

مقدمهای بر پرکاربردترین الگوریتم های یادگیری ماشینی برای مبتدیان
 تیم تحریریه
تیم تحریریه- ۸ مرداد ۱۴۰۱
یکی از مطالعات اخیر نشان داده است که الگوریتم های یادگیری ماشینی طی 10 سال آینده، جایگزین 25% مشاغل سراسر دنیا خواهند شد. با توجه به رشد سریع و افزایش دسترسیپذیری ابرازهای برنامهنویسی (همچون Python و R)، یادگیری ماشین جایگاهی برجسته در میان متخصصان علوم داده به دست آورده است.
برنامههای یادگیری ماشینی به شدت خودکار و خوداصلاحکننده شدهاند؛ امری که همگام با امکان یادگیری از روی دادههای بیشتر و با حداقل مداخلات انسانی ممکن، به بهبود و ارتقای این برنامهها کمک میکند. برای نمونه، الگوریتم توصیهگر Recommendation system Netflix بر اساس فیلمهایی که کاربران تماشا میکنند، در مورد آیتمهایی که دوست داشته و نداشتهاند، بیشتر میآموزد.
تخصصیترین الگوریتم های یادگیری ماشینی ساخته شدهاند که به انواع مسائل پیچیدهی دنیای واقعی پرداخته و آنها را به طرز عالی حل میکنند. این نوشتار قصد دارد به مبتدیانی که در درک مقدمات یادگیری ماشینی به مشکل برخوردهاند، توضیحاتی در مورد الگوریتمهای برتر و پرکاربرد یادگیری ماشینی ارائه دهد.
الگوریتمهای یادگیری ماشین چه هستند؟
الگوریتم های یادگیری ماشینی را میتوان شبیه به الگوریتمهای دیگر علوم کامپیوتر دانست. الگوریتم یادگیری ماشینی فرآیندی است که روی دادهها انجام میشود و برای ساخت یک مدل یادگیری ماشینی و آمادهسازی آن برای تولید، مورد استفاده قرار میگیرد.
اگر یادگیری ماشینی را قطاری در نظر بگیرید که باید به مقصد خاصی (حل مسئلهی موردنظر) برسد، الگوریتم های یادگیری ماشینی حکم موتورهایی را دارند که رسیدن به این مقصد را میسر میسازند. اینکه برای هر مسئله کدام الگوریتم یادگیری ماشینی بهترین عملکرد ممکن را خواهد داشت، بستگی به نوع آن مسئله، ذات مجموعه داده، و منابع موجود دارد.
انواع الگوریتم های یادگیری ماشینی
الگوریتم های یادگیری ماشینی را میتوان در این طبقات دستهبندی کرد:
- الگوریتم های یادگیری ماشینی نظارتشده Supervised machine learning: الگوریتم های یادگیری ماشینی که بر اساس یک مجموعه نمونهی مشخص پیشبینی انجام میدهند در این دسته جای میگیرند. الگوریتمهای نظارتشده به دنبال پیدا کردن الگو در برچسبهای دادهها هستند. برخی از الگوریتم های یادگیری ماشینی که در مسائل یادگیری با نظارت به کار میروند عبارتاند از: SVM (ماشین بردار پشتیبانی) برای مسائل ردهبندی، رگرسیون خطی برای مسائل رگرسیون، و جنگل تصادفی برای مسائل رگرسیون و ردهبندی.
- الگوریتم های یادگیری ماشینی غیرنظارتشده Unsupervised machine learning: در این نوع یادگیری، دادهها هیچ برچسبی ندارند. این الگوریتمها دادهها را در مجموعهای از خوشهها ساماندهی میکنند تا ساختار آنها را توصیف کرده و دادههای پیچیده را برای انجام تجزیه و تحلیل، به صورت ساده و منظم درآورند.
- الگوریتم های یادگیری ماشینی تقویتی Reinforcement machine learning: این الگوریتمها بر اساس هر داده، یک حرکت را انتخاب میکنند و سپس میآموزند تصمیمی که (در انتخاب آن اقدام خاص) گرفتهاند چقدر درست بوده است. این الگوریتم به مرور زمان استراتژی خود را عوض میکند تا یادگیری بهتری داشته باشد و به بهترین پاداش ممکن برسد.
لیستی از الگوریتم های یادگیری ماشینی که هر مهندسی باید بشناسد
- الگوریتم رده بند بیز ساده Naïve Bayes Classifier
- الگوریتم خوشهبندی K میانگین K Means Clustering
- الگوریتم ماشین بردار پشتیبانی Support Vector Machine
- الگوریتم اپریوری Apriori
- الگوریتم رگرسیون خطیLinear Regression
- الگوریتم رگرسیون لوجیستیک Logistic Regression
- الگوریتم درخت تصمیم Decision Tree
- الگوریتم جنگل تصادفی Random Forest
- الگوریتم شبکههای عصبی مصنوعیArtificial Neural Network
- الگوریتم نزدیکترین همسایههاNearest Neighbors
- الگوریتم ارتقای گرادیان Gradient Boosting

الگوریتم رده بند بیز ساده
ردهبندی صفحهی یک وبسایت، سند، ایمیل یا هر متن نوشتاری طولانی دیگری به صورت دستی، کار دشوار و حتی غیرممکنی خواهد بود. اینجاست که الگوریتم رده بند بیز ساده وارد صحنه میشود. رده بند تابعی است که مقدار مؤلفهای که به یک جمعیت اختصاص میدهد را از یکی از دستههای موجود پیدا میکند.
فیلتر ایمیلهای ناشناس (اسپم) یا پیشبینی آب و هوا از جمله کاربردهای الگوریتم بیز ساده هستند. برای فیلتر ایمیلهای ناشناس، رده بندی به کار میرود که برچسب ناشناس (اسپم) یا مجاز (غیراسپم) را به ایمیلها اختصاص میدهد.
رده بند بیز ساده جزو محبوبترین روشهای یادگیری است که بر اساس قضیهی احتمالات بیز کار میکند؛ این الگوریتم مدلهایی برای پیشبینی بیماریها یا ردهبندی اسناد میسازد. این الگوریتم کلمات را بر اساس قضیهی احتمالات بیز ردهبندی میکند تا سپس محتوا مورد تجزیه و تحلیل ذهنی قرار گیرد.
این الگوریتم ردهبندی، با تکیه بر قضیهی بیز، از احتمالات استفاده میکند. مفروضهی بنیادی الگوریتمهای بیز ساده این است که همهی ویژگیها مستقل از یکدیگر باشند. پیادهسازی این الگوریتم کار سادهای است. این الگوریتمها برای کار با مجموعه دادگان بزرگ مناسب هستند و در مجموعه دادگان متنی نیز اجرا میشوند.
قضیهی بیز روشی برای محاسبهی احتمال پسین (خلفی) P(A|B)، از روی P(A)،P(B) و P(B|A) ارائه میدهد:
در این فرمول، P(A|B) احتمال وقوع A به شرط B، P(A) احتمال پسین A ،P(B|A) احتمال وقوع B به شرط A و P(B) احتمال پسین B است.
چه زمانی از الگوریتم رده بند بیز ساده استفاده میکنیم؟
- زمانیکه اندازهی مجموعه داده متوسط تا بزرگ است؛
- زمانی که نمونهها، چندین ویژگی دارند؛
- زمانی که با توجه به پارامتر ردهبندی، ویژگیهایی که نمونهها را توصیف میکنند باید مستقل شرطی باشند.
کاربردهای الگوریتم رده بند بیز ساده

- تجزیه و تحلیل عواطف Sentiment analysis: در فیسبوک برای تحلیل تغییرات قسمت شرححال و تشخیص عواطف مثبت یا منفی به کار میرود.
