
پروژه تشخیص اشیاء و ایجاد یک مکانیزم لاگین کردن با استفاده از TDD
 تیم تحریریه
تیم تحریریه- ۱۴ آذر ۱۴۰۰
توصیف سیستم
برای اینکه دقیقاً متوجه هدف این پست شوید، یک نگاه به نمونه عکس زیر بیندازید:
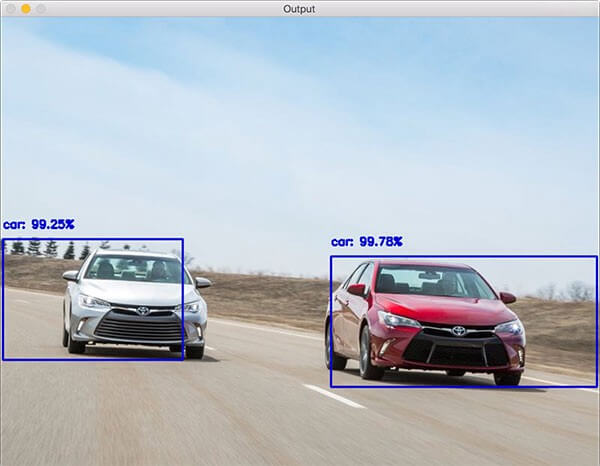
در این عکس، فریمی با دو کادر محصورکننده نشان داده شده و هر کادر حاوی برچسبی با سطح اطمینان مشخص است. پس فهرستی از فریمها در اختیار داریم و هر فریم میتواند دربردارندهی چندین کادر میباشد. معمولاً در اکثر پروژههای تشخیص اشیاء در خروجی شبکههای پروژه تشخیص اشیاء، برای هر کادر محصور کننده چندین برچسب با درجه اطمینان وجود دارد که شی شناسایی شده با اولویت درجه اطمینان انتخاب میشود. پس در این پروژه شرایطی فراهم میآوریم که کادرها فهرستی از برچسبها با درصد اطمینان خروجی شبکه مصنوعی داشته باشند. این کار با انتخاب پارامتری تحت عنوان top_k_label به انجام میرسد. انتظار داریم همه کادرها تعداد برچسب یکسانی داشته باشند. حال، به مثالی از فایل json که به شکل 1 مربوط است، توجه نمائید:
{
“video_details”: {
“frame_width”: 1080,
“frame_height”: 720,
“frame_fps”: 20,
“video_name”: “test.avi”
},
“frames”: [
{
“frame_id”: 1,
“bboxes”: [
{
“bbox_id”: “0”,
“labels”: [
{
“category”: “car”,
“confidence”: 99.25
},
{
“category”: “truck”,
“confidence”: 57.14
}
],
“left”: 5,
“top”: 400,
“width”: 250,
“height”: 145https://hooshio.com/%d9%be%d8%b1%d9%88%da%98%d9%87-%d8%aa%d8%b4%d8%ae%db%8c%d8%b5-%d8%a7%d8%b4%db%8c%d8%a7%d8%a1-%d9%88-%d8%a7%db%8c%d8%ac%d8%a7%d8%af-%d9%85%da%a9%d8%a7%d9%86%db%8c%d8%b2%d9%85-%d9%84%d8%a7%da%af%db%8c/
},
{
“bbox_id”: “1”,
“labels”: [
{
“category”: “car”,
“confidence”: 99.78
},
{
“category”: “bus”,
“confidence”: 65.23
}],
“left”: 650,
“top”: 450,
“width”: 300,
“height”: 150
}]
}]
جزئیات ویدئو نیز در این نمونه مد نظر قرار گرفته است؛ از جمله این جزئیات میتوان به عرض، ارتفاع، سرعت خواندن ویدئو (فریم بر ثانیه fps) و نام فایل ویدئویی اشاره کرد. هدف از این کار، اطمینان حاصل کردن از ساخت مجدد کادرها در هنگام استفاده از فایل ویدئویی است.
