

منظور از کلان داده چیست؟
 تیم تحریریه
تیم تحریریه- ۱۸ بهمن ۱۴۰۱
برای رسیدن به موقعیت کنونی چه مسیری را طی کردهایم؟ در این مسیر به چه قابلیتهایی دست پیدا کردهایم؟ و چه پیشرفتهایی در انتظار ما است؟ برای پاسخ به این سؤالات باید تاریخچه داده را مطالعه کنیم.
گلن بک Glen Beck و بتی اسنایدر Betty Snyder – طرح انیاک ENIAC، آزمایشگاه پژوهشهای بالستیک واقع در ساختمان 328 ( تصاویر ارتش ایالات متحده، کالیفرنیا. 1955 – 1947). تصاویر ارتش ایالات متحده. این تصویر در تملک عمومی قرار دارد.
آغاز راه (دهه 40 میلادی)
سالها پیش در ماه دسامبر سال 1945، اولین کامپیوتر الکترونیکی- دیجیتالی همه منظوره Electronic general-purpose digital computer ساخته شد. این کامپیوتر انیاک ( محاسبهگر و یکپارچهساز عددی الکترونیک ) نامیده میشد. تا پیش از فرا رسیدن این دوره برای انجام هر کاری به صورت سفارشی یک کامپیوتر مجزا ساخته میشد.
اگر بخواهیم انیاک را با تازهترین پیشرفتهایی که در حوزه فنآوری حاصل شده مقایسه کنیم باید بگوییم که بیشینه کلاک Max clock انیاک تک هستهای حدود 5 کیلوهرتز بوده، در حالیکه سرعت ساعت جدیدترین تراشه 6 هستهای تعبیه شده در آیفون (Apple A13) برابر با 2.66 گیگاهرتز است. به عبارت دیگر سیکل واحد پردازنده در هر ثانیه بیش از چهار میلیون برابر افزایش یافته و علاوه بر آن تعداد دستورالعملهایی که واحد پردازنده میتواند در هر یک از این سیکلها انجام دهد افزایش یافته است.
در طول تاریخ پیشرفتهای بیشماری در حوزه سختافزار حاصل شده و انسانها با اتکاء به این پیشرفتها توانستهاند به قابلیتهای جدیدی در زمینه مهندسی نرمافزار دست پیدا کنند. در نتیجه انعطافپذیری نرمافزارها افزایش پیدا کرده و در همان حال لازم است مهندسان مسئولیتپذیری بیشتری داشته باشند. مسلماً مهندسین آرزو دارند بتوانند نرمافزارهایی با همان میزان انعطافپذیری عرضه کنند و در همان حال فشار و زحمت کمتری در این مسیر متحمل شوند

سیر تکاملی دادهها (دهه 60 میلادی – دهه 90 میلادی)
در آغاز هزینه استفاده و نگهداری از سرورها زیاد بود و در عین حال فضای حافظه کمکی و حافظه اصلی و همچنین توان محاسباتی آنها محدود بود و به همین دلیل برنامهنویسها ،از جمله مدیریت حافظه، برای حل مسائل متحمل زحمت زیادی میشدند. در مقابل، امروزه برای انجام این قبیل از کارها ، زبانهای برنامهنویسی با قابلیت زبالهروبی خودکار در اختیار داریم.
به همین دلیل زبانهای C، C++ و FORTRAN به طور گسترده مورد استفاده قرار میگرفتند و کماکان از آنها در حوزههای مهم استفاده میشود؛ در اینگونه حوزهها تلاش ما بر این است که حداکثر استفاده را از کارایی و ارزش یک سیستم داشته باشیم. امروزه نیز اکثر چارچوبهای یادگیری ماشین و تحلیل داده Data analytics به زبان پایتون برای اطمینان از کیفیت عملکرد، از زبان C استفاده میکنند و برنامهنویسها فقط از یک API استفاده میکنند.
شرکتهایی از جمله IBM برای استفاده حداکثری از سیستمهایی که دادهها را سازماندهی میکنند و همچنین به منظور ذخیره کردن، بازیابی و کار کردن با دادهها سرمایهگذاریهای کلانی بر روی برخی مدلها انجام دادهاند. در مقابل مدل سلسله مراتبی از دادهها ارائه شده که در طول دوران بزرگرایانه Mainframe بسیار رایج و متدوال بوده است. شرکتها با ایجاد یک مدل استاندارد میزان فعالیت ذهنی لازم برای شروع یک پروژه را کاهش دادند و دانشی را که میتوان در پروژههای مختلف به کار بست، افزایش دادند.

در گذشته از بزرگرایانهها برای حل مشکلات روز استفاده میشد اما این گونه رایانهها بسیار گرانقیمت بودند، در نتیجه فقط مؤسسات بزرگ از جمله بانکها توان مالی خرید چنین سیستمهایی را داشتند و میتوانستند به نحوی کارآمد از مزایای آنها بهرهمند شوند. بزرگرایانهها در پیمایش ساختارهای درختی traversing tree-like structures بسیار کارآمد بودند، اما روابط یک به چند آنها به حدی دقیق و پیچیده است که درک و استفاده از آنها برای برنامهنویسان دشوار است.
مدتی بعد مدلهای رابطهای Relational model ساخته شدند که امروزه نیروی اکثر دیتابیسهای ما را تأمین میکنند. در مدلهای رابطهای دادهها به صورت دستههای چندتایی (جدولها) با روابط میان آنها نشان داده میشوند. یک رابطه معمولی کلیدی خارجی است که مشخص میکند دادههای درون دو جدول باید با یکدیگر ارتباط داشته باشند. به بیانی سادهتر شما نمیتوانید نمرههایی از یک آزمون درسی داشته باشید اما دانشآموزانی که در این آزمون شرکت کردهاند را نداشته باشید و نمیتوانید کلاسی از دانشآموزان داشته باشید اما معلمی نباشد که به آنها درس بدهد.

با توجه به ساختار دادهها میتوانیم یک زبان استاندارد تعریف کنیم و از این طریق با دادههایی که ساختار مشابهی دارند کار کنیم. سازنده اصلی مدلهای رابطهای، زبان پرسمان ساختاریافته (SQL) Structured Query Language (SQL) را هم ایجاد کرده که زبانی برای مدیرت دادهها است. دلیل آن هم این است که خواندن SQL بسیار آسان است و در همان حال بسیار توانمند است. چنانچه سیستم قابلیت اجرای تابع بازگشتی Recursion و تابع پنجره را داشته باشد، SQL تورینگ کامل Turing complete خواهد بود.
تورینگ کامل به این معناست که اگر زبان زمان کافی داشته باشد میتواند تمامی مشکلات محاسباتی را حل کند. توانایی حل تمامی مشکلات محاسباتی در زمان کافی یکی از ویژگیها و قابلیتهای ممتاز SQL است، اما به این معنی نیست که برای انجام هر کاری میتوان از آن استفاده کرد. به همین دلیل از SQL برای بازیابی و دسترسی به دادهها و از پایتون و زبانهای دیگر برای تحلیل پیشرفته دادهها استفاده میکنیم.
شرکت Oracle در سال 1979 اولین دیتابیس رابطهای Relational database را عرضه کرد. این سیستمها سیستمهای مدیریت دیتابیس رابطهای (RDBMS) نامیده میشوند. از آن زمان به بعد RDBMSهای متنباز و تجاری زیادی عرضه شده است. تمامی این عوامل دست به دست یکدیگر دادند تا Apache Software Foundation به یکی از شرکت اصلی ارائهدهنده ابزارهای حوزه «کلان داده» تبدیل شود. با در اختیار داشتن پروانههای آسانگیر این شرکت میتوان در زمان استفاده از کد منبع اصلی کتابخانه فعالیتهای تجاری را انجام داد.
اینگونه سیستمها عملکرد بسیار خوبی در مدیریت و دسترسی به دادههایی با ساختارهای دادهای نرمالسازیشده Normalized data structures دارند. با وجود این، همزمان با افزایش حجم دادهها، عملکرد آنها تحت تأثیر حجم کاری زیاد، کاهش پیدا میکند. تکنیکهای بهینهسازی بسیاری از جمله شاخصگذاری و read-replicas و غیره داریم که میتوانیم با استفاده از آنها فشار و حجم کاری سیستمها را کاهش دهیم.
جهان متصل و انواع گوناگون دادهها (دهه 90 میلادی)
پیش از راهیابی کامپیوترها به خانهها و پیش از اینکه هر فردی یک تلفن همراه شخصی داشته باشد، ارتباطات مردم با یکدیگر محدود و دادههای مربوط به این ارتباطات به میزان قابل توجهی کم بود. تقریباً تمامی وبسایتهایی که به آنها مراجعه میکنید پیگیری جریان اطلاعات را فعال کردهاند تا درک بهتری از تجارب کاربران به دست بیاورند و از این طریق نتایج شخصیسازیشده بیشتری به کاربران ارائه دهند.
پس از انکه جمعآوری دادهها به صورت خودکار درآمد و کاربران مجبور بودند نظرات و بازخوردهای خود را در قالب پیمایش، تماسهای تلفنی و غیره ارائه دهند، روند جمعآوری داده سیر صعودی در پیش گرفت. امروزه فعالیتهای ما معرف ما هستند و اعمال و فعالیتهای ما بیشتر از افکار و سخنان ما در معرفی ما نقش دارند. از مدتها پیش نتفلیکس دیگر به شما اجازه نمیدهند به فیلمها امتیاز دهید و یا آنها را رتبهبندی کنید، چرا که متوجه شدهاند این اطلاعات به درک بهتر از این اکوسیستم کمکی نمیکند.
شاخص جستوجوی گوگل و نیاز به MapReduce (اوایل دهه اول قرن بیست و یک)
گوگل جز اولین شرکتهایی است که از فنآوریهای پیشرفته برای جمعآوری دادهها در حجم بالا استفاده کرد؛ هرچند امروزه شرگت گوگل به عنوان یکی از سودآورترین شرکتهای دنیا شناخته میشود اما در اواخر دهه 90 میلادی بودجه کلانی کنونی را در اختیار نداشت. مزیت رقابتی شرکت گوگل در حجم دادهای است که در اختیار دارد و علاوه بر این میتواند به بهترین نحو از این دادهها استفاده میکند.
در زمان آغاز به کار شرکت گوگل تیم مهندسی آن با مشکل پیچیدهای رو به رو شد و میباست آن را رفع کند، اما آنها توان مالی خرید سختافزار شرکتی را نداشتند؛ این سختافزار بسیار گران بود و شرکتهای قدیمیتر برای انجام امور خود به آن متکی بودند. هرچند در آن زمان توان محاسباتی این شرکت بیشتر از شرکتهای دیگر نبود اما با آنها برابری میکرد. تقاضا برای خدمات شرکت گوگل و به طور کلی
وبسایت آن رو به افزایش بود و شرکت گوگل برای آنکه بتواند پاسخگوی نیاز کاربران باشد سیستم فرانکنشتاین را ساخت. قطعات به کار رفته در سِروِر آنها کیفیت پایینی داشت و برای استفاده مصرفکنندگان معمولی طراحی و تولید شده بودند و احتمال خطا در آنها وجود داشت و علاوه بر این، کُدی که از آنها استفاده میکرد، مقیاسپذیر نبود و نسبت به این خرابیها مصون نبود.

