
سرعت دادن به شبکه های عصبی عمیق
تیم تحریریه
- ۲ آذر ۱۴۰۰
در این مقاله سعی داریم به سرعت دادن به شبکه های عصبی بپردازیم. شبکه های عصبی امروزی معمولاً عمیق هستند، بدین معنی که میلیونها وزن و تابع فعالسازی دارند. برای نمونه میتوان به GoogleNet و ResNet50 اشاره کرد. این مدلهای بزرگ به شدت محاسباتمحور هستند و حتی با سختافزارهای شتابدهنده بسیار قوی نیز استنتاج (ارزیابی شبکه) در آنها زمانبر خواهد بود.
شاید فکرکنید که تأخیر تنها در موارد خاصی همچون وسایل نقلیه خودران مشکلزاست، اما واقعیت این است که هرزمان که داریم با تلفنهای همراه یا کامپیوترهایمان کار میکنیم در معرض این تأخیر هستیم. طبیعی است که دوست نداریم منتظر نتایج جستجو بمانیم یا معطل بارگذاری یک برنامه یا صفحهی اینترنتی باشیم، مخصوصاً برایمان پذیرفتنی نخواهد بود که این تأخیر در آن تعاملات و کاربردهایی اتفاق بیفتند که نیاز به پاسخ درجا و فوری دارند (مثل تشخیص گفتار).
بنابراین میتوانیم با اطمینان خاطر بگوییم که تأخیر در استدلال مشکلی است که تمایل داریم آن را به حداقل ممکن برسانیم. این مقاله مقدمهای در بحث فشردهسازی و تسریع شبکه های عمیق به منظور استنتاج کارآمد است.
در این پست در مورد این موضوعات به صورت تقرییاً کامل و جامع صحبت خواهیم کرد (برای اینکه روشهای بیان شده را بهتر درک کنید، پیشنهاد میشود به خود مقالههای منبع مراجعه کنید):
- هرس و اشتراک گزاری
- فاکتورگیری حداقلی
- فیلترهای پیچشی فشرده
- تقطیر دانش
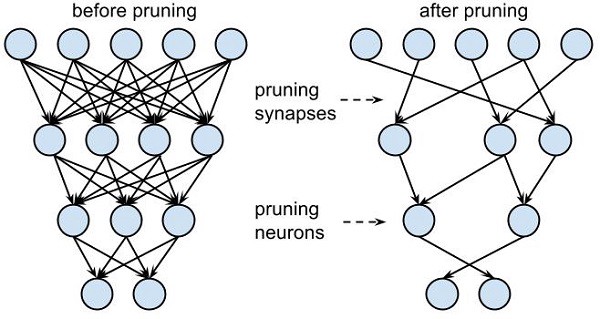
هرس و به اشتراکگذاری پارامترها
هرس به کاهش مقدار چیزی یا حذف بخشهای اضافی آن گفته میشود.
به بیان ساده میتوان گفت که هرس به حذف پارامترهایی اشاره دارد که در عملکرد مدل نقش کلیدی ندارند. مبنای عملکرد هرس کاهش برداری پارامترهایی است که تأثیری در بهتر شدن مدل ندارند. تکنیکهای هرس را میتوان به سه دسته تقسیم کرد:
کوانتیزه کردن و باینری کردن binarization: کوانتیزه کردن به فرآیندی گفته میشود که طی آن یک بازهی پیوسته از مقادیر به یک بازهی محدود از مقادیر گسسته تبدیل میشود. برای درک بهتر تصور کنید یک تصویر سیاهسفید داریم. کوانتیزه کردن (N سطحی) N سطح خاکستری (سیاه) از این تصویر به ما میدهد. از سوی دیگر باینری کردن تنها دو سطح خاکستری از آن ارائه میدهد.
