مصاحبه یادگیری عمیق و 12 پرسشی که نباید از دست بدهید (بخش 2)
تیم تحریریه
- ۹ مرداد ۱۴۰۰
در این مطلب به بخش دوم پرسشهایی که در مصاحبه یادگیری عمیق از افراد جویای کار پرسیده میشود، میپرداریم. افراد علاقهمند به مهندسی هوش مصنوعی و خصوصا یادگیری عمیق معمولا در جلسات مصاحبه استخدامی با سوالاتی مواجه میشوند که شاید برای پاسخ دادن به آنها حضور ذهن نداشته باشند. به همین دلیل در این مطلب به سوالات رایج مصاحبه یادگیری عمیق اشاره شده تا کار برای علاقهمندان این حوزه راحتتر شود. همچنین میتوانید از طریق لینک انتهای مطلب به بخش اول دسترسی داشته باشید.
5- از پسانتشار چه میدانید؟ سازوکار عملکرد آن را توضیح دهید؟
هدف از طرح چنین پرسشی این است که بدانیم شبکههای عصبی چگونه کار میکنند. باید نکات زیر شفافسازی شوند:
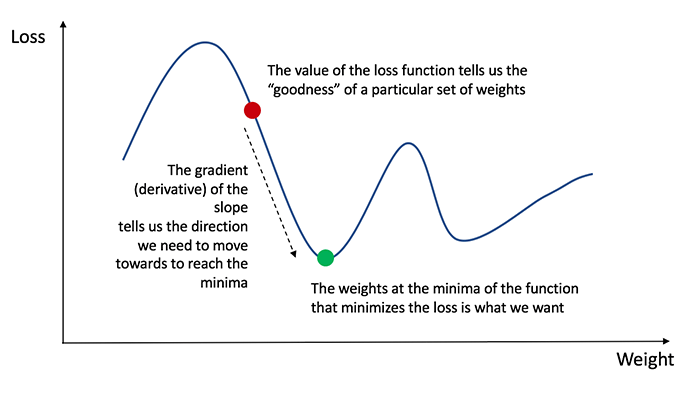
- فرایند Forward به مدل کمک میکند تا وزنهای هر لایه را محاسبه کند. این محاسبه سرانجام به نتیجه yp ختم میشود. این بار، مقدار تابع زیان نیز محاسبه خواهد شد. مقدار تابع زیان نشان میدهد که مدل چقدر خوب عمل میکند. اگر تابع زیان به قدر کافی خوب نباشد، باید راهی برای کاهش مقدار تابع زیان پیدا کنیم. آموزش دادنِ شبکه عصبی اساساً به معنای کمینه کردن تابع زیان است. تابع زیان L (yp, yt) میزان اختلاف میان مقدار خروجیِ مدل yp و مقدار حقیقیِ برچسب داده yt را نشان میدهد.
- باید از مشتق برای کاهش مقدار تابع زیان استفاده کنیم. پسانتشار نقش موثری در محاسبه مشتقِ هر لایه شبکه ایفا میکند. بر اساس مقدار مشتق در هر لایه، ابزار بهینهساز (Adam، SGD و AdaDelta) با استفاده از گرادیان کاهشی میتواند وزن شبکه را بهروزرسانی کند.
- پسانتشار از سازوکار قاعده زنجیرهای یا مشتق برای محاسبه مقادیر گرادیان هر لایه (از لایه آخر به لایه اول) استفاده میکند.