در آن زمان جِف دین و سانجی قماوات مهندسان ارشد شرکت گوگل بودند. آنها با جدیت تمام در حال بازنویسی کُدبیس Frankenstein system گوگل بودند تا مقاومت آن را در مقابل خرابیها افزایش دهند. یکی از اصلیترین مشکلاتی که با آن مواجه بودند این بود که این سختافزار در حین اجرای برنامهها متوقف میشد و میبایست آن را مجدداً راهاندازی کرد. این دو فرد در هنگام رفع مشکل کدبیس، متوجه یک الگوی ثابت شدند که میتوانند چارچوب را بر مبنای آن بسازند. این الگو MapReduce نامیده میشد.
MapReduce یک مدل برنامهنویسی است و شامل دو مرحله است، مرحله نگاشت Map phase و مرحله کاهش Reduce phase. منظور از نگاشت شکستن یک تسک بزرگ به تسک های کوچک تر است و منظور از کاهش جمع بندی تمام نتایج برای تولید نتیجه کار اولیه است. این چارچوب دارای یک رابط ساده است که با استفاده از آن میتوان یک کار را در میان ورکِرهای مختلف یک خوشه به اجزای کوچکتر تقسیم کرد.
اگر بتوانیم کاری را به قسمتهای کوچکتر تقسیم کنیم، در صورت بروز هر گونه خطا میتوانیم کار را بدون نیاز به اجرای مجدد آن، بازیابی کنیم. علاوه بر این، تقسیم یک کار به قسمتهای کوچکتر به این معناست که سیستم مقیاسپذیرتر و قویتر است. راههای زیادی برای ارتقای عملکرد سیستم MapReduce وجود دارد و همزمان با توضیح لایههای انتزاعی Abstraction layers آنها را نیز بررسی میکنیم.

گوگل با استفاده از MapReduce توانست مقیاس زیرساخت خود را با سرورهایی که ارزان بودند و ساخت و نگهداری آنها آسان بود، افزایش دهد. آنها میتوانند به صورت خودکار خطاهای کد را بررسی کنند و حتی میتواند به آنها هشدار دهد که ممکن است سرور به تعمیر نیاز داشته باشد و برخی قطعات را باید جایگزین کرد. این کار موجب شده گراف وب Web graph به اندازهای بزرگ شود که فقط ابرکامپیوترها بتوانند مقیاس آن را اداره کنند.
جف دین و سانجی قماوات کماکان در این شرکت فعالیت دارند و در بسیاری از پیشرفتهایی که در حوزه فنآوری حاصل شده و چشمانداز داده را شکل داده مشارکت داشتهاند.
MapReduce به عنوان یک پیادهسازی متن باز- مقدمهای بر Hadoop (اواسط دهه اول قرن بیست و یک)
شرکت گوگل ابزارهاِ گوناگون را برای استفاده در سیستمهای داخلی و درونسازمانی خود طراحی و تولید میکند. اما این شرکت دانش خود را در قالب مقالات علمی در اختیار دیگران قرار میدهد. در مقاله MapReduce: پردازش آسان داده در خوشههای بزرگ مدل برنامهنویسی MapReduce به طور خلاصه توضیح داده شده است و در قسمت ضمیمه نمونهای از پیادهسازی الگوریتم شمارش کلمات Word count algorithm قرار داده شده است.
تعداد کدهایی که برای نوشتن یک کار MapReduce لازم است بیشتر از تعداد کدهای پایتون برای انجام همان کار است. کدهای پایتون فقط بر روی یک ریسه واحد اجرا میشود و توان عملیاتی Throughput آن محدود است، در مقابل MapReduce با هر تعداد سروری که برای انجام یک کار نیاز داریم، مقیاسبندی میشود.
تفاوت سیستمهای اولیه با سیستمهای امروزی در پیچیده بودن و قابلیت مقیاسپذیری آنها است و سیستمهای اولیهای که MapReduce را توانا میساختند بسیار پیچیده بودند.
اواسط دهه اول قرن بیست و یک داک کاتینگ و مایک کافارلا مقاله گوگل حول موضوع MapReduce را مطالعه کردند و علاوه بر این مقاله دیگری حول موضوع سیستم فایل توزیعشده گوگل موسوم به سیستم فایل گوگل مطالعه کردند. در آن زمان این دو فرد بر روی یک خزنده وب توزیع شده موسوم به Nutch کار میکردند و متوجه شدند آنها هم برای مقیاسپذیر کردن سیستم خود همین مشکل را دارند.
داگ به دنبال یک شغل تمام وقت بود و در نهایت به استخدام یاهو در آمد و از آن جایی که در آن زمان یاهو از شرکت گوگل عقب مانده بود، ایده ساخت سیستم متن باز برای توانا ساختن شاخصگذاری مقیاس بزرگ Large-scale indexing را از داگ خرید. شرکت یاهو کاتینگ را استخدام کرد و از او خواست به کار کردن بر روی پروژه Nutch که باعث بسط دادن سیستم فایل توزیعشده و چارچوب محاسباتی میشد ادامه دهد و این در حالی بود که سیستم فایل توزیعشده و همچنین چارچوب محاسباتی از اجزای اصلی هدوپ Hadoop بودند.
سیستم فایل توزیعشده و چارچوب محاسباتی سیستم فایل توزیعشده هدوپ و Hadoop MapReduce نامیده میشدند. همزمان با اینکه سیستم فایل توزیعشده و چارچوب محاسباتی در هدوپ خلاصه شدند، هدوپ وارد چرخه هایپ (محبوبیت) شد و به همین دلیل این نامگذاری کمی عجیب به نظر میرسد.
MapReduce برای مصون ماندن در مقابل خطاهایی که در کل پشته سختافزار روی میدهد، از سیستم فایل توزیعشده استفاده میکند. جِف دین این مطلب را در ظهور سیستمهای رایانش ابری توضیح داده و در بخشی از این مقاله عنوان میکند که « قابلیت اطمینان باید از جانب نرمافزارها تأمین شود» و در ادامه خطاهایی که در سال 2006 در یک خوشه معمولی گوگل روی داده را شرح میدهد:
- کابلکشی مجدد شبکه Network rewiring ( حدود 5 درصد از ماشینها به مدت دو روز خاموش میشوند)
- خطای رَک Rack failure (40 تا 80 ماشین درون یک رک ناپدید شدند، بازگرداندن آنها 1 تا 6 ساعت طول کشید)
- رَکها ضعیف شدند ( 40 تا 80 ماشین درون یک رک با 50 درصد مشکل ارتباطی مواجه شدند)
- نگهداری شبکه ( ممکن است به طور تصادفی باعث قعطی 30 دقیقهای در ارتباطات شود)
- بارگذاری مجدد مسیر ( سرویس DNS و vipهای مجازی برای دقایقی از دسترس خارج شدند)
- خطاهای مسیریاب ( ترافیک دادهها برای یک ساعت قطع میشود )
- دههاخطای کوچک سی ثانیهای بر روی سرویس DNS، تقریباً 1000 ماشین خاموش شدند
- خطا در دیسک حافظه موجب کندی، مشکل در حافظه، اشتباه در تنظیمات ماشینها، ماشینهای بیثبات و غیره میشود
روشهای زیادی برای ارتقای عملکرد پشته وجود دارد، برای مثال میتوان دادهها را در حجم کم جا به جا کرد و از این طریق تأخیر در شبکه را به حداقل رساند. به منظور دستیابی به این هدف به جای اینکه حافظه کمکی را NFS و یا SAN نگهداری کنیم، با استفاده از دیسکهای بزرگ محاسبه را در حافظه انجام میدهیم. در زمان انجام محاسبات در حافظه نمیخواهیم یک گره خاص در یک خوشه محاسبات بسیار زیادی انجام دهد چرا که حاوی داده است.
علاوه بر این باید یک کپی از دادهها تهیه کنیم، در این صورت اگر گرهای از کار افتاد با مشکل مواجه نخواهیم شد و میتوانیم کار را تقسیم کنیم. اگر به نمونه خطاهایی که گوگل توضیح داده نگاهی بیندازیم، متوجه میشویم که باید آمادگی لازم برای مقابله با خطاهای گرهها و خطای رک را داشته باشیم . به عبارت دیگر باید با انواع خطاهای رک در حافظه آشنایی داشته باشیم و چندین کپی از دادهها داشته باشیم.

