اشکال زدایی از مدل یادگیری ماشینی
تیم تحریریه
- ۲۰ فروردین ۱۴۰۱
فرض میکنیم یک مدل یادگیری ماشینی (ML) آموزش دادهاید. همه مراحل را نیز به درستی انجام دادهاید. مدل شما از دقت و ثبات بسیار خوبی برخوردار است و میتواند عملکردی بهتر از مدل خطی برجای بگذارد. شما حتی مدلتان را در جعبه «Docker» قرار دادهاید و همه ابزارها و وابستگیهای نرم افزاری dependency و فنآوری اطلاعات درون آن قرار دارد. حتما الان هم قصد استفاده از آن دارید؟ خب، عجله نکنید. بحث اشکال زدایی همچنان باقی مانده است.
بهترین راهکارهای آموزش اشکال زدایی و ارزیابی مدلهای یادگیری ماشین که در حال حاضر موجود می باشند تنها بر این نکته تاکید ندارند که چگونه مشکلات را در مسائل دنیای واقعی شناسایی کرده و به حل آنها بپردازیم. ای کاش اشکال زدایی debugging از این سیستم ها مانند نرم افزارهای عادی دیگر به سادگی فشردن دکمه اشکال زدایی از کیبورد بود.
اشکال زدایی از مدل یک مرحله مهم و اساسی است که به آزمایش و بررسی مدلهای پیچیده یادگیری ماشین، توابع پاسخ دهنده و مرزهای تصمیمگیری Decision boundaries آن پرداخته است. هدف از این کار، شناسایی و تصحیح مسائل مربوط به دقت، انصاف و امنیت در سیستمهای یادگیری ماشینی است.
نکات مختصری درباره اطمینان (Trust) و فهم (Understanding)
فهم و اطمینان در یادگیری ماشینی شبیه به هماند، ولی دو مفهوم یکسان نیستند. بررسی تفاوتِ میان آن دو مرا به یاد اشکال زدایی از مدل و نحوه ارتباط آن با سایر بخشهای گردش کاری یادگیری ماشینی میاندازد. همانطور که در شکل شماره 1 ملاحظه میکنید، امروزه ابزارهای گوناگونی برای ارتقای اطمینان و فهمِ ما انسانها از یادگیری ماشینی وجود دارد.
برخی از روشها مثل اشکال زدایی از مدل و آزمایش یا کاهش سوگیری اجتماعی Social bias به ما کمک میکنند تا مدلهای یادگیری ماشینیِ دقیق، منصفانه و امنتری را بسازیم؛ البته بدون اینکه بدانیم دقیقا این مدل چگونه کار میکند. این اقدامات بیشتر از آنکه درک ما را نسبت به مدل افزایش دهند باعث می شود تا اطمینان ما نسبت به عملکردش افزایش یابد. روشهای دیگر مثل مدلهای یادگیری ماشینی قابلتفسیر میتوانند درک ما را به طور مستقیم با آشکار ساختن سازوکارهای مدل یا با خلاصهسازی تصمیمات مدل افزایش دهند.
این روشها در صورتی که مدل یا توضیحات خوبی در اختیارمان بگذارند، اطمینان ما را نیز افزایش میدهند.

مقاله حاضر از دیدگاه ریاضی به بررسی جنبههای اشکال زدایی یادگیری ماشینی و افزایش اطمینان در یادگیری ماشینی خواهد پرداخت. هرچند، باید به دو جنبۀ دیگرِ گردش کاریِ یادگیری ماشینی نیز توجه ویژه ای نمود:
• افزایش درک یادگیری ماشینی
• آزمایش و تحکیم سیستمهای فنآوری اطلاعات مبتنی بر یادگیری ماشین
حتی اگر اطمینان و دقت برای شما ارزشی بیشتر از انصاف، تفسیرپذیری interpretability یا امنیت دارد، باید بدانید اینکه مدلهای یادگیری ماشین هر چقدر توسط شما به مدل قابل درک تری مبدل شود باعث می شود تا اپراتور سیستم به شناخت بهتری نسبت به آن برسد و در زمان مناسب تصمیمات اشتباه سیستم را تصحیح کند.
اگر مدل و منطق درونی آن را به عنوان جعبه سیاه Black box در نظر بگیریم، سخت می توان عملکرد آن را به چالش کشید. برای مثال اگر سیستم آموزشی مبتنی بر مدل های هوش مصنوعی را در نظر بگیرید، دوست ندارید فرزندتان به خاطر یک مدل یادگیری ماشینی دقیق امّا غیرقابل فهم، فرصت حضور در دانشگاه مورد علاقهاش را از دست بدهد. یا به طور مشابه، مطمئناً دوست ندارید در زمان استفاده از سیستم خدمات پزشکی مبتنی بر هوش مصنوعی، توسط مدل یکسانی رد شوید. گزینه ای که ممکن است در این موارد برای شما جذاب تر باشد، این است که بتوانید به تصحیح اشتباهات مدل یادگیری ماشینی بپردازید، به همین دلیل مدل هایی که تصمیم گیری حساسی در زندگی و کار بر عهده دارند باید قابل درک باشند.
[irp posts=”19951″]همان طور که در شکل شماره 2 مشاهده میکنید، مراحل افزایش درک و اطمینان در سیستمهای یادگیری ماشینی به تصویر کشیده شده است. اشکال زدایی از مدل زمانی به بهترین نحو عمل میکند که به همراه سایر روشهایِ پیشنهاد شده در شکل 2 مورد استفاده قرار بگیرد. در حال حاضر احتمالا بسیاری از شما، آزمایش و تحکیم سیستمهای سرویس دهنده مبتنی بر یادگیری ماشینی را به خوبی یاد دارید. صرفاً به این دلیل که سیستم از مدل یادگیری ماشینی بهره میبرد، بدین معنا نیست که مشمول آزمایش نمیشود. علاوهبراین، شرکت گوگل (و احتمالاً چند شرکت دیگر) چارچوبهای عملی خوبی در خصوص این موضوع ارائه کردهاند.

اکنون بگذارید نحوۀ اشکال زدایی از مدلهای یادگیری ماشینی را توضیح دهیم. در ابتدا به بحث درباره مسئله نمونه و دیتاست استفاده شده در این مقاله خواهیم پرداخت. چگونگی شناسایی باگها و فائق آمدن بر آنها نیز در بخشهای بعدی مقاله بررسی خواهد شد.
مسئله نمونه به همراه مجموعهداده
برخی از نمونههای مطرح شده در بخش زیر برپایۀ مجموعهدادههای مشهور کارت اعتباری تایوانی هستند که از منبع یادگیری ماشینی دانشگاه کالیفرنیا گردآوری شدهاند. ما در این مجموعه داده میخواهیم پیشبینی کنیم که کدام صاحبان کارت اعتباری در آینده اقدام به پرداختشان محتمل تر است. متغیرهای این پروژه به شرح زیر است:
در اینجا DEFAULT_NEXT_MONTH = 0 یا به صورت پیش فرض, DEFAULT_NEXT_MONTH = 1 قرار می دهیم.
