
یادگیری انتقالی در پردازش زبان طبیعی – بخش اول
 تیم تحریریه
تیم تحریریه- ۸ خرداد ۱۴۰۱
به اولین بخش از پردازش زبان طبیعی مدرن خوش آمدید. پردازش زبان طبیعی پیشرفت سریع خود را مرهون انتقال یادگیری است و به همین دلیل پیش از هر چیز به معرفی یادگیری انتقالی میپردازیم.
پردازش زبان طبیعی ابزار قدرتمندی است، اما در دنیای واقعی گاهی به مسائلی بر میخوریم که حجم دادههای موجود برای حل آنها کم است و مدل هم در امر تعمیمدهی ضعیف عمل میکند. یادگیری انتقالی برای حل این مشکل به کمک ما آمده و با اتکا به این تکنیک میتوانیم از مدلی که از قبل برای حل مسئله دیگری آموزش دیده استفاده کرده و آن را به مسائل دیگر تعمیم دهیم.
یادگیری انتقالی نقطه اتکای مدلهای زبانی، از جمله ELMo و BERT، است. این مدلها در حل مسائل downstream به کار گرفته میشوند. در ابتدای این فصل به معرفی انواع تکنیکهای یادگیری انتقالی میپردازیم و سپس به شما نشان میدهیم چگونه میتوان از این تکنیکها برای انتقال دانش به مسائل، زبانها و حوزههای دیگر استفاده کرد.
موضوعاتی که در این فصل پوشش میدهیم، عبارتند از:
- یادگیری انتقالی
- انواع یادگیری انتقالی
- تطبیق دامنه Domain adaptation
- یادگیری بینازبانی
- یادگیری چندمسئلهای Multi-task learning
- تطبیق
- تنظیم یا عدم تنظیم
یادگیری انتقالی
تلاشهای گستردهای که در امر جمعآوری داده ها صورت میگیرد، موجب شده در انجام مسائل گوناگون از جمله تشخیص گفتار، درک ماشینی، تشخیص اشیا و ترجمه ماشینی به نتایج شگفتی دست پیدا کنیم. برای آموزش این مدلهای عظیم به حجم بالایی از دادهها، دادههای برچسبگذاری شده، نیاز داریم.
بیشتر مواقع دیتاستهای مورد استفاده برای آموزش یک مدل، در جامعه هدف متفاوتی مورد استفاده قرار میگیرند ( عدم تطبیق جامعه مبدأ و جامعه هدف). برای مثال دیتاستهایی که با هدف آموزش یک سیستم تشخیص گفتار در ایالات متحده جمعآوری شدهاند، در هند مورد استفاده قرار میگیرند.
طی چندین سال گذشته طریقه ساخت مدل یادگیری ماشین برای دادههای صوتی، تصویری و متنی و همچنین آموزششان بر روی حجم بالایی از دادهها را یاد گرفتهایم. متأسفانه اگر مدلی را بر روی دیتاستی آموزش دهیم و بخواهیم از آن برای دیتاست دیگری استفاده کنیم، عملکرد مدل تضعیف میشود. دلیل وقوع چنین اتفاقی این است که مدل نمیتواند تعمیم دهد و الگوهای موجود در دادهها را درک کند. وجود کمترین تفاوتی میان دیتاست مبدا و هدف میتواند عملکرد مدل را با مشکل مواجه کند.
- با توجه به اینکه دادههای دنیای واقعی بهطور مداوم در حال تغییر هستند و آموزش مجدد مدلها برای حل مسائل جدید کار دشواری است، باید راهحلی برای رفع این مشکل پیدا کنیم. و اینجا است که یادگیری انتقالی به کمک ما میآید.
فرض کنید قرار است تکنیک تحلیل احساسات Sentiment analysis را بر روی اخبار بازار سهام هند اجرا کنیم. برای انجام این کار به اندازه کافی داده برچسبگذاری شده داریم و مدل را آموزش میدهیم. اگر از این مدل برای انجام کاری در همان حوزه استفاده کنیم، به نتایج قابل قبولی دست پیدا میکنیم. اما اگر از این مدل برای انجام همان کار (تحلیل احساسات) در حوزهای متفاوت، برای مثال رمزارزها، استفاده کنیم، مدل عملکرد خوبی نخواهد داشت.
در صورتی که بخواهیم مدل را به شیوه یادگیری با نظارت آموزش دهیم، باید دادههای برچسبگذاری شده مربوط به اخبار رمزارزها را جمعآوری کرده و مدل جدیدی آموزش دهیم.
اما اگر به اندازه کافی داده برچسبگذاری شده نداشته باشیم و یا توانایی مالی جمعآوری چنین دادههایی را نداشته باشیم چه؟ بهتر نیست از همان مدل قدیمی استفاده کنیم و آن را بر روی همان حجم کم از دادههای برچسبگذاری شده رمزارزها آموزش دهیم؟
فرض کنید میخواهیم یک کلاس پیشبینی دیگر، برای مثال خنثی، به مدل اضافه کنیم و این در حالی است که مدل قبلی آموزش دیده که فقط کلاسهای مثبت و منفی را پیشبینی کند، در این حالت چه مشکلاتی ممکن است پیش بیاید؟ به کمک یادگیری انتقالی میتوانیم مشکلاتی که در این مسیر وجود دارد را رفع کرده و از دانشی که بر مبنای مسئله/ حوزه قبلی به دست آمده برای حل یک مسئله جدید استفاده کنیم.
برای درک بهتر یادگیری انتقالی، فرض کنید دامنه مبدأ Ds ، مسئله مبدأ Ts، دامنه هدف Dt و مسئله هدف Tt است، هدف یادگیری انتقالی این است که با استفاده از اطلاعات به دست آمده از Ds و در صورتیکه Ds≠Dt یا Ts≠Tt، امکان یادگیری توزیع احتمالی شرطی P(Yt|Xt) در Dt را برای ما فراهم کند.
بیشتر مواقع تعداد کمی نمونههای برچسبگذاریشده هدف در اختیار داریم؛ بهطور کلی تعداد این دادهها نسبت به نمونههای برچسبگذاری مبدأ کم است.
نمودار پایین فرایند یادگیری انتقالی را نشان میدهد:

انواع یادگیری انتقالی
- تطبیق دامنه
- یادگیری بینازبانی
- یادگیری چندمسئلهای
- یادگیری انتقالی متوالی
با توجه به دامنه و مسئله، مشکلات متعددی وجود دارد که با استفاده از یادگیری انتقالی میتوانیم آنها را حل کنیم:
- Xs ≠ Xt : فضای ویژگی مبدأ و مقصد با هم متفاوت است.نمونه این که لغات تخصصی بازار سهام و بازار رمزارزها با هم تفاوت دارند. برای مثال لغت عرضه اولیه سکه (ICO) که مختص بازار رمزارزها است هیچگاه در بازار سهام مورد استفاده قرار نمیگیرد. در ضمن اگر زبانها هم با یکدیگر تفاوت داشته باشند، فضای ویژگی مبدأ و مقصد با هم تطابق نخواهد داشت. به این حالت یادگیری بینازبانی یا تطبیق بیانزبانی گفته میشود.
- Ps(Xs) ≠ Pt (Xt) : توزیع احتمال حاشیهای Marginal probability distribution لغات مبدأ و مقصد متفاوت است. واژه ledger اغلب در بازار رمزارزها استفاده میشود و به ندرت در بازار سهام مورد استفاده قرار میگیرد. به این حالت تطبیق دامنه گفته میشود.
- Ys ≠ Yt : برچسبهای مبدأ و مقصد با یکدیگر تفاوت دارند. دامنه مبدأ برچسبهای مثبت و منفی دارد اما دامنه مقصد علاوه بر برچسب مثبت و منفی، برچسب خنثی هم دارد.
- Ps(Ys) ≠ Pt(Yt): توزیع احتمال حاشیهای برچسبهای مبدأ و مقصد با هم متفاوت است. در طول فرایند آموزش تعداد برچسبهای مثبت بیشتر از برچسبهای منفی است اما اگر بازار سقوط کند، دادههای واقعی برچسبهای منفی بیشتری نسبت به برچسب مثبت خواهند داشت.
- Ps(Ys|Xs) ≠ Pt(Yt|Xt): توزیع احتمال شرطی Condition probability distribution برچسبها متفاوت است. چنانچه یک کلمه واحد معانی متعددی داشته باشد و یا عدم توازن دادهها در مبدأ و مقصد متفاوت باشد، چنین اتفاقی روی میدهد. برای مثال واژه cold storage در بازار رمزارزها معنای کاملاً متفاوتی دارد.
اکنون انواع یادگیری انتقالی را طبق نمودار سلسله مراتبی پَن و یانگ (2010) بررسی میکنیم. پن و یانگ یادگیری انتقالی را به دو بخش قیاسی (inductive) و تمثیلی (transductive) تقسیم میکنند و در قدم بعدی آن را به تطبیق دامنه، یادگیری بینازبانی، یادگیری چند مسئلهای و یادگیری انتقالی تناوبی تقسیم کردهاند.

تطبیق دامنه
این حالت بیشتر در بخش صنعتی روی میدهد که میخواهیم مدلی که بر روی مسئله خاصی آموزش دیده را در حوزه دیگری به کار ببندیم. تطبیق دامنه را میتوانیم بدون استفاده از دادههای برچسبدار هدف و یا با حجم خیلی کمی از این دادهها انجام دهیم. در ادامه به بررسی رویکردهای آن میپردازیم.
رویکردهای بازنمایی
تلاش رویکردهای بازنمایی بر این است که توزیع دادهها را تغییر دهند و برای انجام چنین کاری یا ویژگیهای مشترک میان دو دامنه را پیدا میکند و یا دادههای هر دو دامنه را در یک فضای مشترک با ابعاد کم به نمایش میگذارند:
- رویکردهای توزیع مشابه: در این رویکردها تلاش بر این است که توزیع دادههای مبدأ و دادههای هدف مشابه هم باشد. یک روش ساده برای دستیابی به این نوع توزیع این است که از ویژگیهایی که در جامعه هدف روی نمیدهند، چشمپوشی کنیم. عمده این رویکردها بر پایه یک متریک تشابه استوار هستند که به وسیله معیارهایی از جمله موارد زیر محاسبه میشود:
- واگرایی کولبک لیبلر (KL)
- واگرایی جنسون شانون (JS)
- فاصله واسراشتاین
یکی دیگر از روشهای رایج در این رویکردها، استفاده از یک بازنمایی است که فاصله میان بازنماییهای دو دامنه را به حداقل برساند و در عین حال عملکرد بر روی دادههای دامنه مبدأ را به حداکثر برساند.
- یادگیری ویژگی نهان: متد یادگیری ویژگی نهان، دادهها را در یک فضای ویژگی با ابعاد کم نمایش میدهد و از این طریق شباهتهای میان دامنه مبدأ و مقصد را به حداکثر میرساند. این فضای ویژگی که ابعاد کمی دارد را یا میتوان به کمک الگوریتمهای فاکتورگیری از جمله تجزیه مقادیر منفرد Singular Value Decomposition (SVD) یا به کمک خودرمزگذار شبکه های عصبی یاد گرفت.
وزندهی و گزینش دادهها
در این متد، به جای انتخاب ویژگی، نمونهها را انتخاب و وزندهی میکنیم تا بازنمایی دادههای مبدأ و مقصد را به حداکثر برسانیم. به رویکرد وزندهی نمونهها، انتخاب نرم و به فرایند انتخاب نمونهها انتخاب سخت میگویند. رویکرد انتخاب نمونه از این جهت که نمونههای زیانبخش را به حساب نمیآورد، سومندتر است.
شیا و همکاران (2015) برای ارائه دادن دادهها از متد تحلیل مؤلفههای اصلی (PCA) و برای انتخاب آنها از یکی از متریکهای فاصله PCA استفاده کردند. رودر و همکاران (2017ب) هم برای مشخص کردن میزان شباهت یک نمونه به کلاس از متد حداکثر تفاضل (فاصله) خوشه (MCD) استفاده کردند. در هر دو مثال، برای انتخاب بهترین نمونهها در پایپلاین پردازش زبان طبیعی، وزندهی و انتخاب دادهها در مرحله پیشپردازش انجام شده است.
رویکردهای خود برچسبگذاری
رویکردهای خود برچسبگذاری در دسته یادگیری نیمه نظارتی قرار میگیرند؛ در تکنیک یادگیری نیمهنظارتی مدلی را بر روی دادههای برچسبگذاری شده آموزش میدهیم و سپس از آنها برای نسبت دادن شبه برچسبها به نمونههای بدون برچسب استفاده میکنیم. در گام بعدی، از این نمونههای برای آموزش مجدد مدل استفاده میشود. رویکردهای خود برچسبگذاری از یکی از دو نوع متد آموزش پیروی میکنند:
- خودآموز Self-training: همانگونه که پیش از این نیز گفتیم در این رویکرد فقط نمونههایی که ضریب اطمینان بالایی دارند را انتخاب کرده و به دادههای آموزشی اضافه میکنیم. اصلیترین نقطه ضعف این رویکرد این است که مدل نمیتواند خطاهای خود را تصحیح کند و با گذشت زمان عملکرد آن تضعیف میشود. علاوه بر این مدل میتواند با استفاده از یک تکنیک وزندهی، وزنهای متفاوتی برای برچسبهای حقیقی و شبه برچسبها تعریف کند.
- آموزش چندوجهی Multi-view training: در این رویکرد مدلها را با وجوه (ویژگی) مختلف دادهها آموزش میدهیم. ممکن است این روالهای پردازشی به لحاظ ویژگیهای داده، معماریهای مختلف مدل و دادهها با هم تفاوت داشته باشند. در واقع آموزش چندوجهی را میتوان به شیوههای مختلفی انجام داد:
- آموزش همراه با همکاری Co-training: پس از آموزش مدلها بر روی مجموعه ویژگیهایشان، فقط نمونههایی در مجموعه آموزشی قرار میگیرند که مدل نسبت به آنها اطمینان دارد.
- آموزش همراه با همکاری دموکراتیک Democratic co-learning: این رویکرد از مدلهایی با سوگیریهای استقرایی Inductive bias و الگوریتمها و معماریهای مختلف شبکههای عصبی استفاده میکند.
- آموزش سهگانه Tri-training: این رویکرد مشابه آموزش دموکراتیک است. در این رویکرد از سه مدل مختلف که سوگیری استقرایی دارند استفاده کرده و با استفاده از نمونهبردای بوت استرپ، آنها را بر روی نمونههای مختلفی از دادههای اصلی آموزش میدهیم. پس از آموزش مدلها به نمونههای آموزشی یک داده بدون برچسب اضافه میکنیم تا ببینیم آیا دو مدل (از بین سه مدلی که آموزش دادهایم) میتوانند برچسب واحدی برای آن پیشبینی میکنند یا خیر.
- انطباق دامنه با چندین دامنه مبدأ Multi-source domain adaptation: در این رویکرد، با استفاده از دادههای دامنههای مختلف، مدل میسازیم و از یک رویکرد ترکیبی استفاده میکنیم.
- تلفیق مدلهای مبدأ: در این رویکرد یا میتوانیم دادههای آموزشی تمامی دامنههای مبدأ را با هم ترکیب کنیم و یک مدل واحد آموزش دهیم و یا میتوانیم مدلها را بر روی هر داده فردی، نیمی از آنها و یا تمامی آنها آموزش دهیم. سپس از این شبه برچسبها برای آموزش یک مدل جدید استفاده میکنیم.
- متدهای مبتنی بر شبکه عصبی: این متد با استفاده از مدل مبدأ بازنماییهای نمونههای هدف که ابعاد کمتری دارند را پیدا میکند و لایههای بعدی را با مکانیزم توجه و یا لایههای شبکههای عصبی recurrent آموزش میدهد. علاوه بر این میتواند با استفاده از یک تکنیک وزندهی و بر طبق شباهتهای دامنه مبدأ و دامنه هدف، خروجیهای مدل را وزندهی کند و لایههای بعدی را به صورت دقیق تنظیم کند.
یادگیری بینازبانی
در این بخش به معرفی مدلهای زبانی بینازبانی میپردازیم. با استفاده از این مدلها میتوانیم لغات زبانهای مختلف را با یکدیگر مقایسه کنیم؛ این مقایسه در انجام مسائلی همچون ترجمه ماشینی و بازیابی اطلاعات بینازبانی اهمیت دارد. مهمتر اینکه به کمک این مدلهای تعبیهشده و ایجاد یک فضای ارائه مشترک میتوانیم دانش را از زبانهای غنی به زبانهای ضعیفتر منتقل کنیم.
دادههای مورد نیاز برای انجام این مسئله به دو صورت موجود است: به صورت موازی، یعنی یک مکالمه دقیق (ترجمه کلمه گربه در شکل 4-1) و یا به صورت تطبیقی، که در آن نمونهای در قالب یک تصویر وجود دارد (کلمهای برای تصویری شبیه به گربه).
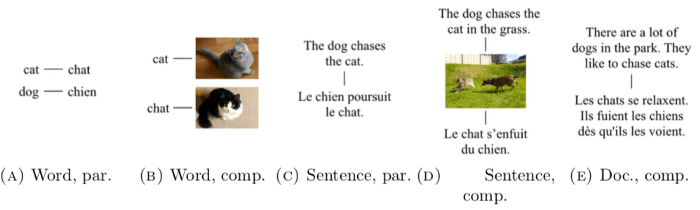
در ادامه به معرفی سه نوع تطبیقی میپردازیم که در تعبیههای کلمات بینازبانی مورد استفاده قرار میگیرند:
- مطابقت در سطح کلمه: در این رویکرد از فرهنگ لغتهایی استفاده میشود که شامل جفت واژههای زبانهای مختلف هستند. این رویکرد که به طور متدوال مورد استفاده قرار میگیرد، میتواند از نمونههای دیگر همچون تصاویر نیز استفاده کند.
- مطابقت در سطح جمله: در این رویکرد از جفت جملههایی مشابه جملاتی استفاده میشود که در ساخت سیستمهای ترجمه ماشینی استفاده شدند. به طور معمول این سیستمها از پیکره (مجموعه اسناد) Europarl استفاده میکنند؛ پیکره Europarl حاوی صورت جلسات پارلمان اروپا است.
- مطابقت در سطح سند: در این رویکرد به اسناد متناظر نیاز است که جملات آنها به ردیف ترجمه شدهاند. به ندرت میتوان به چنین اسنادی دسترسی پیدا کرد، اسناد قابل مقایسه بیشتر مورد استفاده قرار میگیرند. برای ایجاد چنین دادههایی میتوانیم از موضوعات مطالب منتشرشده در ویکیپدیا استفاده کنیم یا دادهها را به زبانهای مختلف جمعآوری کنیم.
یادگیری چند مسئلهای
معمولاً برای انجام هر مسئله باید یک مدل آموزش دهیم. در این حالت اطلاعاتی که میتوانند به عملکرد بهتر مدل کمک کنند را از دست میدهیم. اما اگر یک مدل را برای انجام چندین مسئله آموزش دهیم، ممکن است بتواند از طریق به اشتراک گذاشتن بازنمایی تمامی مسائل، بهتر تعمیم دهد.
- تکنیک یادگیری چند مسئلهای (MTL) یا یادگیری مشترک Joint learning به فرایندی اطلاق میشود که طی آن تلاش کنیم توابع زیان را بهینه کنیم.
MTL با بهرهگیری از اطلاعاتی که مختص یک دامنه هستند و در سیگنالهای آموزشی مسائل مربوطه وجود دارند، به تعمیمدهی بهتر مدل کمک میکند.
نقطه قوت یادگیری چندمسئلهای در این است که از پارامترهای یکسانی برای مسائل مختلف استفاده میکند و همین ویژگی ما را به سمت اشتراکگذاری پارامترهای سخت و نرم سوق میدهد.
اشتراکگذاری پارامترهای سخت Hard parameter sharing
اشتراکگذاری پارامترهای سخت رایجترین متد به کار رفته در MTL است. در این روش لایههای پنهان میان تمامی مسائل به اشتراک گذاشته میشوند و لایههای مختص دامنه به صورت جداگانه حفظ میشوند (شکل 5-1):