کوانتیزه کردن شبکهی اصلی را از طریق کاهش تعداد بیتهای نمایندهی وزنها فشرده میکند. کوانتیزه کردن به شکلی کارآمد تعداد وزنهای گوناگونی که میتوانیم در کرنلها استفاده کنیم را محدود میکند. اگر N بیت داشته باشیم، میتوانیم 2^N وزن مشخص کنیم. هدف در اینجا اصلاح وزنهای موجود در کرنل هست به صورتی که تنها وزنهای 2^N را بگیریم. بنابراین برای مقادیر زیر 4 بیت، معرفی وزنها بدون کاهش دقت کار دشواری خواهد بود.

وزنها و فعال در طول آزمون (TESTING) در دقت ثابتی نگه داشته شدهاند.

وزنها و فعالسازیها در طول آموزش (TRAINING) در دقت ثابتی نگه داشته شدهاند.
همانطور که مشاهده میکنید کوانتیزه کردن در طی آموزش تأثیر معناداری بر میزان دقت نمیگذارد که خود نکته خوبی است. کوانتیزه کردن در مرحلهی استنتاج به نحوی با شکست مواجه میشود که دیگر امکان آموزش وجود نخواهد داشت.
تصور کنید یک شبکهی 32 بیتی آموزش دیده شده داریم که میخواهیم با انجام پسپردازش، اندازهی آن را کاهش داده و وزنش را به چهار بیت کوانتیزه کنیم. هنگام گذر به جلو همهی وزنهای کرنل کوانتیزه خواهند شد. اما بعد از این به صورت مسطح یا با گرادیان صفر برمیگردند که به این معنی است که شبکهی ما دیگر آموزش نخواهد دید.
[irp posts=”5325″]به منظور گذشتن از این مانع در پسانتشار از برآوردگر مستقیم Straight through estimator (STE) استفاده میکنیم. STE گرادیانهای اصلی را برگردانده و مقادیر اعشاری را، بدون اصلاح مقادیر کوانتیزه شده بالایی، به روز میکند. سپس گذر رو به جلو و گذر رو به عقب دوباره انجام میشوند.
مقالات بسیار خوبی در مورد شبکه های 8 بیتی، 4 بیتی، 2 بیتی و 1 بیتی (شبکه های باینری) وجود دارد.

هرس و به اشتراکگذاری: یکی از رویکردهای شناخته شده در بحث هرس شبکهها و به اشتراکگزاری وزنها، مراحل این فرآیند را بدین صورت بیان میکند:
- در شروع کار انحراف معیار هر کدام از لایههای شبکه را پیدا میکنیم تا توزیع وزن آن لایه را بفهمیم.
- وقتی انحراف معیار توزیع را به دست آوردیم، وزنهای پایینتر را از طریق آستانهگذاری حذف میکنیم. آستانهی پیاده شده را با ضرب انحراف معیار لایه در نسبت هرس به دست میآوریم. نسبت هرس برای لایههای مختلف از آزمایشاتی به دست میآید که از حوصله این متن خارج است.
- برای اینکه به دقت بهینه برسیم، شبکه هرس شده را دوباره آموزش میدهیم تا وزنهای حذف شده جبران گردند.
- در مرحلهی به اشتراکگذاری وزنها، وزنهایی که تفاوت کمی با هم دارند توسط مقادیر نماینده جایگزین میشوند. این مقادیر نماینده، مقادیر مرکز خوشه Centroid values نامیده میشوند و بنابر توزیع وزن هر لایه متفاوت هستند. این مقادیر بعد از محاسبهی فاصلهی خطی به دست میآیند در طی آموزش مجدد، نهایی میشوند.

فاکتورگیری حداقلی ماتریس (LRMF)
ایده ی زیربنایی فاکتورگیری حداقلی ماتریس این است که در داده ها ساختارهای نهفتهای وجود دارند که با کشفشان میتوانیم به بازنمایی فشردهای از دادهها برسیم. LRMF ماتریس اصلی را فاکتورگیری کرده و آنها را درضمن اینکه به ماتریسهای با رتبه پایینتر تبدیل می نماید، همزمان ساختارهای نهفته مذکور را حفظ میکند تا موضوع پراکندگی ماتریس نیز حل شود.