اولین مدل MapReduce به نام Hadoop MapReduce به دانش زیادی در زمینه فرایند MapReduce و مبانی بهینهسازی عملکرد در چارچوب نیاز داشت. یکی از اصلیترین مشکلات MapReduce این بود که نمیتوانستیم فرایندهای پیچیدهای بر روی آن تعریف کنیم. در آن زمان سیستمی برای ایجاد منطقهای پیچیده وجود نداشت.
در عوض، Hadoop MapReduce بلوکهای سطح پایینتر را برای انجام محاسبات مقیاسپذیر ارائه میداد اما نمیتوانست به نحوی کارآمد آنها را هماهنگ کند. یکی دیگر از نقاط ضعف Hadoop MapReduce استفاده از دیسک بود و چیزی بر روی حافظه ذخیره نمیشد. در زمان عرضه MapReduce حافظه بسیار گران بود و اگر حافظه پر میشد، در انجام کارها اختلال به وجود میآمد . همه مواردی که به آنها اشاره کردیم نشان میدهند که Hadoop Reduce کند و نوشتن برای آن دشوار بوده، اما در همان حال ثابت و مقیاسپذیر بود.
به منظور حل این مشکلات چندین راهکار از جمله Pig (رونویسی، Hive ( زبان پرسمان ساختاریافته)، MRJob (پیکربندی) ارائه شد. تمامی این راهکارها موجب شدند MapReduce، الگوریتمهای تکراری Iterative algorithms، بویلرپلیت Boilerplate کمتر، انتزاع ( مخفی کردن نحوه پیادهسازی) بهتر کد را توانا سازد. وجود اینگونه ابزارها به افرادی که تخصص کمتری در حوزه مهندسی نرمافزار دارند و تجربه کمتری در حوزه جاوا دارند کمک کرد از مزایای «کلان داده» بهرهمند شوند.
کاهش مسئولیتپذیری و افزایش انعطافپذیری با استفاده از انتزاعها (اوایل دهه دوم قرن بیست و یکم)
همزمان با ظهور و افزایش میزان استفاده از فنآوری ابری با وب سرویسهای آمازون (AWS) در اوایل دهه دوم قرن بیست و یکم، این سؤال برای مردم پیش آمد که چگونه میتوانند حجم کاری هدوپ را بر روی AWS اجرا کنند. AWS تمامی شرایط و ویژگیهای لازم برای اجرای حجمهای کاری تحلیلی را داشت، حجمهای کاری تحلیلی برای مدت زمان کوتاهی اجرا میشدند و سرورها در مدت زمان باقیمانده در یک مرکز داده منتظر باقی میماندند.
با وجود این در آن زمان Hadoop MapReduce تا حد زیادی به سیستم فایل HDFS متکی بود. در آن زمان استفاده از راهکارهای ذخیرهسازی مقیاسپذیر غیر ممکن بود؛ این راهکارها که محصول فنآروی ابری بودند و میتوانستند خوشهها را از رده خارج کنند. چگونه میتوانستیم این حجمکاری را به ابر منتقل کنیم و همزمان با مقیاسپذیر کردن حجم کاری خود هزینهها را کاهش دهیم و از مزایای فضاهای ابری بهرهمند شویم؟ اگر محدودیت عدم استفاده از حافظه را برطرف میکردیم و شرایطی فراهم میکردیم تا دادهها را با مقدار تأخیر کمتری در حافظه نگهداری کنیم چه اتفاقی میافتاد؟ چگونه میتوانیم فرایندهای تکرارپذیر همچون فرایندهای یادگیری ماشین را انجام دهیم؟
Spark ابتدا در سال 2014 با هدف تحقق همین اهداف عرضه شد. مقاله اصلی در سال 2010 منتشر شد. نویسندگان این مقاله متوجه شدند اگر فقط کمی از حافظه استفاده شود عملکرد تا 10 برابر افزایش پیدا میکند و علاوه بر این پیچیدگیهای برنامهنویسی تا حد زیادی کاهش پیدا میکند.
Spark 1.x عملکرد بسیار خوبی در مقیاسبندی و کار کردن با دادهها نداشت. مدل برنامهنویسی Spark 1.x کماکان پیچیده است و برای نوشتن کد به دانش زیادی لازم است. Spark انعطافپذیری زیادی داشت و مجموعهای از مسئولیتها که وجود آنها ضروری نبود را حذف کرد. Spark ابزار نسل دوم و فوقالعاده ای بود و از آن زمان شهرت و محبوبیت آن افزایش چشمگیری داشته است. در ابتدا عملکرد آن نسبت به هدوپ بهتر بود و همزمان با شکلگیری نیازهای جدید، Spark نیز تکامل پیدا کرد.
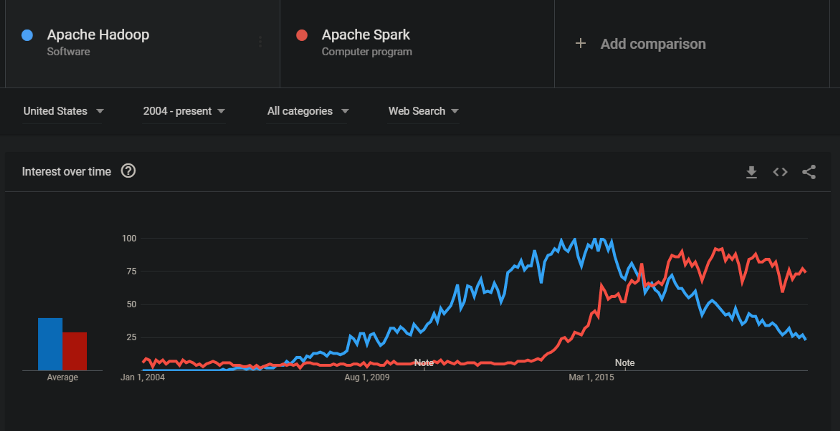
ارتقای تجارب (اواسط دهه دوم قرن بیست و یک)
تا سال 2016 ، Spark به اندازه کافی تکامل یافته بود و به همین دلیل مردم به استفاده از این مدل برنامهنویسی روی آوردند. از افرادی که در زمینه مهندسی نرمافزار تجربه نداشتند خواسته میشد از دادهها خلق ارزش کنند. به همین دلیل حوزه علم داده بر استخراج ارزش از دادهها به روشی علمی متمرکز بود و مسیر پیشرفت و تکامل را در پیش گرفته بود.
Pandas به عنوان ابزاری معرفی شد که همه میتوانند با بهرهگیری از آن با دادهها کار کنند و به همین دلیل شهرت زیادی پیدا کرد. Pandas یک API ساده در اختیار کاربران قرار میداد. این ابزار را وِس مککینی در Two Sigma ساخت؛ هدف از ساخت این ابزار آسان کردن زندگی برای پژوهشگران کمّی بود. این پژوهشگران برای تحلیل دادهها مجبور بودند یک کد را بارها ایجاد کنند. Two Sigma این کتابخانه را به صورت متنباز در آورد و آن را به الگویی برای چگونگی برقراری ارتباط انسانها با دادهها تبدیل کرد.
گروهی که بر روی Spark کار میکردند متوجه شدند که بسیاری از کاربران آنها کارهای اولیه خود را در Pandas انجام میدهند و پس از آنکه ایدههایشان به اندازه کافی پرورش یافت از Spark استفاده میکنند. استفاده جداگانه از این دو ابزار موجب شد بار کاری انسجام نداشته باشد و برای آنکه کد مناسب مدل MapReduce در Spark شود باید آن را دوباره مینوشتند.
Spark به دلیل اینکه کاربران از Pandas استفاده میکردند DataFrame API را اضافه کرد که از Pandas API تقلید میکرد؛ به عبارت دیگر، کاربران Spark میتوانستند از همان بارکاری استفاده کنند اما میبایست آن را در مقابل موتور MapReduce اسپارک اجرا کنند ، در این حالت امکان مقیاسبندی حتی در طول مرحله تحلیل نیز وجود داشت.
علاوه بر کاربرد برنامهای Spark، تعدادی از کاربران آنها تمایل داشتند از SQL برای دسترسی به دادهها استفاده کنند. همانگونه که پیش از این گفتیم، از SQL تقریباً به مدت پنجاه سال برای دسترسی به دادهها استفاده میشود. تیم Spark در آن زمان تصمیم فوقالعادهای گرفتند، آنها تصمیم گرفتند Spark SQL را توانا سازند اما از همان موتور بهینهسازی که برای DataFrame API نوشته بودند، استفاده کند.
استفاده از یک موتور بهینهسازی واحد موجب میشد کدی که مینوشتند رابط SQL و همچنین رابط برنامهای آنها را تحت تأثیر قرار دهد. این موتور بهینهساز Catalyst نامیده میشد و همانند بهینهساز برنامه پرسمان Query plan optimizer در یک RDBMS قدیمی کار میکرد. Spark 2.0 تمامی این قابلیتها را داشت و به همین دلیل کارایی آن تا حد زیادی افزایش یافت.