[irp posts=”4503″]شروع کار
من کد اولیه را با سه class شروع کردم. این class حاوی اطلاعاتی درباره فریمها، کادرها و برچسبها است.
class Label: """ For each bounding box there are various categories with confidences. Label class keeps track of that information. """ def __init__(self, category: str, confidence: float): self.category = category self.confidence = confidence class Bbox: """ This classhttps://hooshio.com/%d9%be%d8%b1%d9%88%da%98%d9%87-%d8%aa%d8%b4%d8%ae%db%8c%d8%b5-%d8%a7%d8%b4%db%8c%d8%a7%d8%a1-%d9%88-%d8%a7%db%8c%d8%ac%d8%a7%d8%af-%d9%85%da%a9%d8%a7%d9%86%db%8c%d8%b2%d9%85-%d9%84%d8%a7%da%af%db%8c/ keeps the information of each bounding box in the frame. """ def __init__(self, bbox_id, top, left, width, height): self.labels = [] self.bbox_id = bbox_id self.top = top self.left = left self.width = width self.height = height class Frame: def __init__(self, frame_id: int): self.frame_id = frame_id self.bboxes = []
دستههای پایه
class دیگری برای مدیریت خروجی ایجاد و آن را JsonParser نامگذاری کردم:
class JsonParser:
def __init__(self, top_k_labels: int = 1):
self.frames = {}
self.video_details = dict(frame_width=None,
frame_height=None,
frame_rate=None,
video_name=None)
self.top_k_labels = top_k_labels
این class مخصوصِ مدیریت logger است.
[irp posts=”13463″]مرحله 1: افزودن فریم
حال که class های اولیه را در اختیار داریم، بیایید از رویکرد TDD software development استفاده کنیم. من فایل دیگری به نام test_json_parser ایجاد کردم و آن را در پوشه tests قرار دادم. حالا به کدی نیاز داریم که افزودنِ فریم به JsonParser.frames را تحت آزمایش unittest قرار دهد. اکنون زمان اجرای TestCase با کد زیر فرا رسیده است:
import unittest
import sys
from unittest.case import TestCase
sys.path.append('../..')
from json_parser.json_parser import *
class TestFrame(TestCase):
def setUp(self) -> None:
self.json_parser = JsonParser()
self.video_details = {'frame_width': 500,
'frame_height': 200,
'frame_rate': 20,
'video_name': 'something.mp4'}
مقداردهی اولیه برای jsonparser tests
من از ابزارهای نرم افزار pycharm برای آزمایش کد استفاده کردم. دلیل افزودنِ sys.path.append(../..) این بود که اگر قادر به استفاده از pycharm نبودید، بتوانید از فرمانهای terminal برای انجام unittest ها استفاده کنیم. کد زیر، فرایند افزودن فریم را تحت unittest قرار میدهد.
def test_add_frame(self): frames_ids = [1, 2, 3, 4, 5] self.json_parser.set_top_k(0) for frame_id in frames_ids: self.json_parser.add_frame(frame_id) output = self.json_parser.output() output_ids = [frame['frame_id'] for frame in output['frames']] for frame_id in frames_ids: self.assertIn(frame_id, output_ids) # if repeated frame id was inserted, raise ValueError with self.assertRaisesRegex(ValueError, "Frame id: (.*?) already exists"): self.json_parser.add_frame(frames_ids[1])
در این آزمایش:
1. اطمینان حاصل میکنیم که تعداد فریمی که در json قرار دارد همان مقداری است که در ورودی تخصیص یافته است.
2. اگر بر اساس شماره فریم، فریمی تکراری جایگذاری شود، انتظار میرود روند کار با خطا همراه باشد.
توجه داشته باشید که تابع assertRaisesRegex از عبارات معمولی برای بررسی پیام خطا استفاده میکند. عبارت (.*?) یک عبارت معمولی است، اما در این مورد، برای چشمپوشی از جملات میان (Frame id:) و already exists استفاده شد. حال بیایید کد را برای پشت سر گذاشتن این آزمایش به کار ببندیم. باید کار را با ماژول JsonParser آغاز کنیم. در همین راستا، سه تابع زیر به کد اضافه می شود:
def set_top_k(self, value):
self.top_k_labels = value
def frame_exists(self, frame_id: int):
return frame_id in self.frames.keys()
def add_frame(self, frame_id: int):
