ساخت سرورهای یادگیری ماشین
 تیم تحریریه
تیم تحریریه- ۹ خرداد ۱۴۰۱
چگونه (API) کاربردی رابط برنامهنویسی Application Programming Interface (API) قوی بنویسیم؟ علاقه من به مهندسی تولید و طراحی سیستم به طور مداوم افزایش مییابد. پیش از این مقالهای با موضوع مراحل استقرار یک مدل در کاربرد واقعی نوشتم اما در آن مقاله مراحل ساخت سرورهای یادگیری ماشین را با جزئیات شرح ندادم. اگر فرایند ساخت مدلهای یادگیری با نظارت/ بدوننظارت را به اتمام رساندهاید، اکنون باید یک API برای استفاده از آن مدل (مرحله استنتاج) بسازید. در مقاله پیشرو، به مطالعه مبانی سرویسدهی به مدل یادگیری ماشین و چگونگی استقرار آن بر روی واحد پردازش مرکزی (CPU) / و واحد پردازش گرافیکی (GPU) و در مجموع ساخت سرورهای یادگیری ماشین خواهیم پرداخت.
استقرار CPU
در این بخش شیوه نوشتن APIها برای استقرار روی CPU را بررسی میکنیم.
در این بخش به مطالعه و بررسی موارد زیر خواهیم پرداخت:
- صفهای وظیفه Task queues
- مفاهیم حافظه کَش
- مفاهیم کارگر worker
Framework combo → Fastapi + uvicorn + huey + redis
صفهای وظیفه

چرا صف؟
سرورهای یادگیری ماشین از قبیل flask و uvicorn از صف فراخوانهای API پشتیبانی نمیکنند و وظایف به صورت پیشفرض به صورت همزمان اجرا میشوند. این قابلیت به شما کمک میکند بهتر از سرور استفاده کنید. اما اگر باید APIها را حذف و یا بهروز رسانی کنید، ممکن است مجبور شوید حالت سرور را تغییر دهید.
زمانیکه فراخوانیهای همزمان تلاش میکنند به اشیای یکسانی در حافظه دسترسی پیدا کنند که تغییر میکنند و به صورت همزمان میتوان به آنها دسترسی پیدا کرد، تغییر حالت سرور باعث ایجاد بینظمی میشود. در نتیجه در مواقعیکه همزمانی باعث بروز مشکل میشود، به یک مکانیزم صفبندی نیاز خواهید داشت.
برای حل این مشکل بهتر است وظایفی ایجاد کنید و آنها را به صفی که در اختیار کارگر است ارسال کنید و کارگر به صورت ترتیبی آنها را اجرا میکند. اما مشکلی که در اینجا با آن مواجه هستیم این است که اگر صف طولانی شود، پاسخ کند میشود. در صورتیکه پاسخ به فراخوان یک پاسخ ثابت و واحد مثل « x بهروز رسانی خواهد شد» باشد میتوانید وظایف را به صورت ناهمزمان درآورید و یک پاسخ ثابت به واحد ارائه دهید.
نظریه صفبندی عمومی
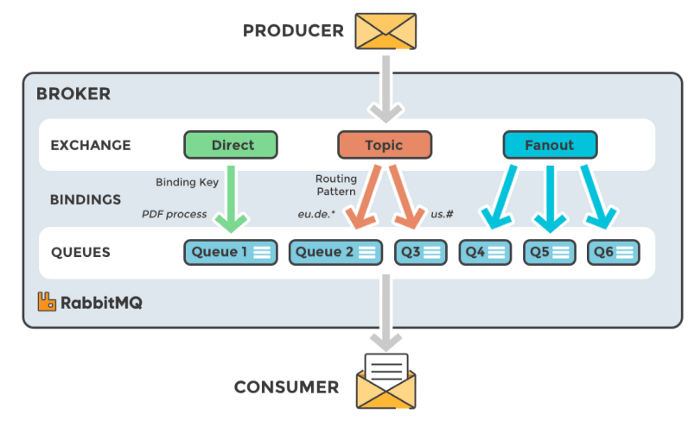
تولیدکنندگان – کدی که وظایف را به صفها ارسال میکند.
تبادلکنندگان – تصمیم میگیرد که پیام در کدام صف باید ذخیره شود.
