
نیاز مبرم به گسترش هوش مصنوعی
 تیم تحریریه
تیم تحریریه- ۱۸ آذر ۱۴۰۳
وقتی مدلهای مبتنی بر ترنسفورمرها معرفی شدند، تحول بزرگی در دنیای هوش مصنوعی ایجاد شد. اما در این بین یک مشکل مهم وجود داشت. وقتی یک مدل خیلی بزرگ میشد و محققان میخواستند فقط بخشی از آن را آموزش دهند، تنها راهحل این بود که کل مدل را از ابتدا آموزش دهند.
این موضوع یک چالش جدی بود، به همین دلیل برای حل آن، محققانی از گوگل، موسسه ماکس پلانک و دانشگاه پکن رویکرد جدیدی به نام TokenFormer معرفی کردند.
مدلهای دینامیک
ایده جدید این است که پارامترهای مدل بهجای ثابتبودن، مانند توکنها عمل کنند. این تغییر باعث میشود که مدل بتواند به طور دینامیک و منعطف با توکنهای ورودی تعامل داشته باشد و بهجای این که فقط از پیشبینیهای ثابت و خطی استفاده کند، از یک مکانیزم توجه (Attention) برای پردازش استفاده کند.
معماری سنتی ترنسفورمر وقتی به مقیاسهای بزرگتر میرسد، با یک چالش جدی روبهرو میشود. در واقع هنگام اعمال تغییرات معماری، مدل باید از صفر آموزش داده شود که این کار هزینههای محاسباتی بسیار بالایی دارد.
TokenFormer مشکل مقیاسپذیری را با معرفی لایه توجه به پارامترها (Pattention) حل کرده است. این لایه بدون آنکه نیاز به آموزش مجدد کامل باشد، امکان گسترش تدریجی مدل را فراهم میکند. همچنین این روش نتایج بسیار خوبی به همراه داشته است و توانسته مدلها را از 124 میلیون پارامتر به 1.4 میلیارد پارامتر گسترش دهد، در حالی که عملکرد آن مشابه مدلهایی است که از ابتدا آموزش دیدهاند.
یکی از کاربران Redit توضیح داد که این تحقیق امکان یادگیری تدریجی را فراهم میکند. به عبارت دیگر، تغییر اندازه مدل و اضافهکردن پارامترهای بیشتر به این معنی نیست که باید مدل را از ابتدا آموزش دهید.
او گفت: «مدل ما تنها یک دهم هزینههای آموزش مدلهای ترنسفورمر را نیاز دارد. برای مقابله با تأثیر دادههای آموزشی مختلف، ما عملکرد مدلی که از ابتدا آموزش داده شده و با همان منابع محاسباتی 30 میلیارد توکن آموزش دیده را هم بررسی کردیم.»
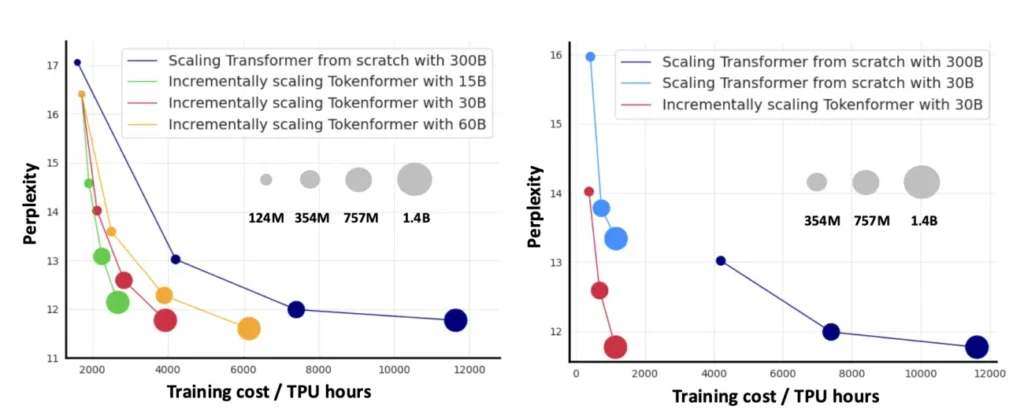
او اضافه کرد: «با استفاده از منابع مشابه، مدل مقیاسپذیر ما پریپلکسیتی 11.77 را به دست آورد، در حالی که مدل ترنسفورمر پریپلکسیتی 13.34 داشت. این نشاندهنده کارایی و مقیاسپذیری بهتر روش ما است.» در نهایت، او اشاره کرد که استفاده از TokenFormer هزینهها را به طور قابل توجهی کاهش میدهد.
چرا کارایی مقیاسپذیری مهم است؟
ویژگی برجسته TokenFormer، توانایی حفظ دانش موجود هنگام گسترش مدل است که رویکرد جدیدی در یادگیری مداوم ارائه میدهد. این ویژگی با تلاشهای صنعت برای بهبود کارایی مقیاسپذیری همراستا است. وقتی پارامترهای جدید از صفر شروع به کار میکنند، مدل میتواند توزیع خروجی خود را حفظ کرده و در عین حال ظرفیت اضافی را وارد کند.
