آموزش قایم باشک به ربات ها؛ کلید دستیابی به نسل بعدی AI
 تیم تحریریه
تیم تحریریه- ۶ دی ۱۴۰۰
آموزش قایم باشک به ربات ها کلید دستیابی به نسل بعدی AI می باشد.
هوش مصنوعی عمومی (AGI) شاخهای از AI است و عامل هوش مصنوعی با اتکا به آن میتواند همانند انسانها فکر کند و یاد بگیرد؛ AGI مدتها موضوعی محدود به داستانهای عملی تخیلی بود. اما همزمان با هوشمندتر شدن AI – علیالخصوص به لطف پیشرفتهای چشمگیری که در ابزارهای ML حاصل شده و این ابزارها میتوانند کدشان را بازنویسی کنند و از تجارب جدید بیاموزند- AGI به یکی از موضوعات داغ در حوزه AI تبدیل شده است.
سؤال: بر چه مبنایی میتوانیم سطح AGI را اندازهگیری کنیم؟
طی سالهای گذشته، پژوهشگران روشهای متعددی برای ارزیابی AGI پیشنهاد کردهاند. مشهورترین آنها آزمون تورینگ است که در آن شخصی با انسان و ماشین، بدون اینکه آنها را ببیند، تعامل برقرار میکند و باید حدس بزند در آن لحظه با چه کسی (انسان یا ماشین) گفتوگو داشته است. آزمون Robot College Student بن گورتزل Ben Goertzel و آزمون استخدامی نیلسون دو نمونهی دیگر از این آزمونها هستند، هدف از انجام این آزمونها این بوده که مشخص کنند آیا ماشینها میتوانند مدرک دانشگاهی اخذ کنند و یا جایی مشغول به کار شوند. یکی دیگر از این آزمونها ادعا میکند که موفقیت عامل AI در مونتاژ مبلمان چوبی IKEA را میتوان مبنایی برای سنجش میزان هوشمندی آن قرار داد.
علاوه بر مواردی که گفته شد، همبنیانگذار شرکت اَپل (Apple) یعنی استیو وزنیاک نیز معیار فوقالعاده جالبی برای سنجش AGI ارائه داده است. آزمونی که وز (نامی که دوستان و طرفداران وی برای خطاب به او به کار میبرند) پیشنهاد داده، آزمون قهوه Coffee Test نام دارد. به گفته وی، منظور از AGI این است که ربات بتواند به خانهای، در هر کجای این کره خاکی، برود، آشپزخانه را پیدا کند، قهوه دم کند و قهوه را در فنجان بریزد.
همچون هر آزمون دیگری، در مورد جزئی و کلی بودن مفاد این آزمونها نیز اختلاف نظرهایی وجود دارد. با این حال، سنجش هوشِ عامل AI بر مبنای تواناییاش در مسیریابی و گشت و گذار در محیط واقعی نیز جالب به نظر میرسد. مؤسسه آلن قصد دارد در پژوهش جدید خود این مورد را به آزمایش بگذارد.
ساخت دنیایی جدید
لوکا ویز، یکی از پژوهشگران مؤسسه هوش مصنوعی آلن Allen Institute for AI در مصاحبه با Digital Trends گفت: «ظرف چند سال گذشته، جامعه AI شاهد پیشرفتهای چشمگیری در زمینه آموزش عاملهای AI برای انجام کارهای دشوار بوده است.». مؤسسه هوش مصنوعی آلن یک آزمایشگاه هوش مصنوعی است که توسط همبنیانگذار شرکت مایکروسافت یعنی پاول آلن پایهریزی شده است.

ویز با اشاره به اینکه عاملهای هوش مصنوعیای که DeepMind توسعه داده قادر به یادگیری بازیهای آتاری هستند و میتوانند در بازی GO بر حریفان خود(انسانها) غلبه کنند، گفت این قبیل کارها « غالباً مستقل» از دنیای واقعی هستند. برای درک بهتر این مطلب کافی است تصویری از دنیای واقعی به رباتی که با هدف بازی کردن آتاری آموزش دیده، نشان دهید و خواهید دید که این ربات هیچ ایدهای از اینکه به چه چیزی نگاه میکند، ندارد. اینجا دقیقاً همانجایی است که پژوهشگران مؤسسه آلن معتقدند میتوانند وارد عمل شوند و تغییر ایجاد کنند.