عملیاتهای پیچشی در شبکه های عصبی پیچشی (CNN) عمیق معمولاً دارای هزینه محاسبات بالایی هستند. بنابراین کاهش تعداد عملیات پیچشی Convolution operation به فشرده سازی شبکه و سرعت دادن به شبکه های عصبی کمک میکند.
[irp posts=”20023″]LRMF بر اساس این مفروضه بنا شده که ماتریس های چند بعدی کرنل پیچشی 4 بُعدی بسیار زائد هستند و میتوان آنها را تجزیه کرد. لایه به صورت تنسورهای دو بُعدی نشان داده میشوند.
مدت زیادی است که از روشهای LRMF استفاده میشود، با اینحال محدودیتهای بزرگی هم دارند؛ زیرا تجزیهی تنسورها وظیفهای است که از نظر محاسباتی سنگین است. علاوه بر این روشهای نوینی که در LRMF موجود هستند از تخمین لایه به لایهای حداقلی استفاده میکنند و بدین ترتیب قادر به متراکمسازی کلی پارامترها نیستند. امری که خود اهمیت زیادی دارد چون لایههای مختلف اطلاعات متفاوتی را نگه میدارند.

فیلترهای پیچشی فشرده
این قسمت برای سرعت دادن به شبکه های عصبی اهمیت زیادی دارد. استفاده از فیترهای پیچشی فشرده میتواند مستقیماً باعث کاهش هزینههای محاسباتی لازم شود. ایدهی اصلی در این رویکرد، جایگزین کردن فیلترهایی که پارامترهای زیادی دارند با فیلترهای فشرده است تا بتوان باعث سرعت دادن به شبکه های عصبی شد و در عین حال دقت را در حد قابل قبولی نگه داشت. برای درک بهتر به این مثال توجه کنید.
تعداد پارامترهای شبکهی عصبی Squeezenet 50 برابر کمتر و اندازهی آن کمتر از 0/5 مگابایت است، اما به عملکردی برابر با شبکهی Alexnet دست یافت. توجه داشته باشید که ظرفیت حافظهی این شبکه نسبت به Alexnet 510 برابر کمتر است. حال بررسی کنیم که برای رسیدن به این دستاورد چه رویکردی را در پیش گرفتهاند. آنها به عنوان بلوک سازندهی معماری شبکهی عصبی پیچشی (CNN) خود از ماژولهای Fire استفاده کردند. راهبردهای به کار رفته در طراحی Squeezenet را میتوان به صورت کلی در سه دسته تقسیمبندی کرد:
- جایگزینی فیلترهای 3×3 با فیلترهای 1×1.
- کاهش تعداد کانالهای ورودی به فیلترهای 3×3.
- به تأخیر انداختن کاهش نمونهگیری به این منظور که لایههای پیچشی، نگاشتهای فعالسازی بزرگی داشته باشند. کاهش نمونهگیریdownsampling در شبکه در مراحل ابتداییتر منجر به از دست رفتن برخی اطلاعات میشود. زیرا لایههای خروجی نگاشتهای فعالسازی کوچکی دارند. با توجه به تأخیر کاهش نمونهگیری ، بیشتر لایههای شبکه نگاشتهای فعال بزرگتری خواهند داشت که خود حتی در شرایطی که بقیهی عوامل ثابت نگه داشته شده باشند، منجر به دقت بیشتر در مسئله میشود.