# Use this function to add frames with index.
if not self.frame_exists(frame_id):
self.frames[frame_id] = Frame(frame_id)
else:
raise ValueError("Frame id: {} already exists".format(frame_id))
توابع لازم برای پشت سر گذاشتن آزمایش «اضافه کردنِ فریم»
من معمولاً از دستورالعمل __dict__() برای دسترسی به خصوصیات کلاسها در پایتون استفاده میکنم. اما به منظور دسترسی به خصوصیاتی که شامل یک لیست از اشیاء میشوند، مثل labels در دسته Bbox یا bboxes در دسته Frame، باید از یک ترفند برای به دست آوردن این پارامترها استفاده کنیم. به لطف این لینک ، یک کلاس والد Parent class ایجاد کردم که خصوصیت دیگری به کلاسهای Frame، Bbox و Label اضافه میکند. نام این کلاس BaseJsonParser است. به فرایند زیر توجه نمائید.
class BaseJsonParser(object):
"""
This is the base class that returns __dict__ of its own
it also returns the dicts of objects in the attributes that are list instances
"""
def dic(self):
# returns dicts of objects
out = {}
for k, v in self.__dict__.items():
if hasattr(v, 'dic'):
out[k] = v.dic()
elif isinstance(v, list):
out[k] = self.list(v)
else:
out[k] = v
return out
@staticmethod
def list(values):
# applies the dic method on items in the list
return [v.dic() if hasattr(v, 'dic') else v for v in values]
class Label(BaseJsonParser):
"""
For each bounding box there are various categories with confidences. Label class keeps track of that information.
"""
def __init__(self, category: str, confidence: float):
self.category = category
self.confidence = confidence
class Bbox(BaseJsonParser):
"""
This class keeps the information of each bounding box in the frame.
"""
def __init__(self, bbox_id, top, left, width, height):
self.labels = []
self.bbox_id = bbox_id
self.top = top
self.left = left
self.width = width
self.height = height
class Frame(BaseJsonParser):
def __init__(self, frame_id: int):
self.frame_id = frame_id
self.bboxes = []
تعریف BaseJsonParser
با انتخاب BaseJsonParser به عنوان کلاس والد، خصیصه ای به نام dic برای کلاس ها تخصیص داده میشود. این خصوصیت Attribute به ما اجازه خواهد داد تا خصوصیات را در کلاس های جایگذاری شده بازگردانیم. اکنون زمان افزودنِ دستورالعمل output به `JsonParser` و اجرای آزمایش فرا رسیده است:
def output(self):
output = {'video_details': self.video_details}
result = list(self.frames.values())
output['frames'] = [item.dic() for item in result]
return output
این تابع را به کلاس `JsonParser` اضافه کنید.
حالا به اجرای test_add_frame.pyمی پردازیم.
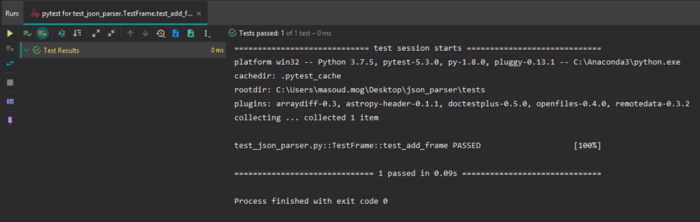
آزمایش اول با موفقیت به پایان رسید!
