

سیستم پردازشگر صوتی خود را بسازید: تشخیص واژهی فعالسازی و ردهبندی صدا
 تیم تحریریه
تیم تحریریه- ۱۷ آبان ۱۴۰۰
امروزه دیگر همگی به دستیاران هوشمند خانگی و سیستم پردازشگر صوتی عادت کردهایم؛ این دستگاهها میتوانند دستورات صوتی را اجرا کنند، دربارهی فعالیتهای شکبرانگیز و غیرمعمول به ما اخطار دهند، و حتی جوک بگویند. بازهی قیمت این تکنولوژی بسیار گسترده است و به همین دلیل عمدهی مردم توان خرید آن را دارند. اما آیا تا به حال به این فکر کردهاید که خودتان چنین مدلی بسازید؟
در این نوشتار قصد داریم به شما کمک کنیم سیستم پردازشگر صوتی خود را بسازید. گامهایی که در این مقاله مطرح میکنیم شما را به سوی طراحی سیستمی هدایت میکند که جریان صوتی گرفته شده از یک میکروفون متصل را به کار برده و با تشخیص یک کلمهی کلیدی یا تشخیص صدای هدف (مثل گریهی یک بچه) هشدار صادر میکند.
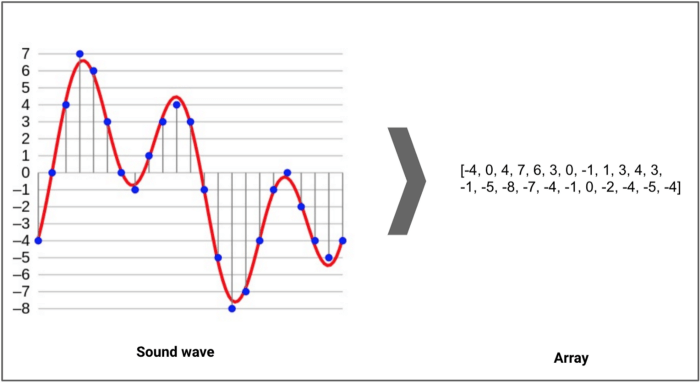
دادهی صوتی Voice commands
ابتدا تعریفی از نوع صوتی داده ها ارائه میدهیم؛ مطابق ویکیپدیا صدا ارتعاشی است که به صورت یک موج صوتی Acoustic wave در محیطهای انتقال Transmission medium (گاز، مایع یا جامد) پخش میشود. برای تبدیل صدا به دادهی صوتی، باید با نمونهگیری از صداها در فواصل مجزا (نرخ نمونهگیری Sampling rate)، آنها را به صورت رقمی شده digitize درآورد. نرخ نمونهگیری معمول برای صوتی با کیفیت CD، 44.1 کیلوهرتز است؛ به این معنی که از این موج صوتی 44100 بار در ثانیه نمونهگیری انجام میشود.
یک نمونه برابر است با دامنهی نوسان amplitude موج در یک فریم زمانی خاص. چگالی بیتها Bit depth میزان جزئیات نمونه را نشان میدهند. این مقدار معمولاً 16 بیت (65536 مقدار نوسان ) است.
دیتاست صوتی
در شروع یک پروژهی سیستم پردازشگر صوتی یکی از اولین دغدغهها مربوط به منبع دریافت دادههاست (به خصوص اگر تا به حال فقط با دادههای جدولی یا تصاویر کار کرده باشید). اما، همانطور که خواهید دید، دیتاستهای صوتی زیادی وجود دارند که در مقاصد پژوهشی به کار برده میشوند. برخی از آنها را در این نوشتار معرفی میکنیم:
• دستهبندی صداهای محیطی Environmental sounds classification (ESC-50)
• دیتاست دستور صوتی گوگل Google speech command
• Freesound
ESC-50
یکی از دیتاستهای مهم و باارزش دیتاست دستهبندی صداهای محیطی است. این دیتاست 2000 رکورد برچسبخورده از صداهای محیطی را در برمیگیرد که میتواند در محکزنی benchmarking روشهای مختلف دستهبندی صداهای محیطی بسیار مفید باشد.
