

نسخه چهارم الگوریتم YOLO: دقت و سرعت بهینه در تشخیص اشیاء
 تیم تحریریه
تیم تحریریه- ۶ شهریور ۱۴۰۰
الگوریتم تنها یکبار نگاه کن یا YOLO You only look once یکی از زیرمجموعههای الگوریتمهای یک مرحلهای تشخیص اشیاء object detector است که سرعت و دقت بالایی دارد. اخیراً با انتشار مقالهای نسخه چهارم الگوریتم YOLO معرفی شد. این نسخه جدید در مقایسه با سایر الگوریتمهای تشخیص اشیاء عملکرد بسیار خوبی از خود نشان داده است.
امروزه برای اینکه بتوان مدلهای نوین و دقیق را به کمک حجم زیادی از بستههای دادهای کوچک mini-batch آموزش داد، به تعداد زیادی GPU نیاز است. اگر برای آموزش مدل تنها از یک GPU استفاده کنیم، فرآیند یادگیری کند و حتی غیرممکن میشود. اما نسخه چهارم الگوریتم YOLO با ارائه الگوریتم تشخیص اشیاء که میتواند تنها با استفاده از یک GPU و تعداد کمتری بسته دادهای آموزش ببیند، این مشکل را حل کرد. بدینترتیب، هماکنون میتوان تنها با استفاده یک GPU برای مثال مدل 1080 Ti یا 2080 Ti با سرعت و دقتی بسیار بالا یک الگوریتم تشخیص اشیاء را آموزش داد.
نسخه چهارم YOLO توانست روی دادههای دیتاست MS COCO با متوسط دقت 43.5% و با سرعت 65 فریم در ثانیه روی GPU مدل Tesla V100 به نتایج چشمگیری دست پیدا کند. برای کسب این نتایج ویژگیهای مختلف از جمله اتصالات باقیماندههای وزنی (WRC)Weighted-Residual-Connections، اتصالات بخشی میان مرحلهای (CSP) Cross-Stage-Partial-connections، نرمالسازی متقابل بستههای دادهای کوچک (CmBN) Cross mini-Batch Normalization و خودآموزی خصمانه (SAT) Self-adversarial-training را با تابع فعالسازی Mish Mish-activation، روشهای موزاییکی دادهافزایی، متد متعادلساز DropBlock
DropBlock regularization و تابع زیان CIoU CIoU loss ترکیب شدند. این ویژگیها، ویژگیهای کاملی هستند، زیرا بدون وجود مدلها، دیتاستها و مسائل بینایی رایانهای نیز به درستی کار میکنند. در ادامه این مقاله بیشتر به این ویژگیها خواهیم پرداخت.

نکته: مدلهایی که در منطقه آبی روشن قرار میگیرند، مدلهای تشخیص اشیاء همزمان هستند (30+ فریم در ثانیه).
در این تصویر میبینیم که مدل EfficientDet D4-D3 متوسط دقت بالاتری درمقایسه با نسخه چهارم YOLO دارد، اما سرعت اجرای این مدلها روی GPU مدل V100 کمتر از 30 فریم در ثانیه است. درحالیکه، YOLO با سرعتی بسیار بالاتر (بیشتر از 60 فریم بر ثانیه) و دقتی قابلقبول اجرا میشود.
معماری عمومی یک الگوریتم تشخیص شیء
الگوریتم YOLO یک الگوریتم تشخیص شیء یک مرحلهای است، اما الگوریتمهای تشخصی شیء دو مرحلهای نیز وجود دارند که از جمله آنها میتوان R-CNN ،R-CNN سریع و R-CNN سریعتر را نام برد. این الگوریتمها بسیار دقیق، اما کند هستند. در ادامه به مؤلفههای اصلی یک الگوریتم تشخیص شیء نوین و یک مرحلهای نگاهی خواهیم انداخت.

