

تشخیص اشیاء با استفاده از الگوریتم DETR فیسبوک
 تیم تحریریه
تیم تحریریه- ۲۳ شهریور ۱۴۰۰
پیش از این سعی کردیم افراد حاضر در تصاویر بیکیفیتی که از اینترنت گرفته شدهاند را تشخیص دهیم. برای این کار از سیستم محبوب تشخیص اشیاء YOLO استفاده کردیم. این بار قصد داریم الگوریتم DETR را بررسی کنیم. هدف ما تشخیص افراد در تصاویر خام ویدئویی بود. ولی همانطور که در نمونه پایین مشاهده میکنید، به خاطر کیفیت پایین تصویر قادر به تشخیص همه افراد نبودیم.

اخیراً به مقالهای جالب از طرف تیم تحقیقاتی فیسبوک برخوردم. گروه فیسبوک، الگوریتم DETR یا ترنسفرمر تشخیص Detection TRansformer را در دسترس عموم قرار داده است. DETR یک الگوریتم تشخیص اشیاء است که قابلیت استفاده در کتابخانه پای تورچ را نیز دارد.
در این نوشتار سعی داریم عملکرد DETR را روی چند تصویر باکیفیت و بیکیفیت امتحان کنیم.
مقدمهای بر DETR
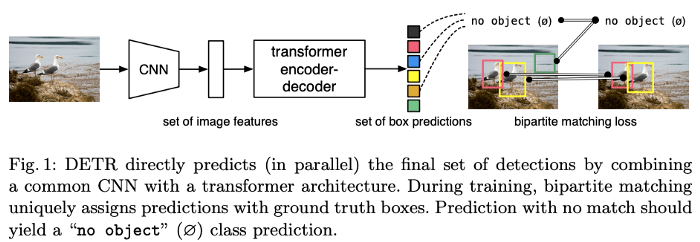
DETR میتواند (به صورت موازی) با ترکیب یک شبکه عصبی پیچشی (CNN) متداول با یک معماری ترنسفرمر، مجموعه نهایی تشخیصها را پیشبینی کند. طی مرحله آموزش، فرآیند تطبیق دوبخشی پیشبینیها را منحصراً به کادرهای محصورکننده حقیقت پایه اختصاص میدهد. آن پیشبینیهایی که با هیچ کادری از حقیقت پایه جفت نمیشوند، در کلاس “بدون شیء” یا تهی (Ø) قرار میگیرند.
DETR میتواند 91 کلاس را، از انسان گرفته تا مسواک، تشخیص دهد. اجازه دهید قدرت DETR را در یک تصویر به عنوان نمونه نشان دهیم. بدین منظور این گامها را روی GPU (واحد پردازش گرافیکی) انجام میدهیم:
- مدل DETR را نمونهسازی و وارد GPU میکنیم.
- طبقاتی که DETR میتواند تشخیص دهد را تعریف میکنیم.
- تصویر را بارگزاری کرده و آن را نرمالسازی میکنیم. در این مرحله باید به این مسئله دقت کنیم که تصویر فرمت RGB داشته باشد (600×800).
- به کمک سامانه Cuda تصویر را وارد GPU میکنیم.
- تصویر خود را وارد مدل کرده و این پیشبینیها را دریافت میکنیم:
i: کادرهای محصورکننده اطراف اشیایی که تشخیص داده شدهاند؛
ii: احتمالات مربوط به پیشبینی برای هرکدام از 100 تصویر مشخص شده.
برای مورد ii، برای هر کدام از تصاویر تشخیص داده شده یک توزیع از مقادیر مربوط به هر کلاس در دست داریم. بعد از نرمالسازی آن با (برای نمونه) یک تابع بیشینههموار softmax، برای هر تصویر یک بردار اندازه (1, N_CLASSESکه در آن N_CLASSES = 91) و احتمالات را به دست میآوریم. شکل خروجی: (100,91).
- سپس عملیات argmax را برروی هر ردیف از خروجیهای قبلی اجرا میکنیم تا شاخص مربوط به کلاس را به دست بیاوریم که احتمال جدا کردن شیء را از طبقات دیگر به حداکثر میرساند. توجه داشته باشید اگر قرار است فقط به استفاده از argmax توجه داشته باشیم، نیازی نخواهد بود که از قبل با استفاده از تابع بیشینههموار نرمالسازی انجام دهیم (argmax شاخص احتمال بیشینه در بردار احتمالات همه طبقات است). شکل خروجی: (100,1).
- حالا که کلاس پیشبینی شده برای هر شیء تشخیص داده شده را داریم، میتوانیم بر روی تصویر، کادر محصورکننده رسم کنیم تا شیء و کلاس مربوط به آن مشخص شوند. مختصات این کادر یکی از خروجیهای DETR در گام پنج است.
طراحان DETR یک co-lab را فراهم آوردهاند تا نشان دهند استفاده از آن چقدر آسان است. آنها بیان میکنند:«DETR با استفاده از نرمالسازی استاندارد ImageNet، کادرهای محصورکنندهای تولید میکند که مختصات تقریبی آنها به فرمت [w,h,مرکزy,مرکزx] مشخص میشود ( [مرکزy,مرکزx] مختصات مرکز کادر، w عرض و h ارتفاع آن هستند). از آنجایی که مختصات به ابعاد تصویر بستگی داشته و مقادیر بین 0 تا 1 را به خود میگیرد، پیشبینیها را به مختصات دقیق تصویر تبدیل کرده و آن را به منظور تصویریسازی، وارد فرمت [x0,y0,x1,y1] میکنیم.»
عملکرد DETR برروی تصاویر با کیفیت و بیکیفیت
ما از منبع کدی که در co-lab قرار داده شده استفاده کردیم تا بتوانیم همه عملیات را برروی GPU انجام دهیم. این قسمت از نوشتار را با تجزیه و تحلیل خروجی DETR از یک تصویر باکیفیت شروع میکنیم.