- دستهبندی اسناد Document categorization: قابلیت PageRank گوگل برای شاخصدهی به اسناد و مشخص کردن میزان ارتباط صفحات استفاده میکند. PageRank صفحات را تجزیه و دستهبندی کرده و بر اساس میزان ارتباط، آنها را به عنوان «مهم» تشخیص میدهد.
- الگوریتم بیز ساده در ردهبندی مقالات جدید در حوزههای گوناگون (فناوری، سرگرمی، ورزش، سیاست و غیره) کاربرد دارد.
- فیلتر ایمیلهای ناشناس: Google Mail از الگوریتم بیز ساده در ردهبندی ایمیلها در دو دستهی ناشناس (اسپم) یا مجاز (غیراسپم) استفاده میکند.
مزایای رده بند بیز ساده
- زمانی که متغیرهای ورودی از نوع ردهای باشند، این الگوریتم عملکرد خوبی از خود نشان میدهد.
- سرعت همگرایی رده بند بیز ساده در مقایسه با مدلهای متمایزگر (همچون رگرسیون لجستیک) بیشتر است و این باعث میشود به دادههای آموزشی کمتری نیاز داشته باشد؛ البته به شرطی که مفروضهی استقلال شرطی بیز برقرار باشد.
- پیشبینی کلاس دادههای مجموعه داده ها آزمایشی با رده بند بیز ساده آسانتر است؛ به همین دلیل، این الگوریتم برای مسائل پیشبینی چندکلاسی نیز عملکرد خوبی دارد.
- با اینکه کارکرد رده بند بیز ساده مشروط به برقراری مفروضهی استقلال شرطی است، عملکرد خوبی در حوزههای کاربردی گوناگون از خود نشان داده است.
کتابخانههای Python برای پیادهسازی بیز ساده: Scikit Learn
الگوریتم خوشهبندی K میانگین
الگوریتم K میانگین یکی از محبوبترین الگوریتم های یادگیری ماشینی برای تجزیه و تحلیل خوشهای Cluster analysis است. K میانگینK-mean یک روش تکراری و غیرقطعی (غیرجبری) است. این الگوریتم روی یک مجموعه دادهی مشخص، با تعداد خوشهی از پیشتعیین شده (k) عمل میکند. خروجی الگوریتم K میانگین، k خوشه و قسمتبندی دادههای ورودی در این خوشههاست.
برای مثال فرض کنید میخواهیم الگوریتم خوشه بندی K میانگین را برای نتایج جستجوی ویکیپدیا به کار ببریم. در نتیجهی جستجوی واژهی جگوآر در ویکیپدیا صفحاتی نشان داده میشود که این کلمه را در معانی مختلف آن دربردارند؛ این کلمه میتواند به یک ماشین، به یک نسخه از Mac OS و یا به یک حیوان اشاره داشته باشد.
الگوریتم خوشهبندی K میانگین را میتوان روی مجموعهای از صفحات وب اجرا کرد و صفحاتی که مفهوم مشابهی دارند را در یک خوشه قرار داد. برای مثال، الگوریتم همهی صفحات وب که به جگوآر به عنوان یک حیوان اشاره کردهاند را در یک خوشه قرار میدهد.
مزایای استفاده از الگوریتم خوشهبندی K میانگین
- در صورتی که با خوشههایی کلی سروکار دارید، الگوریتم K میانگین نسبت به روش خوشهبندی سلسلهمراتبی، خوشههای کوچکتری ایجاد میکند.
- اگر k مقدار کوچکی داشته باشد و تعداد متغیرها زیاد باشد، این الگوریتم میتواند عملکردی سریعتر از خوشهبندی سلسلهمراتبی داشته باشد.
کاربردهای الگوریتم خوشهبندی K میانگین
بیشتر موتورهای جستجو، همچون Yahoo و Google برای خوشهبندی صفحات وب بر اساس شباهت و تعیین مقدار ارتباط نتایج جستجو، از الگوریتم خوشهبندی K میانگین استفاده میکنند. این روش به موتورهای جستجو کمک میکند زمان محاسبات را برای کاربران کاهش دهند.
کتابخانههای Python برای پیادهسازی الگوریتم خوشهبندی K میانگین: SciPy ،Sci-Kit Learn ،Python Wrapper.
کتابخانههای R برای پیادهسازی الگوریتم خوشهبندی K میانگین: stats
الگوریتم ماشین بردار پشتیبانی
ماشین بردار پشتیبانی یک الگوریتم نظارتشده است که در مسائل ردهبندی و رگرسیون به کار میرود. در این الگوریتم، مجموعه داده به ماشین بردار پشتیبانی یا SVM آموزش میدهد تا دادههای جدید پشتیبانی کند. این الگوریتم خطی (ابرصفحه) را پیدا میکند که مجموعه داده آموزشی را در چندین کلاس تقسیم میکند.
از آنجایی که تعداد زیادی از این ابرصفحات وجود دارند، الگوریتم SVM سعی میکند ابرصفحهای را پیدا کند که فاصلهی بین کلاسها را به حداکثر میرساند؛ به این امر «بیشینهسازی حاشیه Margin maximization» گفته میشود. اگر خطی پیدا شود که فاصلهی بین کلاسها را به حداکثر برساند، احتمال تعمیم دادههای جدید (به کلاسهای موجود) افزایش مییابد.
3SVMها را میتوان به دو دسته تقسیم کرد
- SVM خطی: در SVM خطی، دادههای آموزشی یعنی کلاسها توسط یک ابرصفحه از هم جدا میشوند.
- SVM غیرخطی: در SVM غیرخطی امکان جداسازی دادههای آموزشی با استفاده از یک ابرصفحه وجود ندارد. برای مثال، دادههای آموزشی برای مسئلهی شناسایی چهره شامل مجموعهای تصویر چهره و مجموعهی دیگری از تصاویر غیرچهره (هر تصویر دیگری که از چهره نباشد) هستند. تحت چنین شرایطی، دادههای آموزشی آنقدر پیچیده هستند که نمیتوان برای هر بردار ویژگی یک بازنمایی پیدا کرد. جداسازی مجموعهی چهرهها از مجموعهی غیرچهره به صورت خطی، مسئلهی بسیار پیچیدهای خواهد بود.
مزایای استفاده از SVM
- SVM بهترین عملکرد (بالاترین دقت) را در ردهبندی دادههای آموزشی از خود نشان میدهد.
- SVMها عملکرد دقیقتری در ردهبندی دادههای جدید دارند.
- برجستهترین مزیت SVMها این است که هیچ مفروضهی قطعی در مورد دادهها ندارند.
- این الگوریتم به مشکل بیشبرازش برنمیخورد.
کاربردهای SVM
یکی از کاربردهای رایج ماشینهای بردار پشتیبانی در بازار سهام توسط مؤسسات مالی است. برای مثال، از این الگوریتم میتوان برای مقایسهی عملکرد نسبی سهامهای یک بخش استفاده کرد. مقایسهی نسبی SVM از سهامها میتواند در تصمیمگیری دربارهی سرمایهگذاری مفید باشد.
کتابخانههای Python برای پیادهسازی الگوریتم SVM: SciKit Learn ،PyML،SVMStruct Python و LIBSVM
الگوریتم اپریوری
الگوریتم اپریوری یکی از الگوریتم های یادگیری بدون نظارت است که بر اساس یک مجموعه داده، قوانین اتحاد تولید میکند. منظور از قوانین اتحاد این است که اگر آیتم A روی دهد، آیتم B هم با میزان احتمال مشخصی اتفاق خواهد افتاد. بیشتر قوانین اتحاد تولیدشده در فرمت «اگر-پس If-then » هستند.
برای مثال، اگر مردم یک iPad بخرند، پس یک جلد iPad هم میخرند. این الگوریتم برای استخراج چنین نتیجهگیریهایی، ابتدا تعداد افرادی را که iPad خریدهاند و جلد iPad نیز خریدهاند را مشاهده میکند. سپس یک نسبت به دست میآید؛ مثلاً از 100 نفری که iPad خریدهاند، 85 نفر جلد iPad هم گرفتهاند.
