آشنایی با روش تقطیر دانش جهت بهبود عملکرد مدلهای یادگیری عمیق
 تیم تحریریه
تیم تحریریه- ۱۱ مرداد ۱۴۰۰
تا کنون مدلهای پیچیدهای ساختهایم که قادر به انجام وظایف و حل مسائل پیچیده هستند، اما چالشی که اکنون با آن روبرو هستیم این است که چطور میتوانیم چنین مدلهای سنگینی را برای استفادهی فوری روی دستگاههای موبایل پیاده کنیم؟ شاید بتوانیم مدل را روی ابر به کار انداخته و هر زمان که لازم بود آن را فرا بخوانیم. اما این روش هم نیازمند اتصال اینترنتی قوی است و به همین دلیل با محدودیت مواجه میشود. پس به بیان خلاصه نیاز به مدلی داریم که روی دستگاههای موبایل قابل اجرا باشد.

مشکل کجاست؟ آیا میتوانیم شبکهی کوچکی آموزش دهیم که روی توان محاسباتی محدود گوشی همراه قابل اجرا باشد؟ این روش یک مشکل دارد: مدلهای کوچک قادر نیستند ویژگیهای خیلی پیچیدهای را استخراج کنند که برای برخی پیشبینیها لازم هستند؛ مگر اینکه یک الگوریتم فوقالعاده کارآ بسازید که به حافظهی خیلی کمی نیاز دارد. مجموعهای از مدلهای کوچک هم میتوانند نتایج قابل قبولی ارائه دهند؛ اما انجام پیشبینی با استفاده از چندین مدل کار سنگینی بوده و از نظر محاسباتی آنقدر پرهزینه است که بسیاری از کاربران توان استفاده از آن را نخواهند داشت. به همین دلیل در این نوشتار به دو تکنیک دیگر خواهیم پرداخت:
- تقطیر دانش
- متراکمسازی مدل Model compression
(در این نوشتار به تقطیر دانش میپردازیم و بحث متراکمسازی مدل را به وقت و مطلب دیگری موکول خواهیم کرد.)
تقطیر دانش
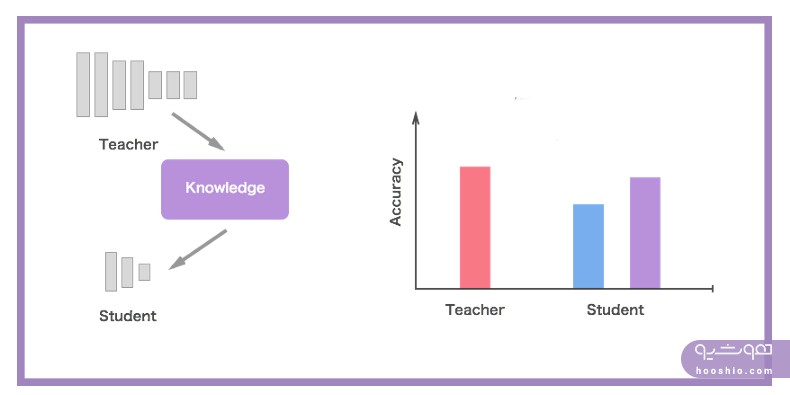
تقطیر دانش روشی ساده برای بهبود عملکرد مدلهای یادگیری عمیق روی دستگاههای موبایل است. در این فرآیند یک شبکهی بزرگ و پیچیده یا یک مدل گروهی آموزش میدهیم که میتواند ویژگیهای مهم دادهها را استخراج کرده و پیشبینیهای خوبی انجام دهد. سپس به کمک این مدل سنگین Cumbersome model، شبکهای کوچک را آموزش میدهیم. این شبکهی کوچک قادر خواهد بود نتایجی در حد قابل مقایسه (با مدل سنگین) ارائه دهد و در برخی موارد هم میتواند همان نتایج شبکهی سنگین را تولید کند.