ستون فقرات
مدلهای از قبیل ResNet، DenseNet ،VGG و غیره به عنوان استخراجکننده ویژگی مورداستفاده قرار میگیرند. این مدلها از قبل توسط دیتاستهای طبقهبندی تصویر همچون ImageNet آموزش داده شدهاند و به خوبی با دیتاست مورد استفاده در فرآیند تشخیص هماهنگ میشوند. این شبکهها به تدریج و با عمیقتر شدن شبکه (افزایش تعداد لایهها)، سطوح مختلفی از ویژگیها را تولید میکنند که معنای بیشتر دارند و در بخشهای بعدی شبکه تشخیص اشیاء استفاده میشوند.
گردن
لایههای این بخش بین ستون فقرات و سر قرار دارند و برای استخراج نگاشتهای ویژگی در مراحل مختلف ستون فقرات استفاده میشوند. گردن معماری عمومی این الگوریتم میتواند از یک شبکه هرم ویژگی (FPN)، یک شبکه متراکمسازی مسیر (PANet) یا یک شبکه دوطرفه هرم ویژگی (Bi-FPN) تشکیل شده باشد. برای مثال، نسخه سوم الگوریتم YOLO برای استخراج ویژگیها در مراحل مختلف ستون فقرات از FPN استفاده میکند.
شبکه هرم ویژگی (FPN) چه کاری انجام میدهد؟
این شبکه با ترکیب یک شبکه پیچشی استاندارد با یک مسیر بالابهپایین و ایجاد اتصالات افقی، از یک تصویر ورودی که واضح و باکیفیت باشد، یک هرم ویژگی غنی و چند مقیاسی میسازد.

اتصالات افقی نگاشتهای ویژگی مسیر پایینبهبالا را با مسیر بالایهپایین ادغام میکنند و بدین ترتیب، سطوح مختلف هرم را شکل میدهند. پیش از ادغام نگاشتهای ویژگی جدید، نمونههای سطح قبلی هرم در FPN با ضرب شدن در عامل 2x افزایش پیدا میکنند تا سایز فضایی همه سطوح یکسان شود. سپس شبکههای طبقهبندی و رگرسیون (که در بخش سر قرار دارند) به هر یک از سطوح هرم اعمال میشوند تا شیء مدنظر در سایزهای مختلف قابل شناسایی باشد.
شبکههای هرم ویژگی را میتوان به انواع ستون فقرات اعمال کرد. برای مثال، در مقاله اصلی FPN از ResNet استفاده شده است.

4 نوع از هرمهای ویژگی.
در قسمت (د) از ماژول SFAM استفاده شده است.
همچنین، ماژولهایی چون SFAM ،ASFF و Bi-FPN میتوانند FPN را تکمیل کنند.
تصویر (الف) نحوه استخراج ویژگیها از ستون فقرات را در معماری تشخیص تک مرحلهای (SSD) نشان میدهد. علاوه بر این، در تصویر بالا سه نوع دیگر شبکههای هرمی را نیز ملاحظه میفرمایید، اما ایده اصلی پشت همه این شبکهها یکسان است و همگی در رفع مشکلاتی که در اثر تفاوت در مقیاس نمونههای اشیاء پیش میآید، به ما کمک میکنند.
ASFF و Bi-FPN نیز شبکههای جالبتوجهی هستند و نتایج قابلتوجهی ارائه دادهاند، اما در اینجا به آنها نمیپردازیم.
سر
این بخش خود یک شبکه است؛ شبکهای که مسئولیت تشخیص و دنبال کردن (طبقهبندی و رگرسیون) کادرهای محصورکننده را برعهده دارد. هر یک از خروجیهای این بخش ممکن است به این صورت باشند (بسته به نحوه اجرا): 4 مقدار (x و y و h و w) که تعیینکننده ابعاد کادر پیشبینیشده هستند و احتمالهای k کلاسه بهعلاوه 1 (این عدد 1 با k جمع میشود تا پیشزمینه نیز درنظر قرار گیرد). در الگوریتمهای تشخیص اشیاء که از کادرهای محصورکننده از پیش تعیینشده Objected detectors anchor-based استفاده میکنند، از جمله الگوریتم YOLO، بخش سر روی تمام کادرهای از پیش تعیینشده اعمال میشود. از دیگر شناساگرهای یکمرحلهای محبوب که از کادرهای محصورکننده از پیش تعیینشده نیز استفاده میکنند، میتوان الگوریتم تشخیص تک مرحلهای Single Shot Detector و RetinaNet را نام برد.