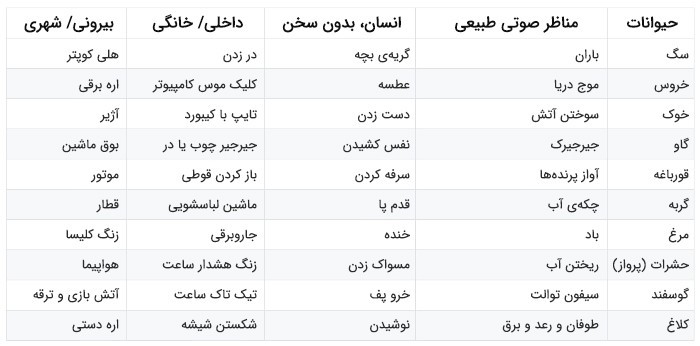
دیتاست ESC-50 شامل رکوردهای 5 ثانیهای است که در 50 کلاس معنایی Semantical classes (هر کلاس 40 نمونه دارد) و 5 دستهی کلی مرتب شدهاند:
• حیوانات
• نامآواها و صدای آب
• صدای انسان، بدون کلام
• صداهای داخلی /خانگی
• صداهای بیرونی /شهری
دیتاست دستور صوتی گوگل Google speech command
تیمهای تنسورفلو و AIY با همکاری همدیگر دیتاست دستور صوتی را ارائه دادهاند. این دیتاست رایگان بوده و برای مبتدیها نیز قابل استفاده است. در این دیتاست 65000 گفتار یک ثانیهای وجود دارد که مربوط به 30 کلمهی کوتاه بیان شده توسط هزاران نفر میباشد. با استفاده از این دیتاست قادر خواهید بود رابطهای صوتی ابتدایی Basic voice interfaces بسازید که شامل کلماتی مثل بله و خیر، اعداد و جهتها میشوند.
تیم تنسورفلو یک ویدئوی آموزشی تهیه و منتشر کرده است که طی آن نحوهی ساخت یک شبکهی سادهی تشخیص گفتار، قادر به شناسایی ده کلمهی متفاوت، آموزش داده میشود.
Freesound
Creative Commons نام یک گواهی است که امکان به اشتراکگذاری، استفاده و تغییر یک اثر را بدون نقض حق کپیرایت آن فراهم میکند. Freesound نیز یک پایگاه داده است که دقیقاً همین کار را انجام میدهد. یعنی میتوانید همهی صداهای روی این دیتاست (از صدای جلوههای ویژه تا صدای انسان) را جستجو و دانلود کرده و به اشتراک بگذارید.
گردآوری داده
اگر مسئلهی مدنظر شما اختصاصیتر است و به گردآوری دادههای بیشتری نیاز دارد میتوانید از وبسایتهای freelance استفاده کنید. از آنجایی که وبسایت Quantum به گردآوری دستورهای صوتی مرتبط با سامانه Platform-related نیاز داشت، ما برای پروژهی خود از وبسایت Amazon Mechanical Turk استفاده کردیم. با اینکه در این منبع هیچ الگوی از پیش تعیینشدهای Pre-made template از مجموعههای صوتی وجود ندارد، میتوانید دستورالعملهای زیادی را روی وب بیابید که شما را در ساخت چنین الگویی راهنمایی خواهند کرد.
پردازش صوتی
وقتی همهی دادههای لازم را در اختیار داشتید، میتوانید کار خود را آغاز کنید.
ارزیابی دیتاست
اولین قدم در هر پروژهای بررسی دادههای موجود و فهم آنهاست. در مسائل پردازش صوتی نیز لازم است به همهی صوتها گوش دهید تا بتوانید کیفیت و گوناگونی آنها را ارزیابی کنید. در صورتیکه دادههای خود را از یک سامانهی freelance تهیه کردهاید، پیشنهاد ما این است که همهی رکوردها را ارزیابی نمایید (زیرا ممکن است کیفیت همهی آنها خوب و قابل قبول نباشد). اما اگر دیتاست مورد استفادهی شما از پیش موجود بوده، گوش دادن به فقط چند رکورد هم کافی است. غالب مشکلات احتمالی مربوط به دادههای نویزدار Noisy data هستند.
شروع کار
در این قسمت مثالهایی را میبینید که شما را در شروع کار با هر کدام از دو بسته (Librosa و Pydub) راهنمایی خواهند کرد.
با این دستور میتوانید یک فایل صوتی را با استفاده از بستهی Librosa بارگذاری کنید. X یک بازنمایی آرایهای NumPy از فایل صوتی ورودی است. این آرایه به شکل (N, SR) مشخص میشود که در آن N تعداد کانالها (1 برای تک کانالی Mono، 2 برایاستریو stereo) و SR نرخ نمونه (که به صورت پیشفرض روی 22100 تنظیم شده) است.
import librosa audio_path = 'audio-path' x , sr = librosa.load(audio_path)
این دستور هم مربوط به استفاده از بستهی Pydub در بارگذاری و گوش دادن به یک فایل صوتی در نوتبوک Jupyter است.
from pydub import AudioSegment
audio = AudioSegment.from_file("file.wav", "wav")
هنگام فیلتر کردن فایلها، به جای استفاده از پخشکنندههای استاندارد صدا، میتوانید این «صورسازی داده» را به کار ببرید.