برای مثال GoogLeNet شبکهای بسیار سنگین، یعنی عمیق و پیچیده است. عمقش به آن توان استخراج ویژگیهای پیچیده را میدهد و پیچیدگیش به حفظ دقت کمک میکند. این مدل آنقدر سنگین است که برای پیادهسازی به حجم زیادی حافظه، یک GPU قدرتمند و محاسبات پیچیده نیاز خواهد داشت. به همین دلیل باید بتوانیم دانش این مدل را به یک مدل بسیار کوچکتر منتقل کنیم که قابلیت استفاده در یک دستگاه موبایل را دارد.
[irp posts=”18831″]نکاتی در مورد مدلهای سنگین
مدلهای سنگین یاد میگیرند تا بین تعداد زیادی از دسته ها تمایز قائل شوند. هدف اصلی در آموزش , به حداکثر رساندن متوسط احتمال لگاریتمی Average log probability پاسخ درست است و بدین منظور, مدل به هر دسته یک احتمال اختصاص میدهد (احتمال برخی طبقات از بعضی دیگر کوچکتر است). مقادیر نسبی احتمالات مربوط به پاسخهای اشتباه اطلاعات زیادی در مورد نحوهی تعمیمپذیری این مدل پیچیده در اختیار ما میگذارند. مثلاً تصویر یک ماشین به احتمال کمی به عنوان کامیون شناخته خواهد شد، اما احتمال وقوع همین اشتباه از احتمال تشخیص یک گربه (به جای ماشین) خیلی بیشتر است.
توجه داشته باشید که انتخاب تابع هدف Objective function باید به نحوی باشد که به خوبی به دادههای جدید تعمیم داده شود. پس زمان انتخاب تابع هدف مناسب باید به خاطر داشته باشیم قرار نیست این تابع روی دادههای آموزشی عملکردی بهینه داشته باشد.
از آنجایی که این عملیات برای دستگاههای موبایل بسیار سنگین است، باید دانش این مدلهای سنگین را به یک مدل کوچکتر انتقال دهیم که به آسانی روی دستگاههای موبایل به کار برده شود. بدین منظور میتوانیم مدل سنگین را شبکهی معلم Teacher network و مدل کوچک را شبکهی دانش در نظر بگیریم.
معلم و دانشآموز
میتوانید شبکهی بزرگ و پیچیده را به شبکهای بسیار کوچکتر تقطیر کنید؛ این شبکهی کوچکتر تابع اصلی را که توسط شبکهی عمیق آموخته شده، به خوبی برآورد میکند.

یک نکته اینجا وجود دارد و آن این است که مدل تقطیرشده (دانشآموز) به نحوی آموزش دیده که به جای آموزش مستقیم روی دادههای خام، خروجی شبکهی بزرگتر (معلم) را تقلید کند؛ شاید به این خاطر که شبکهی عمیقتر انتزاعات سلسله مراتبی ویژگیها را میآموزد.
این انتقال دانش چطور انجام میشود؟
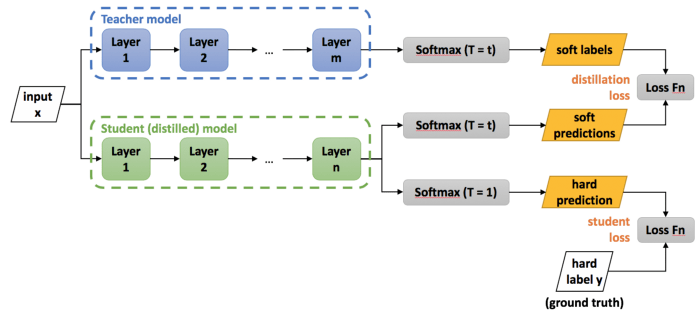
با استفاده از احتمالات تولید شده برای هر کلاس که با عنوان “اهداف نرم” توسط مدل سنگین و به منظور آموزش مدل کوچک تولید میشوند میتوان توانایی تعمیمپذیری مدل سنگین را به یک مدل کوچکتر انتقال داد. در مرحلهی انتقال میتوانیم همان مجموعهی آموزشی یا یک “مجموعه انتقال Transfer set” را برای آموزش مدل سنگین به کار ببریم. وقتی مدل سنگین مجموعهای از مدلهای سادهتر باشد میتوانیم از میانگین حسابی Arithmetic mean یا هندسی توزیعهای پیشبین هر یک از آن مدلها به عنوان اهداف نرم استفاده کنیم. زمانی که آنتروپی اهداف نرم بالا باشد، برای آموزش هر مورد اطلاعات بسیار بیشتر و واریانس خیلی کمتری بین آنها ارائه میدهند (در مقایسه با اهداف سخت). بنابراین مدل کوچک میتواند روی دادههای بسیار کمتری از آنچه مدل سنگین نیاز دارد، آموزش ببیند و در عین حال به نرخ یادگیری Learning rate بالاتری دست یابد.