نتایج حاصل از پژوهش باکستر (1997) نشان میدهد به اشتراکگذاری پارامترهای سخت احتمال بیشبرازش مدل را کاهش میدهد، چرا که پارامترهایی که به اشتراک گذاشته شدهاند از طریق تعمیمدهی، بازنماییهای مشترک میان مسائل را یاد میگیرند.
اشتراکگذاری پارامترهای نرم Soft parameter sharing
در این رویکرد، هر مسئله، مدل و پارامترهای مخصوص به خود را دارد. فاصله میان پارامترهای مدل تنظیم میشود تا پارامترها به هم شباهت پیدا کنند:

دلایل اهمیت و تأثیرگذاری یادگیری چندمسئلهای
MTL مدلی بهتر و عالیتر به ما میدهد و برای درک و آگاهی از منطق زیربنایی این روش، از مزایای آن نباید غافل شویم:
- دادهافزایی: متد MTL دادههای آموزشی لازم برای آموزش مدل را افزایش میدهد. تمامی مسائل داده نویزدار دارند و به همین دلیل مدل باید یک بازنمایی را بیاموزد که داده نویزدار نداشته باشد. و به دلیل اینکه انواع گوناگون دادهها، الگوهای نویزی متفاوتی هم دارند، مدل باید یک بازنمایی یاد بگیرد که در تمامی مسائل عملکرد خوبی داشته باشد.
یادگیری مشترک الگوهای نویزی را تعدیل میکند و بازنمایی بهتری به دست میآورد.
- تمرکز توجه Attention focusing: اگر دادهها نویز و یا ابعاد زیادی داشته باشند و حجم آنها کم باشد، آموزش مدل به مشکل میخورد. آموزش مدل بر روی چندین مسئله به مدل میآموزد که بر روی ویژگیهای بااهمیتتر تمرکز کند و علاوه بر این میتواند به بهبود عملکرد مدل کمک کند.
- بایاس در بازنمایی Representation bias: MTL موجب میشود مدل بازنماییهایی را بیاموزد که برای تمامی مسائل مفید و سودمند هستند. بازنماییای که در بسیاری مسائل کارایی داشته، در یک مسئله جدید هم میتواند عملکرد خوبی داشته باشد، به همین دلیل مدل در آینده میتواند برای تمامی مسائل سریعتر تعمیم دهد.
- نرمالسازی Regularization: MTL با تعریف بایاس استقرایی و کاهش پیچیدگی مدل رادماخر Rademacher complexity به مثابه یک نرمالساز (regularizer) عمل میکند ( بیش برازش را کاهش میدهد).
به توانایی MTL در برازش نویز تصادفی پیچیدگی رادماخر میگویند.
نکاتی در باب MTL
اگر پیشبینیهای چندین مسئله را به طور همزمان بخواهیم، میتوانیم از MTL استفاده کنیم. در این بخش به بررسی مقولههایی میپردازیم که به تعامل بهتر مغز و مسائل فرعی Auxiliary task کمک میکنند.
لایههای مشترک
مسائل کمکی میتوانند بر روی لایهها تأثیر بگذارند، از این روی باید در مورد لایههایی که ارزش به اشتراک گذاری دارند، تصمیمگیری کنیم. نتایج پژوهش ساگارد و گلدبرگ (2016) نشان میدهد زمانیکه مسئله اصلی، مسائل فرعی، برای مثال تشخیص موجودیت اسمی (NER) و یا تگگذاری نقش دستوری کلمات (POS) داشته باشد، بهتر است لایههای پایینی را به اشتراک بگذاریم. بر همین اساس هاشیموتو و همکاران (2017) یک معماری سلسله مراتبی ایجاد کردهاند که از چندین مسئله برای مدلسازی مشترک تشکیل شده است.
سان و همکاران (2019) هم برای مسائل معنایی (Semantic) یک معماری سلسله مراتبی ارائه دادهاند. در این معماری، مدل به صورت سلسله مراتبی آموزش میبیند تا سوگیری استقرایی ایجاد کند؛ به همین منظور بر مجموعهای از مسائل سطح پائین لایههایی انتهایی مدل و مسائل دشوار لایههای بالایی مدل نظارت میکند (شکل 7-1).
تعبیهها و انکودر میان مسائل مشترک است و به همین جریان اطلاعات از سطوح پایینتر معماری به سطوح بالاتر راحتتر صورت میگیرد.
مدل بر روی مسائل تشخیص موجودیت اسمی (NER)، تشخیص بازنمایی موجودیت Entity Mention Detection و استخراج روابط به نتایج شگفتی دست یافت. در Coreference resolution هم با اینکه فرایند آموزش و منظمسازی سادهتری نسبت به مسائل قبلی داشت، به نتایج فوقالعادهای دست پیدا کرد.

تأثیرات متقابل مسائل
به طور معمول در MTL، دستهها batches به شیوهای یکسان از مسائل نمونهبرداری میشوند. در طول فرایند آموزش، بهینهساز تلاش میکند مجموع وزنی Weighted sum زیان را کاهش دهد و به همین دلیل یافتن وزنهای مناسب اهمیت پیدا میکند. همانند َبَر پارامترهای دیگر، این وزنها را هم میتوانیم بر روی یک مجموعه اعتبارسنجی تنظیم کنیم.
یک روش متدوال برای دستیابی به این هدف این است که وزنهای یکسانی نسبت دهیم، اما روش بهتری هم میتوانیم به کار ببندیم که در آن وزنها را میتوان یاد گرفت (کندال و همکارن، 2018).
تعداد نمونهها از مسئلهای به مسئله دیگر متفاوت است و بهینهسازی برای مسئلهای بهینه میشود که حداکثر نمونه را دارد.
برای غلبه بر این مشکل میتوانیم با احتمالات مختلف از مسائل نمونهبرداری کنیم (متناسب با تعداد نمونهها) تا بتوانیم از هر مسئله، تعداد نمونههای آموزشی یکسانی را نمونهبرداری کنیم. علاوه بر این، برای تأکید بر اهمیت مسئله اصلی میتوانیم بیشتر از آن نمونهبرداری کنیم.
تنظیم نسبت نمونهبرداری و تعیین وزنهای متفاوت تأثیرات یکسانی دارند.
انتخاب مسئله فرعی
دلیل اصلی استفاده از مسئله فرعی این است که این مسئله به مسئله اصلی ربط دارد و به حل آن کمک میکند. به روشهای متعددی میتوان رابطهمندی یک مسئله را مشخص کرد. یکی از روشهای تشخیص این رابطهمندی این است که ببینیم آیا مسئله اصلی و مسائل فرعی از ویژگیهای یکسانی (اطلاعات سطح پایین) برای پیشبینی استفاده میکنند یا خیر.
به گفته شو و همکاران (2007) دو مسئله مشابه، حدود طبقهبندی مشابهی خواهند داشت. رایجترین مسائل فرعی عبارتند از:
- آماری: اینگونه مسائل تلاش میکنند اطلاعات سطح پایینِ دادههای ورودی، از جمله فراوانی لگاریتمی Log frequency یک کلمه را پیشبینی کنند.
انتخابی بدون نظارت Selective unsupervised: این مسائل تلاش میکنند بخشی از داده ورودی را پیشبینی کنند. برای مثال، یو و جیانگ (2016) برای تحلیل احساسات پیشبینی میکنند که آیا در جمله یک واژه با بار احساسی مثبت یا بار احساسی منفی، مستقل از دامنه وجود دارد یا خیر و در نتیجه مدل نسبت به بار احساسی کلمات تشکیلدهنده جمله حساس میشود.
- مسائل نظارتشده: رایجترین مورد کاربردی که در آن از مسئله نظارت شده استفاده میشود. ژانگ و همکاران (2014) برای تشخیص نقاط راهنمای صورت Facial landmark detection از برآورد وضعیت سر Head pose estimation و استنباط ویژگیهای تصویر چهره Facial attribute inference به عنوان مسائل فرعی استفاده کردند.
- مسائل بدون نظارت: مسائل فرعی که به آنها اشاره کردیم مشابه مسئله اصلی هستند و بازنماییهای مشترک میان مسئله اصلی و فرعی را یاد میگیرند. اما میتوانیم یک مدل را با یک مسئله بدون نظارت آموزش دهیم تا بازنماییهای همه منظوره از جمله مدلسازی زبانی ایجاد کنیم.
مسائل مرتبط با پردازش زبان طبیعی

یادگیری انتقالی تناوبی
در یادگیری انتقالی تناوبی (STL) دانش طی چندین مرحله منتقل میشود، در این روش مسئله مبدأ و مسئله هدف مشابه هم نیستند. اما در MTL مسائل به صورت مشترک یاد گرفته میشوند، اما STL از دو مرحله تشکیل میشود. در مرحله اول یعنی پیش آموزش، مدل بر روی دادههای مبدأ آموزش میبیند و در مرحله دوم یعنی تطبیق، مدل مبدأ بر روی مسئله هدف آموزش میبیند.
مسئله پیش آموزش هزینهبر است اما فقط یک بار باید آن را انجام داد. مسئله تطبیق، به دلیل اینکه شبیه به مرحله تنظیم دقیق است، سریعتر انجام میشود.
STL در موقعیتهای زیر به کار میآید:
- امکان دسترسی همزمان به دادههای مسئله مبدأ و هدف وجود ندارد
- تعداد دادههای مسئله مبدأ نسبت به مسئله هدف زیادتر است
- تطبیق با تعدادی زیادی مسئله هدف لازم و ضروری است
STL و MTL شباهتهای زیادی با هم دارند، اما در شیوه انتقال دانش با یکدیگر تفاوت دارند. در MTL، مسئله مبدأ و مسئله هدف همزمان با هم آموزش میبینند اما در STL، ابتدا مسئله مبدأ و سپس مسئله هدف آموزش داده میشود.

