
آموزش پردازش زبان طبیعی با اکوسیستم هاگینگ فیس ؛ بررسی جامع پایپ لاین (قسمت دوم فصل دوم)
 تیم تحریریه
تیم تحریریه- ۳۰ آبان ۱۴۰۰
در این قسمت قرار است بررسی جامعی از پایپ لاین داشته باشیم؛ اما محتوای این بخش قدری با سایر بخشها فرق دارد. بیایید در ابتدای کار این مثال را بررسی کنیم. در زیر خواهید دید که با اجرای کد زیر چه اتفاقی رخ میدهد:
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier([
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
])
نتیجه به صورت زیر قابل نمایش میباشد:
[{'label': 'POSITIVE', 'score': 0.9598047137260437},
{'label': 'NEGATIVE', 'score': 0.9994558095932007}]
همانطور که در فصل 1 (لینک مربوط به قسمتهای دیگر در پایان مطلب قرار داده شده است) ملاحظه کردید، این تابع شامل سه مرحله میباشد: پیشپردازش، درج ورودیها در مدل و پسپردازش. این مراحل به طور جامع توضیح داده خواهند شد.
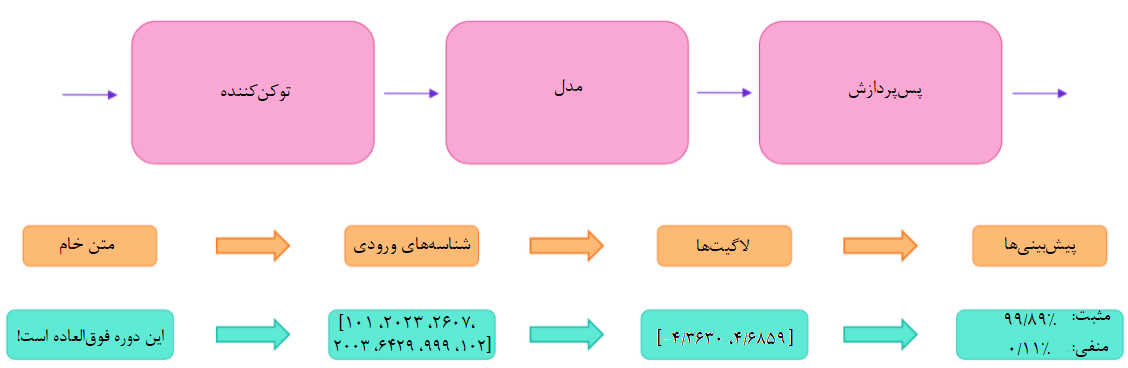
پیشپردازش با توکنکننده
مدلهای ترنسفورمر به مانند سایر شبکههای عصبی قادر به پردازش مستقیم متن خام نیستند؛ بنابراین، باید در اولین گام ورودیهای متنی را به اعدادی تبدیل کرد تا مدل بتواند با آنها کار کند. توکنکننده tokenizer بهترین ابزار برای انجام این کار است و مسئولیت انجام کارهای زیر را بر عهده دارد:
- تقسیم ورودیها به واژه، زیرواژه یا علائم نگارشی که توکن نامیده میشوند.
- نگاشت هر توکن به یک عدد صحیح
- افزودن ورودیهای بیشتر که ممکن است برای مدل مفید باشد.
کل مرحله پیشپردازش باید با همان رویکردی انجام گیرد که در هنگام پیشآموزشِ مدل اتخاذ شد. لذا، باید اطلاعات لازم را از Model Hub دانلود کرد. این کار با کلاس AutoTokenizer انجام میپذیرد. در این میان، از روش پیشآموزش یافته نیز کمک گرفته میشود. این ابزار میتواند دادههای مرتبط با توکنکنندهی مدل را به صورت خودکار گردآوری و ذخیره کند. بنابراین، تنها زمانی دانلود میشود که برای اولین بار کد زیر را اجرا کنید.