6- تابع فعالسازی به چه معناست؟ نقطه اشباع توابع فعالسازی کجاست؟
معنای تابع فعالسازی
توابع فعال سازی با هدفِ از بین بردن خاصیت خطیِ شبکه های عصبی ایجاد شدند. میتوان این توابع را صرفاَ به عنوان فیلتری در نظر گرفت که مشخص میکند اطلاعات از میان نورونها منتقل میشوند یا خیر. توابع فعالسازی نقش مهمی در طی آموزش شبکه عصبی ایفا کرده و شیب مشتق را تنظیم میکنند. برخی توابع فعالسازی از قبیل sigmoid، fishy یا ReLU در بخشهای بعدی به طور مفصل بررسی خواهند شد. با این حال، باید به این نکته توجه داشت که ویژگیهای این توابع غیرخطی باعث میشود تا شبکههای عصبی بازنمایی پیچیدهتری از توابع را نسبت به توابع خطی یاد گیرند. اکثر توابع فعالسازی در زمرهی توابع پیوسته و مشتقپذیر جای میگیرند. این توابع، توابع پیوسته هستند. اگر ورودی تغییر کوچکی داشته باشد، تغییر کوچکی در خروجی پدید میآید. البته، آنطور که در فوق ذکر شد، محاسبه مشتق حائز اهمیت فراوانی است و عاملی تعیینکننده در آموزش یا عدم آموزش نورونها میباشد. توابع فعالسازی متعددی وجود دارد که میتوان به عنوان مثال Sigmoid، Softmax یا ReLU را ذکر کرد
بازه اشباع تابع فعالسازی
توابع فعالسازی غیرخطی از قبیل Tanh ،Sigmoid و ReLU همگی دارای بازه اشباع هستند.
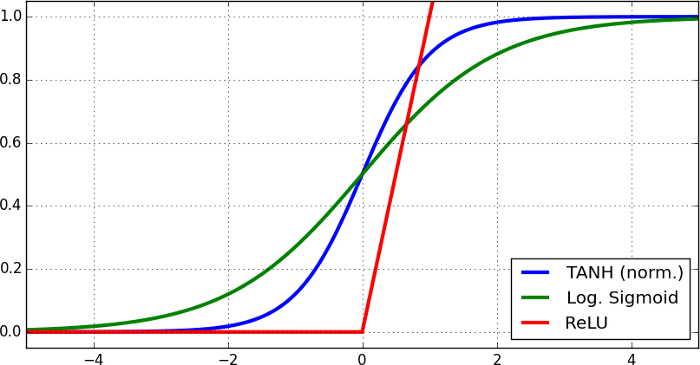
همانطور که ملاحظه میکنید، دامنههای اشباع تابع Trigger شامل بازهای میشود که در آن، مقدار خروجیِ تابع تغییر نمییابد، حتی اگر مقدار ورودی عوض شود. یکی از مسائلی که با آن مواجه میشویم این است که در جهت رو به عقب، مشتق در ناحیه اشباع برابر با صفر خواهد بود. بنابراین، شبکه چیز بیشتری یاد نخواهد گرفت. به همین دلیل است که باید دامنه مقادیر را میانگین صفر در نظر بگیریم. جزئیات این کار در بخش نرمالسازی دستهای ذکر شده بود.
7- هایپرپارامتر مدل چیست و چه فرقی با پارامتر دارد؟
پارامتر مدل چیست؟
با توجه به ماهیت یادگیری ماشین، برخورداری از مجموعهداده یکی از لازمههای اصلیِ کار با یادگیری ماشین است. آیا امکان یادگیری بدون داده وجود دارد؟ اگر دادهها در دسترس باشند، ماشینها باید به دنبال پیوستگی در حجم بالایی از دادهها باشند. فرض کنید دادههای ما از اطلاعات جوی نظیر دما، رطوبت و غیره تشکیل شده است. از ماشین درخواست میشود تا ارتباط میان عوامل فوق را پیدا کند و تشخیص دهد که آیا شریک عشقیمان عصبانی است یا خیر. خب شاید بگویید این دو چه ارتباطی با یکدیگر دارند. گاهی، لیست کارهای یادگیری ماشین احمقانه است. حال فرض کنید از متغیر y برای تشخیص عصبانیت شریک عشقیمان استفاده میکنیم. متغیرهای x1, x2, x3 نیز عناصر جوّی را نشان میدهند. از فرمول زیر برای محاسبه تابع f(x) استفاده میکنیم.