ماژول Fire تقریباً چنین شکلی دارد:
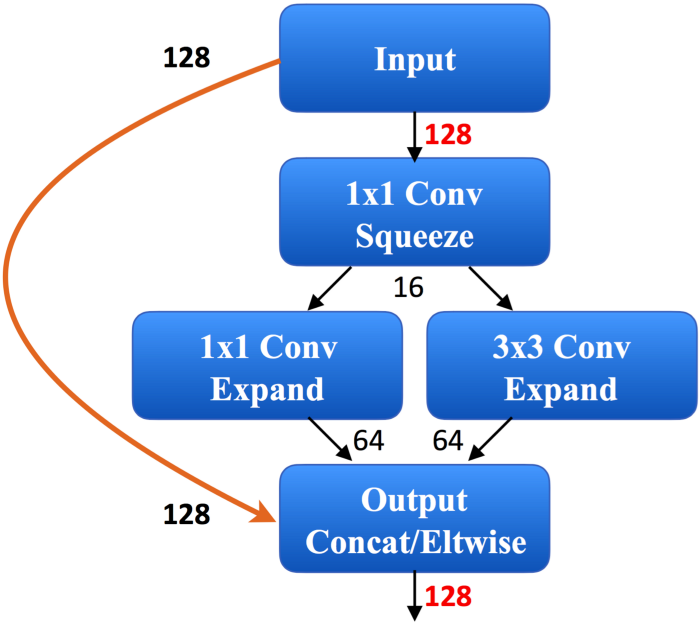
تنها نگرانی ما در آنچه توضیح داده شده این است که تجزیهی فیلترهای 3×3 و کانالهای ورودی به کانولوشنهای کوچکتر چطور میتواند منجر به ایجاد یک شبکهی متراکمتر شود که در عین حال که عملکرد یکسانی از خود نشان میدهد، سرعت بسیار زیاد و حافظه ارزان هم داشته باشد.
تقطیر دانش
تصور کنید میخواهید مجموعهی (دادههای) خود را برروی دیتاستهای Kaggle یا Imagenet به صورتی فشردهسازی کنید که مدلهای بسیار کوچکتری به دست آورید که در زمان اجرا نیز عملکرد خوبی دارند. کارهای اخیر پرفسور هینتون و جف دین در تیم تحقیقاتی گوگل به رفع این مسئله میپردازد. برای واضحتر کردن مطلب از یک مثال استفاده میکنیم. در یک کلاس درس معلم معادل مدلی بزرگ و سنگین است که بسیار دقیق آموزش دیده تا معیارهای تعیین شده را برآورده کند. دانشآموز هم یک شبکهی کوچکتر است که از معلم دانش کسب میکند.
[irp posts=”9735″]موضوعی که مقاله بیان میکند مربوط به تقطیر یا انتقال دانش از مجموعهای از شبکه های بزرگ به یک شبکهی کوچکتر است. این شبکهی کوچک مستقیماً از خروجیهای آن مدل سنگین میآموزد و پیادهسازی آسانتری دارد. چرا این روند به خوبی جواب میدهد؟ زمانی که آموزش دیده باشید همان پیشبینیهای مدل سنگین را انجام دهید، دیگر لازم نیست نگران مسائلی همچون بیشبرازش باشید؛ زیرا مدل سنگین خودش قبلاً این مسئله را حل کرده است.
یک دلیل دیگر هم این است که شبکه بر اساس احتمالات «نرمِ» مدل سنگین آموزش دیده، نه بر اساس اهداف «سخت» آن که به صورت one-hot رمزگزاری شدهاند. به تصویر پایین دقت کنید.

مدل سنگین آموزش دیده تا اهداف سخت را به این صورت به کار ببرد: ماشین—1، انسان—0، درخت—0.
از سوی دیگر مدل تقطیری برای استفاده از احتمالات نرم آموزش دیده است: ماشین— 0/96، انسان—0/00001~، درخت —~000002/0 ، ساختمانها —~ 03/0.
مدل تقطیری نسبت به مدل سنگین «اطلاعات» بیشتری باید بیاموزد. اما هنوز هم ممکن است در یادگیری ویژگیهای فضایی ساختمان موفق عمل نکند، زیرا تنها احتمال 0/03 برای آن یادگیری وجود دارد که طی آن گرادیانها خیلی ضعیف خواهند بود و برای لایههای عمیقتر تفاوتی را ایجاد نمی کنند.