با پیادهسازی گامهای 1 تا 7 که بالاتر توضیح دادیم، میتوانیم با استفاده از DETR در چنین تصویری به تشخیص اشیاء بپردازیم.

بالای کادرهای مستطیلشکلی که میبینید، میزان احتمال شیء مشخصشده درج شده است. هرچقدر این احتمال به 1 نزدیکتر باشد، میتوانیم اطمینان بیشتری به صحت پیشبینی مدل داشته باشیم.
حال میتوانیم بسته به هدفمان اشیاء را فیلتر (جدا) کنیم. برای مثال هدف ما اینجا تشخیص افراد است. بنابراین علاوه بر اجرای قدمهای 1 تا 7، باید تنها کادرهایی را رسم کنیم که عنوان مربوط به آنها «فرد» است.

حالا میخواهیم عملکرد DETR را برروی فریمی گرفتهشده از تصاویر ویدئویی خامی بررسی کنیم که بیکیفیت هستند. برای این قسمت از نمونه تصاویری استفاده میکنیم که از دوربینی در گوتنبرگ سوئد گرفته شده است. در نمونه اول 17 فرد دیده میشوند (توسط انسان).
همانطور که در شکل پایین مشاهده میکنید، میتوان افراد را به صورت دستی تشخیص داد. اما این کار در عمل زحمت و وقت زیادی خواهد برد. به همین دلیل از ابزاری همچون DETR استفاده میکنیم که در تشخیص اتوماتیک افراد مفید واقع میشود.

در این تصویر 17 نفر دیده میشوند.
میخواهیم بدانیم مدل ما میتواند چند نفر را با درصد اطمینان قابل قبولی پیشبینی کند. میتوان این سطح اطمینان را به عنوان یک هایپرپارامتر قابل تغییر در نظر گرفت. در تصویر پایین دو خروجی از DETR را نشان میدهیم؛ سطح اطمینان در اولی 70% در نظر گرفته شده است.
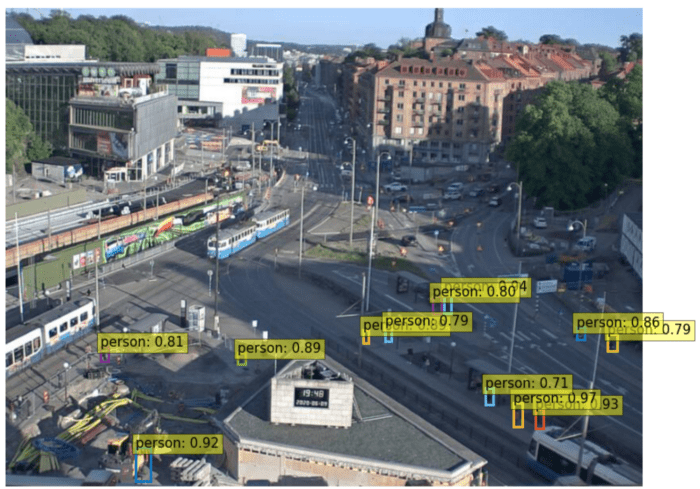
در این خروجی مدل توانسته است 12 نفر را تشخیص دهد (با حداقل سطح اطمینان 70%)
سطح اطمینان برای دومین خروجی پایینتر آمده و روی 10% تنظیم شده است. در این مورد، مدل از پیشبینیهای خود اصلاً اطمینان ندارد زیرا حداقل احتمال پیشبینی 0.10 است.
تا اینجا دریافتیم که سطح اطمینان یا احتمال کلاس پیشبینی شده برای یک شیء، هایپرپارامتری کلیدی است. برخی از افرادی که در خروجی اول تشخیص داده نشدند، با احتمال پایینتر از 0.70 توسط DETR تشخیص داده شدهاند. برای روشنسازی این مطلب اجازه دهید در همین تصویر سطح اطمینان را از 0.70 به 0.60 تغییر دهیم.