در تصویر زیر میتوانید 3 ماژولی که پیشتر به آنها پرداختیم را ملاحظه نمایید.
[irp posts=”14835″]متدهای BoF و BoS
نویسندگان مقاله نسخه چهارم YOLO دو گروه متد برای افزایش دقت الگوریتمهای تشخیص اشیاء تعریف کردهاند. آنها متدهای هر دو گروه را تجزیه و تحلیل کردند تا بتوانند به شبکه عصبی سریع و با دقت بالا دست یابند. این دو گروه عبارتند از:
-
BoF
این گروه شامل متدهایی است که دقت الگوریتم تشخیص اشیاء را افزایش میدهند، بدون آنکه هزینه استنتاج بالا برود. این متدها تنها روی استراتژی یا هزینه آموزش الگوریتم تأثیر میگذارند.
به عنوان یک مثال از متدهای گروه BoF میتوان داده افزایی data augmentation را نام برد که تعمیمپذیری مدل را افزایش میدهد. برای این کار میتوانیم در مشخصات عکس از جمله روشنایی، اشباع رنگ، کنتراست و نویز تغییر ایجاد کنیم یا در مشخصههای هندسی تصویر اختلال ایجاد کنیم، مثل چرخاندن تصویر، جدا کردن و غیره. این تکنیکها مثالهای خوبی از BoF هستند که میتوانند دقت الگوریتم را بالا ببرند.

نکته: وقتی از این روش در ردیابی اشیاء استفاده میکنیم، تغییرات و اختلالات اعمالشده باید در مشخصات کادرهای محصورکننده نیز اعمال شوند.
تکنیکهای جالب دیگری نیز برای افزایش حجم دادههای تصویری وجود دارد که ازجمله آنها میتوان به روش CutOut اشاره کرد. در این روش طی فرآیند آموزش قسمتهای مربعی شکل از تصویر به صورت اتفاقی بوشانده میشود. این تکنیک اثبات کرده که میتواند توانایی و عملکرد شبکههای عصبی پیچشی را بهبود بخشد. تکنیک Random Erasing نیز قسمتهایی مستطیل شکل از یک تصویر را انتخاب کرده و پیکسلهای موجود در آن منطقه را پاک میکند.

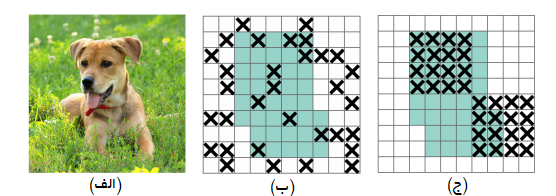
نوع دیگری از تکنیکهایی که در گروه BoF قرار دارند، تکنیکهای متعادلساز هستند که بهمنظور جلوگیری از بیشبرازشمورد استفاده قرار میگیرند. از جمله این تکنیکها میتوان DropOut ،DropConnect و DropBlock را نام برد. تکنیک DropBlock عملکرد بسیار خوبی در شبکههای عصبی پیچشی از خود نشان داده و در ستون فقرات نسخه چهارم الگوریتم YOLO نیز بهکار گرفته شده است.
قراردادن توابع فعالسازی در نقاط تصادفی همچون تصویر (ب) برای برداشتن اطلاعات معنایی رویکرد خوبی نیست، زیرا اطلاعات توابع فعالسازی که در نزدیکی یکدیگر قرار گرفتهاند شباهت زیادی با یکدیگر دارند. درعوض، وقتی توابع فعالسازی بهصورت پیوسته درکنار یکدیگر قرار میگیرند، میتوانند اطلاعات معنایی را بردارند و یادگیری دیگر ویژگیها (بهمنظور طبقهبندی تصویر ورودی) را نیز برای سایر واحدها را تسهیل کنند.
تابع هزینه شبکه رگرسیون نیز به این مجموعه اضافه میشود. بهطور معمول به کمک تابع میانگین مربعات خطا، مختصات نقاط رگرس میشوند.