اصل زیربنایی الگوریتم اپریوری
- اگر یک مجموعه آیتم غالباً اتفاق بیفتد، همهی زیرمجموعههای آن مجموعه نیز غالباً روی خواهند داد.
- اگر یک مجموعه آیتم به ندرت اتفاق بیفتد، ابرمجموعهی (زبرمجموعه) آن هم قبلاً به ندرت اتفاق افتاده است.
مزایای الگوریتم اپریوری
- پیادهسازی و اجرای موازی این الگوریتمها آسان است.
- با اجرای اپریوری میتوان ویژگیهای مجموعههای بزرگی از آیتمها را مورد استفاده قرار داد.
کاربردهای الگوریتم اپریوری

- تشخیص واکنش منفی به دارو: الگوریتم اپریوری ارتباط بین دادههای حوزهی بهداشت و درمان (مثلاً داروهای استفاده شده توسط بیماران، مشخصات بیماران، سابقهی بیمار از عوارض جانبی داروها، تشخیص اولیه و مواردی از این دست) را تجزیه و تحلیل میکند. نتیجهی این تجزیه و تحلیل، قوانین اتحادی هستند که ترکیب مشخصات بیمار و داروها را تشخیص میدهند تا در نهایت عوارض جانبی و اثرات منفی داروها را مشخص کنند.
- تجزیه و تحلیل Market Basket: بسیاری از برجستهترین برندهای بازرگانی دیجیتال برای استخراج اطلاعات دادهها در مورد محصولات پرفروش و محصولاتی که باید ارتقاء یابند، از الگوریتم اپریوری استفاده میکنند. برای نمونه، یک فروشنده میتواند با استفاده از الگوریتم اپریوری پیشبینی کند افرادی که شکر و آرد میخرند، احتمالاً تخممرغ هم خواهند خرید تا یک کیک درست کنند.
- قابلیت تکمیل خودکار: قابلیت تکمیل خودکار گوگل یکی دیگر از کاربردهای پرطرفدار الگوریتم اپریوری است؛ وقتی کاربر یک کلمه را تایپ میکند، موتور جستجو دنبال کلمات مرتبط میگردد؛ یعنی کلماتی که مردم معمولاً بعد از آن کلمهی خاص جستجو میکنند.

کتابخانهی Python برای پیادهسازی الگوریتم اپریوری: PyPi
کتابخانهی R برای پیادهسازی الگوریتم اپریوری: arules
الگوریتم رگرسیون خطی
الگوریتم رگرسیون خطی ساده علاوه بر رابطهی بین دو متغیر، این موضوع را نشان میدهد که تغییر در یکی از این متغیرها چطور میتواند بر دیگری تأثیر بگذارد. این الگوریتم، تأثیر تغییرات متغیر مستقل روی متغیر وابسته را نشان میدهد. متغیرهای وابسته را به نام متغیرهای توضیحی نیز میشناسند؛ زیرا عواملی که بر متغیر وابسته تأثیر میگذارند را توضیح میدهند. در سوی دیگر، به متغیر وابسته عامل موردنظر یا پیشبینی کننده نیز گفته میشود.

مزایای الگوریتم رگرسیون خطی
- این الگوریتم یکی از توضیحپذیرترین الگوریتم های یادگیری ماشینی است و توضیح آن برای افراد آسان است.
- استفاده از آن آسان است و به حداقل تنظیم ممکن نیاز دارد.
- از پرکاربردترین الگوریتم های یادگیری ماشینی است که اجرای سریعی هم دارد.
کاربردهای رگرسیون خطی
- برآورد میزان فروش: رگرسیون خطی در کسب و کار، برای مثال در پیشبینی میزان فروش بر اساس ترندهای بازار، کاربرد فراوانی دارد. اگر شرکتی شاهد افزایش مداوم در میزان فروش ماهیانهی خود باشد، تجزیه و تحلیل رگرسیون خطی دادههای فروش ماهیانه به شرکت کمک میکند فروش ماههای آینده را پیشبینی کند.
- ارزیابی خطر: رگرسیون خطی به ارزیابی خطر در حوزههای بیمه و مالی کمک میکند. یک شرکت بیمهی درمانی میتواند روی تعداد درخواستهای هر مشتری بر اساس سن آنها، تجزیه و تحلیل رگرسیون خطی انجام دهد. نتیجهی این فرآیند به شرکتهای بیمه کمک میکند بفهمند مشتریان مسنتر تعداد درخواستهای بیشتری دارند. چنین نتایجی نقش مهمی در تصمیمات اساسی این حوزهها ایفا کرده و به پیشبینی ریسک کمک میکنند.
کتابخانههای Python برای پیادهسازی رگرسیون خطی: statsmodel و scikit
کتابخانهی R برای پیادهسازی رگرسیون خطی: Stats
الگوریتم های یادگیری ماشینی رگرسیون لوجیستیک
اسم این الگوریتم شاید مقداری گمراهکننده به نظر برسد؛ چون این الگوریتم برای مسائل ردهبندی استفاده میشود، نه مسائل رگرسیون. کلمهی رگرسیون که در نام این الگوریتم به کار رفته حاکی از این است که یک مدل خطی در فضای ویژگی جای میگیرد. الگوریتم رگرسیون لوجیستیک یک تابع لوجیتسیک را روی ترکیب خطی از ویژگیها اجرا میکند تا خروجی یک متغیر ردهای وابسته را بر اساس متغیرهای پیشبینی کننده (مستقل) پیشبینی کند.
مقادیر احتمال (که خروجی یک بار آزمایش هستند) به صورت تابعی از متغیرهای توصیفی مدلسازی میشوند. الگوریتمهای رگرسیون لوجیستیک کمک میکنند برآورد کنیم بر اساس متغیرهای پیشبینی کننده موجود، احتمال سطح خاصی از متغیر ردهای وابسته چقدر است.
فرض کنید میخواهید پیشبینی کنید فردا در نیویورک بارش برف خواهیم داشت یا نه. خروجی پیشبینی در این مثال یک عدد پیوسته نیست، چون برف یا میبارد یا نمیبارد. در نتیجه میتوان از رگرسیون لوجیستیک استفاده کرد. متغیر خروجی باید در یکی از دستههای (ردهها) موجود قرار داشته باشد؛ بنابراین، الگوریتم رگرسیون لوجیستیک به رسیدن به این خروجی کمک میکند.
انواع رگرسیون لوجیستیک
- رگرسیون لوجیستیک دودویی Binary Logistic Regression: وقتی پاسخ ردهای، دو خروجی ممکن (یعنی بله یا خیر) دارد، پرکاربردترین الگوریتم، رگرسیون لوجیستیک دودویی است. مثالها: آیا دانشآموزی نمرهی قبولی را در یک امتحان به دست میآورد یا خیر؛ فردی فشار خون بالا دارد یا نه؛ تومور سرطانی است یا نه.
- رگرسیون لوجیستیک چندجملهایMulti-nominal logistic regression: زمانی به کار میرود که پاسخ ردهای 3 یا تعداد بیشتری خروجی احتمالی داشته باشد. مثال: شهروندان ایالات متحده از کدام موتور جستجو (Yahoo، Bing، Google و MSN) بیشتر استفاده میکنند.
- رگرسیون لوجیستیک ترتیبیOrdinal Logistic Regression: پاسخ ردهای 3 یا تعداد بیشتری خروجی دارد که ترتیب طبیعی دارند. مثال: مشتری چه نمرهای از مقیاس 1 تا 10 به خدمات و کیفیت غذای یک رستوران اختصاص میدهد.
برای درک بهتر آنچه گفته شد یک مثال میزنیم. فرض کنید یک شیرینیپزی میخواهد بررسی کند کیکهایی که در دمای 160، 180 و 200 درجه پخته میشوند بافت «نرم» خواهند داشت یا «خشک» (با فرض اینکه این شیرینیپزی هر دو نوع کیک را با اسامی و قیمتهای مختلف میفروشد). در بین تکنیکهای آماری، رگرسیون لوجیستیک برای این مسئله مناسبترین راهکار است.