- Direct ( پیامی به همراه جدول مربوطه به صف ارسال میکند)
- Topic ( پیامی به صف ارسال میکند که با یک الگوی مسیریابی خاص مطابقت دارد)
- Fan out ( یک پیام به تمامی صفها ارسال میکند)
صفها – مباحثی که تا به اینجا ارائه دادیم، تعریفی از صف بوده است. صف فهرستی از وظایف برای کارگرها/ مصرفکنندگان دارد.
مصرفکنندگان – مصرفکنندگان (کارگر) که کارگرها هم نامیده میشوند، وظیفه اجرای وظایف را بر عهده دارند. در هر زمانی میتوان کارگرها را پیکربندی کرد تا بر روی یک صف خاص کار کنند. (RabbitMQ/ Redis کارگرهای مخصوص به خود ندارند و در نتیجه به کارگرهای وظیفه همچون Celery متکی هستند.)
صف وظیفه Huey
بسیاری از مردم برای صف وظیفه از Celery استفاده میکنند اما برای استفاده مناسب از Celery باید دانش کافی نسبت به آن داشته باشید علاوه بر آن Celery ویژگیهایی دارد که ممکن است شما به آنها نیاز نداشته باشید. به عقیده من huey جایگزین مناسبی برای Celery است.
مقایسه RQ، Celery و huey
- Celery از RabbitMQ، Redis و Amazon SQS پشتیبانی میکند. RQ فقط با Redis کار میکند. huey با Redis و sqlite کار میکند.
- Celery و huey از وظایف برنامهریزیشده پشتیبانی میکنند.
- Celery از زیروظیفهها پشتیبانی میکند اما RQ و huey از آنها پشتیبانی نمیکنند.
- RQ و huey از صفهایی که اولویت بیشتری دارند پشتیبانی میکنند. در Celery تنها روش پشتیبانی از صفهایی با اولویت بیشتر این است که وظایف را به یک سرور متفاوت مسیریابی کرد.
- RQ و huey فقط با زبان پایتون نوشته میشود اما Celery را علاوه بر پایتون با go و node هم میتوان نوشت.
انواع صف
تمامی وظایف خود را در core.py بنویسید.
# In core.py
from huey import RedisHuey, PriorityRedisHuey, RedisExpireHuey
huey = RedisHuey('worker') #simple FIFO queue
huey = PriorityRedisHuey('worker') #queue with task priorities
huey = RedisExpireHuey('worker') #queue which persists response in redis for only some time to save space
وظایف مختلف
وظایفی با اولیت 10 ( 10 اولویت بیشتری نسبت به 1 دارد)
@huey.task(priority=10, retries=2, retry_delay=1) def predict_task(name:str): ...
وظایف دورهای از قبیل واکشی دادهها Fetching data و بهروز رسانی دادهها
@huey.periodic_task(crontab(minute='0',
hour='*/3'), priority=10)
def some_periodic_task():
# ...
کارگر وظیفه huey
کارگری که خطاها را ثبت میکند آغاز کنید
huey_consumer.py core.huey --logfile=logs/huey.log -q
FastAPI
-
- سریعترین – از آنجاییکه fastapi برای باندهای ورودی خروجی سریعترین است، API را مطابق با این دستورالعمل بنویسید و دلایل آن هم در این مطلب توضیح داده شده است.
- مستندسازی – نوشتن API در fastapi مستندسازی رایگان و همچنین نقاط انتهایی آزمایش را در اختیار ما قرار میدهد که همزمان با اینکه ما کد را تغییر میدهیم، fastapi به صورت خودکار آنها را تولید و بهروز رسانی میکند.
- اعتبارسنجی – با بهرهگیری از pydantic از اعتبارسنجی نوعداده پشتیبانی میکند
- کارگرها – با استفاده از uvicorn، رابط برنامهنویسی کاربردی را برای بیش از یک کارگر مستقر میکنند.