درمقاله مربوطه گفته شده که این تابع هر نقطه را یک متغیر مستقل درنظر میگیرد، اما تمامیت شیء را درنظر نمیگیرد. برای حل این مشکل، تابع زیان IoU معرفی شد. این تابع منطقهای که کادر محصورکننده پیشبینیشده و حقیقی احاطه خواهند کرد را مدنظر قرار میدهد. این ایده با بهکارگیری تابع زیان GIoU بهبود پیدا کرد. در این تابع علاوهبر منقطهای که توسط شیء اشغال شده، شکل و جهت آن نیز درنظر گرفته میشود. از سوی دیگر، تابع زیان CIoU نیز معرفی شد تا علاوهبر موارد قبلی مناطق مشترک، فاصله میان نقاط مرکزی کادرها و نسبت ابعاد نیز درنظر گرفته شوند. نسخه چهارم YOLO از تابع زیان CIoU برای رسم کادرهای محصورکننده استفاده میکند، زیرا با استفاده از آن سرعت همگرایی افزایش یافته و عملکرد بهتری را شاهد خواهیم بود.
نکته: یک مسئله در اینجا ممکن است باعث سردرگمی شما شود، اما باید بدانید با اینکه بسیاری از مدلها از تابع میانگین مربعات خطا استفاده میکنند، اما تابع IoU را نیز بهکارمیگیرند، البته نه در نقش تابع زیان بلکه به عنوان یک معیار.
تصویر زیر عملکرد انواع مختلف تابع زیانIoU را در یک مدل نشان میدهد.

همانطور که ملاحظه میفرمایید عملکرد CIoU بهتر از GIoU است. مدل شناساگر در این مثال «R-CNN سریعتر» بوده که توسط دیتاست MS COCO آموزش دیده و در آن از توابع زیان GIoU و CIoU استفاده شده است.
-
BoS
این گروه شامل ماژولهای افزونه plugin modules و متدهای پساپردازشی post-processing methods است که دقت الگوریتم تشخیص شیء را به میزان قابل توجهی افزایش میدهند، اما هزینه استنتاج را نیز اندکی بالا میبرند.
مطابق آنچه در مقاله مربوطه گفته شده، این ماژولها یا متدها بهطور معمول شامل تعریف سازوکارهای توجه (ماژولهای توجه فشار و تحریک و فضایی)، افزایش سایز برد پذیرش مدل و تقویت قابلیت یکپارچگی ویژگی هستند.
ماژولهایی که برای گسترش برد پذیرنده مدل استفاده میشوند عبارتند از: SPP ،ASPP و RFB (در نسخه چهار الگوریتم YOLO از ماژول SPP استفاده شده است).
علاوه براین، ماژولهای توجه در شبکههای عصبی پیچشی به دو دسته توجه متکی بر کانال (فشار و تحریک (SE)) و توجه متکی بر فضا (ماژول توجه فضایی (SAM)) تقسیم میشوند. دلیل اینکه گاهی ماژولهای دسته دوم به دسته اول ارجحیت پیدا میکنند این است که SE سرعت استنتاج GPU را تا 10% افزایش میدهد که برای ما مطلوب نیست. نسخه چهارم YOLO ماژول SAM را بهکار گرفته است، اما نه ماژولی که در مقاله اصلی معرفی شده است. تصویر زیر را درنظر بگیرید:

نسخه اصلی این ماژول با درنظر گرفتن یک نگاشت ویژگی به نام ، در طول محور کانال عملیات میانگین تجمیع و حداکثر تجمیع را انجام میدهد و سپس آنها را با یکدیگر تلفیق میکند. سپس یک لایه پیچشی (همراه با تابع تحریک سیگموید به عنوان تابع فعالسازی) به آن اعمال میشود تا یک نگاشت توجه ( ) ایجاد شود. این نگاشت توجه سپس به افزوده میشود.
از طرف دیگر، نوع اصلاحشده ماژول SAM بهکاررفته در نسخه چهارم YOLO، لایههای حداکثر تجمیع و میانگین تجمیع را ندارد و بهجای آن، از یک لایه پیچشی (و تابع تحریک سیگموئید) عبور میکند که نگاشت ویژگی اصلی را تکثیر میکند.
هرمهای ویژگی از قبیل SFAM، ASFF و Bi-FPN که پیشتر درخصوص آنها صحبت کردیم نیز همچون توابع فعالسازی در گروه BoS قرار میگیرند. از زمانیکه ReLU معرفی شد، انواع گوناگونی از آن مثل LReLU ،PReLU و ReLU6 نیز ارائه شد. توابع فعالسازی همچون ReLU6 و hard-Swish بهطور تخصصی برای شبکههای کوانتیزهشده طراحی شدهاند. این توابع برای استنتاچ نهایی در دستگاهها تعبیهشده مثل Google Coral Edge TPU استفاده میشوند.