در این خروجی مدل توانست 18 نفر را تشخیص دهد (با حداقل سطح اطمینان 60%).
با این درصد اطمینان هنوز هم شاهد عدم تطابقهایی در پیشبینیها هستیم. دور اشیاء (در اینجا افرادی) که مدل با سطح اطمینان بالاتر از 60% نتوانسته تشخیص دهد را دایره و روی مثبتهای کاذب False positve (اشیائی که مدل تشخیص داده اما فرد نیستند) خط قرمز میکشیم.
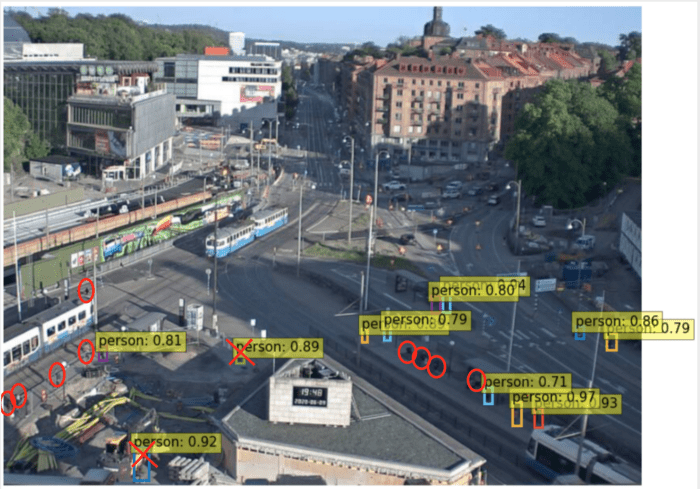
در این تصویر مدل توانسته است 12 نفر را تشخیص دهد (با حداقل سطح اطمینان 70%). سپس به صورت دستی دور افرادی که تشخیص داده شدهاند دایره و روی مثبتهای کاذب خط قرمز کشیدیم.
مقایسه بین YOLO و DETR به زبان ساده
همانطور که در قسمت مقدمه گفتیم، پیش از این با سیستم YOLO کار کردیم تا افراد را در فریمهای مختلف گرفته شده از تصاویر ویدئویی خام تشخیص دهیم. همانطور که دیدیم، مدل نتوانست افرادی را که تشخیصشان کار دشواری نبود، شناسایی کند. میتوانیم از این مثال در مقایسه بین YOLO و DETR استفاده کنیم. برای انجام این مقایسه دو فریم را که به صورت تصادفی از تصاویر ویدئویی گرفته شدهاند به کار میبریم.
این بار میخواهیم اجرای YOLO در پای تورچ را به کار ببریم. بدین منظور از سیستم تشخیص اشیا که پیشنهاد کردهاند در یک مسئله تشخیص شیء عمومی (بدون جدا کردن کلاس «انسان») استفاده خواهیم کرد.
همان گامهای 1 تا 7 را که در قسمت معرفی DETR بیان شد اجرا میکنیم.
ابتدا فریمها (گرفته شده از ویدئویی در استکهلم سوئد) را بازیابی مینماییم. تصویر پایین یک تصویر بیکیفیت است که تشخیص افراد در آن حتی برای انسانها هم دشوار است.

سپس با استفاده از YOLO شروع به تشخیص اشیاء موجود در تصویر مینماییم. جالب بود که این الگوریتم نتوانست هیچ فردی را تشخیص دهد.