متغیرهای مربوط به پرداخت برای تولید میزان احتمالِ پرداخت یا عدم پرداخت صاحب کارت استفاده میشوند که با p_DEFAULT_NEXT_MONTH در مسئله نشان داده می شوند.
ما در مقاله حاضر از الگوریتم (M-GBM) monotanically constrained gradient boosting machine برای انجام این نوع پیشبینیها استفاده میکنیم. p_DEFAULT_NEXT_MONTH باید تنها زمانی در M-GBM افزایش یا کاهش پیدا کند که متغیر ورودی معینی افزایش یابد. همین موضوع سبب سهولت در توضیح و اشکال زدایی از مدل میشود و بر دقت کلی مدل در این مجموعهداده تاثیر نمیگذارد. M-GBM با متغیرهای پرداخت مثل PAY_0 — PAY_6، PAY_AMT1 — PAY_AMT6 یا BILL_AMT1 — BILL_AMT6 آموزش داده میشود. کلیه مبالغ بر اساس دلار تایوان گزارش شدهاند (NT$).
برخی از نتایجِ این مثال حاوی متغیرهایِ LIMIT_BAL و r_DEFAULT_NEXT_MONTH میباشند. LIMIT_BAL همان محدودیت اعتبار مشتری می باشد. r_DEFAULT_NEXT_MONTH که در یادگیری ماشین به نام خطای لگاریتمی Logloss residuals باقیماندهها شناخته می شود و معیار عددی می باشد که فاصله پیشبینیِ M-GBM از جواب صحیح را نشان می دهد.
ما در این مجموعه از متغیرهای جمعیتشناختی demographic همچون جنسیت در این مجموعهداده استفاده خواهیم کرد تا سوگیری های ناخواسته که تحت تاثیر جامعه منتخب در داده ها پیش می آید را بسنجیم. مقاله حاضر مسئله اعتباردهی را به عنوان یک فعالیت مدلسازیِ پیشبینیگر general predictive modeling مورد بررسی قرار میدهد.
راهبردهای شناسایی
چطور میتوان باگهای ریاضی را در مدلهای یادگیری ماشینی پیدا کرد؟ ما دستکم چهار روش کلی برای شناسایی باگها میشناسیم: تحلیل حساسیت، sensitivity analysis تحلیل باقیمانده، residual analysis مدلهای بنچمارک، benchmark models و اعتبارسنجی ضریب اطمینان یادگیری ماشینی ML security audits verification شاید روشهای دیگری هم به ذهن شما خطور کند.
تحلیل حساسیت
روش تحلیل حساسیت که از آن به عنوان روش تحلیلی «What-if» نیز یاد می شود، بر اساس ایدهای قوی و ساده پایه گذاری شده است. فقط دادهها را در سناریوهای مهم تر شبیهسازی کنید تا متوجه بشوید که مدلتان چه نوع پیشبینیهایی در آن سناریوها انجام میدهد. زیرا پیش بینی واکنش مدل یادگیری ماشینی غیرخطی در برابر دادههایی که در طول آموزش با آنها مواجه نشده، غیرممکن است.
از این حیث پیادهسازیِ تحلیل حساسیت در مدل یادگیری ماشینی حائز اهمیت فراوانی میباشد. شاید شما ایدهها و پیشنهادهای خوبی در خصوص آزمایش سناریوهای مختلف در ذهن داشته باشید و صرفا به دنبال سناریوهای مختلفی می گردین که بتوانید مدل خود را مورد آزمایش قرار بدهید. اگر اینطور باشد، لطفاً همین الان دست به کار شوید و ایدههای خود را به مرحله اجرا در بیاورید. در همین راستا، استفاده از ابزار What-If-Tool بسیار کارآمد خواهد بود.
این ابزار میتواند زمینه را برای دسترسی به روشی ساماندهیشده در تحلیل حساسیت فراهم آورد. بخش زیر به معرفی سه راهبرد برای تحلیل حساسیت ساماندهیشده خواهد پرداخت:
1- وابستگی جزئی، Partial dependence انتظار شرطی (ICE)، و نمایش تاثیر محلی تجمعی (ALE)
2- جستجوی نمونههای تخاصمی
3- حملات تصادفی
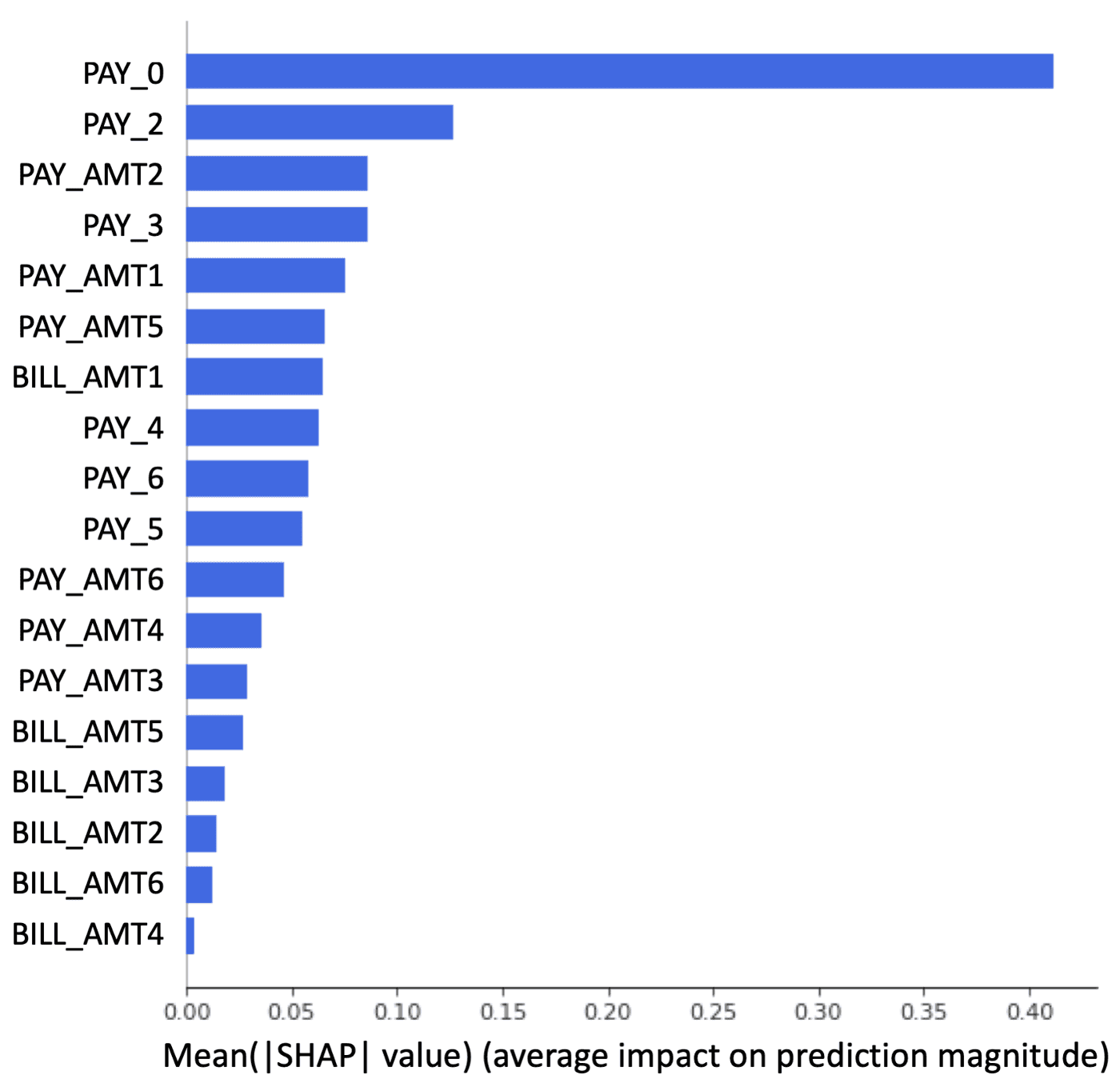
قبل از اینکه با سازوکار هر کدام از این موارد آشنا شوید، باید بدانید که کدام متغیرها بیشترین تاثیر را درمدل شما دارند. ما همواره در انجام کارهای آزمایش بر روی این متغیرهای مهم تمرکز میکنیم. شکل شماره 3 اهمیت متغیرها را با توجه به مقدار sharpley value در قالب یک نمودار به تصویر کشیده است. بدین منظور از XGBoost استفاده شده است. شکل 3 به ما نشان میدهد که PAY_0 اهمیت زیادی دارد. در بخشهای بعدی بیشتر به اهمیت آن پی خواهید برد.