شیرینیپزها دو دسته کیک درست میکنند؛ دستهی اول 20 کیک (که 7 تا بافت «خشک» و 13 تا بافت «نرم» دارند) و دستهی دوم 80 کیک (41 با بافت «نرم» و 39 تا با بافت «خشک») دارد. الگوریتم رگرسیون خطی اینجا ضریب اهمیت یکسانی برای هر دو دسته در نظر میگرفت و به تعداد کیکهای موجود در هر دسته توجهی نمیکرد. اما با استفاده از الگوریتم رگرسیون لوجیستیک، به این عامل نیز توجه میشود و به کیکهای دستهی دوم ضریب بیشتری داده میشود.
موارد استفادهی الگوریتم رگرسیون لوجیستیک
- وقتی باید احتمالات متغیر پاسخ را به صورت تابعی از یک متغیر توصیفی دیگر مدلسازی کنید. برای مثال، احتمال خرید محصول X به عنوان تابعی از جنسیت مشتریان.
- وقتی باید مشخص کنید احتمال اینکه متغیرهای وابستهی ردهای، به صورت تابعی از متغیرهای توصیفی، در یکی از دو دسته (پاسخهای دودویی) قرار بگیرند، چقدر است. برای مثال، چقدر احتمال دارد مشتری، به شرط اینکه خانم باشد، محصول X را خریداری کند؟
- زمانی که باید مؤلفهها را بر اساس متغیر توصیفی در دو دسته، ردهبندی کرد. برای مثال، خانمها را بر اساس سنشان در دو دستهی «جوان» و «مسن» دستهبندی کنید.
مزایای الگوریتم رگرسیون لوجیستیک
- امکان بازبینی آنها آسانتر بوده و پیچیدگی کمتری دارند.
- الگوریتمی قوی و مقاوم است، چون متغیرهای مستقل نباید لزوماً واریانس برابر یا توزیع نرمال داشته باشند.
- این الگوریتمها پیشفرضی مبنی بر وجود رابطهی خطی بین متغیرهای مستقل و وابسته ندارند و در نتیجه میتوانند اثرات غیرخطی را مدیریت کنند.
- تعامل آزمونها را کنترل میکنند.
معایب الگوریتم رگرسیون لوجیستیک
- وقتی دادههای آموزشی پراکنده و پیچیده باشند، مدل لوجیستیک ممکن است دچار مشکل بیشبرازش شود.
- الگوریتمهای رگرسیون لوجیستیک نمیتوانند خروجیهای پیوسته را پیشبینی کنند. برای نمونه، اگر بخواهیم شدت بارش باران را تعیین کنیم، نمیتوانیم از این الگوریتم استفاده کنیم چون شدت بارش یک متغیر پیوسته است. متخصصان علوم داده میتوانند بارش سبک یا سنگین را پیشبینی کنند، اما این امر مستلزم تغییر دادن و سازگار کردن مجموعه داده است.
- الگوریتمهای رگرسیون لوجیستیک برای دستیابی به نتایج پایا و معنیدار نیاز به دادههای بیشتری دارند. این الگوریتمها برای داشتن عملکردی قابل قبول باید به ازای هر متغیر پیشبینی کننده، حداقل 50 نقطهداده داشته باشند.
- این الگوریتمها خروجیها را بر اساس یک گروه از متغیرهای وابسته پیشبینی میکنند؛ بنابراین اگر یک متخصص علوم داده یا متخصص یادگیری ماشینی در تشخیص متغیرهای وابسته مرتکب اشتباه شود، مدل ساختهشده هیچ ارزش پیشبینی نخواهد داشت یا ارزش آن بسیار پایین خواهد بود.
- این الگوریتم در برابر دادههای پرت و دادههای گمشده مقاوم نیست.
کاربردهای الگوریتم رگرسیون لوجیستیک
- الگوریتم رگرسیون لوجیستیک در حوزهی اپیدمیولوژی (همهگیرشناسی) برای تشخیص عوامل خطرزای بیماریها و برنامهریزی راهکارهای پیشگیرانهی مناسب کاربرد دارد.
- برای پیشبینی برد یا باخت یک نامزد خاص در رقابتهای سیاسی، یا پیشبینی اینکه رأیدهندگان به نامزد خاصی رأی میدهند یا خیر، استفاده میشود.
- در ردهبندی مجموعه کلمات (مثلاً در دستههای اسم، فعل، صفت) به کار میرود.
- یکی دیگر از کاربردهای این الگوریتم در پیشبینی وضعیت آب و هوا برای پیشبینی احتمال بارش باران است.
- در سیستمهای مدیریت خطر، برای ردهبندی اعتبار به منظور پیشبینی نکول حسابها به کار میرود.
کتابخانهی Python برای پیادهسازی الگوریتم رگرسیون لوجیستیک: Sci-Kit Learn
کتابخانهی R برای پیادهسازی الگوریتم رگرسیون لوجیستیک: stats package (glm () function)
الگوریتم درخت تصمیم
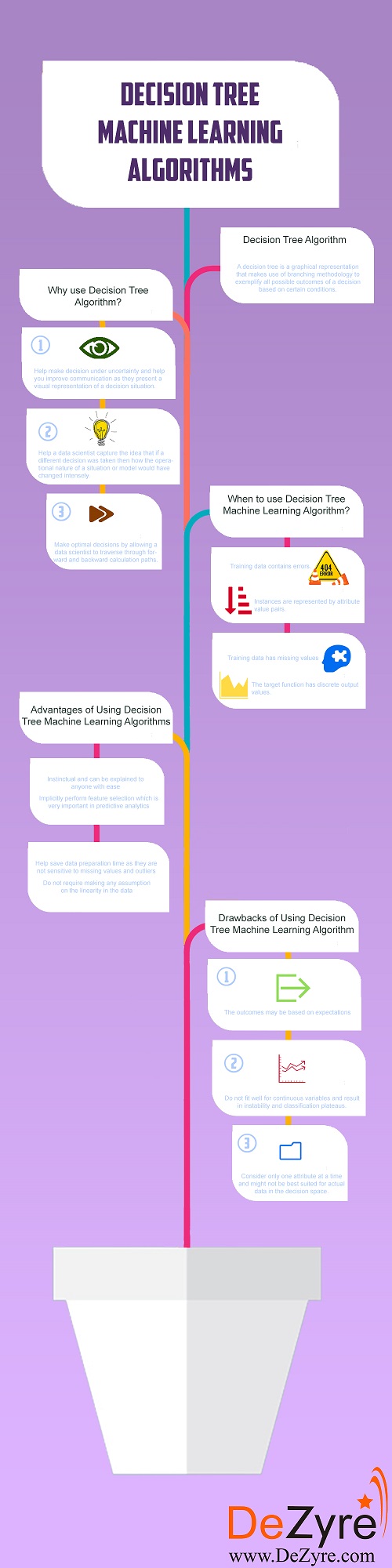
فرض کنید آخر هفته مهمان دارید و میخواهید به بهترین رستوران شهر بروید. اما در مورد اینکه کدام رستوران را انتخاب کنید شک دارید. هروقت میخواهید به رستورانی بروید از دوستتان تایرون میپرسید به نظرش شما آنجا را دوست خواهید داشت یا نه. تایرون برای پیدا کردن پاسخ این سؤال، ابتدا باید بداند شما چه رستورانهایی را دوست دارید.