کاهش مسئولیت با همان میزان انعطافپذیری (2020)
ماه ژوئن سال 2020 جدیدترین و پیشرفتهترین نسخه Spark یعنی Spark 3.0 عرضه شد، این نسخه از Spark قابلیتهای جدیدی ندارد اما عملکرد، قابلیت اطمینان و قابلیت استفاده آن ارتقا پیدا کرده است.
به منظور ارتقای عملکرد، Spark اجرای تطبیقی پرسمان Adaptive query execution
و حذف پویای پارتیشن را اضافه کرده است، هر دوی مواردی که از آنها نام برده شد حتی در حوزه RDBMS نیز پیشرفتهای نسبتاً جدیدی به حساب میآیند. ارتقای عملکرد میتواند مزایای بسیاری به همراه داشته باشد. مطابق با معیارهای TPC-DS، حذف پویای پارتیشن از 60 پرسمان از میان 120 پرسمان بین 2 برابر و 18 برابر ارتقا پیدا میکند.
به عبارت دیگر، اگر شرکتها از Spark استفاده کنند، محاسبات کمتری باید انجام دهند و هزینههای آنها در زمینه زیرساخت کاهش پیدا میکند و بیشتر بر روی نتایج تمرکز میکنند. کاربران به این قابلیتهای جدید واقف هستند و نیازی به بازنویسی کدها وجود ندارد.
برای افزایش قابلیت اطمینان، تیم Spark تعداد قابل توجهی از باگها (3.400) را بین شاخههای 2.x و 3.0 رفع کردند و این امکان را برای کاربران فراهم کردند تا بهتر بتوانند خطاهای پایتون را کنترل کنند تا استفاده از API پایتون آسانتر شود. علاوه بر این، ارتقای عملکرد موجب میشود بدون نیاز به تغییر مدل مسئولیت Spark، انعطافپذیری آن افزایش پیدا کند.
برای افزایش قابلیت استفاده، Spark یک UI جدید برای استفاده در موارد کاربرد جدید ارائه داده است که اطلاعات بیشتری راجع به آمارهای mini batch و به طور کلی وضعیت پایپ لاین ارائه میدهد. در بسیاری از موارد کاربرد، به سختی متوجه میشدیم که چه زمانی سیستم تأخیر دارد و چگونه میتوانیم به نحوی کارامد به این تغییرات از جمله مقیاسبندی گرههای جدید یا مقیاسبندی به منظور کاهش هزینهها واکنش نشان دهیم.
Spark 3.0 بدون کاهش میزان انعطافپذیری، مسئولیت کاربران نهایی را کاهش میدهد و کماکان به پیشرفت و ارتقای این حوزه کمک میکند. این قابلیت Spark به ما کمک میکند چالشهای بیشتری را حل کنیم و تا حد زیادی عملیاتهای خود را ارتقا دهیم و و بر روی کارهای ارزشآفرین تمرکز کنیم.

چالشهای امروز – آینده پیش رو
در این مقاله به بحث و گفتوگو راجع به هدوپ و Spark پرداختیم و سیر تکامل و پیشرفت این حوزه را در طول زمان بررسی کردیم. بیش از 100 ابزار در حوزه «کلان داده» وجود دارد که هر کدام موارد کاربرد خاصی دارند و برای حل مشکلات و مسائل خاصی طراحی شدهاند. اگر به رابطهایی مشابه SQL دادهها در چارچوبهای توزیعشده نگاهی بیندازید، به Hive، Presto و Impala میرسید که هر کدام مسئول حل چالشهای متفاوتی در این حوزه بودهاند. چنانچه به پیاپیسازی داده Data serialization از جمله CSV قدیمی و ناکارآمد علاقهمند هستید تا ذخیرهسازی و مدت زمان محاسبه را کاهش دهید به Avro، Parquet، ORC و Arrow میرسید.
از زمان آغاز چرخه هایپ «کلان داده» در سال 2010، پیشرفتهای زیادی در این حوزه حاصل شده است. در حال حاضر شرکتهایی از جمله آمازون، مایکروسافت و گوگل خدمات ابری ارائه میدهند و قابلیتهایی را ممکن میسازند که پیش از این داشتن آنها در حد رویا بود. فنآوری ابری بر مقیاسپذیری بارکاری متمرکز است. در عوض شما مبلغی مازاد بر ارزش واقعی مرکز داده پرداخت میکنید و نیاز به حفظ و نگهداری جنبههای فنی، عملیاتی، نظارتی و غیره زیرساخت مرکز داده را کاهش میدهید. اگر موارد کاربرد تحلیلی را بررسی کنیم متوجه میشویم که در همه آنها از سختافزار استفاده میشود و به همین دلیل میتوانیم از فنآوری ابری در آنها استفاده کنیم.
ارائهدهندگان خدمات ابری برای بار کاری «کلان داده» فرایند مقیاسبندی عمودی و افقی و کاهش مقیاس را بر روی راهکارهای خود انجام میدهند. برای نمونه میتوان به EMR (آمازون)، Azure Databricks (مایکروسافت) و Dataproc (گوگل) اشاره کرد که هر کدام از این ارائهدهندگان از بار کاری موقتی بر ر روی فضای ابری پیشتیبانی میکنند. این ارائهدهندگان راهکارهایی از جمله ذخیرهسازی اشیا S3، Azure Lake Storage و Google Cloud Storage برای ذخیرهسازی ارائه دادند و انجام محاسبات را به فضای دیگری- به غیر از حافظه- منتقل کردند.
اگر میخواهید تحلیلی انجام دهید، آن را در خوشهای مجزا انجام میدهید بدون اینکه بر روی کارهای در حال اجرای دیگران تأثیر بگذارید. تنظیم دقیق خوشه چالش بسیار بزرگی بود چرا که بارهای کاری مختلف چالشهای عملکردی متفاوتی دارند. با رفع این چالش، متخصصین میتوانند به جای تمرکز بر روی زیرساخت، توجه خود را به تحقق اهداف معطوف کنند.
افزون بر این، ما میخواهیم فشار بر روی کدها را هم کم کنیم. در دنیای امروزی موارد کاربرد لحظهای و بیشماری داریم. پیش از این مجبور بودیم دو کد بیس جداگانه داشته باشیم تا بتوانیم عملکردی درخور هر یک از موارد کاربرد داشته باشیم. پس از مدتی متوجه شدیم که دسته فقط یک مورد خاص اجرا است، پس بهتر نیست روش استفاده از آن را به کار ببندیم؟ Flink، Spark و Beam به روشهای متفاوتی در تلاش هستند تا این مشکل را حل کنند، چه به صورت first-class citizen (Beam) یا با تغییر APIهای خود تا آن را برای کاربران نهایی آسان کنند (Flink\Spark).
در مرکز تمامی این پیشرفت ها نیاز به توانا سازی تحلیلهای پیچیده دیتاستهای حجم بالا احساس میشود. ما باید موارد کاربرد یادگیری ماشین و هوش مصنوعی را برای دادهها آسان کنیم. برای انجام این کار، فقط پردازش دادهها کافی نیست، باید بتوانیم این فرایند را بدون دخالت کاربر نهایی انجام دهیم. استفاده همگانی از ابزارهای هوش مصنوعی و یادگیری ماشین طی بیست سال گذشته با استفاده از scikit-learn، Keras ، Tensorflow، Pytorch، MXNet و تعداد زیادی دیگری از کتابخانهها صورت گرفته است تا امکان مدلسازی آماری و همچنین موارد کاربرد یادگیری عمیق را فراهم سازد. هدف از استفاده از این ابزارها در حوزه کلان داده درس گرفتن از این ابزارها و استفاده مستقیم از آنها است.
منظور از کلان داده چیست؟
دهها میلیون انسان، میلیاردها حسگر، تریلیونها تراکنش اکنون برای ایجاد مقادیر غیرقابل تصور اطلاعات کار میکنند. آیا این حجم از داده را میتوان به روشهای سنتی ذخیره، پردازش و نگهداری نمود؟ بدون شک پاسخ منفی است. در این جاست که بحث کلانداده با نامهای دیگری نظیر بیگ دیتا Big data، دادههای بزرگ و مَهداده مطرح میشود. کلانداده با سه ویژگی اصلی حجم زیاد، سرعت تولید بالا و تنوع زیاد توانسته کسبوکارهای مختلفی را دچار تحول نماید و مرزهای دانش را در زمینههای گوناگون جا به جا کند. در این بخش به معرفی این منبع ارزشمند و فناوریهای مرتبط با آن، انواع کلانداده و کاربردهای آن در حوزههای مختلف اشاره میکنیم. پس با ما همراه باشید.