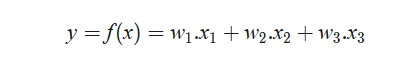
آیا ضرایب w1, w2, w3..w_1, w_2, w_3 ..w1, w2, w3 را میبینید؟ این رابطهی میان دادهها و عناصری است که به دنبالش هستیم (یعنی پارامتر مدل). بنابراین، پارامتر مدل به صورت زیر تعریف میشود: پارامترهای مدل، مقادیر مدلی هستند که با استفاده از دادههای آموزشی ایجاد شدهاند و نقش مهمی در نمایش رابطه میان کمیتها در مدل دارند. از این رو، وقتی میگوییم بهترین مدل را برای مسئله پیدا کردهایم، منظورمان این است که مناسبترین پارامترهای مدل را از میان مجموعهداده موجود برای مسئله پیدا کرد. این مدل از چند خصوصیت مهم برخوردار است:
- این مدل در پیشبینی دادههای جدید کاربرد دارد.
- نشاندهنده توان مدلی است که استفاده میکنیم. معمولا با استفاده از صحت یا فاکتور های مشابه بیان میشود.
- یادگیری مستقیم از مجموعهداده آموزشی
- عدم جابجایی دستی توسط انسان
میتوان پارامترهای مدل را در اَشکال گوناگونی از قبیل وزن شبکههای عصبی، برداهای پشتیبان یا ضرایب رگرسیون خطی یا الگوریتمهای رگرسیون لوجستیک پیدا کرد.
هایپرپارامتر مدل چیست؟
اغلب، فرض بر این است که هایپرپارامتر مدل همان پارامتر مدل است یا دستکم به آن شباهت دارد، اما این برداشت درستی نیست. در واقع، این دو مفهوم کاملاً جدا از هم هستند. اگر پارامتر مدل از خود مجموعهداده آموزشی مدلسازی گردد، هایپرپارامتر مدل کاملاً متفاوت خواهد بود. هایپرپارامتر به صورت کامل خارج از مدل است و به دادههای آموزشی بستگی ندارد. بنابراین، چه هدفی دارد؟ در حقیقت، هایپرپارامترها چند نقش دارند:
- بکارگیری در فرایند آموزش؛ کمک به مدل برای یافتن مناسبترین پارامترها
- عاملین حاضر در آموزش مدل معمولاً آنها را به صورت دستی انتخاب میکنند.
- امکان تعریف آنها بر اساس راهبردهای کلنگر وجود دارد.
نمیدانیم بهترین مدل هایپرپارامتر برای مسئلهای خاص چیست. بنابراین، در واقعیت، باید از راهکارهایی برای ارزیابیِ بهترین دامنهی مقادیر استفاده کنیم؛ مثل جستجوی شبکه. در این بخش، میخواهیم چند نمونه از هایپرپارامتر مدل را برایتان نشان دهیم:
- شاخص نرخ یادگیری در هنگام آموزش شبکه عصبی مصنوعی
- پارامترهای C و sigma در هنگام آموزش ماشین بردار پشتیبان
- ضریب k در مدل k نزدیکترین همسایه
8- اگر نرخ یادگیری بسیار بالا یا بسیار پایین باشد، چه اتفاقی رخ میدهد؟
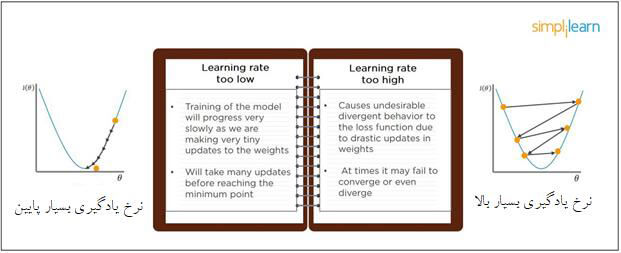
اگر نرخ یادگیری بسیار پایین باشد، مدل با سرعت پایینی آموزش خواهد دید زیرا باید بهروزرسانی بسیار اندکی در وزنها صورت گیرد. اگر نرخ یادگیری بسیار بالا باشد، بعید است مدل همگرایی پیدا کند چرا که بهروزرسانی وزنها کار سنگینی خواهد بود. ممکن است مدل در یکی از مراحل وزندهی بر بهینهسازی محلی فائق آید. در این صورت، مدل راه دشواری برای بهروزرسانیِ خود در نقطه بهینه خواهد داشت.
لینک مربوط به بخش اول مطلب:
پرسش های مصاحبه یادگیری عمیق (بخش اول)