از آنجا که چکپوینت پیشفرضِ پایپ لاین «تحلیل احساسات Sentiment analysis» عبارت است از distilbert-base-uncased-finetuned-sst-2-english، باید کد زیر را اجرا کرد:
from transformers import AutoTokenizer checkpoint = "distilbert-base-uncased-finetuned-sst-2-english" tokenizer = AutoTokenizer.from_pretrained(checkpoint)
حال که توکنکنند موجود میباشد، میتوان به طور مستقیم جملات را به آن برای توکن کردن پاس داد. در این صورت، یک دیکشنری خواهیم داشت که ورودی مدل میباشد. تنها کاری که باقی مانده، این است که لیست شناسههای ورودیinput IDs را به تنسور تبدیل کنیم. بدون اینکه نگران این موضوع باشید که کدام چارچوب یادگیری ماشین به عنوان بکاِند مورد استفاده قرار میگیرد، از ترنسفورمرها استفاده کنید. ممکن است مدل مد نظرتان پایتورچ، تنسورفلو یا فلکس باشد. مدلهای ترنسفورمر فقط تنسورها را به عنوان ورودی میپذیرند. اگر عبارت «تنسور» برای نخستین بار به گوشتان میخورَد، میتوانید آنها را به عنوان آرایههای NumPy در نظر بگیرید. آرایه NumPy میتواند اسکالر، بردار یا ماتریس باشد و یا دو بُعد بیشتر داشته باشد؛ مطمئناً یک تنسور به حساب میآید. تنسورهای سایر چارچوبهای یادگیری ماشین رفتار مشابهی دارند. از آرگومان return_tensors برای تعیین نوع تنسورهای مورد نیاز استفاده میشود:
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="tf")
print(inputs)
نگران حاشیه پد padding و برش truncation دادگان نباشید. این مفاهیم در بخشهای بعدی توضیح داده خواهند شد. باید این موضوع را به خاطر بسپارید که میتوانید جمله یا لیستی از جملات را به توکنکننده پاس بدهید؛ و نوع تنسورهایی را که میخواهید به دست آورید، مشخص کنید(توجه کنید اگر نوع تنوسر مشخص نشود به صورت پیشفرض لیستی از لیستها در نظر
گرفته میشود). در بخش زیر، نتایج مربوط به تنسورهای TensorFlow نشان داده شده است:
{
'input_ids': <tf.Tensor: shape=(2, 16), dtype=int32, numpy=
array([
[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102],
[ 101, 1045, 5223, 2023, 2061, 2172, 999, 102, 0, 0, 0, 0, 0, 0, 0, 0]
], dtype=int32)>,
'attention_mask': <tf.Tensor: shape=(2, 16), dtype=int32, numpy=
array([
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
], dtype=int32)>
}
خروجی یک نوع دیکشنری است که حاوی دو کلید input_ids و attention_mask میباشد. input_ids دو سطر اعداد صحیح دارد که شناساگر منحصربهفردِ هر توکن در هر جمله میباشند. attention_mask در بخشهای بعدیِ این فصل توضیح داده خواهد شد.
[irp posts=”12270″]بررسی مدل
به همان شیوهای که در توکنکننده عمل شد، میتوان مدل پیشآموزش داده شده را نیز دانلود کرد. ترنسفورمرها کلاسی به نام TFAutoModel ارائه میکنند که از from_pretrained بهره میبرد.
from transformers import TFAutoModel checkpoint = "distilbert-base-uncased-finetuned-sst-2-english" model = TFAutoModel.from_pretrained(checkpoint)
در این قطعه کد، همان چکپوینتی دانلود شده است که پیشتر در پایپ لاین به کار گرفته شد. این معماری فقط حاوی ماژول پایه ترنسفورمر است. اگر چند ورودی در اختیارش قرار دهیم، حالات پنهانHidden states یا ویژگیهاFeatures را به عنوان خروجی ارائه میدهد. در ازای هر ورودی مدل، یک بازنمایی چندبعدی که دارای اطلاعات و دانش مفهوم و محتوای ورودی ترنسفورمر میباشد. اگر متوجه نشدید، نگران نباشید. توضیحات بیشتر در بخشهای بعدی فصل ارائه خواهد شد.