تعریف کلان داده
کلانداده که معمولا در کنار مفاهیمی نظیر دادهکاوی و یا هوش تجاری شنیده میشود، پیشنیاز اصلی برای انجام تحلیلهای پیشرفته است. به عبارت دیگر کلان داده متشکل از حجم فزایندهای از دادههای متنوع است که با سرعت بسیار بالا تولید میشوند.
به دلیل حجم زیاد و سرعت تولید بالا کلانداده دیگر نمیتوان آن را توسط سختافزارها و نرمافزارهای سنتی پردازش داده مدیریت کرد. این امر باعث شده که بسیاری از افراد و یا سازمانها به طور تخصصی بر روی راهکارهای پردازش کلاندادهها تمرکز نمایند زیرا با وجود چالشهای موجود در نگهداری، پردازش و مدیریت این دادههای وسیع، میتوان به کمک آنها بسیاری از مشکلات تجاری که قبلا مقابله با آنها بسیار دشوار بود را به راحتی حل کرد. در زیر به چند نمونه از اثرات پردازش کلاندادهها و تأثیر حضور آنها در دنیای امروز اشاره میکنیم:
- تعیین علل ریشه ای خرابیها، مسائل و عیوب در لحظه
- تشخیص ناهنجاریها، سریعتر و دقیقتر از چشم انسان
- بهبود نتایج بیمار با تبدیل سریع دادههای تصویر پزشکی به بینش
- محاسبه مجدد کل پرتفوی ریسک در چند دقیقه
- تشدید توانایی مدلهای یادگیری عمیق برای طبقهبندی دقیق و بروز واکنش مناسب به متغیرهای دائما در حال تغییر
کلان داده چه ویژگیهایی باید داشته باشد؟
همانطور که در تعریف کلانداده اشاره شد، این مجموعه از دادهها دارای سه ویژگی اصلی حجم فزاینده (Volume)، تنوع (Variety) و سرعت تولید بالا (Velocity) هستند که اصطلاحا به آنها 3V میگویند که به طور شماتیک در شکل زیر نشان داده شده است:

حجم (Volume): حجم کلانداده از سایز ترابایت تا زتابایت و حتی بیشتر متغیر است.
تنوع (Variety): با توجه به اینکه دادههای موجود در کلاندادهها از منابع مختلفی بوجود میآیند، بنابراین فرمهای مختلفی دارند، از دادههای ساختاری و عددی در پایگاههای داده سنتی گرفته تا اسناد متنی بدون ساختار، ایمیلها، فیلمها، فایلهای صوتی، دادههای مربوط به سهام و تراکنشهای مالی.
سرعت تولید (Velocity): یکی از تفاوتهای اصلی کلاندادهها با مجموعههای سنتی داده، سرعت تولید و ذخیرهسازی آنها است. با رشد اینترنت اشیا، دادهها با سرعت بیسابقهای وارد کسبوکارها میشوند و باید به موقع مدیریت شوند. تگهای RFID، حسگرها و کنتورهای هوشمند نیاز به مقابله با این حجم زیادی از دادهها را در زمان واقعی ایجاد میکنند.
البته لازم به ذکر است، امروزه، دو ویژگیهای دیگری نظیر صحت و ارزش، به این مجموعه 3V به عنوان ویژگیهای اصلی کلاندادهها اضافه شده است که بیشتر بر کیفیت یک کلانداده دلالت میکنند:
صحت (Veracity): دادههای اشتباه و یا غیردقیق به راحتی میتوانند افراد و سازمانها را از مسیر درست و بهینه منحرف کنند. منظور از دادههای اشتباه و یا غیر دقیق، وجود تعصب، ناهنجاریها یا ناسازگاریها، تکثیرها و بی ثباتیها است که میتواند کیفیت یک کلانداده و متعاقبا تحلیلهای برگرفته از آن را به شدت تحت تأثیر قرار دهد.
ارزش (Value): کلانداده زمانی مفید است که پردازش آن ما را به اهدافمان نزدیکتر کند و بینشهایی را فراهم کند تا بتوان در تصمیمگیری از آن استفاده کرد. لزوما نگهداری و ثبت هر دادهای این مشخصات را ندارد. بنابراین یکی از معیارهای کیفی کلانداده ارزش دادههای موجود در آن است.
نمونههایی از کلان داده
در این بخش، به نمونهای از شرکتهایی که با بهرهگیری از کلاندادههای خود توانستند به میزان قابل توجهی پیشرفت کنند اشاره میکنیم تا بتوانیم درک عمیقتری از این مفهوم و اهمیت آن پیدا کنیم.
آمازون
بدون شک یکی از قدرتمندرین شرکتها در زمینه تجارت الکترونیک است که بخشی اعظمی از قدرت خود را مدیون پایگاه داده بزرگش است. این شرکت توانسته به طور مداوم از کلاندادهاش برای بهبود تجربه مشتریان خود استفاده کند، در اینجا تنها به دو مورد از استفاده آمازون از مجموعههای عظیم دادههایش اشاره میکنیم:

- قیمتگذاری پویا
همه میدانند که خطوط هوایی هنگام فروش بلیط هواپیما از تکنیک قیمتگذاری پویا استفاده میکنند، اگر بلیطهای یکسان را بارها و بارها بررسی کنید، احتمالاً به این معنی است که واقعاً آنها را میخواهید و حاضرید برای آنها هزینه بیشتری بپردازید. همین منطق در وب سایت آمازون پیاده سازی شده است. اما چیزی که احتمالاً نمی دانستید این است که آنها قیمتهای خود را تا 2.5 میلیون بار در روز تغییر می دهند. عواملی مانند الگوهای خرید، قیمتهای رقیب و نوع محصول بر این تغییرات قیمت تأثیر میگذارد که همگی با پردازش کلانداده حاصل میگردد.
- پیشنهاد محصول
فرقی نمیکند که شخص محصولات را بخرد، آن را در سبد خرید بگذارد یا حتی فقط نگاهی به آن بیندازد، آمازون از آن دادهها استفاده خواهد کرد. به این ترتیب آنها میتوانند یاد بگیرند که هر مشتری چه چیزی می خواهد و دوست دارد، که همان محصول یا محصولات مشابه را زمانی که مجددا بازگشت به او توصیه کنند. از این طریق آمازون توانسته 35 درصد از فروش سالانه خود را انجام دهد!
مکدونالد
صنعت غذا و روندهای موجود در آن همیشه در حال تغییر هستند و افراد در این زمینه بخواهند در اوج بمانند، باید بتوانند با آنها تغییر کنند و این دقیقا همان کاری است که مک دونالد انجام داده است. با افزایش روند زندگی سالم و استفاده از سفارش آنلاین، خیلی از فست فودها با مشکل مواجه شدند. در این زمان مکدونالد تصمیم گرفت از دادههایی که طی سالها جمعآوری کرده بود، استفاده کند. آنها میخواستند از بازاریابی انبوه به سفارشی سازی انبوه منتقل شوند که برای انجام چنین کاری، باید قفل دادهها را به گونهای باز میکردند که برای مشتریان مفید باشد.