پیشپردازش دیتاست
اولین قدم، پاک کردن همهی نمونههای سکوت است. با استفاده از پکیج Librosa میتوانید به آسانی این گام را اجرا کنید؛ اما کاربرد این بسته مستلزم سروکار داشتن با آستانهی top_db است که مقدار پیشفرض آن پاسخگوی پروژهی ما نبود.
حذف نمونههای سکوت
y, sr = librosa.load(file)
yt, index = librosa.effects.trim(y, top_db=20)
y_harm, y_perc = librosa.effects.hpss(yt)
librosa.display.waveplot(y_harm, sr=sr, alpha=0.25)
librosa.display.waveplot(y_perc, sr=sr, color='r', alpha=0.5)
plt.title('Harmonic + Percussive')
plt.tight_layout()
plt.show()
صوت خام:
صوت کوتاه شده:
نرمالسازی صوت
حال، از آنجایی که همهی دادهها فقط صداهای هدف را شامل میشوند، برای نرمالسازی میتوانیم از ماژول Pydub استفاده کنیم (مثل کارهای قدیمی یادگیری ماشین). به این مثال توجه کنید:
from pydub import AudioSegment, effects
rawsound = AudioSegment.from_file("input.wav", "wav")
normalizedsound = effects.normalize(rawsound)
normalizedsound.export("output.wav", format="wav")
صوت خام
صوت نرمالسازی شده
استخراج ویژگی
وقتی دادهها کاملاً تمیز و فیلتر شدند، زمان استخراج ویژگی از فایلهای خام صوتی فرا میرسد.
ویژگیهای زیادی در کتابخانهی Librosa وجود دارند. ما در پروژهی خود این ویژگیها را انتخاب کردیم (شما میتوانید ویژگیهای دیگری انتخاب کنید):
y, sr = librosa.load(audio_file_path) chroma_stft = librosa.feature.chroma_stft(y=y, sr=sr) rmse = librosa.feature.rms(y=y) spec_cent = librosa.feature.spectral_centroid(y=y, sr=sr) spec_bw = librosa.feature.spectral_bandwidth(y=y, sr=sr) rolloff = librosa.feature.spectral_rolloff(y=y, sr=sr) zcr = librosa.feature.zero_crossing_rate(y) mfcc = librosa.feature.mfcc(y=y, sr=sr)
اینجا نیز نتیجهی مصورسازی برخی از ویژگیهای تولیدشده را مشاهده میکنید:
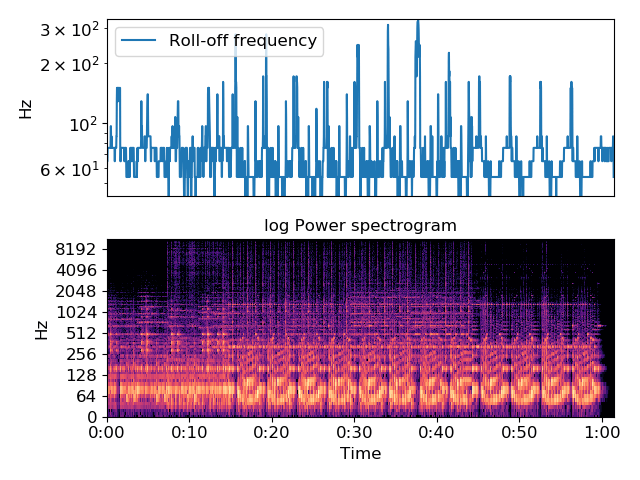
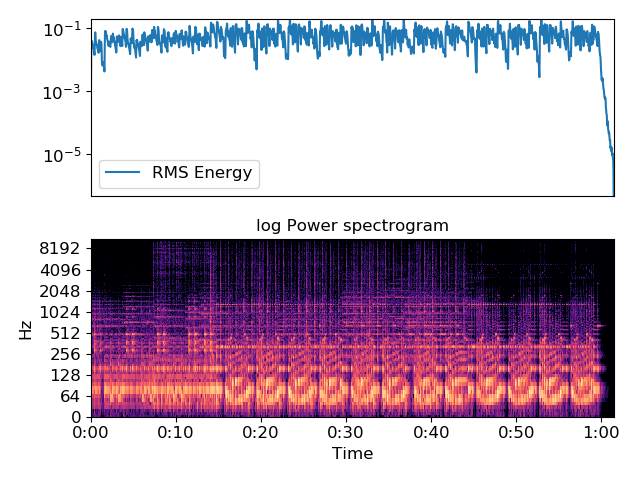