شما هم یک لیست به او میدهید که شامل رستورانهایی که تا به حال رفتهاید و علاقه یا عدم علاقهی شما به آنهاست (مجموعه داده برچسبدار). وقتی از تایرون بپرسید به نظرش رستوران X مطابق علاقهی شما هست یا خیر، او سؤالاتی از این دست از شما میپرسد: «آیا رستوران X در فضای آزاد است؟»، «آیا غذای ایتالیایی دارد؟»، «پخش زندهی موسیقی دارد؟»، «آیا تا نیمهشب باز هست؟». تایرون با پرسیدن این سؤالات آگاهیبخش، حداکثر اطلاعات ممکن را کسب میکند و یک پاسخ «بله» یا «خیر» به شما ارائه میدهد. در این مثال، تایرون یک درخت تصمیم برای ترجیحات شما در مورد رستورانها به شمار میرود.
درخت تصمیم یک بازنمایی گرافیکی است که با استفاده از روش شاخهای (انشعاب)، همهی خروجیهای ممکن یک تصمیم را در شرایط مختلف، نشان میدهد. گرهی داخلی یک درخت تصمیم نشاندهندهی یک آزمون ویژگی است، هر شاخه نشاندهندهی خروجی آن آزمون و گرههای برگی نشاندهندهی برچسب یک کلاس خاص است (یعنی تصمیمی که بعد از محاسبهی همهی ویژگیها گرفته میشود). قواعد ردهبندی توسط مسیرهای مختلف ریشه تا هرکدام از گرههای برگی مشخص میشوند.
انواع درخت تصمیم
- درختهای ردهبندیClassification trees: حالت پیشفرض درختهای تصمیمگیری این الگوریتمها هستند. درختهای ردهبندی، مجموعه داده را بر مبنای متغیر پاسخ به کلاسهای مختلف تقسیم میکنند. این درختها اغلب زمانی مورد استفاده قرار میگیرند که متغیر پاسخ، ردهای باشد.
- درختهای رگرسیون Regression trees: وقتی متغیر پاسخ یا هدف پیوسته یا عددی باشد، از درختهای رگرسیون استفاده میکنیم. این درختها بیشتر در مسائلی از نوع پیشبینی به کار میروند.
درختهای تصمیم را میتوان بر اساس متغیر هدف نیز به دو دستهی متغیر پیوسته و متغیر دودویی تقسیم کرد. متغیر هدف است که به انتخاب درخت تصمیم مناسب کمک میکند.

چرایی استفاده از درخت تصمیم
- این الگوریتم های یادگیری ماشینی به تصمیمگیری تحت شرایط مبهم کمک میکنند. علاوه بر این، به خاطر بازنمایی تصویری که از موقعیتهای تصمیم ارائه میدهند، در ارتقای روابط نیز مفید هستند.
- متخصصان علوم داده به کمک درختهای تصمیم میتوانند درک کنند اگر تصمیم متفاوتی میگرفتند، ذات عملیاتی یک موقعیت یا مدل چطور تحت تأثیر قرار میگرفت.
- الگوریتم درخت تصمیم در اتخاذ تصمیمات بهینه مفید است؛ زیرا به متخصص علوم داده این امکان را میدهند که در طول مسیرهای محاسباتی رو به عقب و جلو حرکت کنند.
موقعیتهای استفاده از الگوریتم درخت تصمیم
- درختهای تصمیم در برابر خطاها مقاوم هستند. به همین دلیل اگر در دادههای آموزشی خطایی وجود داشته باشد، این الگوریتمها بهترین گزینه برای حل مسئلهی موجود خواهند بود.
- درختهای تصمیم برای حل مسائلی که نمونههای آن به صورت جفت مقادیر ویژگی بازنمایی میشوند، بهترین انتخاب هستند.
- اگر در دادههای آموزشی مقادیر گمشده وجود داشته باشد، میتوان از درختهای تصمیم استفاده کرد. زیرا میتوانند به خوبی، با نگاه کردن به دادههای موجود در ستونهای دیگر، مقادیر گمشده را مدیریت کنند.
- هنگامی که مقادیر خروجی تابع هدف، گسسته هستند، بهترین راه استفاده از درختهای تصمیم است.
مزایای الگوریتمهای درخت تصمیم
- درختهای تصمیم بدیهی هستند و به راحتی میتوان آنها را به همه توضیح داد. افرادی که پیشزمینهای در حوزهی فنی ندارند نیز میتوانند فرضیهای که توسط یک درخت تصمیم تولید میشود را درک کنند، چون این خروجیها واضح هستند.
- در استفاده از درختهای تصمیم، لازم نیست به نوع داده به چشم یک محدودیت نگاه کنیم. چون این الگوریتمها میتوانند هر دو نوع متغیرهای ردهای و عددی را مدیریت کنند.
- الگوریتمهای درخت تصمیم مفروضهای در رابطه با خطی بودن دادهها ندارند و به همین دلیل در شرایطی که پارامترها رابطهی غیرخطی دارند میتوان از آنها استفاده کرد. این الگوریتمها در مورد ساختار رده بند و توزیع فضا نیز مفروضهای ندارند.
- درختهای تصمیم در جستجوی داده نیز به کار میروند. این الگوریتمها مسئلهی انتخاب ویژگی را که در تحلیل پیشبینی کننده از اهمیت بالایی برخوردار است، به صورت ضمنی اجرا میکنند. وقتی یک درخت تصمیم روی مجموعه داده آموزشی آموزش میبیند، گرههای بالا (که درخت در آنها شاخه شاخه میشود) به عنوان متغیرهای مهم موجود در آن مجموعه داده شناخته میشوند و بدین طریق انتخاب ویژگی خودبخود به انجام میرسد.
- این الگوریتمها باعث صرفهجویی در زمان آمادهسازی داده نیز میشوند؛ زیرا به مقادیر گمشده و مقادیر پرت حساس نیستند. به عبارتی، دادههای گمشده نمیتوانند مانع از تقسیم دادهها برای ساخت یک درخت تصمیم، شوند. دادههای پرت نیز روی درختهای تصمیم تأثیری نمیگذارند؛ چون تقسیم داده بر اساس نمونههایی انجام میگیرد که داخل یک بازه قرار دارند (نه مقادیر مطلق و دقیق).
معایب الگوریتمهای درخت تصمیم
- هرچه تعداد تصمیمات یک درخت بیشتر باشد، میزان دقت آن کاهش مییابد.
- یکی از معایب عمدهی درختهای تصمیم این است که خروجیها میتوانند مبتنی بر انتظارات باشند. هنگام تصمیمگیری فوری، بازده و نتایج به دستآمده شاید همان چیزی باشند که انتظار میرفت یا برنامهریزی شده بود. در نتیجه این احتمال وجود دارد که این درختهای تصمیم غیرواقعنگر، منجر به تولید تصمیمات نامناسبی شوند. هرگونه انتظار غیرمنطقی میتواند منجر به خطا و نقص عمده در تحلیل درخت تصمیم شود؛ چون همیشه نمیتوان همهی احتمالات که از یک تصمیم ناشی میشوند را برنامهریزی کرد.
- درختهای تصمیم روی متغیرهای پیوسته خوب آموزش نمیبینند و این باعث عدم ثبات و وجود حاشیه برای ردهبندی میشود.
- استفاده از درختهای تصمیم در مقایسه با سایر مدلهای تصمیمگیری آسان است، اما ساخت درختهای تصمیم بزرگ که چندین شاخه دارند، کاری پیچیده و زمانبر است.
- الگوریتم های یادگیری ماشینی ویژگیها را تک تک در نظر میگیرند و به همین دلیل شاید برای کار با دادههای واقعی در حوزهی تصمیم مناسب نباشند.
- درختهای تصمیم بزرگ با شاخههای متعدد قابل درک نیستند و ارائه و توضیح آنها مشکلزاست.
کاربردهای الگوریتمهای درخت تصمیم
- درختهای تصمیم از جمله الگوریتم های یادگیری ماشینی هستند که در حوزهی مالی برای قیمتگذاری، محبوبیت زیادی دارند.
- سنجش از راه دور یکی از کاربردهای مسئلهی شناسایی الگو است که از طریق درختهای تصمیم انجام میشود.