مرحله 2: اضافه کردن کادر محصورکننده به هر فریم
بسیار عالی! اکنون میخواهیم آزمایش دوم را بنویسیم که مخصوصِ اضافه کردنِ کادر به فریمها است:
def test_add_bbox_to_frame(self): # test if bbox is added to its own frame frame_one_id = 0 bbox_id = 1 bbox_xywh = (10, 20, 30, 40) top_k = 0 self.json_parser.set_top_k(top_k) self.json_parser.add_frame(frame_one_id) self.json_parser.add_bbox_to_frame(frame_one_id, bbox_id, *bbox_xywh) out = self.json_parser.output() # retrieve the bbox in the frame inserted_bbox = out['frames'][0]['bboxes'][0] # check the values inserted in bbox self.assertEqual((inserted_bbox['bbox_id']), bbox_id) self.assertEqual(inserted_bbox['top'], bbox_xywh[0]) self.assertEqual(inserted_bbox['left'], bbox_xywh[1]) self.assertEqual(inserted_bbox['width'], bbox_xywh[2]) self.assertEqual(inserted_bbox['height'], bbox_xywh[3]) # check if error raises with repeated insertion with self.assertRaisesRegex(ValueError, 'frame with frame_id: (.*?) already contains the bbox with id: (.*?) '): self.json_parser.add_bbox_to_frame(frame_one_id, bbox_id, *bbox_xywh) # check if error raises when frame_id is not recognized with self.assertRaisesRegex(ValueError, 'frame with frame_id: (.*?) does not exist'): self.json_parser.add_bbox_to_frame(2, bbox_id, *bbox_xywh)
این کار برای اضافه کردن کادر ضروری است.
باید موارد زیر را برای پاس کردن تستها پیادهسازی کنیم:
1. ایجاد تابع برای JsonParser تا بررسی کند آیا bbox وجود دارد یا خیر.
2. ایجا تابع برای اضافه کردنِ bbox به فریم
def bbox_exists(self, frame_id, bbox_id):
bboxes = []
if self.frame_exists(frame_id=frame_id):
bboxes = [bbox.bbox_id for bbox in self.frames[frame_id].bboxes]
return bbox_id in bboxes
def add_bbox_to_frame(self, frame_id: int, bbox_id: int, top: int, left: int, width: int, height: int):
if self.frame_exists(frame_id):
frame = self.frames[frame_id]
if not self.bbox_exists(frame_id, bbox_id):
frame.add_bbox(bbox_id, top, left, width, height)
else:
raise ValueError(
"frame with frame_id: {} already contains the bbox with id: {} ".format(frame_id, bbox_id))
else:
raise ValueError("frame with frame_id: {} does not exist".format(frame_id))
این موارد را به `JsonParser` اضافه کنید.
def add_bbox(self, bbox_id: int, top: int, left: int, width: int, height: int):
bboxes_ids = [bbox.bbox_id for bbox in self.bboxes]
if bbox_id not in bboxes_ids:
self.bboxes.append(Bbox(bbox_id, top, left, width, height))
else:
raise ValueError("Frame with id: {} already has a Bbox with id: {}".format(self.frame_id, bbox_id)
این مورد را به دستۀ Frame اضافه کنید.
حالا نوبت انجام مجدد هر دو آزمایش فرا رسیده است:
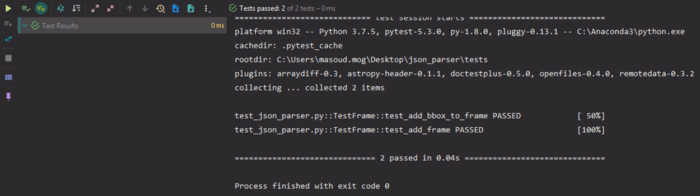
مرحله 3: اضافه کردنِ برچسب به کادرها
در گام بعدی، باید برچسبها را به bboxes افزوده و فرایند کار را آزمایش کنیم. باید موارد زیر آزمایش شوند:
1. با بکارگیری top_k_labels و افزودن برچسبهای یکسان به bboxes، انتظار داریم کار بدون هیچ مشکلی پیش برود.
2. با اضافه شدن برچسبهای بیشتر از top_k_labels به خطای ValueError خواهیم خورد.
3. در حین خروجی گرفتن از json، انتظار داریم برنامه از این موضوع را اطمینان حاصل کند که تعداد برچسبهای هر کادر یکسان باشد.