این ویژگی در سناریوهای یادگیری مداوم بسیار ارزشمند است، جایی که مدلها باید بتوانند بدون اینکه اطلاعات قبلی را از دست بدهند، با دادههای جدید سازگار شوند. در عین حال، این معماری کارایی چشمگیری در کاربردهای عملی نشان داده است. TokenFormer در تستهای معیار، عملکردی مانند ترنسفورمرهای استاندارد نشان داد، در حالی که تنها یک دهم منابع محاسباتی را نیاز داشته است.
این کارایی در وظایف زبان و بینایی نیز قابل مشاهده است. مدل در ارزیابیهای مختلف از جمله ارزیابیهای بدون آموزش قبلی و وظایف دستهبندی تصاویر، عملکرد رقابتی از خود نشان داده است.
از اول شروع نکن
طراحی TokenFormer مزایای زیادی برای پردازش متون طولانی دارد که برای مدلهای زبان مدرن حیاتی است. در ترنسفورمرهای سنتی برخلاف TokenFormer، هرچه اندازه مدل بزرگتر میشود، هزینههای محاسباتی برای تعامل بین توکنها هم افزایش مییابد. در واقع با استفاده از TokenFormer این هزینهها ثابت میماند و حتی زمانی که پارامترهای مدل گسترش مییابند، هزینهها افزایش پیدا نمیکند.
این ویژگی باعث میشود TokenFormer برای پردازش توالیهای طولانی مناسبتر باشد. همچنین این قابلیت بهویژه در کاربردهای هوش مصنوعی امروزی که نیاز به پردازش دادههای طولانی و پیچیده دارند، اهمیت زیادی دارد.
یکی از کاربران ردیت درباره تحقیق TokenFormer گفته است: «آنها به نوعی سیستمی طراحی کردهاند که میتواند دانش را ذخیره کند و بدون اینکه به اطلاعات قبلی آسیبی وارد شود، به تدریج اطلاعات جدید را اضافه نماید. این میتواند واقعاً یک پیشرفت بزرگ باشد.»
در عین حال، در زمینه پیشرفتهای فنی که میتوانند مشکل مقیاسپذیری را حل کنند (همانند کاری که TokenFormer انجام داده) بحثهای زیادی در جریان است. در رویداد Microsoft Ignite 2024، «ساتیا نادلا»، مدیرعامل مایکروسافت، بر تغییر تمرکز اشاره کرد و گفت: «آنچه باید به خاطر بسپارید این است که اینها قوانین فیزیکی نیستند، بلکه مشاهدات تجربی هستند، مشابه قانون مور.»
ساتیا نادلا در این رویداد یک معیار جدید به نام «توکن به ازای وات و دلار» را برای سنجش کارایی هوش مصنوعی معرفی کرد و بر اهمیت بیشینه کردن ارزش تأکید کرد. «جِنسِن هوانگ»، مدیرعامل NVIDIA هم نگرانیهای مشابهی را مطرح کرد و فرآیند استنتاج (inference) را به دلیل نیاز به دقت بالا، تأخیر کم و توان پردازشی زیاد، «بسیار دشوار» توصیف کرد.
او گفت: «امید ما این است که در آینده، دنیا بتواند حجم زیادی از پردازشهای هوش مصنوعی را انجام دهد.» این صحبت نشان میدهد که نوآوریهایی مانند TokenFormer در مقیاسپذیری و پیشرفتهای آینده هوش مصنوعی اهمیت زیادی دارند.
آیا این ایده واقعاً درست است؟
چندین کاربر این ایده را برای واقعی بودن، بیش از حد خوب دانسته و برخی مشکلات را در مقاله تحقیقاتی مطرح کردهاند. یکی از کاربران در Hacker News گفت که اعتماد به اعداد ارائه شده در تحقیق دشوار است. او توضیح داد: «وقتی یک ترنسفورمر را برای مقایسه آموزش میدهند، همان نسخه اصلی GPT-2 را که در سال ۲۰۱۹ معرفی شد، بازسازی میکنند. در این فرآیند، سالها پیشرفتهای معماری مانند rotary positional embeddings، SwiGLU و RMSNorm نادیده گرفته شدند که در نهایت به Transformer++ منجر شد.»
از طرف دیگر، برخی کاربران در همان بحث این روش را تحسین کرده و گفتهاند که به نظر میرسد یک پیشرفت بزرگ باشد. یکی از آنها گفت: «فکر میکنم این میتواند امکان مدولار بودن و سازگاری بین مجموعه وزنهای مختلفی که به طور عمومی در دسترس هستند را فراهم کند، به شرطی که ابعاد کانالها مشابه باشند. شاید این روش یک چارچوب جدید برای فکر کردن درباره تنظیم دقیق مدل هم ارائه دهد، جایی که میتوان از روشهای خاص برای اضافهکردن یا حذف دادهها در لایههای Pattention استفاده کرد.»
همچنین یکی از کاربران گفت که طبق این مقاله، مدل میتواند به راحتی با اضافهکردن ردیفهای جدید (جفتهای کلید و مقدار) به ماتریسهای خاصی مانند K و V در لایههای توجه، به طور پویا گسترش پیدا کند. ردیفهای ابتدایی ممکن است اطلاعات پایه و مهمتری داشته باشند، در حالی که ردیفهای بعدی جزئیات خاصتر و کماهمیتتر را اضافه میکنند.
اگرچه این روش در تئوری امیدوارکننده است، اما باید منتظر بمانیم تا توسعهدهندگان آن را در مدلهای واقعی پیادهسازی کنند.