- از فراخوانهای ناهمزمان پشتیبانی میکند
- وظایف پسزمینه
اسناد رابط برنامهنویسی کاربردی Swagger
این سند توسط fastapi به صورت خودکار در http:url/docs ساخته میشود

وظایف ناهمزمان
به هر دلیلی ممکن است بالافاصله به نتایج احتیاج نداشته باشید. در این حالت میتوانید وظایف را به صورت ناهمزمان درآورید.
from fastapi import FastAPI
import core
app = FastAPI()
@app.get("/api/v1/predict/{name}")
def predict(name:str):
core.predict_task(name)
#This is asynchornous
return f"predict will be executed with
{name}"
وظایف همگام
به دلایلی ممکن است بالافاصله به نتایج احتیاج داشته باشید. در این حالت میتونید وظایف را همگام کنید.
import core
@app.get("/api/v1/predict/{name}")
def predict(name:str):
return core.predict_task(name)
(blocking=True) # synchornous
مفاهیم حافظه کَش
اندازه حافظه کَش ← مطابق با نیاز، محاسبه سرور و ذخیرهسازی بهینهسازی میشود.
سیاست پاکسازی حافظه کَش ← با توجه به اینکه نمیتوانیم همهچیز را در حافظه کَش ذخیره کنیم، باید آیتمهایی که کاربردهای کمتری دارند را حذف کنیم.
- مدت زمان اعتبار حافظه کَش (TTL) TTL (Time To Love) cache
حافظه کَش را پس از آنکه برای آخرین بار استفاده شد تا مدت زمان مشخصی نگه میدارد.
- حافظه کَش دورترین به کار رفته (LRU) LRU (Least Recently Used) cache
LRU – صف FIFO. در این حالت آیتمهای قدیمی از صف کَش پاک میشوند.
- حافظه کَش با کمترین فروانی به کار رفته (LFU) LFU (Least Frequently Used) cache
LFU – آمار آیتمهایی که درخواست برای آنها بیشتر است را دارد و آیتمهایی که بیشتر مورد استفاده قرار میگیرند را نگه میدارد.
اکثر مردم در عمل از LRU استفاده میکنند چرا که اندازه حافظه کش و تأخیر را تضمین میکند.
from huey import RedisHuey, PriorityRedisHuey,
RedisExpireHuey
from cachetools import LRUCache, cached
huey = RedisHuey('worker')
cache = LRUCache(maxsize=10000)@huey.task(priority=10, retries=2, retry_delay=1)
@cached(cache)
def predict_task(name:str):
...
مفاهیم کارگر
در صورتیکه یک ماشین چندهستهای در اختیار دارید، میتوانید بیشتر از یک کارگر را آغاز کنید تا توان عملیاتی سرورهای یادگیری ماشین را افزایش دهید. هر کارگر در درون خود شبیه به یکی از سرورهای یادگیری ماشین فعالیت میکند. حداکثر تعداد کارگرها را هستهها و RAM مشخص میکنند. نمیتوان کارگرهایی بیشتر از RAM/ اندازه مدل شروع کرد و علاوه بر آن نباید کارگرهایی بیشتر از 2 هسته + 1 را شروع کنید.
ثبت
به عقیده من به اندازه کافی به ثبت توجه نشده است.
Uvicorn از فایلهای ثبت سرور پشتیبانی میکنند.
پیکربندی مقابل را در config/logger.config ذخیره کنید.
این پیکربندی فایلهای ثبت 7 روز گذشته را نگه میدارد و شما میتوانید آنها را اشکالزدایی کنید.

سرور را آغاز کنید
mkdir logs uvicorn main:app --workers 1 --host 0.0.0.0 --port 8000 --log- config config/logger.config
استقرار GPU
در این مرحله نگاهی خواهیم انداخت به مبحث دستهسازی Batching و اینکه چگونه میتوانیم با استفاده از دستهها از مزایای GPUها بهرهمند شویم.
Framework combo1 → Fastapi + uvicorn + huey
Framework combo2 → Tensorflow serving
دلیل اینکه از GPU استفاده میکنیم این است که با استفاده از CUDA موجود در GPUها میتوانیم به سرعت ماتریسها را ضرب کنیم. برای دستیابی به نتایج قابلقبول باید درخواستها را در دستهها پردازش کنیم.
مفاهیم دستهسازی
بدون دسته
در تصویر مقابل چگونگی پردازش درخواستها بدون دسته نشان داده شده است.

با دسته
در تصویر مقابل چگونگی عملکرد دستهسازی نشان داده شده است. درخواستها بالافاصله پردازش نمیشوند، بلکه پس از مدتی تأخیر در دستهها پردازش میشوند.

تنها پس از استقرار GPU میتوان دستهسازی را انجام داد و هزینه استقرار GPU بسیار گرانتر از هزینه استقرار CPU است.