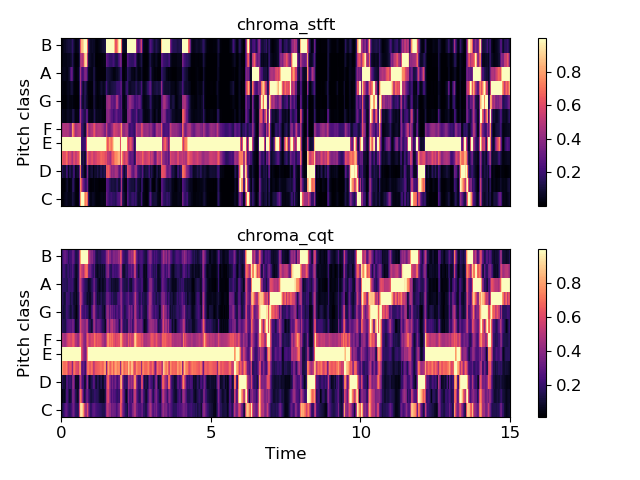
مدلسازی
اگر میخواهید سیستم روی یک دستگاه تعبیهشده (همچون Raspberry Pi) و به خصوص همراه ماژولهای دیگر (مثل تشخیص اشیاء) روی یک برنامههای پخش ویدئو اجرا شود، باید به اندازهی مدلهایی که به کار میبرید توجه داشته باشید. از آنجایی که خود ما نیز به دنبال چنین هدفی بودیم، انواع مدلهایی که به کاربردیم از الگوریتم LogisticRegression کتابخانه Scikit-learn تا شبکه های عصبی ساده گسترده بودند.
دستهبندی صدا
در این مسئلهی دستهبندی صدایی که در دست داریم، میخواهیم سیستمی شبیه هشدار دهنده خودکار کودک Automated baby monitor پیادهسازی کنیم که با شنیدن صدای گریهی بچه فعال میشود.
ردهبندی صدای گریهی یک بچه بسیار آسان است، زیرا این صدا قابل تمایز بوده و به سختی با صدای دیگری اشتباه گرفته میشود. نکتهی دیگر این است که سعی داشتیم این ماژول را کوچک نگه داریم تا به عملکردی خوب روی دستگاههای تعبیهای دست یابیم. به همین دلیل هم از مدلهای LogisticRegression کتابخانه Scikit-learn، گوسی بیز ساده Gaussian Naïve Bayes و جنگل تصادفی Random Forest استفاده کردیم.
ویژگیهایی که از نمونههای صوتی استخراج شدند عبارتاند از:
• ‘chroma stft’
• ‘mfcc’
• ‘rolloff’
• ‘spectral bandwidth’
• ‘spectral centroid’
• ‘zero-crossing rate’
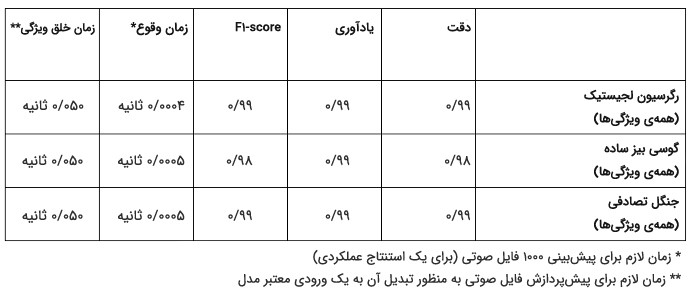
در این جدول، عملکرد مدلهای مختلفی را مشاهده میکنید که برای ردهبندی صدا آموزش دیدهاند:
تشخیص واژه فعالسازی
برای تشخیص واژهی فعالسازی سفارشی حدود 1500 فایل صوتی روی وبسایت Amazon MTurk جمعآوری شده است. در این طرح آزمایشی، مدلهای به کار رفته هفت معماری متفاوت و سه اندازهی گوناگون داشتند. آموزش مدلها با استفاده از منبع کد Keyword Spotting صورت گرفت که همواره مورد تأیید دستگاههای تعبیهای با پردازشگرهای Arm بوده است.
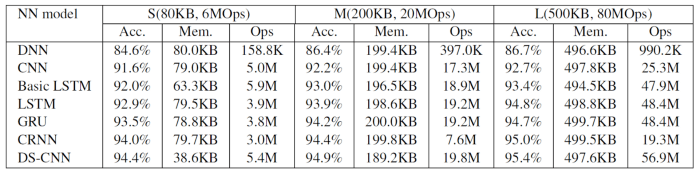
این جدول نتایج آموزش مدل را (فقط) روی دیتاست دستور صوتی گوگل نشان میدهد.