- بانکها از الگوریتمهای درخت تصمیم برای ردهبندی متقاضیان وام بر اساس احتمال نکول اقساط آنها استفاده میکنند.
- Gerber Products یک شرکت محبوب وسایل کودک است که از این الگوریتمها برای تصمیمگیری در مورد ادامه یا توقف استفاده از PVC (کلرور پلی وینیل) پلاستیکی در محصولات خود از این الگوریتمها استفاده کرد.
- مرکز علوم پزشکی دانشگاه راش ابزاری به نام Gaurdian ساخته است که با استفاده از الگوریتم درخت تصمیم، بیماران در معرض خطر و رویهی بیماریها را تشخیص میدهد.
کتابخانههای Python برای پیادهسازی الگوریتمهای درخت تصمیم: SciPy، Sci-Kit Learn
کتابخانهی R برای پیادهسازی الگوریتمهای درخت تصمیم: caret

الگوریتم های یادگیری ماشینی جنگل تصادفی
از همان مثالی که برای درختهای تصمیم زدیم برای توضیح الگوریتم جنگل تصادفی استفاده میکنیم. دوستتان، تایرون، یک درخت تصمیم است که در انتخاب رستوران به شما کمک میکند. با این حال تایرون نمیتواند همیشه در تشخیص رستوران موردعلاقهی شما صحیح عمل کند. برای رسیدن به نتایج دقیقتر و صحیحتر، از چند نفر از دوستانتان این سؤال را میپرسید و بعد اگر نظر همهی آنها این بود که شما رستوران X را میپسندید، آن را انتخاب میکنید.
پس به جای اینکه فقط از تایرون بپرسید، از جان، ساندر، بران و جک هم میخواهید که نظر خود را در مورد رستوران X مطرح کنند. در نتیجه میتوان گفت یک مجموعهی رده بند متشکل از چندین درخت تصمیم ساختهاید؛ به این مجموعه جنگل میگویند.
از آنجایی که نمیخواهید همهی دوستانتان یک پاسخ تکراری به شما بدهند، اطلاعاتی که در اختیار آنها گذاشتهاید کمی با هم تفاوت دارد. به عبارتی، فرض کنید در مورد ترجیحاتی که دربارهی رستورانها دارید مطمئن نبودید و شک داشتید. برای مثال، به تایرون گفتید که رستورانهای واقع روی بام و فضای باز را دوست دارید، چون تابستان سال قبل که به چنین رستورانی رفتید از آن خوشتان آمد؛ شاید در هوای سرد این نوع رستوران را دوست نداشته باشید. به همین دلیل همهی دوستان شما نباید از این داده که رستورانهای فضای باز را دوست دارید استفاده کنند، تا در نهایت بتوانند پیشنهادات مناسبی به شما ارائه دهند.
وقتی دادههای کمی متفاوت را در اختیار دوستانتان قرار میدهید، آنها هم از شما سؤالات مختلفی در زمانهای مختلف میپرسند. میتوان گفت با تغییر اندک دادهها (ترجیحاتتان در مورد رستوران)، دارید تصادفی بودن را در سطح مدل (با تصادفی بودن در سطح دادهها که در درختهای تصمیم دیدیم تفاوت دارد) تزریق میکنید. بدین ترتیب دوستان شما یک جنگل تصادفی را شکل میدهند.
[irp posts=”8129″]جنگل تصادفی یکی از الگوریتم های یادگیری ماشینی است که با استفاده از روش bagging، چند درخت تصمیم ایجاد میکند، زیرمجموعههایی از دادهها که در اختیار این درختها قرار میگیرند تصادفی هستند. مدل چندین بار روی نمونههای تصادفی از مجموعه داده آموزش میبیند تا به عملکرد خوبی در پیشبینی دست پیدا کند.
در این روش یادگیری گروهی، خروجی همهی درختهای تصمیم موجود در جنگل تصادفی، با هم ترکیب میشوند تا پیشبینی نهایی را تولید کنند. پیشبینی نهایی الگوریتم جنگل تصادفی یا با نمونهگیری نتایج هرکدام از درختها به دست میآید یا با انتخاب یکی از پیشبینیها که بیشتر از همه بین درختها تکرار شده است.
در مثالی که بالا زده شد، اگر 5 نفر از دوستانتان تصمیم بگیرند که شما رستوران X را دوست خواهید داشت، اما تصمیم تنها دو نفر خلاف این باشد، پیشبینی نهایی این خواهد بود که به احتمال زیاد رستوران X را دوست خواهید داشت (چون نظر اکثریت این بوده است).
چرایی استفاده از الگوریتم جنگل تصادفی
- پیادهسازیهای فراوان، باکیفیت، رایگان و متنباز از این الگوریتم در زبان R و Python وجود دارند.
- وقتی دادهی گمشده یا دادهی پرت دارید، این الگوریتم میتواند همچنان عملکرد خوبی داشته باشد.
- کاربرد آن آسان است، زیرا تنها با چند خط میتوان آن را اجرا کرد.
- الگوریتمهای جنگل تصادفی به متخصصان علوم داده کمک میکنند زمان لازم برای آمادهسازی دادهها را کاهش دهند، زیرا نیازی به آمادهسازی ورودی ندارند و میتوانند ویژگیهای عددی، دودویی و ردهای را بدون مقیاسدهی، تبدیل یا تغییر استفاده کنند.
- این الگوریتمها در عین حال که برآورد میکنند کدام متغیرها در ردهبندی مهم هستند، انتخاب ویژگی را نیز به صورت ضمنی انجام میدهند.
مزایای الگوریتم جنگل تصادفی
- مشکل بیشبرازش در الگوریتمهای جنگل تصادفی، در مقایسه با درختهای تصمیم، کمتر به چشم میخورد؛ علاوه بر این، نیازی به هرس جنگل تصادفی نیز وجود ندارد.
- این الگوریتمها سرعت بالایی دارند (البته نه در همهی موارد). یک الگوریتم جنگل تصادفی میتواند روی یک ماشین 800 مگاهرتزی، با مجموعه دادهی متشکل از 100 متغیر و 5000 مورد (نمونه)، در هر 11 دقیقه، 100 درخت تصمیم تولید کند.
- جنگل تصادفی یکی از کارآمدترین و انعطافپذیرترین الگوریتمهای یادگیری ماشین است و میتواند در بازهی وسیع و متنوعی از مسائل ردهبندی و رگرسیون به کار رود؛ زیرا در برابر نویز مقاومت بالایی دارد.
- ساخت یک الگوریتم جنگل تصادفی بد چندان محتمل نیست. در پیادهسازی این الگوریتمها، تعیین اینکه از چه پارامترهایی استفاده شود آسان است؛ چون جنگل تصادفی نسبت به پارامترهای اجراشده در الگوریتم حساس نیست. به عبارتی، هرکسی میتواند بدون تنظیم زیاد، یک مدل خوب و قابل قبول بسازد.
- الگوریتمهای جنگل تصادفی را میتوان به صورت موازی توسعه داد.
- این الگوریتمها روی مجموعه دادگان بزرگ، عملکرد خوبی از خود نشان میدهند.
- دقت این الگوریتمها در مسائل ردهبندی بالاتر است.
معایب الگوریتم جنگل تصادفی
- الگوریتمهای جنگل تصادفی کاربرد آسانی دارند، اما تحلیل آنها به صورت نظری میتواند کار دشواری باشد.
- اگر یک جنگل تصادفی تعداد زیادی درخت تصمیم داشته باشد، در انجام پیشبینیهای فوری و لحظهای سرعت پایینی خواهد داشت.
- اگر دادهها از متغیرهای ردهای تشکیل شده باشند که تعداد سطوح (ردهها) در آنها متفاوت است، الگوریتم (به نفع ویژگیهایی که سطوح بیشتری دارند) سوگیری خواهد داشت؛ در نتیجه مقادیر اهمیت متغیرها قابل اتکا و معتبر نخواهد بود.