فقط زمانی میتوانید GPU را مستقر کنید که خروجی کافی برای توجیه هزینه و تأخیر داشته باشید.
همانگونه که در تصویر مقابل مشاهده میکنید پس از مقدار مشخصی از خروجی، عملکرد دستهسازی در مقایسه با بدون دستهسازی ارتقا پیدا میکند.

مفاهیم پیشرفته دستهسازی
در ادامه مقاله ساخت سرورهای یادگیری ماشین باید بگوییم که مفاهیم دیگری در حوزه دستهسازی وجود دارد که همانگونه که در ابتدای این مقاله گفتیم، در چارچوبهایی از جمله clipper مورد استفاده قرار میگیرند.
هدف دستهسازی تطبیقی Adaptive batching این است که اندازه مناسب را برای یک دسته مشخص پیدا کند. یکی از روشهایی که clipper برای یافتن اندازه مناسب برای یک دسته به کار میبندد استفاده از روش « افزایش جمعی/کاهش ضربی Additive increase multiplicative decrease (AIMD)» است.
به عبارت دیگر clipper به طور مداوم اندازه دسته را افزایش میدهند تا زمانیکه به SLOها دست پیدا کند. همزمان با اتمام تأخیر SLO، اندازه دسته چند برابر افزایش پیدا میکند. این روش آسان و کارآمد است و روشی است که clipper به طور پیشفرض ارائه میدهد. روش دیگری که نویسندگان مورد مطالعه و بررسی قرار دادند استفاده از یک رگرسیون چارکی Quantile regression در صدک 99ام تأخیر است و ماکسیسم ندازه دسته را هم مطابق با همان تنظیم میکنند. این روش همانند AIMD عمل میکند و به دلیل پیچیدگیهای محاسباتی رگرسیون چارکی پیادهسازی و اجرای آن آسان نیست.
زمانی که بارکاری انفجاری یا متوسط باشد میتوان از دستهسازی تأخیردار Delayed batching استفاده کرد. در برخی موارد ممکن است نتوانیم به اندازه بهینه دسته که برای یک چارچوب خاص انتخاب شده دست پیدا کنیم. در اینگونه موارد، دستهها میتوانند چند میلیثانیه تأخیر داشته باشند تا درخواستهای بیشتری جمعآوری شود.
پیادهسازی سفارشی دستهسازی
1 import threading
2 import time
3 from queue import Empty, Queue
4
5 import numpy as np
6 from flask import Flask, request as flask_request
7
8 from build_big_model import build_big_model
9
10 BATCH_SIZE = 20
11 BATCH_TIMEOUT = 0.5
12 CHECK_INTERVAL = 0.01
13
14 model = build_big_model()
15
16 requests_queue = Queue()
17
18 app = Flask(__name__)
19
20
21 def handle_requests_by_batch():
22 while True:
23 requests_batch = []
24 while not (
25 len(requests_batch) > BATCH_SIZE or
26 (len(requests_batch) > 0 and time.time() - requests_batch[0]['time'] > BATCH_TIMEOUT)
27 ):
28 try:
29 requests_batch.append(requests_queue.get(timeout=CHECK_INTERVAL))
30 except Empty:
31 continue
32
33 batch_inputs = np.array([request['input'] for request in requests_batch])
34 batch_outputs = model.predict(batch_inputs)
35 for request, output in zip(requests_batch, batch_outputs):
36 request['output'] = output
37
38
39 threading.Thread(target=handle_requests_by_batch).start()
40
41
42 @app.route('/predict', methods=['POST'])
43 def predict():
44 received_input = np.array(flask_request.json['instances'][0])
45 request = {'input': received_input, 'time': time.time()}
46 requests_queue.put(request)
47
48 while 'output' not in request:
49 time.sleep(CHECK_INTERVAL)
50
51 return {'predictions': request['output'].tolist()}
52
53
54 if __name__ == '__main__':
55 app.run()
ثبت
ثبت فرایندی خستهکننده است و به همین دلیل آن را نادیده میگیریم. این یک ماژول برای ثبت سفارشی است که میتوانید در نقاط مختلف کد از آن استفاده کنید.