این حالات پنهان میتوانند به تنهایی مفید واقع شوند، اما معمولاً ورودیِ بخش دیگری از مدل (موسوم به head) هستند. در فصل 1، امکان انجام کارهای مختلف با معماری یکسان وجود داشته است، اما هر کدام از این کارها دارای head متفاوتی خواهند بود.
بردار چندبعدیA high-dimensional vector
خروجی مدل با ماژول ترنسفورمر معمولاً بزرگ است و عموماً دارای سه بُعد میباشد:
- اندازه دستهBatch size : تعداد توالیهای پردازش شده در یک سری.
- طول توالیSequence length : طول بازنماییهای عددیِ توالی.
- اندازه پنهانHidden size : بُعد برداریِ هر ورودی مدل.
دلیل انتخاب چنین نامی برای بردار یاد شده، مقدار بعد آخر آن(اندازه پنهان) است. اندازه پنهان میتواند بسیار بزرگ باشد. اگر ورودیهای پیشپردازش شده به مدل اضافه شوند، موضوع فوق به روشنی توضیح داده میشود:
outputs = model(inputs) print(outputs.last_hidden_state.shape) . (2, 16, 768)
توجه داشته باشید که خروجی مدلهای ترنسفورمر رفتاری مانند namedtuples یا دیشکنری دارند. دسترسی به خروجی به شکل (outputs[“last_hidden_state”]) نیز قابل دسترس هستند.
سرهای مدل
سرhead مدل یک بردار با ابعاد بالای حالات پنهان را به عنوان ورودی به کار برده و آنها را در بُعد متفاوتی بازتاب میدهند. سر های مدل معمولاً از یک یا چند لایه خطیlinear تشکیل یافتهاند. خروجی مدل ترنسفورمر به طور مستقیم به سر مدل ارسال میشود تا عمل پردازش بر روی آن صورت گیرد. در این نمودار، مدل با لایه embeddings و لایههای بعدی نمایش داده میشود.
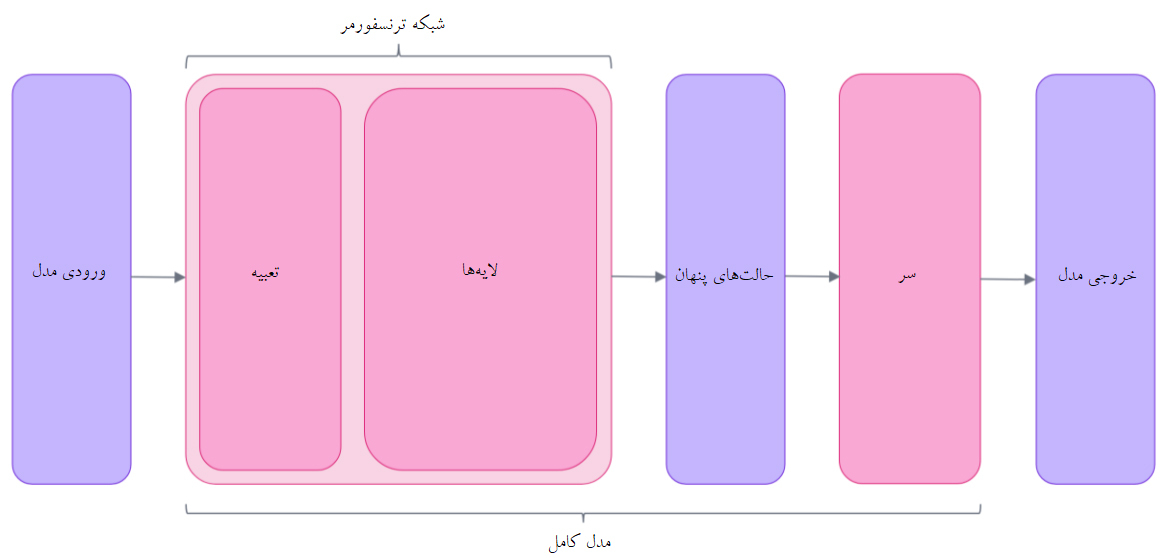
لایه embeddings هر یک از شناسههای ورودی را به برداری تبدیل میکند توکن مربوطه را به نمایش میگذارد. لایههای بعدی آن بردارها را با استفاده از مکانیسم توجه دستکاری میکنند تا بازنمایی نهایی از جملات ایجاد شود. معماریهای بسیار متفاوتی در ترنسفورمرها وجود دارد که هر کدام برای عمل خاصی طراحی شدهاند. به لیست زیر توجه نمایید:
- *Model (retrieve the hidden states)
- *ForCausalLM
- *ForMaskedLM
- *ForMultipleChoice
- *ForQuestionAnswering
- *ForSequenceClassification
- *ForTokenClassification
- و دیگر موارد …
برای مثال به مدلی با سر دستهبندی توالیsequence classification head نیاز داریم. بنابراین، امکان دستهبندی توالیها در قالب مثبت یا منفی فراهم میشود. پس بهتر است از TFAutoModelForSequenceClassification استفاده کنیم:
from transformers import TFAutoModelForSequenceClassification checkpoint = "distilbert-base-uncased-finetuned-sst-2-english" model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint) outputs = model(inputs)
اکنون اگر نگاهی به شکلِ ورودیهایمان بیندازیم، میبینیم بعد خروجی کاهش یافته است.