از طرف دیگر، در ستون فقرات نسخه چهارم YOLO تعداد زیادی تابع فعالسازی Mish بهکار گرفته شده است. نمودار زیر را ملاحظه بفرمایید:


این تابع فعالسازی نتایج نویدبخشی داشت. برای مثال، با بهکارگیری شبکه فشار و تحریک به همراه تابع Mish (روی دیتاست CIFAR-100) بهجای توابع Swish و ReLU، دقت آزمون Top-1 به ترتیب به مقدار 0.494% و 1.671% افزایش پیدا کرد.
میتوانید در این لینک نمودار سایر توابع فعالسازی را نیز مشاهده نمایید.
طراحی نسخه چهارم الگوریتم YOLO
تا به اینجا درخصوص بخشهای مختلف الگوریتم تشخیص اشیاء و متدهایی که برای افزایش دقت مدل بهکار میروند، صحبت کردیم. حال بیایید ببینیم کدامیک از آنها در الگوریتم YOLO به کار رفته است.
• ستون فقرات: در YOLO از ورژن GPU مدل CSPDarknet53 به عنوان استخراجکننده ویژگی استفاده شده است. به عنوان VPU (واحد پردازش بینایی) نیز EfficientNet-lite ،MixNet ،GhostNet یا MobileNetV3 بهکار گرفته شده است. در ادامه بیشتر بر روی نسخه GPU تمرکز میکنیم.
در جدول زیر نتایج استفاده از چندین نوع ستون فقرات مختلف برای این نسخه از GPU را مشاهده میکنید.

البته این مدلهای ستون فقرات بیشتر برای طبقهبندی مناسبند تا تشخیص اشیاء. برای مثال، مدل CSPDarknet53 در تشخیص اشیاء بهتر از CSPResNext50 عمل کرد، اما عملکرد CSPResNext50 در طبقهبندی تصاویر از CSPDarknet53 بهتر بود. براساس آنچه در مقاله اصلی گفته شده، مدل ستون فقرات موردنیاز برای تشخیص اشیاء باید سایز ورودی شبکه بزرگتری داشته باشد تا بتواند اشیاء بسیار کوچک را نیز شناسایی کند. همچنین، برای داشتن میدان پذیرنده بزرگتر باید لایههای بیشتر داشته باشد.
گردن: طراحان YOLO در این بخش از تجمیع هرم فضایی (SPP) و شبکه متراکمسازی مسیر (PAN) استفاده کردهاند. البته شبکه PAN استفادهشده تفاوتهایی با شبکه اصلی دارد و نسخه اصلاحشده آن در YOLO بهکار گرفته شده که بهجای افزودن لایهها، آنها را با هم تلفیق میکند. تصویر زیر این شبکه PAN را نشان میدهد.

درواقع در مقاله اصلی شبکه PAN، پس از کاهش سایز و رساندن آن به سایز ، این جدید و کوچکشده به افزوده میشود. این کار در تمامی سطوح برای و انجام میشود تا ساخته شود. اما همانطور که در تصویر زیر ملاحظه میکنید، YOLO بهجای افزودن هر به ، این دو را با یکدیگر پیوند میزند.