وابستگی جزئی ، انتظار شرطی (ICE)، و نقشههای تاثیر محلی تجمعی (ALE)
کار وابستگی جزئی تنظیم کلیه مقادیر ستونهای مورد نظر (مثل PAY_o) در مجموعهداده دلخواه مانند دیتاست اعتبارسنجی Validation dataset بر روی مقدار دلخواه (مثلا مقدار NaN یا خالی) و یا هر مقدار منطقی دیگر است. این مدل بعد از آموزش با مجموعهداده جدید، به اجرا در آمده و در هر ردیف اقدام به پیشبینی میکند.
مقداری که بعد از گرفتنِ میانگینِ همه آن پیشبینیها به دست می آید به منزلۀ وابستگی جزئی به ازای آن مجموعهداده، آن مقدار و آن مدل است. اکنون میتوان این فرایند را با مقادیر مختلف انجام داد تا سرانجام از منحنی وابستگی جزئی خروجی بگیریم. نمودارِ شکل 4 رفتار متوسط PAY_o را در مدل M-GBM نشان میدهد.
با وجود این که درک وابستگی جزئی کار چندان دشواری نیست، اما باید بدانید که این روش چندان هم روش کاملی نیست. در زمانهایی که همبستگی بین متغیرها در مجموعهداده زیاد باشد، نتایج غیرقابل اطمینانی به دست میآید. خوب حداقل می توانیم با دو گزینه به نام ALE و ICE نتایج وابستگی جزئی را بهبود ببخشیم. ALE را تقریبا می توان به صورت یک جایگزین مستقیم برای معیار وابستگی جزئی استفاده کرد. محاسبه این معیار به لحاظ پیچیدگی محاسبات به صرفه تر و از لحاظ کارآیی دقیق تر است. ALE در زبان برنامه نویسی R نظیر ALEPlot، DALEX و iml در دسترس می باشد.
ICE غالباً به همراه وابستگی جزئی مورد استفاده قرار میگیرد. محاسبه ICE بسیار مشابه با وابستگی جزئی می باشد. دقیقا طبق مراحل توضیح داده شده پیش می روید فقط توجه داشته باشید که مجموعهداده دلخواه فقط یک ردیف را شامل شود. وقتی منحنیهای ICE با رفتار میانگینی که وابستگی جزئی نشان میدهد همراه باشد، میتوان حدس زد که وابستگی جزئی از دقت کافی برخوردار است. اگر منحنیهای ICE نسبت به وابستگی جزئی واگرا diverge شود ، میتوان این چنین برداشت کرد که برهمکنشهایی در مدل وجود دارد.
در کل، ICE میتواند اطلاعات خوبی درباره رفتار افراد واقعی یا شبیهسازی شده در مدل در اختیارمان بگذارد؛ البته به این شرط که وابستگی جزئی قابلاطمینان باشد و ما نیز به دنبال برهمکنشهای قوی در مدل باشیم. ترکیبها و انواع مختلف وابستگی جزئی و ICE در چندین بسته منبع باز وجود دارد که از جمله آنها میتوان به PDFbox، PyCEboc، ICEbox و pdp اشاره کرد.
شکل 4 به ادغام وابستگی جزئی، ICE و یک هیستوگرام histogram میپردازد تا بینش خوبی درباره مهمترین متغیر PAY-o در مدل M-GBM فراهم کند. در ابتدا میبینیم که دادههای آموزشیِ PAY_o پراکنده است. این پراکندگی معمولاً نشانه خوبی نیست. مدلهای یادگیری ماشینی به حجم بالایی از داده برای یادگیری نیاز دارند. این مدل تقریباً هیچ دادهای درباره افرادی که بازپرداختشان یک ماه به تعویق افتاده است، ندارد.
مطابق با وابستگی جزئی، میتوان به وجود چند مسئله بالقوه دیگر پی برد. از دید امنیتی، با خطراتی مواجه هستیم. اگر خواهان امتیاز خوبی از این مدل هستیم، شاید لازم باشد فقط یک نمونه تخاصمی را هک کنیم. همچنین نوسان بزرگی در پیشبینیها از PAY_0=1 تا PAY_0=2 وجود دارد. آیا این کار از دید کسبوکار منطقی است؟ شاید منطقی باشد، اما باید از دید امنیتی نسبت به آن آگاهی کافی بدست بیاوریم.
اگر بخواهیم عملیات «حمله منع سرویس» Distributed Denial of Service attack را برای یکی از کاربران این مدل به اجرا دربیاوریم، باید مقدار PAY_o را به بیشتر از 1 افزایش دهیم. در این مدل باید به همکاران فنآوری اطلاعات بگوییم که بر حملات نمونه تخاصمی نظارت داشته باشند. در این حملات، شاهدِ PAY_0 = NaN and PAY_0 > 1 هستیم. همچنین، اگر بازار به سمت رکود حرکت کند و قبض پرداختنشدۀ مشتریان زیاد باشد، باید به این نکته توجه کرد که M-GBM حساسیت بالایی در برابر مقادیرِ PAY_0 > 1 دارد.

نکته اطمینانبخش این است که منحنیهای ICE وابستگی جزئی نشان میدهند که مولفۀ یکنواختی در PAY_0 در مقدار میانگین حفظ میشود. خوشبختانه، مولفههای یکنواختی این فرصت را به ما میدهند تا با مسئله پراکندگی دادهها نیز به خوبی مقابله کنیم.
به دلیل وجود مولفههای یکنواختی، مدل توانست احتمال را از PAY_0 = 2 به PAY_0 > 8 (جایی که خبری از دادههای آموزشی نیست) هدایت کند. پیشبینیهای مدل در PAY_0 در صورت نبودِ این مولفه صرفاً نویز تصادفی قلمداد خواهند شد. درنهایت، چون ICE و وابستگی جزئی تا حدود زیادی همتراز هستند، میتوان دید که منحنی وابستگی جزئیِ PAY_0، این مجموعه داده و مدل M-GBM تا حدود زیادی قابل اطمینان است.