1 import datetime
2 import json
3 import logging
4 import ntpath
5 import os
6
7
8 def create_folder(directory):
9 try:
10 if not os.path.exists(directory):
11 os.makedirs(directory)
12 print('Directory created. ' + directory)
13 except OSError:
14 print('Directory exists. ' + directory)
15
16
17 def create_logger(level='DEBUG', log_folder='logs', file_name=None, do_print=False):
18 """Creates a logger of given level and saves logs to a file of __main__'s name
19 LEVELS available
20 DEBUG: Detailed information, typically of interest only when diagnosing problems.
21 INFO: Confirmation that things are working as expected.
22 WARNING: An indication that something unexpected happened, or indicative of some problem in the near future (e.g. 'disk space low'). The software is still working as expected.
23 ERROR: Due to a more serious problem, the software has not been able to perform some function.
24 CRITICAL: A serious error, indicating that the program itself may be unable to continue running.
25 """
26 import __main__
27 if file_name is None:
28 file_name = ntpath.basename(__main__.__file__).split('.')[0]
29
30 logger = logging.getLogger(file_name)
31 logger.setLevel(getattr(logging, level))
32 formatter = logging.Formatter(
33 '%(asctime)s:%(levelname)s:%(module)s:%(funcName)s: %(message)s', "%Y-%m-%d %H:%M:%S")
34 stream_formatter = logging.Formatter(
35 '%(levelname)s:%(module)s:%(funcName)s: %(message)s')
36
37 # formatter = logging.Formatter('%(message)s')
38 # stream_formatter = logging.Formatter('%(message)s')
39
40 date = datetime.date.today()
41 date = '%s-%s-%s' % (date.day, date.month, date.year)
42 log_file_path = os.path.join(log_folder, '%s-%s.log' % (file_name, date))
43
44 create_folder(log_folder)
45 file_handler = logging.FileHandler(log_file_path)
46 file_handler.setFormatter(formatter)
47
48 stream_handler = logging.StreamHandler()
49 stream_handler.setFormatter(stream_formatter)
50
51 logger.addHandler(file_handler)
52 if do_print:
53 logger.addHandler(stream_handler)
54
55 logger.propagate = False
56
57 return logger
کنترل
یک مانیتور برای کنترل و نظارت بر وضعیت API داشته باشد تا زمانیکه سرویس با مشکل مواجه میشود به شما اطلاع دهد. بسیاری مواقع این مورد نادیده گرفته میشود.
کدهای وضعیت HTTP
ما به عنوان متخصصین علوم داده معمولاً دانش کافی در اختیار نداریم و بهتر است خطاهای کد که در مقابل به آنها اشاره شده را به خاطر بسپاریم
- 400 Bad Request – ورودی سمت کلاینت نادرست است.
- 401 Unauthorized – کاربر مجاز به دسترسی به منبع نیست. این خطا معمولاً زمانیکه اعتبار کاربر اثبات نشده باشد، نشان داده میشود.
- 403 Forbidden – اعتبار کاربر اثبات شده اما اجازه دسترسی به یک منبع را ندارد.
- 404 Not Found – منبع پیدا نشد.
- 500 Internal server error – یک خطای عمومی سرور است.
- 502 Bad Gateway – پاسخ مناسبی از سرورهای بالادست Upstream server دریافت نشد.
- 503 Service Unavailable – اتفاقی غیرمنتظره در سمت سرور رخ داده است ( این اتفاق میتواند هرچیزی از جمله ترافیک زیاد سرور، از کار افتادن بخشهایی از سیستم و غیره باشد.)
تست API
تست API اهمیت زیادی دارد چرا که ممکن است مدلها سنگین باشند و API CPU را محدود کنند. در ادامه مقاله ساخت سرورهای یادگیری ماشین با استفاده از نرمافزار کاربردی یا وبسایت خود و یا با همفکری با همتیمیهای خود موارد کاربرد API را برآورد کنید. برای تست API باید چهار نوع تست انجام دهید
- تست عملکرد Functional testing ( برای مثال خروجی مورد انتظار برای یک ورودی مشخص)
- تست آماری Statistical testing ( برای مثال API را بر روی 1000 درخواست کاملاً جدید تست کنید و توزیع کلاس پیشبینیشده باید با توزیع آموزشی مطابقت داشته باشد)
- رفع اشکال Error handling ( برای مثال اعتبارسنجی نوع داده درخواستی)
- تست بار Load testing ( n کاربر به صورت همزمان درخواست x زمان/ دقیقه میکنند)