگوهای پیچیده زبانی را درک نماید. قابلیت پایهای آن به عنوان پیشبینیکنندهی کلمه بعدی، این امکان را میدهد که محتملترین کلمه یا عبارت را که پس از یک زمینه مشخص میآید، بر اساس الگوها و ساختارهایی که از دادههای آموزشی خود یاد گرفته، پیشنهاد دهد.
مدلهای زبانی پیشبینیکنندههای قدرتمندی برای کلمه بعدی هستند. تنظیم پارامتر دما اهمیت زیادی دارد چون به تعیین احتمال انتخاب گزینههای مختلف برای کلمه بعدی کمک میکند. بیشتر مدلهای زبانی دامنه دمایی بین ۰ تا ۱ دارند.
شاید بارها خواندهاید که دمای صفر یعنی تعیینپذیر (deterministic) و دمای ۱ یعنی غیرتعیینپذیر یا خلاقانه(non-deterministic/creative)، اما آیا میدانید چرا و چگونه؟
بررسی یک مثال
بیایید با یک مثال این موضوع را بررسی کنیم؛
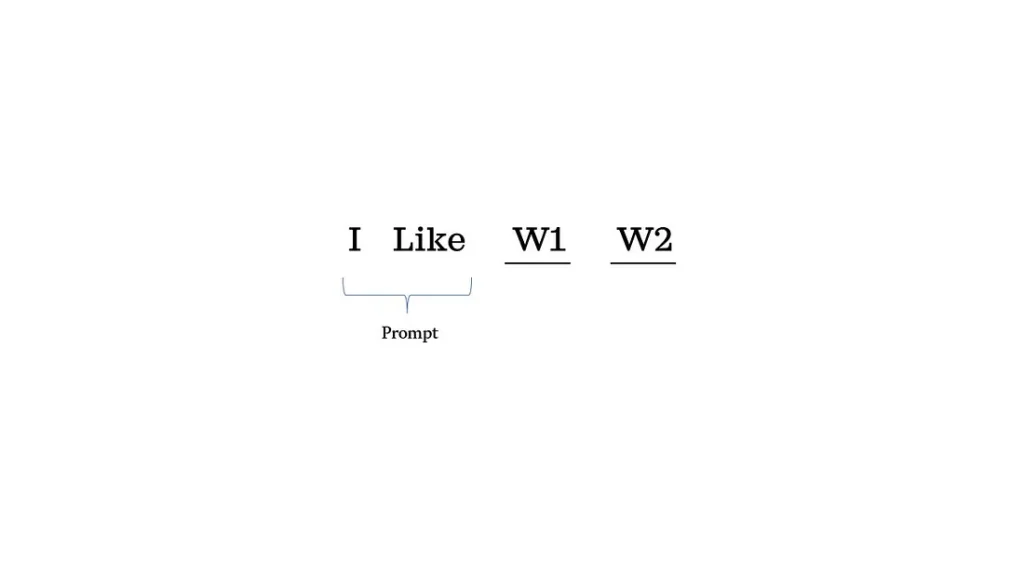
ما پرامپت «I like» را به مدل زبانی بزرگی دادهایم و انتظار داریم مدل دو کلمه بعدی یعنی w1 و w2 را پیشبینی کند.
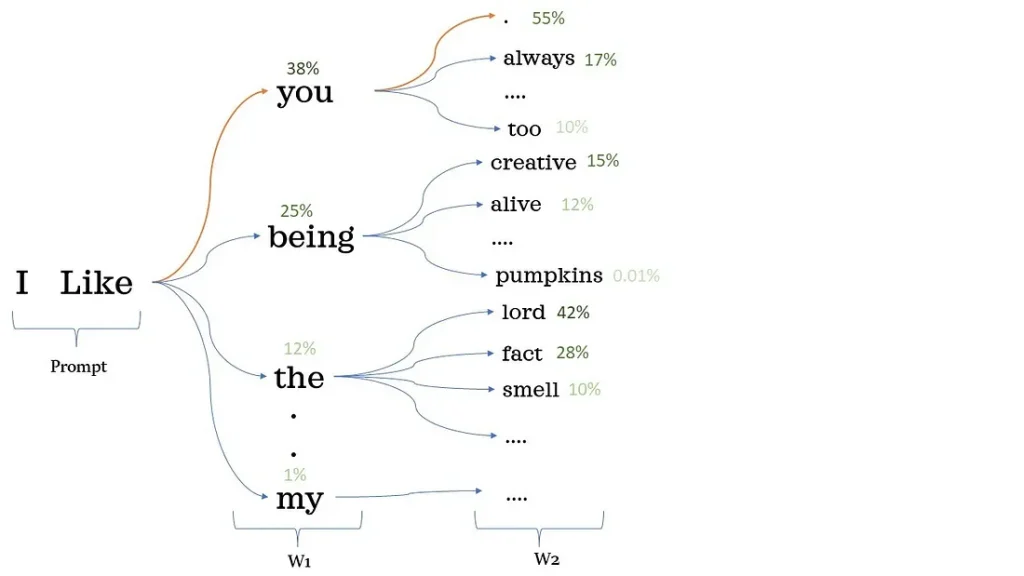
کلمات احتمالی بعدی برای مدل زبانی با توجه به چند کلمه اول «I like» و توزیع احتمالاتی که در مرحله آموزش ایجاد شده است:
احتمال ظاهر شدن کلمه (توکن) «you» پس از «I like» برابر با ۳۸٪ است.