اکنون به روند آزمایش دقت کنید:
def test_add_label_to_bbox(self): # test if label exists in bbox frame_one_id = 0 bbox_id = 1 bbox_xywh = (10, 20, 30, 40) self.json_parser.add_frame(frame_one_id) self.json_parser.add_bbox_to_frame(frame_one_id, bbox_id, *bbox_xywh) categories = ['car', 'truck', 'bus'] confidences = [0.47, 0.85, 1] top_k = 3 self.json_parser.set_top_k(value=top_k) for cat, conf in zip(categories, confidences): self.json_parser.add_label_to_bbox(frame_one_id, bbox_id, cat, conf) out = self.json_parser.output() inserted_labels = out['frames'][0]['bboxes'][0]['labels'] # Does output contain all labels that were inserted. for label in inserted_labels: self.assertTrue(label['category'] in categories) self.assertTrue(label['confidence'] in confidences) # Check if appending extra label (more than top_k) raises ValueError with self.assertRaisesRegex(ValueError, 'labels in frame_id: (.*?), bbox_id: (.*?) is fulled'): self.json_parser.add_label_to_bbox(frame_one_id, bbox_id, 'new_category', 0.12) # Check if error raises when the number of inserted labels are less than top_k self.json_parser.set_top_k(4) with self.assertRaisesRegex(ValueError, 'labels in frame_id: (.*?), bbox_id: (.*?) is not fulled before outputting.'): out = self.json_parser.output()
آزمایشِ روند افزودن برچسب به bbox
حال با پیاده سازی موارد زیر این تست را پشت سر می گذاریم:
1. تابعی نیاز داریم تا bbox را در لیست bboxes با در اختیار داشتن frame_id و bbox_id از لیست frames پیدا کند.
2. ایجاد تابعی که برچسبی به bbox پیدا شده اضافه کند.
3. باید تعداد برچسبهای اضافه شده به bbox برابر با تعداد top_k_labels باشد. در غیر این صورت، انتظار داریم خطا رخ بدهد. هنگام خروجی گرفتن از فریمها نیز باید این مسئله بررسی شود.
حال، تابع find_bbox را در JsonParser اضافه میکنیم:
def find_bbox(self, frame_id: int, bbox_id: int):
if not self.bbox_exists(frame_id, bbox_id):
raise ValueError("frame with id: {} does not contain bbox with id: {}".format(frame_id, bbox_id))
bboxes = {bbox.bbox_id: bbox for bbox in self.frames[frame_id].bboxes}
return bboxes.get(bbox_id)
اینجا باید add_label_to_bbox را به JsonParser اضافه کنیم:
def add_label_to_bbox(self, frame_id: int, bbox_id: int, category: str, confidence: float):
bbox = self.find_bbox(frame_id, bbox_id)
if not bbox.labels_full(self.top_k_labels):
bbox.add_label(category, confidence)
else:
raise ValueError("labels in frame_id: {}, bbox_id: {} is fulled".format(frame_id, bbox_id))
همان طور که ملاحظه میکنید، باید add_label در bbox وجود داشته باشد. البته من علاوه بر آن تابع دیگری تحت عنوان labels_full نیز اضافه کردم:
class Bbox(BaseJsonParser): """ This class keeps the information of each bounding box in the frame. """ def __init__(self, bbox_id, top, left, width, height): self.labels = [] self.bbox_id = bbox_id self.top = top self.left = left self.width = width self.height = height def add_label(self, category, confidence): # adds category and confidence only if top_k is not exceeded. self.labels.append(Label(category, confidence)) def labels_full(self, value): return len(self.labels) == value
با افزودن `add_label` و `labels_full`، بهروزرِرسانیِ کلاس `Bbox` در دستور کار قرار گرفت.
مقداری که در ورودی برای labels_full تخصیص داده شد، top_k خواهد بود. این مورد در JsonParser مد نظر قرار گرفته بود. اکنون مجبوریم کد مربوط به تابع خروجی را در JsonParser اصلاح کنیم:
def output(self):
output = {'video_details': self.video_details}
result = list(self.frames.values())