اکنون باید همین تحلیل را برای سایر متغیرهای مهم انجام دهیم. حالا وقت آن رسیده که درباره جستجوهای نمونه تخاصمی، راهبرد اشکال زدایی و تحلیل حساسیت بعدی به بحث بپردازیم.
جستجوی نمونه تخاصمی
نمونههای تخاصمی به ردیفهایی از داده گفته میشود که باعث میشوند مدل به تولید نتایج غیرمنتظره بپردازد. جستجوی نمونههای تخاصمی یکی از روشهای عالی برای اشکال زدایی محسوب میشود. فرایند جستجو این فرصت را به ما میدهد تا از چگونگی عملکرد مدلمان در چند سناریوی مختلف مطلع شویم.
یافتن و درکِ نمونههای تخاصمیِ واقعی میتواند مستقیماً ما را به سمت روشهایی ببرد که مدلهایمان را قدرتمندتر کنیم و نابهنجاریها را در هنگام ورودِ مدل به بخش تولید پیدا کنیم. اگر در فضای یادگیری عمیق پایتون مشغول به فعالیت هستید، میتوانید به بخشهای «Cleverhans» و «foolbox» نگاه کنید تا نمونههای تخاصمی را پیدا کنید.
در خصوص دادههای ساماندهیشده باید به این نکته اشاره کرد که نرمافزارهای قابلدسترس کمی در این زمینه وجود دارد تا از آنها کمک بگیریم، اما در مقاله حاضر یک روش جستجوی اکتشافی heuristic search معرفی میشود که میتوان از آن استفاده کرده یا به اصلاح و تغییر آن بپردازید. شکل شماره 5 نتایج جستجوی کلنگر را نشان میدهد.
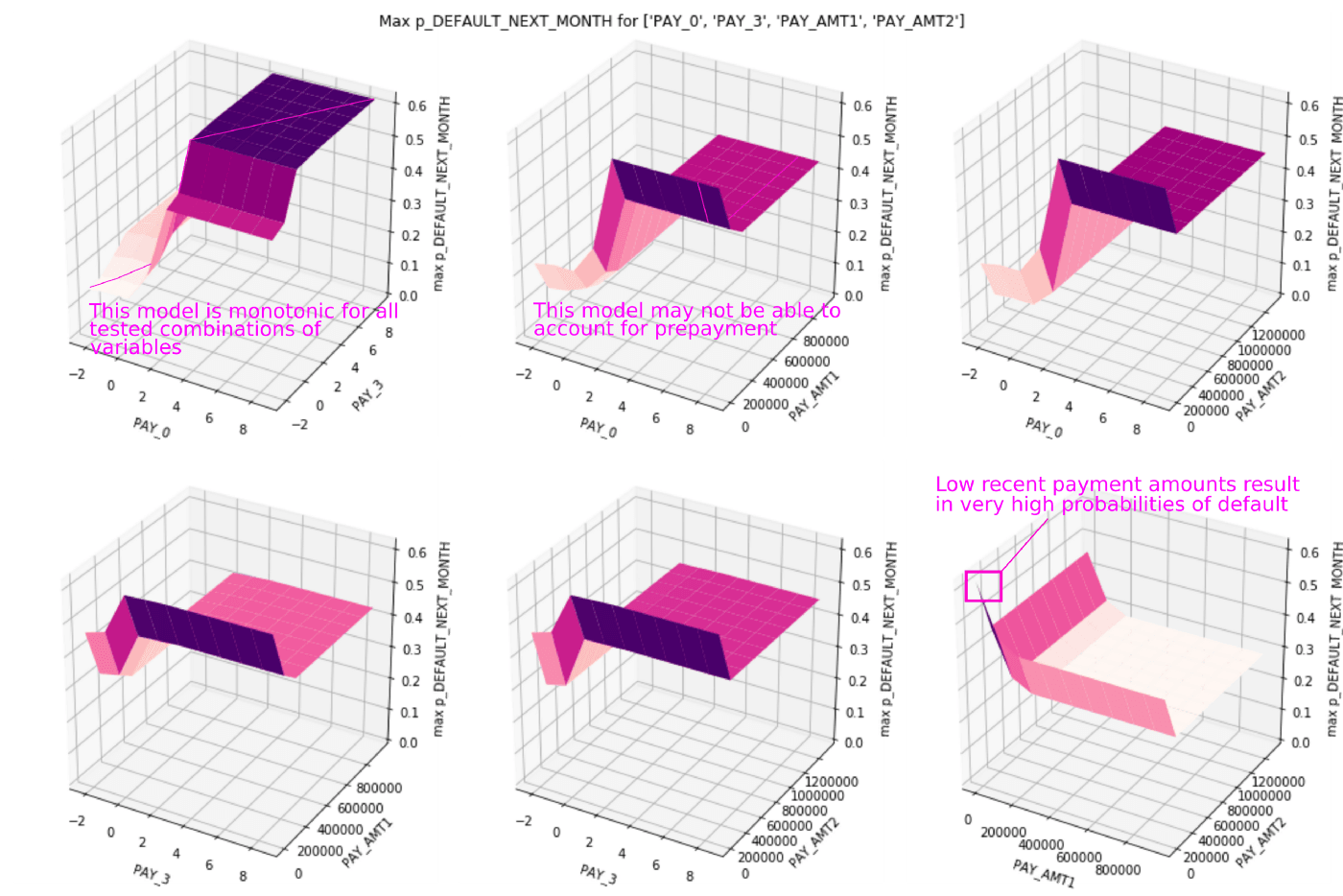
جستجوی اکتشافی در دادهها و مدل M-GBM با PAY_0 آغاز میشود؛ بر این اساس، همانطور که در شکل 4 ملاحظه شد، ICE مورد محاسبه قرار گرفته و منحنی ICE با بزرگترین تغییر در پیشبینیها بدست میآید. در این مجموعهداده و مدل، این منحنی در بیش از 90 درصدِ p_DEFAULT_NEXT_MONTH حاصل میآید.
سپس، ردیف دادهای در بیش از 90 درصد p_DEFAULT_NEXT_MONTH به تعداد 10.000 بار دچار آشفتگی میشود. البته نباید این نکته را فراموش کرد که 10 مقدار مختلف برای چهار متغیر مهم در اختیار داریم: PAY_0، PAY_3، PAY_AMT1 و PAY_AMT2. این مقادیر به خاطر طیف وسیع مقادیر Shapley انتخاب شدند، نَه بهطور مستقیم از نمودار اهمیت متغیر در شکل 3.