راهحلی که در این مقاله ارائه شده است تقسیم ورودیهای تابع Softmax (تابعی که خروجی آن احتمالات است) با استفاده از عددی که در اینجا به آن دما میگوییم. برای مثال اگر ورودیهایی که وارد softmax میشوند عبارت باشند از ، بعد از تقسیم بر مقدار دما (که مثلاً در اینجا 5 است)، مقادیر جدیدی که وارد تابع softmax میشوند هستند. این مسئله باعث تغییر احتمالات نرم خروجی از مدل سنگین میشود، طوری که برای مدل تقطیری آسانتر خواهد بود یاد بگیرد که یک ساختمان وجود دارد. بعد از تغییرات softmax، احتمالات نرم بدین شکل خواهند بود:
ماشین —~67/0، انسان —~04/0، ساختمان—~24/0 و درخت—~05/0.
این احتمالات بر پیشبینی مدل تقطیری تاثیر میگذارند. بنابراین لازم است برای پیشبینی، ورودیهای softmax را با ضرب آنها در مقدار دما به حالت اولیه بازگردانیم.
ابرپارامتر دما قابلیت تغییر متناسب با نیاز کاربر را دارد. در مقالهی اصلی برای بیشتر موارد استفاده از مقدار دمای 5 پیشنهاد میشود. کاهش دما باعث میشود ورودیهای softmax به سمت واقعی خود نزدیکتر باشند (که در نتیجه دیگر در مورد ساختمان چیزی نمیآموزد) و افزایش دما نویز(اختلال) بیشتری به گرادیانها میدهد، زیرا softmax برای تقریباً تمام طبقات، احتمالات بالاتری را بیرون خواهد داد.
تقطیرساز
به منظور تسهیل اجرای دستی الگوریتم، توجه خود را به سمت تقطیرساز شبکهی عصبیHover over me Neural Network Distiller که توسط Intel AI Labs ارائه شده سوق میدهیم. تقطیرساز شبکهی عصبی یک پکیج پایتون برای پژوهشهای فشردهسازی شبکه های عصبی میباشد. تقطیرساز برای نمونه سریعتر و تحلیل الگوریتمهای تراکمی (همچون روش پراکندهساز و محاسبات کمدقت) یک محیط در PyTorch آماده میکند.
در نتیجه میتوان گفت تقطیرساز چارچوبی فراهم میکند برای کاربرد الگوریتمهای نوین و جالبی همچون هرس، کوانتیزه کردن و تقطیر دانش و علاوه بر اینها، مجموعه ابزاری دارد که برای ارزیابی تراکم و عملکرد شبکه استفاده میشود.
نتیجهگیری
در نتیجه مقاله مربوط به سرعت دادن به شبکه های عصبی باید گفت، با اینکه هیچ راهی نیست که بتوان گفت کدام روش بهترین است، اما روشهای هرس و به اشتراکگزاری توانستهاند نرخ فشردهسازی خوبی از خود به نمایش بگذارند و در عین حال به دقت هم آسیب چندانی وارد نکنند. زمانی که این روشها را با روشهای فاکتورگیری حداقلی ترکیب کنیم، میتوانیم مدلهای از پیش آموزش دیده را نیز فشرده کنیم.
اما روشهایی همچون هرس کانالها میتوانند منجر به کاهش عرض نگاشت ویژگی شده و مدل را به یک مدل کوچکتر تبدیل کنند. از طرف دیگر روشهای تقطیر دانش را میتوان با افزایش انتقال دانش بین شبکهی معلم و دانشآموز، کارآمدتر کرد. بیشتر مقالات موجود در مورد هرس، به اشتراکگزاری و یا کوانتیزه کردن هستند اما کمتر مقالهای پیدا میشود که به صورت ترکیبی به همهی این روشها بپردازد.
بنابراین میتوان گفت با اینکه این ترکیب ممکن است در عمل بتواند به نتیجه برسد، پیشینهی نظری محکمی ندارد. پژوهشهای جاری در این حوزه فضا را برای انتقال شبکه های یادگیری عمیق به دستگاههای متحرکی که به توان کمی نیاز و احتمال تأخیر پایینی هم دارند فراهم کرده است.