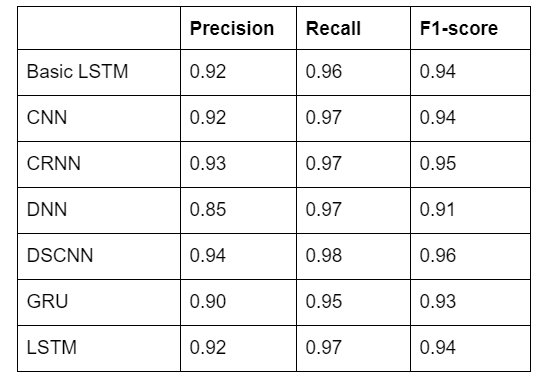
در جدول پایین اندازههای مربوط به آزمایش مدلهایی (فقط مدلهای متوسط ) را میبینید که روی دادههای سفارشی جمعآوریشده آموزش دیدهاند.
پسپردازش postprocessing
برای کاهش نرخ جوابهای مثبتهای کاذب False-positive میتوانید روشهای پردازشی متفاوتی به کار ببرید. ابتدا لازم است یک پنجرهی لغزان Sliding window از جریان صوتی را انتخاب و فریمهای صوتی متوالی Consecutive audio frames آن را برای مقایسهی نتایج بررسی کنید؛ اگر مدل به خوبی آموزش دیده باشد، بیشتر مثبتهای کاذب حذف خواهد شد. سپس یک پنجرهی لغزان کوچکتر را انتخاب و یک آستانه برای تعداد فریمهای متوالی آن تعیین کنید؛ این آستانه زمان راهاندازی هشدار سیستم پردازشگر صوتی را مشخص خواهد کرد. علاوه بر این، برای بلندی صدا نیز میتوانید آستانهای مشخص کنید تا بدین ترتیب از بخشهای سکوت (بدون صدا) جریان صوتی رد شوید.
پردازش جریان
حالا که همهی مدلها آموزش دیده و تنظیم شدهاند، باید مسیر پردازش صوتی Audio processing pipeline را ایجاد کنیم. در کتابخانهی PyAudio تنظیمات مناسبی برای پردازش جریان صوتی ارائه شده است. این جریان صوتی یک گزینهی فراخوانی بازگشتی دارد که با استفاده از آن میتوان مدلها را با استفاده از دادههای ورودی به دست آورد. علاوه بر این، امکان تنظیم پارامترها برای دستیابی به آن پنجرهی لغزانی که در بخش پسپردازش مطرح شد نیز وجود دارد.
# instantiate PyAudio (1) p = pyaudio.PyAudio() # define callback (2) def callback(in_data, frame_count, time_info, status): data = wf.readframes(frame_count) return (data, pyaudio.paContinue) # open stream using callback (3) stream = p.open(format=p.get_format_from_width(wf.getsampwidth()), channels=wf.getnchannels(), rate=wf.getframerate(), output=True, stream_callback=callback) # start the stream (4) stream.start_stream() # wait for stream to finish (5) while stream.is_active(): time.sleep(0.1)
سخن نهایی
همهی روشهایی که توضیح دادیم مرسوم و قابل قبول هستند و به نتایج موفقیتآمیزی دست یافتهاند. با این حال ممکن است در زندگی و موقعیتهای واقعی، که از جریان صوتی تولیدشده توسط دستگاه هدف استفاده میشود، منجر به مشکلاتی شوند.
برای مثال، ممکن است دیتاست آنقدر متعادل نباشد که جریان صوتی واقعی Realistic audio feed (سکوت و سروصداهای پسزمینه) را در نظر بگیرد. این مشکل را میتوان با ایجاد قوانینی در مسیر سیستم پردازشگر صوتی یا با کاربرد نمونههای دسته منفی دیتاست حل کرد. مشکل دیگر میتواند این باشد که دستگاه هدف (مثلاً میکرفون) با دستگاهی که برای ضبط دادههای صوتی به کار رفته متفاوت بوده و در نتیجه لازم باشد روی خود بستر هدف Target platform آزمایشات اضافی صورت گیرد.
این نوشتار سعی داشت شیوهی کار با دادههای صوتی در پروژههای علوم داده را به مخاطبان توضیح دهد. امیدواریم دستورالعمل و راهنمایی که برای شروع کار ارائه دادیم به پروژههای شما در این حوزه کمک کند.