حال بیاییم با استفاده از DETR به تشخیص افراد بپردازیم. همانطور که در تصویر پایین مشاهده میکنید، این بار افراد به آسانی و با حداقل سطح اطمینان 0.70 تشخیص داده شدند.

اکنون همین کار را بر روی فریم دیگری امتحان میکنیم.

در این تجربه نسخه چهارم الگوریتم YOLO توانست یک فرد را با سطح اطمینان 0.32 تشخیص دهد. از اینکه چرا هیچ شیء دیگری در این فریم تشخیص داده نشده چیزی نمیدانیم. همانطور که میبینید همین یک مورد هم اشتباه تشخیص داده شده است. بر همین اساس باید از یک معماری دیگر با پارامترهای وزنی متفاوت استفاده کنیم. (شاید در یکی از مقالههای آینده پارامترهای لازم برای چنین وظیفهای را مورد مطالعه قرار دهیم).

از سوی دیگر DETR عملکرد خوبی در مسئله تشخیص فرد از خود نشان داد؛ نتیجه را در تصویر پایین مشاهده میکنید.

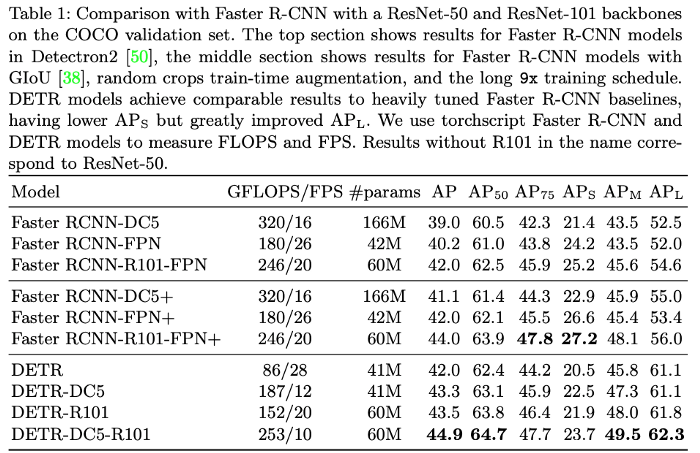
بدیهی است این طرح آزمایشی از دقت کافی برخوردار نیست. به منظور مقایسه این دو معماری (YOLO و DETR) باید دیتاست بزرگتری از تصاویر برچسبدار داشته باشیم. پژوهشگران تیم تحقیقاتی فیسبوک تجزیه و تحلیل بسیار دقیقتر و کاملتری را انجام دادهاند؛ در این قسمت جدولی از مقاله منتشر شده توسط این تیم را مشاهده میکنید که شبکههای Faster R-CNN، ResNet-50 و ResNet-101 را مقایسه کرده است.
تشخیص اشیاء پیوسته با استفاده از ترنسفرمرها
جدول بالا عملکرد ستون مهره معماریهای Faster R-CNN، ResNet-50 و ResNet-101 را روی مجموعه اعتبارسنجی COCO مقایسه میکند. قسمت بالایی جدول عملکرد مدلهای Faster R-CNN را در کتابخانه Detectron2 نشان میدهد؛ بخش دوم جدول عملکرد Faster R-CNN را با اصل GIoU (38)، تکنیک دادهافزایی Random Crops و مدت زمان آموزش 9 برابری، نشان میدهد. مدلهای DETR در مقایسه با مدلهای faster R-CNN که به عنوان خط پایه در نظر گرفته شدهاند، عملکرد خوبی از خود نشان دادند. به بیان دقیقتر، این مدلها در عین داشتن AP_sپایینتر، AP_L را به شدت تقویت کردهاند. به منظور اندازهگیری معیارهای FLOPS و FPS مدلهای Faster R-CNN و DETR از روش Torchscript استفاده میکنیم. نتایجی که در اسمشان R101 وجود ندارد، مربوط به ResNet-50 هستند.
نتیجهگیری
در این مطلب به معرفی مختصر DETR پرداختیم که یک الگوریتم تشخیصگر افراد با قابلیت کاربرد بسیار آسان است. سپس عملکرد آن را بر روی تصاویر باکیفیت و بیکیفیت مشاهده کردیم. در آخر نیز DETR را با الگوریتم محبوب دیگری به نام YOLO مقایسه نمودیم.