- وقتی از الگوریتم جنگل تصادفی برای مسائل رگرسیون استفاده میکنیم، نمیتوانیم پاسخی فراتر از مقادیر پاسخ موجود در مجموعه داده آموزشی را پیشبینی کنیم.
کاربردهای الگوریتم جنگل تصادفی
- بانکها از الگوریتمهای جنگل تصادفی استفاده میکنند تا پیشبینی کنند متقاضیان وام در دستهی افراد پرخطر قرار میگیرند یا خیر.
- این الگوریتمها در صنعت اتومبیلسازی برای پیشبینی شکست یا از کارافتادگی یک قطعهی مکانیکی به کار میروند.
- در حوزهی بهداشت و درمان نیز از الگوریتمهای جنگل تصادفی استفاده میشود تا پیشبینی شود آیا احتمال بروز یک بیماری مزمن در یک فرد وجود دارد یا خیر.
- جنگل تصادفی در مسائل رگرسیون کاربرد دارند؛ برای نمونه، تعداد میانگین به اشتراکگذاری یک محتوا در شبکههای اجتماعی یا میانگین نمرات عملکردی را پیشبینی میکنند.
- این الگوریتمها اخیراً برای پیشبینی الگوها در نرمافزارهای تشخیص گفتار و ردهبندی تصاویر و متون نیز به کار میروند.
کتابخانهی Python برای پیادهسازی الگوریتمهای جنگل تصادفی: Sci-Kit Learn
کتابخانهی R برای پیادهسازی الگوریتمهای جنگل تصادفی: randomForest

الگوریتم شبکههای عصبی مصنوعی
مغز انسان مانند یک کامپیوتر غیرخطی موازی و پیچیده است که میتواند اجزای تشکیلدهندهی ساختار (یعنی نورونهایی که به شکلی پیچیده با یکدیگر ارتباط دارند) را ساماندهی کند. برای درک بهتر، از یک نمونهی ساده در مورد شناسایی چهره استفاده میکنیم: وقتی یک نفر را ملاقات میکنیم، اگر فرد آشنا باشد میتوانیم به راحتی او را به همراه اسم، یا محل کارش یا براساس رابطهای که با او داریم به یاد بیاوریم. شاید هزاران نفر را بشناسیم؛ این مسئله نیازمند این است که مغز ما به سرعت فرد را شناسایی کند (شناسایی چهره).
حال تصور کنید به جای انسان، یک کامپیوتر بخواهد این کار را انجام دهد. این مسئله برای ماشینها کار آسانی نخواهد بود، چون افراد را نمیشناسند. باید به کامپیوتر تصاویری از افراد متفاوت را بیاموزید. اگر 10000 نفر را میشناسید، باید 10000 تصویر وارد کامپیوتر کنید. در این صورت هرگاه یک نفر را ببینید و تصویرش را به کامپیوتر بدهید، کامپیوتر آن تصویر را با همهی 10000 تصویر قبلی (که از پیش در دیتابیس وجود دارند) مطابقت میدهد.
بعد از تمام این محاسبات، فردی که بیشترین شباهت را با آن عکس دارد به شما ارائه میدهد. همین مسئله میتواند چندین ساعت طول بکشد (بسته به تعداد تصاویر موجود در دیتابیس). پیچیدگی این مسئله، با افزایش شمار تصاویر دیتابیس بیشتر میشود. از سوی دیگر، مغز انسان میتواند فوراً فرد را شناسایی کند.
حال سؤال اینجاست که آیا میتوانیم این کار را با یک کامپیوتر، به صورت فوری، انجام دهیم؟ آیا قابلیت محاسباتی مغز انسانها با کامپیوترها تفاوت دارد؟ اگر سرعت پردازش یک IC (مدار پردازشی) سیلیکونی را 10-9 (نانوثانیه) در نظر بگیریم، سرعت پردازش نورونها در انسان 6 بار کمتر از یک IC معمولی 10-9 (هزارم ثانیه) است. سؤالی که اینجا مطرح میشود این است که پس چطور سرعت پردازش مغز انسان از کامپیوتر بیشتر است؟
مغز انسان 10 میلیارد نورون دارد که حدود 60 تریلیون اتصال بین آنها وجود دارد؛ با این وجود سرعت پردازش آن بسیار بیشتر از سرعت یک کامپیوتر است. زیرا شبکهی نورونها در مغز انسان به شدت موازی است.
شاید از خود بپرسید آیا ممکن است ذات به شدت موازی مغز انسان را با استفاده از یک نرمافزار کامپیوتری شبیهسازی کرد؟ انجام چنین کاری آسان نخواهد بود؛ چون عملاً نمیتوان این تعداد واحد پردازشی را کنار یکدیگر قرار داد و آنها را به شیوهای به شدت موازی فعال کرد.
در عوض، کاری که میتوان انجام داد (که خود با محدودیتهایی روبروست) این است که شبکهای از پردازشگرها را به یکدیگر متصل کرد. در واقع به جای اینکه مغز انسان را به صورت یک کل در نظر بگیریم، یک بخش خیلی کوچک از آن را برای انجام یک مسئلهی خاص تقلید میکنیم. این امر با استفاده از شبکه های عصبی مصنوعی میسر میشود. منظور از مصنوعی این است که آنچه میسازیم از نورونهای واقعی بیولوژیک متفاوت است. شبکههای عصبی مصنوعی (ANN) را میتوان نسخههای شبیهسازی شده از مغز انسان در نظر گرفت که به آن صورتی که ما میخواهیم برنامهنویسی میشوند.
متخصصان علوم داده با تعریف قوانینی برای تقلید رفتار مغز انسان، میتوانند مسائلی از دنیای واقعی را حل کنند که تا قبل از این کسی به آنها فکر نمیکرد.
شبکههای عصبی مصنوعی چطور کار میکنند؟
تصور کنید در حال قدمزدن هستید و یک ستون میبینید (با این فرض که قبلاً هیچگاه ستون ندیدهاید) و به آن برخورد میکنید. از آن به بعد هرگاه ستون ببینید چندمتر قبلتر از آن تغییرجهت میدهید و از کنار آن میگذرید. این بار، شانهیتان به ستون میخورد و دوباره آسیب میبینید. حالا یک ستون دیگر میبینید و مراقب هستید تا به آن برخورد نکیند، اما این بار به یک صندوق پست میخورید (با این فرض که قبلاً هیچگاه صندوق پست ندیدهاید). فرآیند قبلی باز هم تکرار میشود.
شبکه عصبی مصنوعی نیز دقیقاً همینطور میآموزد؛ چند نمونه به آن میدهید و شبکه سعی میکند همان پاسخ را تولید کند. هربار شبکه اشتباه کند، یک خطا محاسبه میشود. بدین ترتیب دفعهی بعد که با یک نمونهی مشابه برخورد کند، مقدار تولیدشده در سیناپس (مقادیر ضریبداری که نورونها از طریق آنها در شبکه متصل میشوند) و نورون مربوطه رو به عقب انتشار مییابند (فرآیند پسانتشار).
پس میتوان گفت ANNها به نمونههای زیادی برای یادگیری نیاز دارند؛ این تعداد برای موارد کاربردی دنیای واقعی میتواند به چندین میلیون یا میلیارد هم برسد.
چرایی استفاده از شبکههای عصبی مصنوعی
- در ANNها، بین نورونهای غیرخطی، اتصالاتی وجود دارد، به همین دلیل، این الگوریتمها میتوانند به صورت توزیعشده، از خاصیت غیرخطی استفاده کنند.
- این الگوریتمها میتوانند پارامترهای آزاد را با تغییرات محیط اطراف سازگار کنند.
- الگوریتم ANN از اشتباهات خود میآموزد و طی فرآیند پسانتشار، تصمیمات بهتری میگیرد.