احتمال ظاهر شدن نشانه «.» پس از «I like you» برابر با ۵۵٪ است.

دمای برابر با صفر
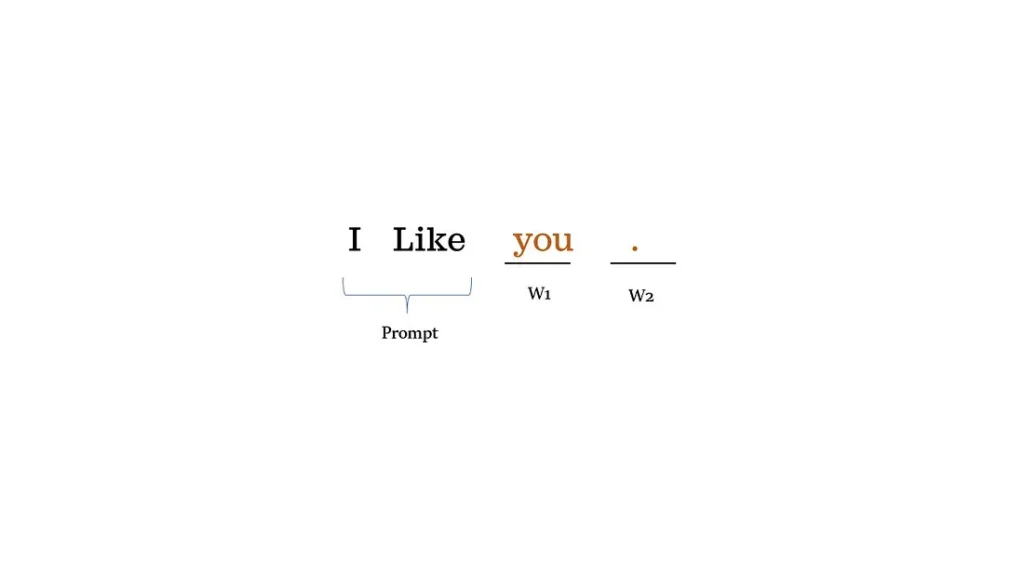
اگر هنگام استنتاج (inference) دما را صفر انتخاب کنید، مدل همیشه کلمه بعدی با بیشترین احتمال را انتخاب میکند که این باعث میشود مدل تعیینپذیر (deterministic) باشد. با پرامپت «I like»، تکمیل جمله همیشه «I like you.» خواهد بود و در انتخاب کلمه بعدی هیچ تصادفی وجود ندارد.
دمای بزرگتر از صفر
اگر هنگام استنتاج دما را بزرگتر از صفر انتخاب کنید، مدل به صورت تصادفی کلمه بعدی را انتخاب میکند که این باعث میشود مدل غیرتعیینپذیر (non-deterministic) یا خلاقانه باشد. با پرامپت «I like»، تکمیل جمله میتواند «I like being pumpkins» یا «I like the lord» باشد. در انتخاب کلمه بعدی درجهای از تصادفی بودن دخیل است.

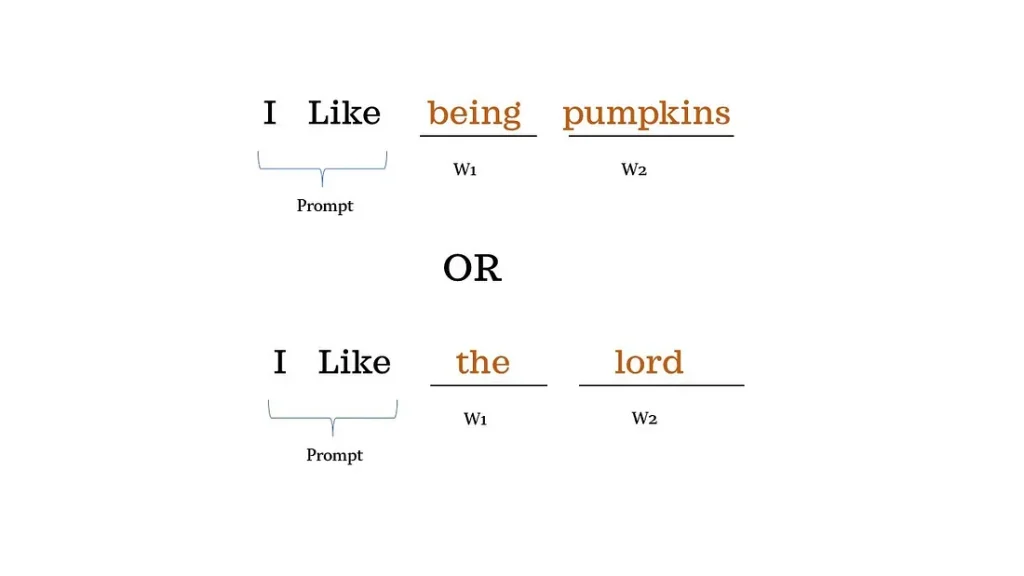
تغییر کوچک در پرامپت، خروجی را به شدت تغییر میدهد
فرض کنید پرامپت را از «I like» به «I like being» تغییر دهید. انتخاب کلمات بعدی به طور قابل توجهی تغییر میکند. این دقیقاً دلیلی است که باید پرامپتها را نسخهبندی کنیم. میتوانید این موضوع را مانند ابرپارامتر (hyperparameter) در الگوریتمهای یادگیری ماشین سنتی در نظر بگیرید که تغییر کوچک در آن میتواند نتیجه را به شدت تغییر دهد.