شکل 5 چندین نکته جالب درباره مدل M-GBM ارائه میکند. اولاً، میبینیم که مولفههای یکنواختی monotonicity constraints در ترکیبی از متغیرهای مختلف نیز حضور دارند. درثانی، یک خطای منطقی هم در مدل M-GBM شناسایی شده است. گویا اهمیتی ندارد که آخرین پرداختِ یک فرد چقدر زیاد باشد، اگر افراد در آخرین مورد حدود یک ماه تاخیر در پرداخت داشته باشند، مدل احتمال بالایی از بازپرداخت (Default) در نظر خواهد گرفت. یعنی این احتمال میرود که مدل M-GBM قادر به منظور کردنِ پیش پرداخت نباشد؛ یا شخصی را که مبالغ زیادی پرداخت میکند تا پرداختهای معوقه خود را جبران کند.
اگر این شرایط را در مدل M-GBM یا در سیستم اعتباردهی لحاظ میکردیم، میتوانستیم گزینه ویرایشِ مدل M-GBM را در نظر بگیریم یا از سیستم اعتباردهی برای مدیریت این سناریوهای پیچیده استفاده کنیم. نکته سوم این است که این جستجو دستکم به شش نمونه تخاصمی دست پیدا کرد. مقادیرِ بسیار پایینِ PAY_AMT1 و PAY_AMT2 در هنگام ترکیب با سایر مقادیر در ردیفهای مورد استفاده برای آغاز جستجو باعث خواهند شد تا مدل M-GBM با احتمال زیادی مقادیر پیش فرض را تولید کنند.
وقتی مدل M-GBM به سمت تولید حرکت کرده باشد، استفاده از این مقادیر برای کارهای نظارتی ضروری خواهد بود. این مقادیر میتوانند نشان دهند که مدل، مورد حمله تخاصمی قرار گرفته است یا نه. اگر فکر میکنید روش جستجوی تخاصمی پیشنهادی مفید است، آن را امتحان کنید. فرایند جستجوی اکتشافی در بخش زیر خلاصه شده است.
برای هر متغیر مهم، به شرح زیر اقدام کنید:
1. منحنیهای ICE را در هر دهک از پیشبینیهای مدل محاسبه کنید.
2. منحنی ICE با بیشترین نوسان یا تغییر در پیشبینیها پیدا کنید.
3. ردیف دادههای مرتبط با منحنی ICE را تفکیک کنید.
در این ردیف از دادهها باید اقدامات زیر را انجام دهید:
1. یک تا سه متغیر مهم دیگر را در ردیف تغییر دهید. (رسم نمودار برای بیش از یک متغیر، کار دشواری است).
2. مجدداً به ردیف تغییریافته نمره دهید.
3. تا آنجایی به کار ادامه دهید تا متغیرهای مهم همه چرخهها را در قلمرویشان در دادههای آموزشی، طی کرده باشند.
به ترسیم نمودار پرداخته و نتایج را تحلیل کنید.
حملات تصادفی
حملات تصادفی زمانی به وقوع میپیوندند که مدل با انواعی از دادههای تصادفی روبرو شود. این نمونه را تصور کنید: مجموعه کاراکترهای دوبایتی، مجموعهدادههایی با یک ردیف و یک ستون، مجموعهدادههایی با یک میلیون ستون و یک ردیف و غیره. حملات تصادفی میتوانند در شناخت باگهای معمول در حوزه IT و همچنین ریاضی کمک کنند.
فرض کنید مجموعهدادهای در اختیار دارید که حاوی 10 میلیون ستون و یک ردیف است. در این شرایط، API به دلیل رویارویی با حجم بالایی از دادههای درونی یا خصوصی دچار سوءعملکرد میشود. این احتمال هم وجود دارد که به شیوهای نامناسب کارآیی خود را از دست بدهد.
شاید API و مدلتان مثل مقادیر گمشده با کاراکترهای دوبایتی برخورد کند و احتمال نکول پایینی را در نظر بگیرد. کسی چه میداند! اگر اصلاً نمیدانید از کجا باید کارهای اشکال زدایی مدل را آغاز کنید، با یک حمله تصادفی کارتان را آغاز کنید. مطمئنم به نکات جالبی دست خواهید یافت.
تحلیل باقیمانده
تحلیل باقیمانده از مدتها پیش به عنوان زیربنای تشخیص مدل خطی به حساب میآمد و این امر باید همچنان در عصر یادگیری ماشین تداوم داشته باشد. باقیمانده به اختلاف میان پیامد واقعیِ شناختهشده و پیشبینی آن پیامد توسط مدل اشاره میکند.
راههای متعددی برای محاسبه باقیماندهها وجود دارد، اما مقدار باقیماندۀ بزرگ به این معنی است که مدل دچار اشتباه شده است. مقدار باقیماندۀ کوچک نیز بدین معناست که مدل به درستی عمل کرده است. نمودارهای باقیمانده کلیه پیشبینیها و دادههای ورودی را به صورت دوبعدی نمایش میدهند؛ لذا، ناهمخوانیهای تاثیرگذار و انواع دیگر باگهای ریاضی، میتوانند به سادگی قابل رویت باشند.
[irp posts=”12844″]تنها عیب تحلیل باقیمانده این است که محاسبه باقیماندهها مستلزم پیامدهای واقعی است. بنابراین، در صورتی که به انجام نوعی از پیشبینی بپردازیم که پیامد واقعی برای بازه زمانی واقعی موجود نباشد، امکان کار با باقیمانده وجود نخواهد داشت.
شکل 6 خطای لگاریتمی باقیماندهها Log loss residuals را که مربوط به مدل M-GBM هست نشان میدهد که با متغیر مهم PAY_0 به تصویر کشیده شده است. باقیماندههای سرخابی رنگ مربوط به مشتریانی است که اقدام به نکول کردهاند. باقیماندههای آبی مربوط به مشتریانی است که اقدام به نکول نکردهاند. متاسفانه، شکل 6 تصویری عیبجویانه از مدل M-GBM را نشان میدهد.

در شکل 6 میبینیم که تعداد زیادی باقیمانده سرخابی برای مقادیر دلخواه PAY_0 < 1 وجود دارد که از جمله آنها میتوان به NO CONSUMPTION (-2)، PAID DULY (-1) یا USE OF REVOLVING CREDIT (استفاده از اعتبار در گردش) اشاره کرد. یعنی مدل اساساً زمانی در پیشبینیِ نکول ناکام میماند که مشتری مقدار دلخواهی برای PAY_0 نداشته باشد.
پس مدل M-GBM قادر به پیشبینی پرداختِ بهموقع نخواهد بود. ادغام این اطلاعات با نمودار “اهمیت متغیر” در شکل 3، نشان میدهد که M-GBM وابستگی زیادی به PAY_0 دارد. در همین راستا، میتوان استفاده از این قانون را در دستور کار قرار داد: IF PAY_0 > 1 THEN DEFAULT_NEXT_MONTH = 1. در این صورت، داشتن دقتی برابر با M-GBM تضمین میشود.
امکان رفع این باگ خطرناک، با استفاده از افزایش داده، عادیسازی، ویرایش مدل و… وجود دارد. ما کمابیش درباره این روشها در بخشهای پیشین مقاله بحث کردیم. اما یک نکته کاملاً روشن است: این مدل دارای مشکلی اساسی است، قابل اطمینان و مناسب برای استفاده در دنیای حقیقی نیست. شاید از این امر تجب کنید که نمودارهای باقیمانده چه اطلاعاتی را درباره مدلهای سالم در اختیارمان میگذارند. خوشبختانه، در مقاله حاضر سعی بر این بود که خوانندگان متقاعد شوند ترسیم باقیماندهها یک روش اشکال زدایی تاثیرگذار است.