مزایای الگوریتم شبکهی عصبی مصنوعی
- درک این الگوریتمها برای متخصصانی که نمیخواهند خیلی وارد جنبهی ریاضیاتی پیچیدهی الگوریتم های یادگیری ماشینی شوند، آسان است. اگر قصد دارید مدلی به یک سازمان بفروشید، انتخاب واضح از بین ANNها و SVMها، گزینهی اول است. زیرا با تشبیه آنها به مغز انسان، به راحتی این الگوریتمها را توضیح دهید.
- مفهومسازی آنها کار راحتی است.
- ANNها میتوانند تعاملات احتمالی بین متغیرهای پیشبینی کننده را تشخیص دهند.
- این الگوریتمها میتوانند روابط غیرخطی پیچیده بین متغیرهای مستقل و وابسته را به شکل زیرکانهای تشخیص دهند.
- افزودن دانش پیشین به مدل کار نسبتاً آسانی است.
معایب الگوریتم شبکهی عصبی مصنوعی
- مهندسی معکوس این الگوریتمها کار بسیار دشواری است. اگر الگوریتم ANN بیاموزد تصویر سگ را یک گربه تشخیص دهد، تعیین چرایی آن کار خیلی دشواری خواهد بود. در این شرایط تنها کاری که میتوانید انجام دهید این است که به تغییر یا آموزش ANN ادامه دهید.
- الگوریتمهای ANN احتمالی نیستند؛ بدین معنی که خروجی این الگوریتم یک عدد پیوسته است و تبدیل آن به یک مقدار احتمال کار سختی است.
- این الگوریتمها را نمیتوان برای همهی مسائل به کار برد.
- شبکههای عصبی مصنوعی در پیادهسازیهای Native در حل مسئله عملکرد چندان موفقی ندارند. با این حال عملکرد آنها را میتوان با استفاده از تکنیکهای یادگیری عمیق بهبود بخشید.
- آموزش الگوریتمهای چندلایهای ANN آسان نیست و مستلزم تنظیم تعداد زیادی پارامتر است.
کاربردهای شبکهی عصبی مصنوعی
شبکههای عصبی مصنوعی از جذابترین الگوریتم های یادگیری ماشینی هستند که در حل مسائل ردهبندی برای تشخیص الگو به کار میروند. این الگوریتمها در زمینهی پژوهشی کاربرد فراوانی دارند، علاوه بر آن به این موارد نیز میتوان اشاره کرد:
- مؤسسات مالی از ANNها برای ارتقای عملکرد سیستمهای خود در ارزیابی متقاضیان وام، رتبهبندی اوراق قرضه، بازاریابی هدف و رتبهبندی اعتبار استفاده میکنند. این الگوریتمها برای تشخیص نمونههای کلاهبرداری در معاملات کارتهای اعتباری نیز به کار میروند.
- وبسایت Buzzfeed از الگوریتمهای ANN در مسئلهی تشخیص تصویر برای ساماندهی تصاویر و ویدئوها و جستجو میان آنها استفاده میکند.
- بسیاری از بمبیابها (تشخیصگران بمب) فرودگاههای ایالات متحده با استفاده از ANNها مؤلفههای ردیابی هوایی را تجزیه و تحلیل کرده و بدین طریق وجود یا عدم وجود مواد شیمیایی انفجاری را تشخیص میدهند.
- گوگل برای مسائل تشخیص گفتار، تشخیص تصویر و تشخیص الگو (در تشخیص دستخط) از ANNها استفاده میکند. این الگوریتمها در گوگل برای تشخیص ایمیلهای ناشناس و بسیاری موارد دیگر نیز کاربرد دارند.
- شبکههای عصبی مصنوعی کاربردهای مهمی در کارخانههای رباتیک دارند و برای سازگاری تنظیمات دما، کنترل ماشینآلات و تشخیص کژکارکردیها به کار میروند.
الگوریتم K نزدیکترین همسایه
K نزدیکترین همسایه یا KNN سادهترین الگوریتم ردهبندی است. از این الگوریتم، همچون الگوریتم رگرسیون، برای پیشبینی مقادیر پیوسته نیز استفاده میشود. در KNNها از معیارهای فاصلهمحور Distance-based measures برای دستیابی به بهترین (نزدیکترین) پیشبینی استفاده میشود. مقدار پیشبینیشدهی نهایی بر اساس k همسایه انتخاب میشود. معیارهای اقلیدسی، منتهن Manhattan ، مینکوفسکی و همینگ از جمله معیارهای فاصله هستند؛ از این معیارها، سه مورد اول توابع پیوسته هستند، اما فاصلهی همینگ برای متغیرهای ردهای به کار میرود. انتخاب مقدار k مهمترین مسئله در استفاده از این الگوریتم است. الگوریتم KNN را به عنوان الگوریتم کند Lazy algorithm هم میشناسند.
همانطور که در تصویر بالا مشاهده میکنید، فواصل نقطهی جدید از هرکدام از کلاسها مشخص شده است. هرچه این فاصله کمتر باشد، نقطهی جدید به آن کلاس (کلاس نزدیکتر) اختصاص داده میشود.

مزایای الگوریتم K نزدیکترین همسایه
- این الگوریتمها دقت بالایی دارند؛ با این حال الگوریتمهای قویتری هم وجود دارند.
- KNNها در کار با دادههای غیرخطی بسیار مفید هستند؛ زیرا هیچ مفروضهای ندارند.
معایب الگوریتم K نزدیکترین همسایه
- الگوریتمهای KNN محاسبهبر بوده و نیاز به حافظهی زیادی دارند.
- این الگوریتمها به مقیاس دادهها حساس هستند.
الگوریتم تقویت گرادیان
رده بند تقویت گرادیان از روش ارتقاء استفاده میکند؛ این روش وامگرفته از روش درخت تصمیم است. یادگیرندههای ضعیف موجود بعد از دریافت وزن بیشتر، به درخت بعدی منتقل میشوند تا پیشبینیهای هر درخت از درخت قبلی بهتر باشد. خروجی، میانگین پیشبینیهای نهایی است. الگوریتم تقویت گرادیان زمانی که دادههای زیاد با پیشبینیهای بالا داریم، مورد استفاده قرار میگیرند.
XGBoost
XGBoost یک پیادهسازی پیشرفته از الگوریتمهای تقویت گرادیان است. این الگوریتم از نظر محاسبات با تقویت گرادیان تفاوت دارد. زیرا تکنیک نرمالسازی Regularization technique را به صورت داخلی اجرا میکند. به بیان ساده، XGBoost به تکنیک تقویت منظم اشاره دارد.
مزایای الگوریتم XGBoost
- سرعت آن از الگوریتم تقویت گرادیان بسیار بیشتر است.
- این الگوریتم کاربران را قادر میسازد اهداف بهینهسازی و معیارهای ارزیابی را سفارشی کنند.
- تکنیکهایی دارد که برای مدیریت مقادیر گمشده مناسب هستند
معایب
- تفسیر الگوریتم XGBoost کار دشواری است.
- احتمال بیشبرازش در این الگوریتم وجود دارد.
- تنظیم این الگوریتم نسبت به الگوریتمهای تقویت گرادیان سختتر است.
Light GBM
LightGBM یک چارچوب تقویت گرادیان است که از الگوریتمهای درخت تصمیم استفاده میکند. همانطور که از نام این رویکرد مشخص است، سرعت آموزش آن بسیار بالاست. علاوه بر این، قابلیت استفاده روی مجموعه دادگان آموزشی بزرگ را نیز دارد.
مزایای LightGBM
- سرعت آموزش و میزان دقت این الگوریتم بالاست.
- حافظهی کمتری را اشغال میکند.
- امکان پشتیبانی موازی GPU را فراهم میکند.
- کارآیی و عملکرد بهتری دارد.
معایب LightGBM
- پایگاه کاربر User base محدودی دارد.