مؤسسه AI آلن یک محیط آزمایشی گسترده (شبیه به خانه) ساخته است. البته این محیط واقعی نیست و مجازی است. این محیط دارای صدها اتاق، آپارتمان -شامل آشپزخانه، اتاق خواب، اتاق نشیمن- است که عامل AI در آن میتواند با هزاران شی ارتباط برقرار کند. فضای این محیطها واقعگرایانه است و از چندین عامل و حتی شرایطی همچون گرما و سرما پشتیبانی میکنند. هدف از ساخت این محیط این بوده که عاملان AI بتوانند در این محیطها بازی کنند و درک بهتر و جامعتری از دنیای واقعی به دست آورند.
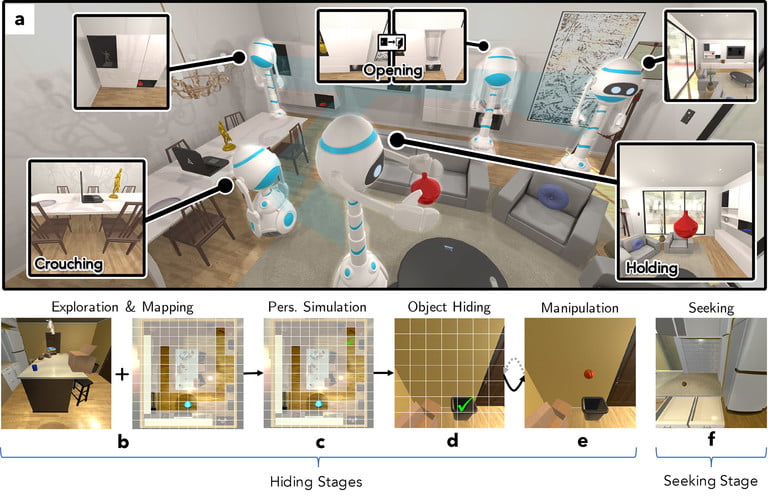
به گفته ویز: «هدف ما از انجام این پروژه این بوده که مشخص کنیم عاملان AI چگونه میتوانند با انجام بازیهای تعاملی در محیطهای واقعی، به دانشی در باب این محیطها دست پیدا کنند»، وی در ادامه اضهار داشت:« برای پاسخ دادن به این سؤال، دو عامل را به کمک یادگیری تقویتی تخاصمی در محیط AI2-THOR، که کیفیت بالایی دارد، آموزش دادیم تا Cache، که یک بازی شبیه قایم باشک است، را بازی کنند.» طی آموزش قایم باشک به ربات ها متوجه شدیم عاملهای AI یاد گرفتهاند تصاویر خاصی نشان دهند و به عملکردی دست پیدا کنند که پیش از این برای دستیابی به آن به میلیونهای تصویر که به صورت دستی برچسبگذاری شده بودند نیاز بود و حتی مجموعهای از رفتارهای شناختی ابتدایی از خود نشان دادند که اغلب روانشناسان به مطالعه آنها میپردازند.»
قوانین بازی
در بازی Cache، برخلاف بازی قایم باشک معمولی، رباتها به نوبت اشیایی، برای مثال لوله بازکن، تکهای نان، گوجه و غیره را پنهان میکنند، که البته شکل هندسی هر کدام از این اشیاء با دیگری متفاوت است. این دو عامل، که یکی از آنها قایم میشود و دیگری به جستوجوی آن میرود، با یکدیگر رقابت میکنند و تلاش میکنند شیای را پنهان کنند. در این بازی چالشهای متعددی ، از جمله کشف و نقشهبرداری، درک نما، قایم شدن، دستکاری شی و جستوجو پیشروی رباتها قرار دارد. گوشه به گوشه این محیط با دقت شبیهسازی شده است،تا جاییکه رباتی که قایم میشود باید بتواند شیای که در دست دارد را دستکاری کند و آن را نیندازد.