# Every bbox in each frame has to have `top_k_labels` number of labels otherwise error raises.
for frame in result:
for bbox in frame.bboxes:
if not bbox.labels_full(self.top_k_labels):
raise ValueError(
"labels in frame_id: {}, bbox_id: {} is not fulled before outputting.".format(frame.frame_id,
bbox.bbox_id))
اصلاح خروجی در JsonParser
بیایید یکبار دیگر همه تستها را یکجا اجرا کنیم:
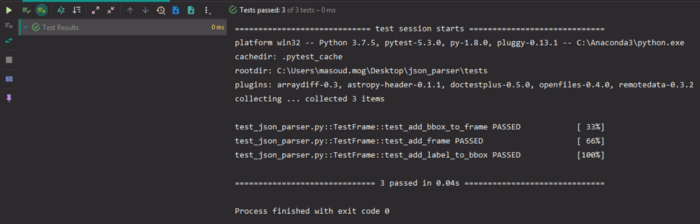
اجرای همه تستها
مرحله 1: خودکارسازی خروجیهای Json
بسیار خب. JsonParser را در اختیار داریم. زمینه برای ساخت تابعی که بتواند کل فرایندِ ذخیرۀ فایلهای json را خودکار کند، فراهم شده است. سازوکارِ من برای پیادهسازی این طرح به صورت زیر است:
1. یک پارامتر interval در اختیار داریم که میتواند بین 1 ثانیه تا 5 ساعت باشد. این پارامتر نشان میدهد که فایلهای json چند وقت به چند وقت ذخیره میشوند.
2. پیش از اینکه فرایند فریم اول آغاز شود، باید زمان آغاز را تعیین کنیم.
3. تابع زمانبندی در حلقه به کار گرفته میشود و این فرایند در هر فریم به اجرا درمیآید. در وهله بعد، میتوان تفاوت میان زمان آغازین و زمان فعلی را اندازه گرفت. هر وقت این تفاوت بیشتر از پارامتر time_to_save باشد، میتوانیم فایل json را ذخیره کنیم.
اکنون زمان ایجاد تست در فایلی دیگر به نام test_scheduled_output.py و انجام فرایند تست به صورت زیر فرا رسیده است:
import unittest
import sys
from datetime import datetime
from os import listdir
from time import sleep
from tempfile import mkdtemp
from unittest.case import TestCase
# from json_parser import JsonParser
sys.path.append('../..')
from json_parser.json_parser import *
class TestFrame(TestCase):
def setUp(self) -> None:
self.json_parser = JsonParser()
self.video_details = {'frame_width': 500,
'frame_height': 200,
'num_of_frames': 100,
'frame_rate': 20}
self.out_path = mkdtemp()
self.list_of_files_to_remove = []
def test_automated_output_jsons(self):
self.json_parser.set_top_k(0)
self.json_parser.set_start()
frames = [0, 1, 2]
bbox_ids = [0, 1]
bbox_xywh = [(10, 20, 30, 40), (50, 60, 70, 80)]
time_to_output = 2
start = datetime.now()
for frame in frames:
self.json_parser.add_frame(frame)
sleep(1)
for i in range(len(bbox_ids)):
self.json_parser.add_bbox_to_frame(frame, bbox_ids[i], *bbox_xywh[i])
self.json_parser.schedule_output(output_path=self.out_path, hours=0, minutes=0, seconds=time_to_output)
end = datetime.now()
saved_files = listdir(self.out_path)
self.assertEqual(int((end - start).seconds / time_to_output), len(saved_files))
if __name__ == '__main__':
unittest.main()
انجام آزمایش خروجی
چرا mkdtemp؟
تابع mkdtemp از کتابخانه tempfile از یک منبع موقتی در سیستم استفاده کرده و یک پوشه موقت هم ایجاد میکند. این پوشه برای ذخیره کردنِ json به منظور آزمایش موقت در آنجا ذخیره میشود.
باید این فرایند بیش از یک ثانیه طول بکشد تا ببینیم json به صورت خودکار ذخیره میشود یا خیر. برای اینکه تاخیر زیادی در فرایند اتفاق نیفتد، از ویدئو در آزمایش استفاده نمیشود.