تاثیر نابرابر، Disparate impact دقت و تحلیل خطا Error analysis
تاثیر نابرابر به تبعیض ناخواسته در سیستمهای تصمیمگیری اشاره میکند. روشهای آزمایش تاثیر نابرابر یکی از روشهای مشهور برای پیدا کردن سوگیریهای اجتماعیِ ناخواسته در دادههای آموزشی و نتایج مدلسازی پیشبینیگر محسوب میشوند. آیا این روشها کامل و بینقص هستند؟ آیا استفاده از این روشها حداقل کاری است که میتوانید انجام دهید تا مدل یادگیری ماشینی از ارتکاب یا تشدید سوگیریهای اجتماعی ناخواسته جلوگیری به عمل آورد؟ احتمالاً.
اینها کتابخانه های منبع بازی هستند که در انجام آزمایشهای تاثیر نابرابر، می توانند مفید واقع شوند؛ مِن جمله aequitas، AIF360 و Themis. روشهای بنیادی آزمایش تاثیر نابرابر، به بررسی نرخ خطا و دقت در متغیرهای جمعیتی میپردازند. رویکرد ایدهآل این است که بخواهیم نرخ خطا و دقت در همه گروههای جمعیتی مختلف برابر باشد. اگر این چنین نباشد، میتوان اینطور برداشت کرد که مدلتان مرتکب سوگیری اجتماعی ناخواسته شده یا این سوگیریها را تشدید کرده است.
در شکل 7، با توجه به متغیر SEX میبینیم که نرخ خطا و دقت برای مردان و زنان نسبتاً مشابه به نظر میرسند. این نشانه خوبی است، اما به این معنا نیست که مدلتان عاری از سوگیری اجتماعی ناخواسته است.
همه مدلها قادرند بر اساس تغییرات کوچکی که در دادههای ورودیشان به وجود میآورند، با افراد مشابه به شیوه متفاوتی برخورد کنند. این عامل منجر به سوگیری محلی یا بیعدالتی فردی Lack of individual fairness میشود. یکی از نمونههای سوگیری محلی این است که تمدید اعتبار را برای خانم جوانی در نظر بگیریم که سابقه پرداخت خوبی داشته و دارای درآمد 100.000 دلاری است و در عین حال، از اعطای چنین تسهیلاتی به خانم جوان مشابهی که درآمدی بالغ بر 99.999 دلار دارد، خودداری کنیم. میدانیم که اختلاف یک دلاری در میزان درآمد هیچ تفاوت بزرگی پدید نمیآورد، اما مدل یادگیری ماشینی میتواند این دو فرد مشابه را در دو سمت متفاوت از مرز تصمیمِ غیرخطی قرار دهد.
[irp posts=”3204″]مسئله بدتر این است که آزمایش استاندارد تاثیر نابرابر معمولاً به مسائل سوگیری محلی بیاعتنا است. چطور میتوان از برقراری عدالت و انصاف در سطح فردی اطمینان حاصل کرد؟ این پرسش تا به امروز بیپاسخ مانده و تلاشها برای پاسخ به آن ادامه دارد. پیشنهاد ما این است که با نزدیکترین فاصله به مرز تصمیم مدلتان به افراد نگاه کنید. در اکثر موارد، افراد خیلی مشابه نباید در سمت متفاوتی از آن مرز قرار داشته باشند.
حالا پیش از اینکه وارد بحثِ نرخ خطا و دقت شویم، اشاره به این نکته ضروری است که یادگیری ماشین میتواند پا را فراتر از این مباحث گذاشته و قابلیتهای بیشتری از خود نشان دهد. اگر میخواهید اطلاعات بیشتری درباره این مورد کسب کنید، به کنفرانس «انصاف، مسئولیتپذیری و شفافیت در یادگیری ماشین» یا به اختصار «FATML» و منابع مرتبط مراجعه کنید.

در کل میتوان از روشهای مرسومِ آزمایش تاثیر نابرابر در متغیرهای دستهای استفاده کرد. این روش به عنوان یکی از روشهای عالی برای تشخیص باگ در سیستم شناخته شده است. شکل 7 متریکهای گوناگون خطا و دقت را در سطوح دستهای مختلفی از متغیر مهم PAY_0 نشان میدهد.
در این بخش، تفاوت فاحش میان عملکرد M-GBM در PAY > 1 کاملاً مشهود است. احتمال میرود پراکندگی دادههای آموزشی در آن قلمرو عامل اصلیِ بروز چنین تفاوتی بوده باشد. این جدول به خوبی نشان میدهد که عملکرد مدل در این قلمرو تا چه حد شکننده و آسیبپذیر است و اینکه عملکرد مدل تا چه حد در PAY > 1 فرق دارد. امکانِ بهکارگیری این روش تشخیص باگ، در متغیرهای عددی وجود دارد.
توضیح باقیماندهها
در سالهای اخیر شاهد ارائه روشهای گوناگونی برای توضیحِ پیشبینیهای مدل یادگیری ماشینی بودهایم. از این روشها میتوان برای ارتقای تحلیل باقیمانده نیز استفاده کرد. همچنین میتوان به ارائه توضیحات تفسیرپذیرِ محلی و وابستگی جزئی پرداخت یا نمودارهای انتظار شرطی از باقیماندهها را ترسیم کرد.
موارد جدیدی که اخیراً به بسته Shap اضافه شده، زمینه را برای محاسبه نقش Shapley در باقیماندهها فراهم کرده است؛ یعنی میتوانید به خوبی تشخیص دهید که کدام متغیرها چه به صورت محلی (تک ردیفی) و چه به صورت جمعی (تمام دیتاست) منجر به افزایش خطا میشوند.
یکی دیگر از گزینهها برای تبیینِ باقیماندهها این است که مدلی را بر روی آنها آموزش دهیم. شکل 8 درخت تصمیمی را نشان میدهد که متناسب با M-GBM است. در این شکل میبینیم که چرا مدل M-GBM نکولهای آتی را در نظر نگرفته است.

درخت تصمیم Decision tree در شکل 8 دارای مربع مجذور 0.89 و خطای درصد مطلق میانگینی در حدود 17 درصد برای باقیماندههای DEFAULT_NEXT_MONTH = 1 است. پس نسبتاً دقیق است؛ یعنی در درک الگوهای داده ها خوب عمل کرده و لذا در شناخت حدسهای اشتباه M-GBM قوی می باشد. بزرگترین باقیماندهها برای PAY_0 < 0.5 AND PAY_AMT2 < NT$ 2802.5 AND PAY_4 < 1 AND PAY_AMT2 ≥ NT$ 1312.5 یا به مشتریانی با سوابق پرداخت خوب تعلق دارد.
تحت این شرایط، میدانیم که مدل M-GBM غالباً در پیشبینی پرداختهای آتی ناکام است. این سیاستِ تصمیم برای باقیماندهها بر نتایج پیشین اشاره میکند و این نتایج تاکید مضائف بر PAY_0 دارند، اما سرنخی در اختیارمان میگذارند تا آن دسته از مشتریانی را که پرداختهای اخیرشان بین 1300 دلار تا 2800 دلار بوده، بیشتر بررسی کنیم.