بیشتر اطلاعاتی که در مورد تابع آموخته شده وجود دارد در نسبتهایی از احتمالات بسیار کوچک در اهداف نرم باقی میماند. این اطلاعات ارزشمند هستند و ساختار شباهت Similarity structure موجود در دادهها را نشان میدهند (که برای مثال میگوید کدام 2 شبیه 3 و کدام شبیه 7 به نظر میرسد یا کدام نژادهای سگ به هم شباهت دارند)، اما تأثیر بسیار کمرنگی روی تابع هزینهی آنتروپی متقاطع Cross-entropy cost function طی مرحلهی انتقال دارند، زیرا مقادیر احتمالات به صفر خیلی نزدیک هستند.
[irp posts=”22941″]تقطیر
به منظور تقطیر دانش آموخته شده، از تابع logit (ورودیهای لایهی نهایی بیشینههموار) استفاده میکنیم. با به حداقل رساندن مجذور تفاوتها بین logit-هایی که مدل سنگین و logit-هایی که مدل کوچک تولید کردهاند، میتوانیم از logit-ها برای یادگیری مدل کوچک استفاده کنیم.

برای دماهای بالا (T -> inf) همهی اقدامات, احتمال تقریباً یکسانی دارند و در دماهای پایینتر (T -> 0)، پاداشهایی که بیشتر موردانتظار هستند بر احتمال تأثیر میگذارند. در مقادیر پایینِ پارامتر دما، احتمال اقدام با بالاترین پاداش موردانتظار نزدیک 1 است.
در تقطیر، دمای لایهی نهایی بیشینههموار را افزایش میدهیم تا جایی که مدل سنگین مجموعهی مناسبی از اهداف نرم را تولید کند. سپس همین دمای بالا را زمان آموزش مدل کوچک به کار میبریم تا با این اهداف نرم سازگار شود.
تابع هدف
اولین تابع هدف، آنتروپی متقاطع با اهداف نرم است. این آنتروپی متقاطع با استفاده از دمای بالای لایهی بیشینههموارِ مدل تقطیرشده یا دانشآموز (همانطور که برای تولید اهداف نرم در مدل سنگین نیز مورد استفاده قرار گرفت) محاسبه میشود.
دومین تابع هدف از آنتروپی متقاطع با برچسبهای صحیح به وجود میآید و با استفاده از دقیقاً همان توابع logit در لایهی بیشینههموار مدل تقطیرشده (اما در دمای 1) محاسبه میگردد.

مجموعههای آموزشی متخصصها
آموزش گروهی مدلها راه بسیار آسانی برای بهرهگیری از محاسبات موازی Parallel computation است. اما به محاسبات بیشاز حد این گروه (مدلها) در زمان آزمایش انتقاداتی وارد میکنند. با تکنیک تقطیر میتوان به سادگی این مشکل را نیز حل کرد.

مدلهای متخصص
مدلهای متخصص و یک مدل عمومی اجزای مدل سنگین ما را تشکیل میدهند. مدل عمومی روی همهی دادههای آموزشی، آموزش میبیند و مدلهای متخصص بر زیرمجموعهی درهمریخته و متفاوتی از ردهها تمرکز دارند؛ بدین ترتیب مقدار کل محاسبات لازم برای یادگیری گروهی کاهش مییابد. مشکل اصلی این است که مدلهای متخصص به آسانی در معرض بیش برازش قرار میگیرند. اما میتوان با استفاده از اهداف نرم از این بیش برازش جلوگیری کرد.
کاهش بیشبرازش در مدلهای متخصص
به منظور کاهش بیشبرازش و همچنین به اشتراکگذاری روند یادگیری تشخیصگرهای ویژگیهای سطح پایینتر، برای هر مدل متخصص وزنهای مدل عمومی تعریف میشود. سپس با آموزش مدل متخصص، این وزنها تا حدی اصلاح میشوند. در آموزش مدل متخصص نیمی از نمونهها از زیرمجموعهی خاص خودش گرفته شده و نیم دیگر به صورت تصادفی از بقیهی مجموعهی آموزشی نمونهگیری میشوند. بعد از آموزش میتوانیم آموزش سوگیرانه Biased training را با افزایش تابع logit ردهی dustbin (به وسیلهی لگاریتم سهمی که ردهی متخصص با آن بیشنمونهگیری میشود) اصلاح کنیم.