اکنون باید کد زیر را به اجرا درآوریم:
import json
from os import makedirs
from os.path import exists, join
from bunch import bunchify
from datetime import datetime
class JsonMeta(object):
HOURS = 4
MINUTES = 59
SECONDS = 59
PATH_TO_SAVE = 'jsons'
class JsonParser:
# ....
# I did not include the rest of code to let you
# just find the update to code
def json_output(self, output_name):
if not output_name.endswith('.json'):
output_name += '.json'
with open(output_name, 'w') as file:
json.dump(self.output(), file)
def set_start(self):
self.start_time = datetime.now()
def schedule_output(self, output_path=JsonMeta.PATH_TO_SAVE, hours: int = 0, minutes: int = 0, seconds: int = 60):
end = datetime.now()
interval = 0
interval += min([hours, JsonMeta.HOURS]) * 3600
interval += min([minutes, JsonMeta.MINUTES]) * 60
interval += min([seconds, JsonMeta.SECONDS])
diff = (end - self.start_time).seconds
if diff > interval:
output_name = self.start_time.strftime('%Y-%m-%d %H-%M-%S') + '.json'
output = join(output_path, output_name)
if not exists(output_path):
makedirs(output_path)
self.json_output(output_name=output)
self.frames.clear()
self.start_time = datetime.now()
اضافه کردن json_output و schedule_output
JsonMeta به چه دردی میخورد؟ دلیل استفاده از JsonMeta این است که میخواهیم بعضی از مقادیر مانند ثانیه، دقیقه و ساعت را به صورت پیش فرض قرار دهیم تا مقادیر مورد استفاده در در تابع schedule_output را کنترل کنیم. به کلاس JsonMeta توجه کنید:
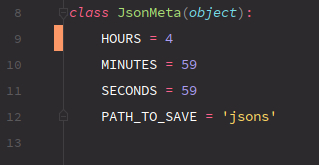
کلاس JsonMeta
بگذارید ببینیم آیا آزمایش با موفقیت انجام شده است یا خیر:
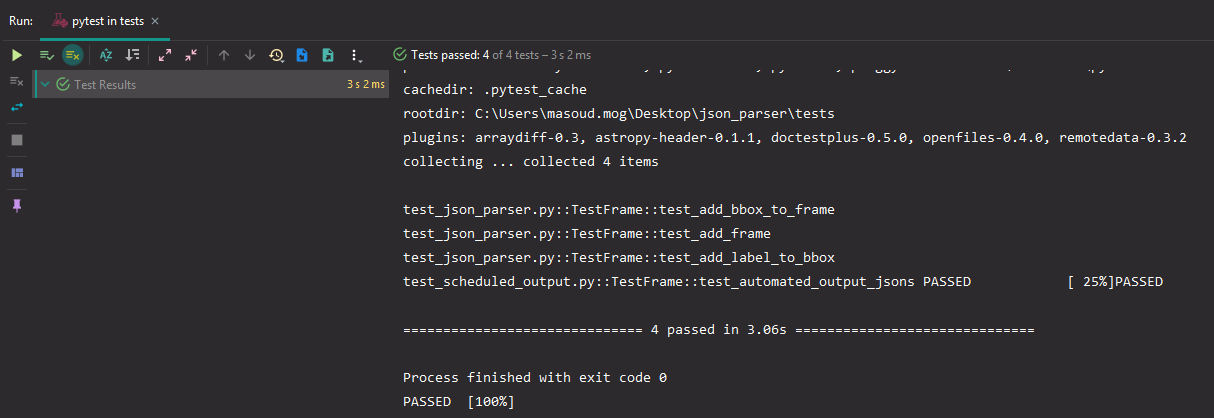
بسیار عالی! همه آزمایشها پاس شده است.
در نهایت از تابع زیر میتوان برای افزودن جزئیات ویدئو به json استفاده کرد:

پیشنهاد برای کارهای آتی
اکنون ابزاری در اختیار داریم که برای ذخیره json در سیستم نظارت لحظهای مفید است. توصیه میکنم ویژگیهای زیر را برای تمرین هم که شده، اضافه کنید:
1. دسته دیگری ایجاد کنید که قادر به تجزیه و تحلیل دادههای json باشد.
2. تابعی ایجاد کنید بتواند با بازسازی bboxها در فریم ویدئو، موارد شناسایی را ذکر کرده و نتایج را نشان دهد.
3. سعی کنید کد را در کد پروژه تشخیص اشیاء مورد استفاده قرار دهید.
کل کد پروژه تشخیص اشیاء در این لینک بارگذاری شده است.