مدلهای معیار
مدلهای معیار به مدلهای باثبات، قابل اطمینان و شفافی اطلاق میشود که نقشِ مدلهای خطی، درخت تصمیم، مدلهای قانونمحور یا مدل یادگیری ماشینی را ایفا میکنند. باید همیشه به این نکته توجه داشت که مدل یادگیری ماشین جدیدتان عملکرد بهتری از یک معیار شناخته شده در دادههای آزمایشی داشته باشد. اگر مدل یادگیری ماشین جدیدتان از مدل معیار بهتر عمل نکند، لطفاً از آن استفاده نکنید.
به مجرد اینکه اطمینان حاصل کردید مدل یادگیری ماشینتان دستکم دقیقتر از یک مدل معیار ساده است، آن مدل میتواند به عنوان یک ابزار اشکال زدایی قوی مورد استفاده قرار گیرد. ما از مدلهای معیار برای بررسی این قبیل از مسائل استفاده میکنیم: کدام داده ها توسط مدل من اشتباه پیش بینی شد که روش معیار آنها را درست پیش بینی کرده بود.
اگر بتوانید رفتار اشتباه مدل خودتان را از مدل یادگیری ماشینی تفکیک کنید، در ادامه می توانید با ادغام پیشبینیهای مدل معیار با پیشبینیهای مدل یادگیری ساخته شده را به عنوان یک رویکرد تازه در نظر بگیرید تا دقت پیشبینیها را ارتقا دهید. همچنین، احتمالاً میتوانید به این شکل استدلال کنید چرا مدلهای شفاف، در برخی از زیرمجموعه های داده ها رفتار بهتری از خود نشان میدهند. بدین ترتیب، میتوانید استراتژیهای درمانی یا ترمیمی بالقوهای را ایجاد کنید.
برای مثال، اگر مدلهای یادگیری ماشینی که عملکرد نامناسبی دارند را با مدلهای خطی مقایسه کنیم، میبینیم که یکی از دلایل احتمالی بیدقتی مدل یادگیری ماشین، تاکید بیش از حد به برهمکنشهای ضعیف در مدل یادگیری ماشین است. افزون براین، میتوان از مدلهای معیار برای شناسایی نابهنجاریها استفاده کرد.
در اکثر نسبتهای سیگنال به نویز، مسائل یادگیریِ ماشین مبتنی بر انسان و پیشبینی مدل یادگیری ماشین و مدل ساده نباید تفاوت چشمگیری با یکدیگر داشته باشند. مقایسۀ پیشبینیهای مدل معیار و مدل یادگیری ماشین میتواند نقش موثری در تشخیص نابهنجاریهای امنیتی، عدالتی و بیدقتی داشته باشد.
حسابرسی امنیتی Security Audits برای حملات یادگیری ماشینی
مدلهای یادگیری ماشین با حملات گوناگونی مواجه میشوند. این حملات میتوانند موجب تغییر مدلها شده یا صدمات عمیقی به آنها وارد کنند. شکل 9 برخی از متداولترین حملات یادگیری ماشین را به تصویر کشیده است. متاسفانه، معیارهای مرسوم ارزیابی مدل، اطلاعات زیادی درباره امنیت مدل در اختیارمان نمیگذارند. افزون بر سایر مراحل اشکال زدایی، میتوان در اقدامی زیرکانه همه یا قسمتی از حملاتی را که علیه یادگیری ماشین هستند، به فعالیتهای هک کلاهسفیدها اضافه کرد.

راهبردهای ترمیم گونه
حالا که چند روش نظاممند برای تشخیص مسائل دقت، عدالت و امنیت در سیستمهای مبتنی بر یادگیری ماشین پیدا کردهایم، بیایید ببینیم چه راهبردهایی برای حل مسائلِ شناسایی شده وجود دارد.
افزایش داده Data augmentation
اگر مدلتان خطاهای منطقی در رابطه با کمبود داده داشته باشد، احتمالاً به دادههای بیشتری احتیاج دارید. شاید قادر به شبیهسازیِ دادههای مورد نیاز خود باشید، آن دادهها را وارد دادههای آموزشیتان کنید، مجدداً به آموزش مدلتان بپردازید و نهایتاً آن را آزمایش کنید. به احتمال زیاد، دوباره به وایتبورد مراجعه خواهید کرد تا در خصوص نحوه گردآوری دادههای آموزشی تجدیدنظر کنید.
شاید تا زمانی که دادههای بیشتری در دسترستان قرار گیرد، صبر کنید. برای اینکه در آینده با این نوع از مشکلات روبرو نشوید، استفاده از روشهای طراحی آزمایشی را در دستور کار قرار دهید. در مثالهایی که در مقاله حاضر به آنها اشاره شد، گردآوری اطلاعات درباره نسبت بدهی به درآمد یا وضعیت اشتغال، نقش مفیدی در تاکیدزدایی از PAY_0 در مدل M-GBM داشته است.
افزایش داده میتواند استراتژی مناسبی برای کاهش سوگیری اجتماعی ناخواسته در مدلهای یادگیری ماشین باشد.
یکی از دلایل اصلی سوگیری اجتماعی در یادگیری ماشین، آن دسته از دادههای آموزشی است که از منظر جمعیتشناختی نامتوازن هستند. اگر قرار باشد مدلتان در کلیه افراد استفاده شود، باید از این نکته اطمینان حاصل کرد که دادههای آموزشی دارای توزیعی از همه افراد است.
بررسی نویز و منظمسازی regularization قوی
امروزه خیلی از افراد به استفاده از روشهای جریمه ای regularization L1 و L2 در مدلهای یادگیری ماشین خود روی آوردهاند و باید به این رویه ادامه داد. متاسفانه، شاید بسیاری از روشهایِ استاندارد عادیسازی قادر به فائق آمدن بر سوگیریهای قوی، همبستگی correlation یا وابستگیها در دادههای آموزشی نباشند. این امر در PAY_0 بیشتر به چشم میخورد.
یکی از راهکاری بالقوه این است که میزانregularization L2 L1 – را افزایش دهیم. اگر این راهکار به قدر کافی قوی و کارساز نباشد، باید معیارهای دیگری از قبیل عادیسازی L∞، weight-clipping، dropout یا روشهای تزریق نویز noise-injection را به کار گرفت. بهکارگیری این قبیل از روشها برای رفع اشکالات دادههای آموزشی میتواند بدین معنا باشد که گردآوری داده با مشکل روبرو شده است. در چنین شرایطی، میتوان «افزایش داده» را به عنوان یکی از روشهای موثر برای رفع مسئله در نظر گرفت.