تخصیص رده به مدلهای متخصص
یک الگوریتم خوشهبندی روی ماتریکس همبستگی Covariance matrix پیشبینیهای مدل عمومی اجرا میکنیم تا مجموعهای از ردهها یا Sm (که اغلب با هم پیشبینی میگردند) به عنوان اهداف یکی از مدلهای متخصص استفاده شوند. بدین ترتیب روش خوشهبندی K-means را روی ستونهای ماتریکس کوواریانس اجرا میکنیم تا خوشهها یا ردههای موردنیاز را به دست بیاوریم.

خوشهبندی کوواریانس/همبستگی روشی برای خوشهبندی مجموعهای از اشیاء در تعداد بهینهای از خوشهها (بدون از پیش تعیین کردن تعداد دقیق آنها) ارائه میدهد.
[irp posts=”7552″]اجرای استنتاج
- برای هر مورد آزمایشی، n رده که (براساس مدل عمومی) بیشترین احتمال را دارند، پیدا میکنیم. این مجموعه از ردهها را k مینامیم.
- سپس همهی مدلهای متخصصی (m) را که زیرمجموعهیشان از ردههای درهمریخته (Sm) با k، تعاملی غیرتهی دارد مشخص کرده و آن را Ak مینامیم (توجه داشته باشید که این مجموعه میتواند تهی باشد). سپس توزیع کامل احتمال q را برای همهی این ردهها پیدا میکنیم. بدین ترتیب فرمول پایین به حداقل میرسد:
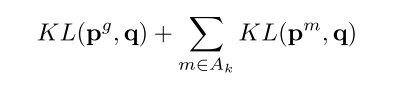

در این فرمولها، KL واگرایی KL، و توزیع احتمال یک مدل متخصص (m) یا عمومی (g) را نشان میدهد. توزیع مربوط به همهی ردههای متخصص m به اضافهی یک ردهی dustbin است. بنابراین زمانی که واگرایی KL از توزیع کامل q را محاسبه میکنیم، همهی احتمالاتی که توزیع کامل q به همه ردههای dustbin m اختصاص داده را با هم جمع میکنیم.
اهداف نرم در نقش تنظیمکننده regularizers
اهداف یا برچسبهای نرم که از یک مدل پیشبینی میشوند در مقایسه با برچسبهای سخت دوقسمتی اطلاعات بیشتری در برمیگیرند؛ زیرا معیارهای شباهت بین ردهها را رمزگذاری میکنند.
برچسبهای اشتباهی که توسط مدل ارائه شدهاند شباهتهای برچسبهای مشترک را توصیف میکنند؛ این شباهتها باید در مراحل بعدی یادگیری آشکار باشند، حتی اگر اثر آنها حذف شده باشد. برای مثال تصور کنید یک شبکهی عصبی عمیق را روی دیتاستی از انواع نژادهای سگ آموزش میدهید؛ در چند مرحلهی ابتدایی یادگیری، مدل قادر به تشخیص و تمیز صحیح بین نژادهای مختلف نیست. همین تأثیر (شاید نه در این مقیاس) در مراحل بعدی آموزش هم میتواند اتفاق بیفتد. مشکل بیش برازش زمانی رخ میدهد که بیشتر تأثیرات این برچسبهای مشترک شروع به ناپدید شدن میکنند. با وادار کردن مدل به نگه داشتن این تأثیرات تا مراحل بعدی آموزش، میزان بیشتطبیقی را کاهش میدهیم.