سر مدل، بردار با ابعاد بالا را به عنوان ورودی به کار میگیرد و بردار حاوی دو مقدار را به عنوان خروجی میدهد:
print(outputs.logits.shape)
.
(2, 2)
چون فقط دو جمله و دو برچسب داریم، نتیجه حاصل از مدل به شکل خواهد بود.
[irp posts=”7889″]پسپردازش خروجی
در این مرحله از پایپ لاین مقادیری که در قالب خروجی از مدل به دست میآیند، به تنهایی معنای چندانی ندارند. بیایید دقیقتر بررسی کنیم:
print(outputs.logits)
.
<tf.Tensor: shape=(2, 2), dtype=float32, numpy=
array([[-1.5606991, 1.6122842],
[ 4.169231 , -3.3464472]], dtype=float32)>
مدلِ ما[-1.5607, 1.6123] را برای اولین جمله و [ 4.1692, –3.3464] را برای دومین جمله پیشبینی کرد. اینها احتمال نیستند، بلکه ارقام خام و نرمالسازی نشدهای هستند که لایه آخرِ مدل از آنها خروجی گرفته است. آنها برای اینکه به احتمال تبدیل شوند، باید از لایه سافتمکسsoftmax عبور کنند.
import tensorflow as tf predictions = tf.math.softmax(outputs.logits, axis=-1) print(predictions)
.
tf.Tensor( [[4.01951671e-02 9.59804833e-01] [9.9945587e-01 5.4418424e-04]], shape=(2, 2), dtype=float32)
اینک، میبینیم که مدل توانسته [0.0402, 0.9598] را برای جمله اول و [0.9995, 0.0005] را برای جمله دوم پیشبینی کند. این ارقام احتمال قابل درک هستند. برای به دست آوردن برچسب متناظر با هر خروجی، میتوان ویژگی از id2label استفاده کرد:
model.config.id2label
.
{0: 'NEGATIVE', 1: 'POSITIVE'}
اکنون، میتوان این چنین نتیجه گرفت که مدل نتایج زیر را پیشبینی کرده است:
جمله اول: منفی: 0402/0، مثبت: 9598/0
جمله دوم: منفی: 9995/0، مثبت: 0005/0
هر سه مرحله پایپ لاین (پیشپردازش با توکنکنندهها، درج ورودیها در مدل و پسپردازش) با موفقیت به انجام رسید.
از طریق لینک زیر میتوانید به دیگر قسمتهای دوره آموزشی پردازش زبان طبیعی دسترسی داشته باشید:
[button href=”https://hooshio.com/%D8%B1%D8%B3%D8%A7%D9%86%D9%87-%D9%87%D8%A7/%D8%A2%D9%85%D9%88%D8%B2%D8%B4-%D9%BE%D8%B1%D8%AF%D8%A7%D8%B2%D8%B4-%D8%B2%D8%A8%D8%A7%D9%86-%D8%B7%D8%A8%DB%8C%D8%B9%DB%8C/” type=”btn-default” size=”btn-lg”]آموزش پردازش زبان طبیعی[/button]