ویرایش مدل
برخی از مدلهای یادگیری ماشین به گونهای طراحی شدهاند که قابلتفسیر باشند و افراد به طور مستقیم نحوه کار آنها را یاد بگیرند. بعضی از این مدلها مثل انواعی از مدلهای درخت تصمیم یا GA2M به طور مستقیم توسط کاربران انسان ویرایش میشوند. اگر موردی را در سازوکار درونیِ مدل GA2M مشاهده کنید که مورد پسندتان نیست، به سادگی میتوانید معادله را در مدل تغییر دهید تا مشکل را رفع کنید. شاید ویرایش برخی از مدلها به سادگیِ درختهای تصمیم یا GA2M نباشد، اما اگر کد امتیازبندی خوانا تولید کنند، میتوانید به ویرایش آنها بپردازید.
اگر قوانین اشتباهِ زیادی در کد امتیازبندیِ M-GBM وجود داشته باشد، شاید بتوانید آن قوانین را اصلاح یا حذف کنید. توصیه ما این است که از GA2M استفاده کنید و ویرایش مدلهای دیگر را هم به عنوان یکی دیگر از راهبردهای اشکال زدایی مد نظر قرار دهید.
اما نکتهای که در خصوص ویرایش مدل، باید توجه داشته باشید این است که شاید باعث شود مدلتان عملکرد بدی در دادههای آموزشی یا اعتبارسنجی داشته باشد. اگر میخواهید مدلی را ویرایش کنید، باید استدلال محکمی برای پشتیبانی از این تصمیم داشته باشید.
تصریح مدل Model Assertions
تصریح مدل، از جمله قواعد کاری پساپیشبینی، در پیشبینی مدل نقش دارد و میتواند به تصحیح پیشبینیهای مشکلزا و اشتباهِ مدل کمک کند. در مثالی که آوردیم، اگر مشتری در پرداخت هزینه یک ماه تاخیر میکرد، مدل M-GBM قادر نبود پیشپرداخت یا پرداخت اضافه را به خوبی درک کند. قبل از اتخاذ تصمیم نهایی، بهتر است این موضوع بررسی شود که آیا مشتری در آخرین پرداخت خود چطور عمل کرده است.
کاهش سوگیری اجتماعی ناخواسته
امروزه، راهکارهای انسانی و فنی زیادی برای رفع و کاهش سوگیری اجتماعی ناخواسته در مدلهای یادگیری ماشین وجود دارد. بسیاری از راهکارهای انسانی برای رفع این مشکل به تنوع عقاید و تجارب در خصوص تیمهای علوم داده تاکید دارند. همچنین، این راهکارها روی بهکارگیری متخصصان مختلف در تمامی مراحل مدلسازی توجه دارند. روشهای فنّیِ کاهش سوگیری در سه دسته جای میگیرند:
• پیشپردازش preprocessing داده:
1. انتخاب عاقلانه ویژگی Judicious feature selection
2. ردیفهای وزنگیری و نمونهگیری در دادههای آموزشی برای کاهش حداقلیِ سوگیری اجتماعی ناخواسته در دادههای آموزشی
• آموزش و انتخاب مدل:
1. در هنگام انتخاب پارامترها و آستانهها، استفاده از متریک انصاف را در نظر بگیرید.
2. آموزش مستقیمِ مدلهای منصفانه:
– کاهش سوگیری تخاصمی در AIF360.
– استفاده از توابع هدف دوگانه که به متریک دقت و انصاف توجه دارند.
• پیشپردازش پیشبینی:
تغییر پیشبینیهای مدل پس از آموزش
اختصاص دادنِ دو پاراگراف به موضوعِ حل سوگیریهای اجتماعی ناخواسته در مدلهای یادگیری ماشین در سال 2019 به هیچ وجه کفایت نمیکند. امروزه روشهای زیادی برای رفع سوگیریهای اجتماعی ناخواسته وجود دارد. میتوانید اطلاعات بیشتری درباره آنها به دست آورید. امروزه، دیگر هیچ بهانهای برای استفاده از مدلهایی که جانب داری نژادی انجام می دهند وجود ندارد، اما کماکان شاهد این اتفاق هستیم.
مدیریت و نظارت بر مدل
باید از تعداد مدلهایی که دارید باخبر باشید؛ باید بدانید مدلها را چه کسانی و در چه زمانی آموزش دادهاند، باید آنها را مثل سایر نرمافزارها دستهبندی کنید، باید به پیشبینیها و ورودیهای مدل یادگیری ماشین نظارت کنید، باید مراقب نابهنجاریها باشید و فقط بر روی دقت تمرکز نکنید، باید درباره مسائل امنیتی و انصاف نیز فکر کنید.
امروزه، اکثر متخصصان داده به این باور رسیدهاند که مدلها با دادههایی که دورنمایی از واقعیت ارائه میدهند، آموزش داده میشوند. واقعیت با گذشت زمان تغییر مییابد. دادههای جدید از این چشمانداز فاصله میگیرند و شاید دقت مدل در دادههای جدید کاهش پیدا کند. این وضعیت در بررسیهای آماریِ مربوط به پیشبینیها و ورودیهای مدل کاملاً مشهود است. آیا این امر میتواند بر خصوصیات انصافِ یک مدل نیز تاثیر داشته باشد؟ احتمالاً.
بنابراین، علاوه بر اینکه باید به پیشبینیها و ورودیها نظارت داشته باشید، باید گزینه آزمایش را همیشه مد نظر قرار دهید تا تاثیر نابرابر را نیز شناسایی کنید. سرانجام، وقتی تصمیم به یافتن جایگزینی برای مدلی قویتر میگیرید، آن مدل باید غیرفعال شده و از رده خارج شود. یعنی این مدل باید به دقت برای نیازهای تشخیصی، قضایی و… ذخیره شود. نباید مدلهای مهم را به این سادگی حذف کرد.
شناسایی نابهنجاریها Anomaly Detection
پیشبینیها و ورودیهای غیرطبیعی همیشه نگرانکننده هستند. اینها گاهیاوقات نشان میدهند که مدلتان مورد حملات خصمانه قرار گرفته است. در M-GBM دیدیم که مدل حساسیت بالایی به مقادیر نامعلوم در PAY_0 دارد. در این مورد، نباید مقادیر نامعلوم و سایر مقادیر غیرمنطقی را به فرایند امتیازدهی پیشبینی M-GBM راه داد.
برای اینکه پیشبینیهای غیرطبیعی را در زمان واقعی شناسایی کنید، به روشهای کنترل فرایند آماری سنتی بیاندیشید؛ پیشبینیهای مدل یادگیری ماشینی را با پیشبینیهای مدل بنچمارک باثبات و شفاف مقایسه کنید؛ به چگونگی راه یافتنِ دادههای جدید به مدل خود نظارت کنید.
در مدلهای بنچمارک، پیشبینیهای مدل یادگیری ماشین را با پیشبینیهای مدل بنچمارک مقایسه کنید. اگر این پیشبینیها متفاوت باشند، قبل از تایید پیشبینی، نگاه دقیقتری بیندازید و یا فقط از پیشبینیهای مدل بنچمارک برای این دادهها استفاده کنید. در انجام تحلیل فعالسازی، Activation analysis دادههای جدید نباید به طور عادی در آن دسته از سازوکارهای مدل که به طور مکرر در طول آموزش مدل فعالسازی نشدهاند، جریان پیدا کند. اگر این اتفاق به کرّات روی میدهد، بهتر است آن را بررسی کنید.