استفاده از کلانداده باعث شد که آنها به منوهای دیجیتالی روی آورند که بر اساس عوامل مختلفی نظیر زمان، آب و هوا و داده های گذشته فروش تغییر میکند. به این ترتیب آنها می توانند به مشتریان خود یک نوشیدنی سرد در یک روز گرم یا شاید یک قهوه همراه با منوی صبحانه در یک روز سرد پیشنهاد دهند.
علت اهمیت کلان داده
اهمیت دادههای بزرگ صرفاً به میزان دادهها بستگی ندارد، بلکه ارزش آنها به نحوه استفاده شما بستگی دارد. با گرفتن دادهها از هر منبع و تجزیه و تحلیل صحیح آن، میتوانید به موارد زیر به راحتی دست پیدا کنید:

- تصمیمگیری سریعتر و بهتر
کسبوکارها میتوانند به حجم زیادی از دادهها دسترسی داشته باشند و منابع متنوعی از دادهها را تجزیه و تحلیل کنند تا بینش جدیدی به دست آورند و اقدامی مناسب انجام دهند.
- کاهش هزینه و افزایش بهرهوری عملیاتی
ابزارهای انعطافپذیر پردازش و ذخیرهسازی دادهها نظیر سرورهای ابری میتوانند به سازمانها در صرفهجویی هزینهها در ذخیرهسازی و تجزیه و تحلیل مقادیر زیادی از داده کمک کنند تا بتوان از طریق آنها الگوهای نهفته و بینشها را کشف کرد و کسب و کار کارآمدتری را ایجاد نمود.
- بهبود ورود آگاهانه به بازار
تجزیه و تحلیل دادهها از حسگرها، دوربینها، گزارشها، برنامههای کاربردی تراکنش، وب و رسانههای اجتماعی، سازمان را قادر میسازد که داده محور باشد و بتواند نیازهای مشتری و ریسک های بالقوه را اندازه گیری کند و آگاهانه محصولات و خدمات جدید ایجاد و ارائه نماید.
انواع کلان داده
کلانداده را میتوان با توجه به نوع دادههایی که در خود ذخیره میکند به سه دسته کلی زیر تقسیمبندی کرد:
ساختاریافته: هر دادهای که بتوان آن را به طور مستقیم پردازش و به آن دسترسی پیدا کرد و به صورت یک فرمت ثابت ذخیره نمود، داده ساختاریافته نامیده می شود که در جدول زیر نمونهای از این نوع داده نشان داده شده است. در طول برههای از زمان، به دلیل توانایی در مهندسی نرمافزار، در ایجاد تکنیکهایی برای کار با این نوع دادهها پیشرفتهای چشمگیری ایجاد گردید. با این حال، با افزایش چشمگیر حجم دادهها در کلاندادهها، پردازش این نوع از دادهها با چالشهایی همراه بوده است. با این وجود، مشکلات پردازش کلاندادههای ساختار یافته به نسبت پردازش دادههای ساختار نیافته کمتر است.

ساختار نیافته: کلان داده ساختارنیافته شامل تعداد زیادی از دادههای بدون ساختار نظیر فایلهای تصویری، صوتی، متنی و فایلهای ویدئویی است. هر دادهای که دارای ساختار یا مدل ناآشنا باشد به عنوان داده بدون ساختار در نظر گرفته میشود. تعداد این نوع از دادهها بسیار زیاد میباشد به همین دلیل این نوع از کلانداده از اهمیت بسزایی برخوردار است. با این حال با توجه به نیاز به آمادهسازی این نوع از دادهها جهت پردازش، مشکلات متفاوتی در بهرهبرداری از آنها وجود دارد.
نیمه ساختار یافته: کلانداده نیمه ساختاریافته همانطور که از نامش نیز مشخص است متشکل از دادههای ساختاریافته و ساختارنیافته است. این نوع از کلاندادهها به طور خاص به دادههایی اشاره میکنند که با وجود اینکه در قالب یک پایگاه داده مشخص قرار نگرفته باشند، اما حاوی برچسبها و یا اطلاعات ضروری هستندکه اجزای منفرد را در داخل دادهها جدا میکند.

منابع اصلی دسترسی به کلان داده
دادههای موجود در کلاندادهها از منابع مختلفی بدست میآیند که در این بخش به اصلیترین آنها اشاره میگردد:
- دادههای جریانی (Streaming data) از اینترنت اشیا (IoT) و سایر دستگاههای متصل به سیستمهای فناوری اطلاعات از دادههای مکانی افراد، ابزارهای پوشیدنی، خودروهای هوشمند، دستگاههای پزشکی، تجهیزات صنعتی و غیره بدست میآیند. شما میتوانید این کلانداده را به محض رسیدن تجزیه و تحلیل کنید، تصمیم بگیرید که کدام داده را نگه دارید یا نه، و کدام یک نیاز به تجزیه و تحلیل بیشتری دارد.
- دادههای موجود در سایتها و رسانههای اجتماعی که ناشی از تعاملات بین افراد در فیسبوک، یوتیوب، اینستاگرام و غیره میباشند. این دادهها در قالبهای تصویر، ویدیو، صدا، متن و صدا جمعآوری میشوند که برای عملکردهای بازاریابی، فروش و پشتیبانی مفید هستند. این کلاندادهها اغلب به شکلهای بدون ساختار یا نیمه ساختار یافته هستند، بنابراین چالشهایی منحصر به فرد برای بهرهبرداری و تحلیل آنها وجود دارد.
- دادههای در دسترس عموم از حجم عظیمی از منابع داده باز مانند مرکز آمار ایران، data.gov دولت ایالات متحده و یا پورتال داده باز اتحادیه اروپا به دست میآیند.
- سایر کلان دادهها که ممکن است از دریاچههای داده (Data Lake)، منابع دادههای ابری، تأمینکنندگان و مشتریان به دست آیند.
فناوریهای کلانداده
معماری کلان داده
همانند معماری در ساخت و ساز ساختمان، معماری کلانداده نیز طرحی برای ساختار اساسی نحوه مدیریت و تجزیه و تحلیل دادههای کسب و کارها ارائه میدهد. معماری کلانداده فرآیندهای لازم برای مدیریت کلان داده را در چهار “لایه” اساسی، از منابع داده، تا ذخیره سازیداده، سپس به تجزیه و تحلیل دادههای بزرگ و در نهایت لایه مصرف که در آن نتایج تجزیه و تحلیل انجام شده در قالب هوش تجاری ارائه میشود، ترسیم میکند.
کلانداده و Apache Hadoop
10 سکه در یک جعبه بزرگ را با 100 نیکل در نظر بگیرد. حال 10 جعبه کوچکتر را در کنار هم، هر کدام با 10 نیکل و فقط یک سکه تصویر کنید. در کدام سناریو تشخیص سکهها آسانتر خواهد بود؟
Hadoop اساساً بر اساس این اصل کار میکند و به عنوان یک چارچوب منبع باز برای مدیریت پردازش دادههای بزرگ توزیع شده در شبکهای از تعداد زیادی رایانههای متصل مورد استفاده قرار میگیرد. بنابراین به جای استفاده از یک کامپیوتر بزرگ برای ذخیره و پردازش تمام دادهها، Hadoop چندین کامپیوتر را در یک شبکه تقریبا بینهایت و مقیاسپذیر، خوشهبندی کرده و دادهها را به صورت موازی تجزیه و تحلیل میکند. این فرآیند معمولاً از یک مدل برنامهنویسی به نام MapReduce بهره میگیرد که پردازش کلانداده را با تجمیع رایانههای توزیع شده میسر میکند.
دریاچه داده، انبار داده و NoSQL
پایگاه دادههای سنتی به سبک صفحه گسترده SQL برای ذخیرهسازی دادههای ساختاریافته مناسب است. کلانداده ساختار نیافته و نیمه ساختاریافته به پارادایمهای ذخیرهسازی و پردازش متفاوتی نیاز دارد، زیرا ایندکسگذاری و یا طبقه بندی نشدهاند. دریاچههای داده، انبارهای داده و پایگاه های داده NoSQL همگی مخازن دادهای هستند که مجموعههای داده بدون ساختار و یا نیمهساختاری را مدیریت میکنند. دریاچه داده مجموعه وسیعی از دادههای خام است که هنوز پردازش نشده است. انبار داده مخزنی برای دادههایی است که قبلاً برای هدف خاصی پردازش شدهاند.
پایگاههای داده NoSQL طرحی انعطافپذیر ارائه میکنند که میتوانند متناسب با ماهیت دادههای مورد پردازش اصلاح شوند. هر یک از این سیستمها نقاط قوت و ضعف خود را دارند و بسیاری از کسب و کارها از ترکیبی از این مخازن دادهای مختلف استفاده میکنند تا به بهترین نحو با نیازهای خود مطابقت داشته باشند.

پایگاه داده In-memory
پایگاه دادههای سنتی مبتنی بر دیسک با در نظر گرفتن فناوریهای SQL و پایگاه داده رابطهای توسعه یافته اند. این نوع از پایگاه دادهها ممکن است بتوانند حجم زیادی از دادههای ساختاریافته را مدیریت کنند، اما برای ذخیره و پردازش دادههای بدون ساختار مناسب نیستند. برخلاف نیاز به بازیابی دادهها از یک سیستم مبتنی بر دیسک، در پایگاه دادههای In-memory، پردازش و تجزیه و تحلیل به طور کامل در RAM انجام میشود. پایگاههای داده درون حافظه نیز بر اساس معماریهای توزیع شده ساخته شدهاند. به عبارت دیگر، آنها میتوانند با استفاده از پردازش موازی، بر خلاف مدلهای پایگاه داده مبتنی بر دیسک تکگرهای، به سرعتهای بسیار بیشتری دست یابند.
کلان داده در رایانش ابری
پردازش کلانداده بر پایه رایانش ابری نقطه مقابل ذخیرهسازی محلی بر روی وسایل الکترونیکی با کامپیوترهاست. شرکتهای ارائه دهنده خدمات رایانش ابری مسئولیت سرورها، ذخیرهسازی، منابع محاسباتی، پایگاه داده، شبکه و نرمافزارها را برعهده میگیرند و شما تنها از طریق اینترنت میتوانید بنا به نیاز خود از این قابلیتها استفاده کنید بدون اینکه نگران جزئیات فنی آن باشید.
رایانش ابری توانسته یک تغییر اساسی در مصرف داده، ارائه خدمات و همکاری در سطح سازمانی ایجاد کند. سرویسهای ابری با ارائه مقرون به صرفه دسترسی سریعتر به دادهها، ذخیرهسازی تطبیقی، زیرساخت، پلتفرم، نرم افزار و منابع پردازشی، چابکی و کشش را به میزان قابل توجهی افزایش میدهد. میتوانید از رایانش ابری برای خودکارسازی بسیاری از این مؤلفهها در زمینه کلانداده نیز استفاده کنید.
این امر فرآیندها را ساده میکند و تلاشهای شما را سریعتر به نتیجه میرساند. معمولا سازمانهایی که در همان ابتدای استفاده از کلانداده سراغ رایانش ابری نمیروند، بعد از مدتی پشیمان خواهد شد زیرا با توجه به ماهیت حجم بالا و تولید سریع دادهها در کلانداده در بیشتر اوقات با محدودیتهای ذخیرهسازی و پردازشی مواجه میشوند.
کلاندادهها چگونه کار میکنند؟
پیش از آنکه هر کسبوکاری بتواند از فناوری بیگ دیتا به نحو احسن استفاده کند، لازم است نحوه جریان آن را در میان تعداد زیادی از مکانها، منابع، سیستمها، مالکان و کاربران بررسی کنند. به طور کلی سه مرحله کلیدی جهت بهرهمندی از قدرت بیگدیتا برای هر سازمان وجود دارد که به شرح زیر میباشد:

جمعآوری داده
همانطور که در قسمت «منابع اصلی دسترسی به کلانداده» اشاره شد؛ بسیاری از دادههای بزرگ از مجموعههای عظیمی از دادههای بدون ساختار تشکیل شده که از منابع متفاوت و متناقضی دریافت میشوند. پایگاه دادههای سنتی مبتنی بر دیسک و مکانیسمهای یکپارچهسازی دادهها به درستی نتوانستند با مدیریت این موضوع کنار بیایند. مدیریت کلانداده مستلزم اتخاذ راهحلهای پایگاه داده In-memory و راهحلهای نرمافزاری خاص برای کسب دادههای بزرگ است.
دسترسی، مدیریت و ذخیره کلاندادهها
سیستمهای محاسباتی مدرن سرعت، قدرت و انعطافپذیری لازم برای دسترسی سریع به مقادیر و انواع عظیم دادههای بزرگ را فراهم میکنند. در کنار دسترسی مطمئن، شرکتها همچنین به روشهایی برای یکپارچهسازی دادهها، ایجاد خطوط لوله داده، اطمینان از کیفیت دادهها، ارائه حاکمیت و ذخیرهسازی دادهها و آمادهسازی آنها برای تجزیه و تحلیل نیاز دارند. برخی از کلاندادهها ممکن است در محل در یک انبار داده سنتی ذخیره شوند. با این حال، بیگدیتا زمانی بهترین عملکرد را دارد که محدودیت اندازه و حافظه نداشته باشد، بنابراین میتوان به گزینههای انعطافپذیر و کمهزینهای برای ذخیره و مدیریت دادههای بزرگ از طریق راهحلهای ابری، دریاچههای داده، خطوط لوله داده و Hadoop روی آورد.
پردازش کلان داده
سازمانها با فناوریهایی با کارایی بالا مانند محاسبات شبکهای یا تجزیه و تحلیل درون حافظهای، میتوانند انتخاب کنند که از کل دادههای خود برای تجزیه و تحلیل استفاده کنند و یا قبل از تجزیه و تحلیل، مشخص کنند کدام دادهها برای هدف در پیش گرفتهاشان مناسب است. در هر صورت، تجزیه و تحلیل کلان داده نحوه کسب ارزش و بینش شرکتها از دادهها است. دادههای بزرگ به طور فزایندهای، فناوریهای تحلیلی پیشرفته امروزی مانند هوش مصنوعی (AI) و یادگیری ماشین را تغذیه میکنند.
چه سازمانها و ارگانهایی از بیگدیتا استفاده میکنند؟
باید این موضوع را قبول کنیم دیگر روشهای سنتی مدیریت کسب و کار همراه با سعی و خطای فراوان، پاسخگوی نیاز بازار رقابتی امروز نخواهد بود. با توجه به رشد روزافزون فناوریهای نوینی مانند کلاندادهها، هوش مصنوعی، اینترنت اشیا و غیره، انجام اشتباهات مکرر و عدم توجه به دادههای موجود در آن صنعت تنها میتواند آن کسب و کار را به منجلاب برشکستگی ببرد. بنابراین دادهها همچون سایر منابع یک سازمان باید در حفظ و مدیریت آنها کوشا بود.
اما همانطور که بارها به آن اشاره شد لزوما حجم مقدار داده جمعآوری شده نمیتواند به تنهایی مفید باشد، بلکه تجزیه و تحلیل آن است که بینشهای ارزشمند را به مدیران و صاحبان کسبوکارها ارائه میدهد. با اشاره به برخی از کاربردهای کلان داده در صنایع مختلف در بخش آتی متوجه خواهید شد، کلان داده برای هر نوع سازمانی صرف نظر از نوع فعالیتهایی که انجام میدهند، میتواند مفید و ارزشمند باشد.
کاربردهای کلان داده
کاربرد کلان داده در دیجیتال مارکتینگ
یکی از زمینههای که کلاندادهها اثرات ارزشمند خود را به اثبات رساندهاند، حوزه دیجیتال مارکتینگ و تجارت الکترونیک است. از جمله مزایایی ارزشمند کلاندادهها در این صنعت میتوان به موارد زیر اشاره کرد:
– طراحی کمپینهای بازاریابی بهتر بواسطه شناخت نیازهای مشتریان و هدفگذاری مناسب
– اتخاذ تصمیمات بهتر برای قیمتگذاری به دلیل تجزیه و تحلیل در لحظه بازار
– طراحی بهینه محتویات سایتها با توجه به مطالعه رفتار افراد در حین مراجعه به سایت
به بیان کلیتر، به کمک کلانداده میتوان مشتریان، نظرات و احساساتشان را شناخت و آنها را طبقهبندی نمود، ترندهای موجود در بازار را شناسایی کرد و عملکرد رقیبان در این زمینه را تجزیه و تحلیل کرد.

کلان داده در بانکداری
در مجله “Big Data”، یک مطالعه در سال 2020 اشاره کرده است که کلانداده نقش مهمی در تغییر بخش خدمات مالی، به ویژه در تجارت و سرمایهگذاری، اصلاحات مالیاتی، کشف و بررسی تقلب، تجزیه و تحلیل ریسک و اتوماسیون ایفا کردهاند. همچنین به کمک تجزیه و تحلیل دادههای مربوط به مشتریان و بازخوردهایشان میتوان به بینش ارزشمندی جهت بهبود رضایت و تجربه مشتری در صنعت مالی دست یافت.
از طرف دیگر، روزانه دادههای تراکنشی زیادی تولید میشوند که یکی از سریعترین و بزرگترین کلاندادهها را در جهان تشکیل میدهد. پذیرش روزافزون راهحلهای پیشرفته مدیریت کلاندادهها به بانکها و مؤسسات مالی کمک میکند که از این دادهها محافظت کنند و از آنها در راههایی استفاده کنند که هم از مشتری و هم از کسبوکار بتوانند به خوبی در مقابل راههای کلاهبرداری و تقلب محافظت نمایند.
کلان داده در پزشکی
تجزیه و تحلیل کلان داده به متخصصان حوزه پزشکی و سلامت اجازه میدهد تا تشخیصهای دقیقتر و مبتنی بر شواهد را انجام دهند. از طرف دیگر هر فرد میتواند با دریافت توصیههای پزشکی شخصیسازی شده از بروز و یا گسترش بیماری جلوگیری کند. بیگ دیتا به مدیران بیمارستانها نیز کمک میکند تا روندها را شناسایی کنند، خطرات را مدیریت کنند و هزینههای غیرضروری را به حداقل برسانند تا بتوانند بیشترین مقدار بودجه را به حوزههای مراقبت و تحقیق از بیمار هدایت کنند.
تمامی این موارد با استفاده از فناوریهای mHealth، eHealth، ابزارهای پوشیدنی میسر میگردد. کلاندادههای پزشکی شامل دادههای پرونده الکترونیکی سلامت، دادههای تصویربرداری، اطلاعات مربوط به هر بیمار و دادههای حسگر میباشند که در حال حاضر کنترل دقت، باورپذیری و مدیریت آنها از مهمترین چالشها در این زمینه محسوب میشود.
در بحبوحه همهگیری کرونا، دانشمندان در سراسر جهان به دنبال راههای بهتری برای درمان و مدیریت ویروس کووید 19 بودهاند که کلاندادهها در این فرایند نقش بسزایی ایفا کرد. مقالهای در جولای 2020 در ژرونال The Scientist توضیح میدهد که چگونه تیمهای پزشکی قادر به همکاری و تجزیه و تحلیل دادههای بزرگ برای مبارزه با ویروس کرونا بودند: «ما روش انجام علم بالینی را تغییر دادهایم و از ابزارها، منابع کلان داده و علم دادهها به روشهایی استفاده کردیم که بیش از این ممکن نبود.»
کلان داده در سازمانهای دولتی