عملکرد رباتها در قایم کردن و پیدا کردن اشیاء با استفاده از یادگیری تقویتی عمیق بهتر و بهتر میشود؛ یادگیری تقویتی عمیق ، یکی از زیرشاخههای یادگیری ماشین است و در آن ماشین باید کارهایی انجام دهد و به حداکثر پاداش دست پیدا کند.
ویز میگوید: «چیزی که این کار را برای عاملهای AI مشکل میکند این است که آنها نمیتوانند دنیا را همانند ما انسانها ببینند» وی در ادامه میگوید: «مغز ما طی میلیاردها سال تکامل توانسته ،حتی زمانیکه نوزاد هستیم، تصاویر را به مفاهیم ترجمه کند. اما عامل AI کار خود را از صفر شروع میکند و دنیای پیرامون خود را در قالب شبکهای گسترده از اعداد میبیند و باید یاد بگیرد آن را رمزگشایی کند. در ضمن، برخلاف بازی شطرنج، که در آن دنیا فقط در 64 مربع خلاصه میشود، هر تصویری که عامل میبیند فقط بخش کوچکی از محیط است و به همین دلیل باید در طول زمان مشاهدات خود را با یکدیگر ترکیب کند تا به درک جامعی از دنیا برسد.»
به عبارت دقیقتر هدف از آموزش قایم باشک به ربات ها ساخت عاملهای AI فراهشمند نیست. در فیلم نابودگر2: روز داوری، Skynet که یک ابرکامپیوتر است رأس ساعت 2:14 صبح روز 29 آگوست 1997 به خودآگاهی میرسد. با وجود اینکه حدود 25 سال از آن روز میگذرد، بعید به نظر میرسد بتوانیم زمان دقیق دستیابی به AGI را مشخص کنیم.
انجام کارهای دشوار آسان و انجام کارهای آسان دشوار است!
پژوهشگران از دیرباز با این تفکر که اگر عاملان AI بتوانند مسائل پیچیده را حل کنند، حل مسائل آسان کار دشواری نخواهد بود، تمایل داشتند عاملان AI را برای حل مسائل پیچیده آموزش دهند. اگر بتوانید فرایند تصمیمگیری یک فرد بالغ را شبیهسازی کنید، آیا شبیهسازی ایده بقای شی ( به این معنا که اشیاء حتی زمانیکه ما نمیتوانیم آنها را ببینیم، وجود دارند)، که کودک طی چندین ماه اول زندگی خود یاد میگیرد، نیز به همان اندازه دشوار خواهد بود؟ بله – و این تناقض، یعنی در حوزه AI انجام مسائل دشوار آسان و انجام مسائل آسان دشوار است، همان چیزی است که پژوهشهایی از این دست تلاش دارند پاسخی برای آن پیدا کنند.
طبق اظهارات ویز: « متداولترین الگو برای آموزش عاملهای AI استفاده از دیتاستهایی با حجم بالا است که به صورت دستی و برای مسئلهای خاص، برای مثال تشخیص اشیا، برچسبگذاری شدهاند.» وی در ادامه اظهار داشت:« هرچند این روش موفقیتآمیز بوده، اما به عقیده من خوشبینانه است اگر فکر کنیم میتوانیم دیتاستهایی با این حجم را ایجاد کنیم و به صورت دستی برچسبگذاری کنیم تا یک عامل AI بسازیم و آن عامل بتواند در دنیای واقعی رفتاری هوشمندانه داشته باشد، با انسانها تعامل برقرار کند و هر مشکلی که به آن برمیخورد را حل کند. به عقیده من برای انجام این کار باید به عاملها اجازه دهیم تا آزادانه با دنیا تعامل برقرار کنند و رفتارهای شناختی را یاد بگیرند. نتایج حاصل از پژوهش ما حاکی از این است که اگر عامل AI بتواند از طریق بازی با دنیا تعامل برقرار کنند و آن را کشف کنند میتواند این رفتارهای شناختی را یاد بگیرد و علاوه بر این نتایج پژوهش ما نشان میدهد بازی روش مناسبی برای یادگیری از طریق تجربه است.»
مقالهی مربوط به این پروژه در کنفرانس بینالمللی ICLR (سال 2021) ارائه خواهد شد.
جدیدترین اخبار هوش مصنوعی ایران و جهان را با هوشیو دنبال کنید.