ماژول SPP نیز فرآیند حداکثر تجمیع را روی نگاشتهای ویژگی 19*19*512 دارای کرنلهایی kernel با سایزهای مختلف (k = { 5, 9, 13}) و padding مشابه (برای یکسان باقی ماندن سایز فضایی) اجرا میکند. سپس این چهار نگاشت ویژگی متناظر به
یکدیگر پیوند زده میشوند تا یک نگاشت به ابعاد 19*19*2048 ایجاد شود. بدین ترتیب، میدان پذیرنده بخش گردن گسترش مییابد و منجر به بالا رفتن دقت مدل شده و زمان استنتاج را نیز اندکی افزایش میدهد.
اگر میخواهید لایههای مختلف موجود در YOLO را مشابه بالا به تصویر بکشید، میتوانید از این ابزار استفاده کنید و فایل yolov4.cfg را در آن باز کنید.
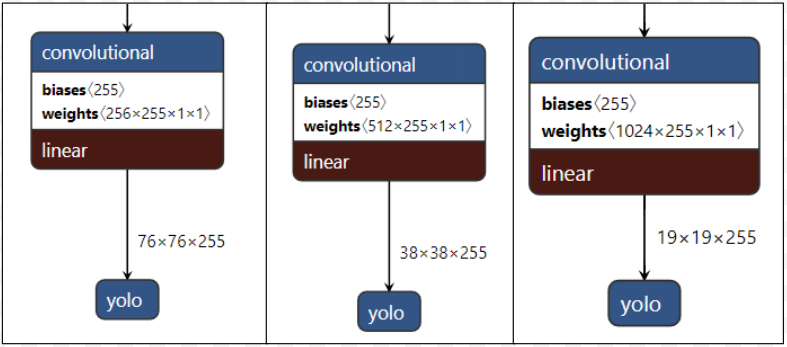
- سر: این بخش مشابه نسخه سوم الگوریتم است:
در تصویر بالا چندین سر برای این الگوریتم وجود دارد که بسته به مقیاس شبکه روی آن قرار میگیرد تا اشیاء با سایزهای مختلف را شناسایی کند. وجود 255 کانال به این دلیل است که در اینجا (80 کلاس + 1 برای شیءسازی + 4 مختصات)×3 کادر محصورکننده از پیش تعیینشده داریم.
خلاصهای از BoF و BoS
ماژولهای یا متدهای مختلف BoF و BoS که در ستون فقرات (Backbone) و شناساگر (Detector) نسخه چهارم YOLO بهکاررفته را میتوان به صورت زیر خلاصه کرد:

اصلاحات تکمیلی
نویسندگان این مقاله روشی جدید به نام «موزاییک» برای داده افزایی معرفی کردند. در این روش، 4 تا از تصاویر دیتاست آموزشی با هم ترکیب و به یک عکس تبدیل میشوند. به این ترتیب، در فرآیند نرمالسازی بستههای دادهای، تابع فعالسازی در هر لایه براساس این 4 تصویر مختلف محاسبه میشود.
و بنابراین، برای آموزش مدل دیگر نیازی به انتخاب بستههای دادهای کوچک با حجم زیاد نخواهد بود. تصاویر زیر نمونهای از اجرای این روش جدید هستند.
آنها همچنین روش خود یادگیری خصمانه (SAT) را بهکار گرفتند که طی دو مرحله پیشرو-پسرو اجرا میشود. در مرحله اول شبکه عصبی به جای وزنهای شبکه، تصاویر را تغییر میدهد. به این ترتیب، شبکه عصبی یک حمله خصمانه به خودش میکند و در آن، تصاویر اصلی را تغییر میدهد تا خودش را گول بزند که شیء مدنظر در تصویر وجود ندارد. در مرحله دوم، به شبکه عصبی یاد داده میشود که به روش همیشگی، شیء را در این تصویر اصلاحشده شناسایی کند.


نسخه نمایشی Colab
من یک نسخه نمایشی برای آزمایش نسخه چهارم YOLO و ورژن کوچکتر آن ساختم که میتوانید روی ویدیوهای خودتان اجرایش کنید. این نسخه نمایشی از مدلی استفاده میکند که توسط دادههای دیتاست MS COCO آموزش دیده است. در این لینک میتوانید این نسخه را مشاهده نمایید.
سخن آخر
در این مقاله ایدههای جالب بسیاری مطرح شد که میتوانستم بیشتر به آنها بپردازم، اما امیدوارم توانسته باشم مفهوم اصلی را به خوبی منتقل کنم.
در مقاله «YOLOv4: Optimal Speed and Accuracy of Object Detection» میتوانید اطلاعات بیشتری در این خصوص پیدا کنید و اگر میخواهید این الگوریتم را روی دیتاست خود آموزش دهید، به این لینک مراجعه نمایید.
نسخه چهارم YOLO در حوزه تشخیص اشیاء به صورت همزمان به نتایج قابلتوجهی (متوسط دقت 43.5%) دست پیدا کرد و قادر است با سرعت 65 فریم بر ثانیه روی GPU مدل V100 اجرا شود. اگر به دنبال الگوریتمی سریعتر اما با دقت پایینتر هستید، نسخه کوچکتر YOLO را میتوانید در این لینک پیدا کنید.