پیش آموزش
برای بهرهمندی حداکثری از مزایای این روش، ابتدا مسئله هدف را آموزش میدهیم که تمامی مسائل هدف هم از آن فایده خواهند برد. پیدا کردن چنین مسئلهای دشوار است، اما بهتر از این است که از صفر شروع کنیم. به سه روش میتوانیم مسئله مبدأ را آموزش دهیم:
- نظارت از راه دور: نظارت از راه دور از دادههایی استفاده میکند که یا به روش اکتشافی (heuristics) جمعآورده شدهاند و یا به واسطه متخصصان همان حوزه به دست آمدهاند. اینگونه دادهها معمولاً نویز دارند و با استفاده از الگوهای از پیش تعرفی شده به دست آمدهاند. فلبو و همکاران (2017) با استفاده از این روش، تعداد زیادی از ایموجیها را در بیش از یک میلیارد توئیت پیشبینی کردند. سپس از مدلی که از قبل آموزش داده بودند در تحلیل احساسات و همچنین تشخیص احساسات و سخنان کنایهآمیز استفاده کردند و ثابت کردند پیش آموزش میتواند برای مسائل هدف سودمند باشد.
- نظارت مرسوم: دادههای آموزشی مورد استفاده در این متد باید به روش دستی برچسبگذاری شوند. در این روش ترجیح بر این است که از دادههای متناسب با مسئله استفاده شود، اما میتوان از بسیاری از دیتاستهای موجود هم استفاده کرد. زوف و همکاران (2016) یک مدل ترجمه ماشینی را بر روی یک جفت زبانی که منابع زیادی داشتند، آموزش دادند و سپس این مدل را به یک جفت زبانی منتقل کردند که منابع آنها محدود بود. یانگ و همکاران (2017 الف) یک مدل تگگذاری POS را از پیش آموزش دادند و آن را در مسئله تقطیع کلمات به کار گرفتند.
امروزه، تلاش پژوهشگران بر این است که مسئلهای انتخاب کنند که به درک پایه و ابتدایی از زبان نیاز داشته باشد.
در اینگونه مسائل معنا و مفهوم یک کلمه و عنوان تصویر پیشبینی میشود. هرچند استفاده از یک دیتاست بزرگ و دسترسی به حجم زیادی از دانش وسوسهانگیز است، اما ارزش و اهمیت مدل از پیش آموزش داده شده در شباهت دامنه و مسئله مبدأ و هدف است.
- بدون نظارت: در متد یادگیری بدون نظارت برای آموزش مدل فقط به حجم بالایی از دادههای متنی بدون برچسب نیاز داریم به همین دلیل این متد، آسانترین روش برای آموزش مدل مبدأ شناخته میشود. این روش مدلسازی زبانی هم نامیده میشود. متد یادگیری بدون نظارت نسبت به متد یادگیری نظارتشده مقیاسپذیرتر است، چرا که دسترسی به متون حوزههای مختلف آسان است.
متد یادگیری بدون نظارت نسبت به متد یادگیری نظارتشده دانش عمومی بیشتری را ثبت میکند. در متد یادگیری نظارتشده فقط ویژگیهایی ثبت میشوند که برای انجام مسئله به آنها نیاز است.
پژوهشگران برای یادگیری این بازنماییها روشهای زیادی را امتحان کردهاند که برای نمونه میتوان به تحلیل معنایی پنهان (LSA)، تخصیص پنهان دیریکله (LDA)، نمونهبرداری منفی با Skip-gram (SGNS)، بُردارهای Skip-thoughts ،GloVe ،ELMo و BERT اشاره کرد.
- پیش آموزش چندمسئلهای: برای بهرهمندی از مزایای سه متد مذکور میتوانیم از روش MTL استفاده کنیم که در آن تمامی مسائل را میتوان با هم آموزش داد. MTL میتواند به این بازنماییهایی در امر تعمیمدهی کمک کند و آنها را برای انجام مسائل downstream مختلف آماده کند. سوبرامانیان و همکاران (2018) پیش آموزش چند مسئلهای را بر روی بردارهای skip-thoughts، ترجمه ماشینی، تجزیه به اجزای سازنده و استنباط زبان طبیعی اجرا کردند.
تطبیق
اولین مرحله از STL را توضیح دادیم و اکنون به سراغ دومین مرحله یعنی تطبیق میرویم. در حال حاضر به دو روش میتوان مدلی که از پیش آموزش داده شده را در انجام مسئله هدف به کار برد: استخراج ویژگی و تنظیم دقیق. استخراج ویژگی، بازنماییهای مدل از پیش آموزش داده شده را به یک مدل دیگر تغذیه میکند. تنظیم دقیق، مدل از پیش آموزش داده شده را بر روی مسئله هدف آموزش میدهد.
- استخراج ویژگی: در استخراج ویژگی، وزنهای مدل ثابت نگه داشته میشوند و خروجی مدل مستقیماً به یک مدل دیگر فرستاده میشود. ویژگیها را یا میتوانیم به یک مدل کاملاً متصل ارسال کنیم یا میتوانیم مدلهای قدیمیتر از جمله ماشین بردار پشتیبان (SVM) یا RandomForest را بر روی آن آموزش دهیم. مزیت استفاده از این روش در این است که میتوانیم مدلی را که برای انجام مسئله خاصی آموزش دیده مجدداً برای دادههای مشابه به کار بگیریم. در ضمن در صورتیکه در استخراج ویژگی به صورت مکرر از همان دادهها استفاده شود، تا حد زیادی در منابع محاسباتی صرفهجویی میشود.
- تنظیم دقیق: در تنظیم دقیق، وزنها قابل آموزش هستند و برای مسئله هدف به صورت دقیق تنظیم میشوند. از این روی مدل از پیش آموزش داده شده نقطه شروعی برای مدل به حساب میآید و نسبت به مقداردهی تصادفی، سریعتر همگرا میشود.
تنظیم دقیق تعبیه کلمات نسبت به استخراج ویژگی عملکرد بهتری دارد. تنها نقص این روش در این است که تعبیه تنها برای کلماتی که در آموزش استفاده میشوند، به روزرسانی میشو و تعبیه ی آن دسته از کلمات بازدید نشده تغییری نمیکنند.
این ویژگی هنگامیکه مجموعه آموزشی بسیار کوچک باشد یا مجموعه آزمایشی شامل تعداد زیادی کلمه خارج از دامنه فرهنگ لغت (OOV) باشد، عملکرد را تحت تأثیر قرار میدهد. بیشتر پژوهشگران برای مقابله با OOV، از مدلهای مبتنی بر تعبیه زیر کلمات همچون ELMo و BERT استفاده میکنند.
هرچند استخراج ویژگی و تنظیم دقیق به ظاهر متفاوت هستند اما میتوان آنها را در یک چارچوب مشترک قرار دارد. فرض کنید مدل مبدأیی که از پیش آموزش داده شده ، از پارامترها و لایههای θs و Ls تشکیل شده است. پارامترها و لایههای هدف هم θt و Lt هستند. در چنین حالتی، پارامترهای مدلی که تطبیق داده میشود برابر است با: LA=Ls+Lt با θA=θt U θt.
لایههای Ls و Lt در بازههای [1, Ls] و [Ls, LA] لایههایی دارند. اصلیترین پارامتر در فرایند تطبیق، نرخ یادگیری یا همان است که با توجه به لایهها متغیر است، چراکه لایههای اولیه قابل تعمیم هستند و نیازی نیست تغییرات زیادی در آنها ایجاد کنیم اما لایههای انتهایی مختص یک مسئله هستند و تغییرات زیادی در آنها ایجاد میشود.
در زمان آموزش مدل و در صورت استفاده از schedule هم، تغییر میکند. به طور کلی به منظور جلوگیری از تغییر شدید وزنها، نرخ یادگیری تطبیق پایینتر از پیش آموزش است. فرض کنید نرخ یادگیری اولین لایه از مدلی تطبیق داده شده است. در این حالت، معادله استخراج ویژگی و تنظیم دقیق را میتوان بدین شکل در نظر گرفت:
- استخراج ویژگی در حالتی روی میدهد که:

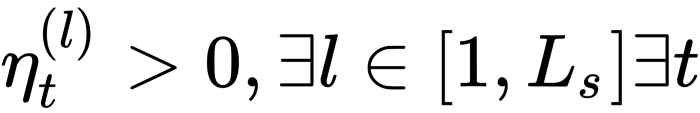
- در رویکرد تنظیم دقیق، در طول فرایند تطبیق حداقل یکی از لایههای مبدأ را باید به روز رسانی کرد:
در این معادله به این معنی است که یک …. وجود دارد.
لایههای مبدأ را میتوان به گونهای آموزش داد که فقط لایههای انتهایی آموزش داده شوند ( لانگ و همکاران، 2015 الف). علاوه بر این میتوانیم آموزش مدل را ادامه دهیم، (unfreezing) برای مثال میتوانیم chain-thaw را بر روی لایهها اجرا کنیم (فلبو و همکاران، 2017). هاوارد و رودِر هم با انجمادزدایی تدریجی و به نتایج فوقالعادهای دست پیدا کردند (2018).
نتایج پژوهش پیترز و همکاران (2019) نیز حاکی از این است که نحوه عملکرد تنظیم دقیق و استخراج ویژگی در مدلهای زبانی به میزان شباهت مسائل پیش آموزش و هدف بستگی دارد.
تطبیق بازنماییهایی که از قبل آموزش دیدهاند
با وجود اینکه استفاده از رویکرد MTL رایج است اما STL محبوبترین تکنیک زمان حال شناخته میشود و هزینههای محاسباتی آن نسبت به MTL کمتر است. STL این امکان را برای ما فراهم میکند تا بازنماییهایی که از قبل آموزش دیدهاند را برای هر مسئلهای تطبیق دهیم.
تنظیم دقیق مدل زبانی سراسری (ULMFiT)
یادگیری انتقالی استقرایی نقش بسزایی در حوزه بینایی کامپیوتری داشته اما در عرصه پردازش زبان طبیعی موفق نبوده است. هاوارد و همکاران متوجه شدند که مشکل تنظیم پارامتر، در مدل زبانی نیست بلکه مشکل را باید در نحوه مقابلهمان با این مشکل جستجو کنیم. مدل زبانی (LM) نسبت به مدلهای بینایی ماشین ضعیفتر است و به همین دلیل برای تنظیم دقیق آنها به رویکرد متفاوتی نیاز است. به همین منظور هاوراد و همکاران ULMFiT را پیشنهاد میدهند که برای یادگیری ویژگیهایی مختص به یک مسئله از تنظیم پارامتر discriminative (‘Discr’) و نرخ یادگیری slanted triangular (STLR) استفاده میکند. کلاسیفایر با unfreeze کردن تدریجی و STLR به صورت دقیق بر روی مسئله هدف تنظیم میشود تا بازنماییهای سطح پایین را حفظ کند و بازنماییهای سطح بالا را تطبیق دهد. به بیانی دقیق تر:
- تنظیم پارامتر discriminative: لایههای پایینی مختص مسئله هستند و لایههای پایینی بازنماییهای سراسری را ثبت میکنند. بهتر است نرخ یادگیری لایههای پایینی کمتر باشد زیرا اگر نرخهای یادگیری بالا باشند، وزنها به سرعت تغییر میکنند و موجب میشوند مدل دچار فراموشی شود. از این گذشته ما میخواهیم هرچه سریعتر مدل را آموزش دهیم. برای مقابله با این محدودیتها، برای هر لایه به یک نرخ یادگیری متفاوت نیاز داریم. برای مثال میتوان نرخ یادگیری را در حرکت از لایههای بالایی به سمت لایههای پایینی کاهش داد.

لایه ورودی، لایههای تعبیه کلمات (E)، لایههای پنهان با نرخهای یادگیری متفاوت(L) و لایه نهایی (T) .
- unfreeze کردن تدریجی: به طور تجربی ثابت شده اگر تمامی لایهها را به صورت همزمان بر روی دادههای مسائل مختلف که توزیع متفاوتی هم دارند آموزش دهیم، به نتایج خوبی دست پیدا نمیکنیم. به همین دلیل لازم است هر لایه را به صورت جداگانه آموزش دهیم تا زمانی کافی داشته باشد خودش را با مسئله و دادههای جدید تطبیق دهد. در کنفرانس ICML 2015، لانگ و همکاران پیشنهاد دادند به جای این کار، تمامی لایهها را، به غیر از لایه بالایی، فریز کنیم. در کنفرانس EMپردازش زبان طبیعی 2017 متدی به نام chain-thaw را پیشنهاد دادند؛ در این متد هر بار فقط یک لایه از حالت فریز خارج میشود و تمامی لایهها قابل آموزش هستند.
کرونوپولو و همکاران هم پیشنهاد دادهاند پارامترهای اضافی را برای n مرحله و پارامترهایی که از قبل آموزش دیدهاند و لایه تعبیه شده ندارند را برای k مرحله به صورت دقیق تنظیم کنیم و سپس تمامی لایهها را آموزش دهیم تا همگرا شوند. در مقابل ULMFiT هم پیشنهاد میدهد که لایهها را از بالا به پایین به صورت تدریجی از حالت انجماد خارج کنیم (شکل 11-1).
در گام اول و به منظور جلوگیری از فراموشی مدل، آخرین لایه از حالت انجماد خارج میشود و به تدریج لایههای دیگر را هم از حالت انجماد خارج میکنیم.

ایده اصلی : استفاده از نرخ یادگیری مناسب به منظور جلوگیری از نوشتن چندباره اطلاعات مفید:
- لایههای پایینی: ثبت اطلاعات عمومی
- در آغاز فرایند آموزش: مدل کماکان باید با توزیع هدف مطابقت پیدا کند
- اواخر فرایند آموزش: مدل به همگرایی نزدیک است
- STLR: همانگونه که گفتیم برای هر لایه به نرخ یادگیری متفاوتی نیاز داریم و به همین دلیل باید برای هر لایه یک نرخ یادگیری مناسب پیدا کنیم. استفاده از یک نرخ یادگیری یکسان روش مناسبی برای دستیابی به این رفتار نیست. شکل 12-1 نشاندهنده رفتارهایی است که در نتیجه نرخهای یادگیری متفاوت شکل میگیرند:
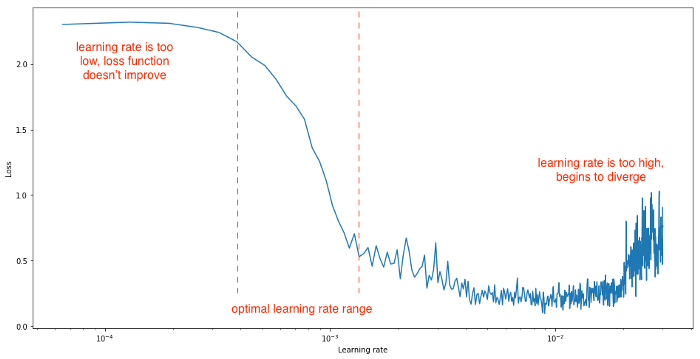
اسمیت، ال. اِن. برای پیدا کردن بهترین نرخ یادگیری و همگرایی سریعتر، نرخ یادگیری دورهای Cyclical learning rate (CLR) را پیشنهاد میکند. در این روش به منظور پیدا کردن بیشترین و کمترین نرخ یادگیری، آموزش در بستههای کوچک با نرخ یادگیری افزیشی اجرا میشود. نرخی که زیان در آن افزایش مییابد، حداکثر نرخ یادگیری است که میتوانید داشته باشید.
شکل 13-1 شیوه آموزش یک مدل را با برنامه زمانبندی نرخ مثلثی نشان میدهد، این نرخ به صورت دورهای کاهش و افزایش مییابد:

علاوه بر این میتوانید تغییراتی ایجاد کنید که در آن حداکثر نرخ یادگیری به طور مداوم کاهش یابد، چرا که در ابتدا به یک نرخ یادگیری بالاتر نیاز داریم و برای همگرایی با کمینه مطلق باشند.
ULMFiT بر روی این ایده کار کرد و در نهات STLR را معرفی کرد که در ابتدا به صورت خطی نرخ یادگیری را افزایش میدهد و سپس به صورت خطی آن را کاهش میدهد. همانگونه که در شکل 14-1 مشاهده میکنید افزایش نرخ یادگیری سریعتر از کاهش آن اتفاق میافتد و موجب میشود از CLR هم سریعتر باشد:

در صورتیکه شرایط افزایش نرخ یادگیری فراهم شود میتوانیم به کمینه شارپ Sharp minima برسیم که به طور موقتی زیان را افزایش میدهد اما در نهایت ممکن است موجب همگرایی با یک کمینه بهتر میشود. علاوه بر این، افزایش نرخ یادگیری امکان عبور سریعتر از نقطه زینی را فراهم میکند.
ULMFiT از جدیدترین مدل زبانی یعنی ASGD Weighted dropped long short term memory (AWD-LSTM) استفاده میکند ( مریتی و همکاران، 2017 الف)؛ این مدل زبانی یک LSTM ساده ( بدون مکانیزم توجه، اتصالات میانبر و ضمیمههای دیگر) است که شامل چندین پارامتر dropout است که به صورت دقیق تنظیم شدهاند. جدول مقابل تعداد نمونهها در دیتاستهای مختلف را نشان میدهد:

همانگونه که مشاهده میکنید، تعداد نمونههای آموزشی TREC-6 و IMDB کمتر است.
- پیش آموزش مدل زبانی بر روی دامنه سراسری: برای ثبت ویژگیهای عمومی و همگانی زبان در لایههای مختلف. عملکرد AWD-LSTM به دلیل استفاده از تکنیکی پیشرفتهتر بهتر از مدل زبانی LSTM ساده است.

- تنظیم دقیق مدل زبانی بر روی مسئله هدف: مدل زبانی با استفاده از تکنیک ‘Discr’ و STLR روی دادههای مسئله هدف به صورت دقیق تنظیم میشود تا ویژگیهای مختص مسئله را یاد بگیرد. هنگامیکه دادههای هدف کمتر از TREC-6 باشد، تنظیم مدل زبانی بر روی دادههای مسئله میتواند به کسب نتایج بهتر کمک کند.

- تنظیم دقیق کلاسیفایر مسئله هدف: تنظیم دقیق با استفاده از انجمادزدایی تدریجی با نرخ یادگیری discriminative و STLR برای حفظ بازنماییهای سطح پایین و تطبیق با بازنماییهای سطح بالا.
جدول هوشمند نرخ یادگیری با یادگیری افتراقی نه تنها باعث افزایش نرخ دقت با حاشیه کوچکتر میشود بلکه به تعداد مراحل کمتری نیاز دارد.

برخی از مشخصههای تنظیم دقیق کلاسیفایر به شرح زیر است:
- کامل: تنظیم دقیق مدل به طور کامل
- نهایی: تنظیم دقیق لایه آخر
- انجماد: unfreeze کردن تدریجی
- کسینوسی: جدول cosine annealing برای نرخ یادگیری مثلثی
یادگیری انتقالی تناوبی به کمک ULMFiT
تا به اینجا راجع به مبانی و اصول یادگیری انتقالی گفتوگو کردیم. در این قسمت با استفاده از کتابخانه fastai هاوارد، نمونهای از یادگیری انتقالی تناوبی را با یکدیگر بررسی میکنیم.
کتابخانه را بارگذاری کنید:
from fastai.text import *
برای آموزش مدل از دیتاست IMDB (دیتاست بررسی و امتیازدهی فیلم و سریال) استفاده کنید. کتابخانه fastai متدهایی توکار برای دانلود و بارگذاری دادهها دارد:
path = untar_data(URLs.IMDB_SAMPLE) df = pd.read_csv(path/'texts.csv') df.head()
دادهها از ستونهای label، text و is_valid تشکیل شده است؛ ستون is_valid تعیین میکنند چه ردیفی برای اعتبارسنجی استفاده میشود.

دادههایی که برای تنظیم دقیق مدل زبانی استفاده میشوند را مطالعه کنید. تمامی متن بررسی برای تنظیم دقیق مدل زبانی بر روی مسئله استفاده میشود:
data_lm = TextLMDataBunch.from_csv(path, 'texts.csv')
بارگذار بستههای داده را تعرفی کنید؛ این بارگذار بسته دادههای متنی را برای آموزش ایجاد میکند:
data_clas = TextClasDataBunch.from_csv(path, 'texts.csv', vocab=data_lm.train_ds.vocab, bs=32)
مدل زبانی را برای یک STLR به صورت دقیق تنظیم کنید:
learn = language_model_learner(data_lm, AWD_LSTM, drop_mult=0.5) learn.fit_one_cycle(1, 1e-2)
در نهایت نرخ دقتی که به دست میآید به شرح زیر است:

برای یک دور دیگر آن را برازش کنید:
learn.unfreeze() learn.fit_one_cycle(1, 1e-3)
میبینید که نرخ دقت مدل زبانی افزایش پیدا کرده:

برای ساخت کلاسیفایر، با استفاده از مدل AWD_LSTM، مدل کلاسیفایر متنی را تعریف کنید:
learn = text_classifier_learner(data_clas, AWD_LSTM, drop_mult=0.5)
learn.load_encoder('ft_enc')
مدل را برای یک دور آموزش دهید:
learn.fit_one_cycle(1, 1e-2)
در نهایت نرخ دقتی که به دست میآید به شرح زیر است:

مدل را یک دور دیگر با اولین و آخرین نرخ یادگیری لایهها ( لایههایی که منجمد شدهاند) و باقی لایهها به لحاظ هندسی به صورت مساوی از یکدیگر فاصله دارند:
learn.freeze_to(-2) #Freeze till last 2 layers learn.fit_one_cycle(1, slice(5e-3/2., 5e-3))
در نهایت نرخ دقتی که به دست میآید به شرح زیر است:

اگر مدل را یک دور دیگر آموزش دهیم، نتایج بهبود پیدا میکنند. در نهایت مدل را بر روی نمونه دادههای متنی آزمایش میکنیم:
learn.predict("This was a great movie!")
(Category positive, tensor(1), tensor([0.0049, 0.9951]))
در بخش بعدی به شما نشان میدهیم که آیا لازم است مدل را در طول فرایند یادگیری انتقالی به صورت دقیق تنظیم کنید یا نه.
تنظیم کردن یا تنظیم نکردن
همانگونه که پیش از نیز گفتیم به دو روش میتوان یادگیری انتقالی را انجام داد:
- استخراج ویژگی
- تنظیم دقیق
در استخراج ویژگی بازنمایی را از مدل منجمدشده میگیریم و آن را به مدل مسئله منتقل میکنیم. اما برای تنظیم دقیق، تمامی لایههای مدل را از حالت انجماد خارج میکنیم و مدل را برای مسئله آموزش میدهیم.
مزیت استخراج ویژگی این است که میتوانیم ویژگیهایی ایجاد کنیم و مدلهای متعددی را بر روی آنها امتحان کنیم و در منابع محاسباتی برای آموزش مجدد و آزمایش صرفهجویی کنیم. در مقابل، مزیت تنظیم دقیق این است که میتوانیم یک مدل را ارتقا دهیم و چندین بار و برای مسائل مختلف از آن استفاده کنیم.
پیترز و همکاران، 2019 تأثیر تنظیم دقیق را بر روی هر دو بررسی کردند و به یک نتیجه رسیدند. آنها عملکرد دو مدل ELMo (پیترز و همکاران، 2019 الف) و BERT ( دولین و همکاران، 2018) را که از قبل آموزش داده شده بودند را با استفاده از استخرجا ویژگی و تنظیم دقیق بر روی هفت مسئله متفاوت با یکدیگر مقایسه کردند.
نتایج این مقایسه نشان داد که بیشتر اوقات هر دو رویکرد به نتایج یکسانی دست پیدا میکنند، اما زمانیکه مسئله مبدأ و هدف مشابه هم باشند، عملکرد تنظیم دقیق بهتر خواهد بود و زمانیکه مسئله مبدأ و هدف با یکدیگر تفاوت داشته باشند، استخراج ویژگی عملکرد بهتری خواهد داشت.

عملکرد مدلهای ELMo و BERT در استخراج ویژگی و تنظیم دقیق متفاوت است. تنظیم دقیق ELMo همیشه نسبت به استخراج ویژگی ضعیفتر عمل میکند و این در حالی است که تنظیم دقیق BERT بهتر از استخراج ویژگی عمل میکند.
یکی از فرضیاتی که برای عملکرد فوقالعاده BERT بر روی مسائل مشابه ارائه شده این است که: ELMo از LSTM استفاده میکند که به صورت تناوبی عمل میکند و هر بار فقط یک توکن را در نظر میگیرد، اما BERT که چندین ترنسفورمر به همراه مکانیزم توجه دارد، کل توالی را در نظر میگیرد و به همین دلیل بهتر از ELMo میتواند تعامل جفت توالی را کدگذاری کند.

برای پیشگیری از فراموشی، نویسندگان لایههایی که از قبل اموزش داده شده بودند را به صورت تدریجی از حالت انجماد خارج کردند و متوجه شدند به محض اینکه آموزش لایههای پایینی را شروع کنند- حتی اگر برای انتقال آسانتر، نرخهای یادگیری را کنترل کنند- عملکرد مدل تضعیف میشود.
نتیجهگیری
در برههای از زمان به سر میبردیم که استفاده از یادگیری انتقالی اجتناب ناپذیر است.
به دلیل اینکه پردازش زبان طبیعی به طور مداوم قابلیتهای جدید کسب میکند و برای حل مسائل مختلفی مورد استفاده قرار میگیرد، ضروری است راههایی برای استفاده از دادههای دامنهها، مسائل و زبانهای دیگر پیدا کنیم.
در این فصل، به معرفی تکنیکهای مختلف یادگیری انتقالی، از جمله تطبیق دامنه، یادگیری بینازبانی، یادگیری چند مسئلهای و یادگیری انتقالی تناوبی پرداختیمغ این تکنیکها به ما کمک میکنند در مدت زمانی کمتر و با صرف منابع کمتر، مدلهای بهتر یادگیری ماشین بسازیم. همچنین در این فصل مثالی از یادگیری انتقالی تناوبی ذکر کردیم و دلایل تنظیم و عدم تنظیم مدل را در یادگیری انتقالی را برای شما توضیح دادیم.
برای مطالعه بخش دوم وارد لینک زیر شوید:
یادگیری انتقالی در پردازش زبان طبیعی – بخش دوم
منابع
Pan, S. J. and Yang, Q. (2010). A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering, 22(10):1345–1359.
Xia, R., Zong, C., Hu, X., and Cambria, E. (2015). Feature Ensemble plus Sample Selection: A Comprehensive Approach to Domain Adaptation for Sentiment Classification. Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence (IJCAI 2015) Feature, PP(99):1.
Ruder, S., Ghaffari, P., and Breslin, J. G. (2017b). Knowledge Adaptation: Teaching to Adapt. In arXiv preprint arXiv:1702.02052.
Caruana, R. (1998). Multitask Learning. Autonomous Agents and Multi-Agent Systems, 27(1):95–133.
Baxter, J. (1997). A Bayesian/information theoretic model of learning to learn via multiple task sampling. Machine Learning, 28:7–39.
Søgaard, A. and Goldberg, Y. (2016). Deep multi-task learning with low level tasks supervised at lower layers. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, pages 231–235.
Hashimoto, K., Xiong, C., Tsuruoka, Y., and Socher, R. (2017). A Joint Many-Task Model: Growing a Neural Network for Multiple پردازش زبان طبیعی Tasks. In Proceedings of EMپردازش زبان طبیعی.
Sanh, V., Wolf, T., and Ruder, S. (2019). A Hierarchical Multi-task Approach for Learning Embeddings from Semantic Tasks. In Proceedings of AAAI 2019.
Kendall, A., Gal, Y., and Cipolla, R. (2018). Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics. In Proceedings of CVPR 2018.
Xue, Y., Liao, X., Carin, L., and Krishnapuram, B. (2007). Multi-Task Learning for Classification with Dirichlet Process Priors. Journal of Machine Learning Research, 8:35–63.
Zhang, Z., Luo, P., Loy, C. C., and Tang, X. (2014). Facial Landmark Detection by Deep Multi-task Learning. In European Conference on Computer Vision, pages 94–108.
Liu, X., Gao, J., He, X., Deng, L., Duh, K., and Wang, Y.-Y. (2015). Representation Learning Using Multi-Task Deep Neural Networks for Semantic Classification and Information Retrieval. NAACL-2015, pages 912–921.
Felbo, B., Mislove, A., Søgaard, A., Rahwan, I., and Lehmann, S. (2017). Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm. In Proceedings of EMNLP.
Zoph, B., Yuret, D., May, J., and Knight, K. (2016). Transfer Learning for Low-Resource Neural Machine Translation. In Proceedings of EMNLP 2016.
Yang, J., Zhang, Y., and Dong, F. (2017a). Neural Word Segmentation with Rich Pretrain- ing. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL 2017).
Radford, A., Narasimhan, K., Salimans, T., and Sutskever, I. (2018). Improving Language Understanding by Generative Pre-Training.
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
Subramanian, S., Trischler, A., Bengio, Y., and Pal, C. J. (2018). Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning. In Proceedings of ICLR 2018.
Peters, M., Ruder, S., and Smith, N. A. (2019). To Tune or Not to Tune? Adapting Pretrained Representations to Diverse Tasks. arXiv preprint arXiv:1903.05987.
Howard, J. and Ruder, S. (2018). Universal Language Model Fine-tuning for Text Classification. In Proceedings of ACL 2018.
Smith, L. N. (2017). Cyclical learning rates for training neural networks. In Applications of Computer Vision (WACV), 2017 IEEE Winter Conference on, pages 464–472. IEEE.