استفاده و پذیرش کلان داده در فرآیندهای دولتی عملکرد را از نظر هزینه، بهرهوری و نوآوری به میزان قابل توجهی افزایش میدهد، اما بدون نقص نیست. تجزیه و تحلیل دادهها اغلب به بخشهای متعدد دولت (مرکزی و محلی) نیاز دارند تا با همکاری یکدیگر کار کنند و فرآیندهای جدید و نوآورانهای را برای ارائه نتیجه مطلوب ایجاد کنند.
یک سازمان دولتی رایج که از دادههای بزرگ استفاده میکند، وزارت اطلاعات است که فعالیتهای اینترنت را بهطور مداوم بر اساس الگوهای بالقوه فعالیتهای مشکوک یا غیرقانونی، رصد میکند. سازمان مدیریت بحران نمونه دیگری است که با دریافت اطلاعات از منابع مختلف و تجزیه و تحلیل آنها میتواند خدمترسانی به مردم آسبدیده را بهبود بخشد و فرایند اطلاعرسانی را تسریع ببخشد.
کاربرد کلانداده در آموزش
کلانداده در زمینه آموزش به عنوان بستری برای آموزش و تربیت نسلهای آینده توانسته بسیار مثمرثمر واقع شود. یکی از اثربخشترین تأثیرات این فناوری، فراهم نمودن آموزش شخصیسازی شده برای محصلین بوده که با جمعآوری دادههای مربوط به هر فرد و تجزیه و تحلیل آن میتوان الگوی مناسب یادگیری را برای آن شخص پیدا نمود. این امر باعث شکوفایی استعدادها، پویایی محیط آموزش و جلوگیری از دلزدگی و ناامیدی شده است.
در طول همهگیری کرونا، تأثیر استفاده از کلانداده بسیار ملموستر از گذشته به چشم آمد. در این دوران، موسسات آموزشی در سراسر جهان مجبور شدند برنامههای درسی و روشهای آموزشی خود را برای حمایت از یادگیری از راه دور ابداع کنند. یکی از چالشهای اصلی این فرآیند، یافتن راههای قابل اعتماد برای تحلیل و ارزیابی عملکرد دانشآموزان و اثربخشی کلی روشهای تدریس آنلاین بود.
مقالهای در سال 2020 در مورد تأثیر کلان داده بر آموزش و یادگیری آنلاین بیان کرده که کلان داده باعث شد، سیستمهای آموزشی بتوانند در شخصیسازی آموزش و توسعه یادگیری تطبیقی، تغییر سیستمهای ارزیابی و ترویج یادگیری مادام العمر، اعتماد به نفس بیشتری داشته باشند.
آموزش کلان داده
کلان داده زمینه وسیعی است و برای کسانی که میخواهند کسب مهارت و تخصص در این حوزه را آغاز کنند ممکن است اندکی طاقتفرسا باشد. البته لازم به ذکر است که نقشهایی که در این حوزه نیز مطرح میشوند نیز بسیار مهم هستند که به طور کلی به دو نقش اصلی مهندس داده و تحلیلگر داده تقسیمبندی میشوند. این دو حوزه به هم وابسته ولی از یکدیگر متمایز هستند.

مهندسی کلان داده حول طراحی، استقرار، کسب و نگهداری (ذخیره) حجم زیادی از دادهها میچرخد. در حالی که تحلیلگران دادههای بزرگ حول مفهوم استفاده و پردازش مقادیر زیادی داده تمرکز دارند. تجزیه و تحلیل دادههای بزرگ شامل تجزیه و تحلیل روندها، الگوها و توسعه سیستمهای طبقهبندی و پیشبینی است. بنابراین، به طور خلاصه، تحلیلگر کلانداده به محاسبات پیشرفته بر روی دادهها میپردازد، در حالی که مهندسی کلانداده بر روی طراحی و استقرار سیستمها و تنظیماتی تمرکز میکند که محاسبات باید درون آنها انجام شود.
به طور کلی پنج موضوع اصلی لازم است جهت آموزش کلان داده به ویژه برای مهندسین کلانداده مورد مطالعه قرار گیرد:
- آشنایی با مفاهیم کلانداده، انواع پایگاه داده (رابطهای، NoSQL و غیره) و سیستمهای ذخیرهسازی توزیع شده
- انواع پردازشها اعم از توزیع شده و موازی
- آشنایی با نحوه کار و تسلط بر اکوسیستم Hadoop
- پردازش با پردازش و تحلیل دادهها توسط Spark
- آشنایی با کلان داده در رایانش ابری
در این راستا دورههای آموزشی و کتابهای زیادی در این زمینه وجود دارد که در ادامه به برخی از آنها اشاره میگردد:
کتابهای کلان داده
– کتاب “Big Data: A Revolution That Will Transform How We Live, Work, and Think” نوشته V. Mayer-Schönberger و K. Cukier و منتشر شده در سال 2014

– کتاب “”Hadoop: The Definitive Guide نوشته Tom White و منتشر شده در سال 2009

– کتاب”Python for Data Analysis: Data Wrangling with Pandas, NumPy, and IPython” نوشته W. McKinney و منتشر شده در سال 2011

– کتاب ” Practical Data Science with R” نوشته N. Zumel و J. Mount و منتشر شده در سال 2014
کلان داده در ایران
کلانداده در ایران نیز مانند سایر کشورهای جهان ارزش خود را با اثبات رسانیده است هرچند که با سرعت آهسته روند صعودی خود را طی میکند . این امر را میتوان از گزارش تهیه شده توسط وزارت اطلاعات و فناوری اطلاعات با عنوان «نخستین پیمایش کلان دادهها در سراسر کشور» کاملا حس کرد که با هدف شناسایی وضعیت موجود و نیز چالشهای توسعه کلان داده در کشور تهیه گردیده است. مشاهدات و یافتههای این پیمایش از جوانب مختلف به شرح زیر مورد بررسی قرار گرفت:
- برنامهریزی و سیاستگذاری
- نوآوری و فناوری
- توسعه خدمات و بازار
- زیرساخت های انتقال، ذخیرهسازی و تحلیل
- کسب و کار و اقتصاد
- حقوقی و قانونی

جهت آشنایی با شرکتهای فعال در زمینه کلانداده میتوانید به «شرکتهای فعال در حوزه دادهکاوی در ایران» مراجعه کنید. البته لازم به ذکر است این شرکتها به طور تخصصی در زمینه طراحی و توسعه زیرساختها و پایگاهداده، استخراج دانش از دادههای سازمانها از طریق روشهای ترکیبی با هوش مصنوعی و یادگیری ماشین، حفظ امنیت و یا به طور کلی مدیریت دادهها کار میکنند.
شرکتهایی مانند دیجیکالا ( فعال در زمینه تجارت الکترونیک) و یا نشان (فعال در زمینه حملو نقل و مسیریابی) که از این خدمات استفاده میکنند در این لیست جای نمیگیرند. همچنین در دیدهبان هوش مصنوعی گزارشهای تحلیل از آخرین وضعیت شرکتهای فعال در زمینه کلانداده نیز جای گرفته است که برای مطالعه و بررسی آن میتوانید به این لینک مراجعه نمایید.
آینده کلان داده
کلان داده با قابلیتهای گستردهای که میتواند برای یک کسب و کار ایجاد نماید خود را تبدیل به یکی از منابع بسیار با ارزش کرده که استفاده بهینه از آن برای ادامه حیات هر سازمانی در این عرصه رقابتی امروز ضروری است. سازمانها به کمک فناوری کلانداده میتوانند از گذشته درس بگیرند، و رفتارهای آینده مشتریان خود را پیشبینی کنند. همچنین به کمک این فناوری میتوان به گسترش دانش در زمینههای مختلف بسیار امیدوار بود. اما با وجود مزایای بیشماری که کلان دادهها میتوانند برای سازمانها داشته باشند، چالشهایی را نیز به همراه دارند.
امنیت دادهها یکی از هراسهای اخلاقی است که هر سازمان را ممکن است در استفاده از کلانداده دچار مشکل نماید. دادههای جمعآوری شده در کلانداده به مرور تبدیل به یکی از هویتهای اصلی آن سازمان میشوند که به همان میزانی که میتوانند سودآور باشند، اگر در معرض حملات سایبری قرار گیرند به همان میزان و یا شاید بیشتر میتوانند آسیبرسان باشند.
همچنین با توجه به رشد نمایی این دادهها، به خصوص دادههای ساختار نیافته؛ جهت ذخیره، پردازش و مدیریت آنها نیاز به سختافزارها و نرمافزارهای قویتر از آنچه که امروز وجود دارد، حس میشود. در حال حاضر دانشمندان داده 50 تا 80 درصد از زمان خود را صرف نگهداری و آمادهسازی داده ها پیش از استفاده میکنند که مقدار قابل توجهی است. میتوان خیلی خلاصه گفت که همگام بودن با فناوری کلانداده، خود یک چالش مداوم است!





