
یادگیری ماشین خودکار و جستوجوی معماری شبکۀ عصبی
تیم تحریریه
- ۵ بهمن ۱۴۰۰
یکی از مهمترین دستاوردها در حوزه هوش مصنوعی در سال 2018، یادگیری ماشین خودکار (AutoML) بود. این فناوری، فرایند یادگیری ماشین را خودکار میکند. شرکت گوگل در ژانویه این سال فرایند یادگیری ماشین خودکار را در مسائل بینایی ماشین به کار گرفت و سپس در ژوئیۀ همان سال نسخه دیگری از آن را در برنامههای ترجمه ماشین (Machine Translation) و پردازش زبان طبیعی (Natural Language Processing) استفاده کرد. شرکتهایی نظیر دیزنی نیز از هر دوی این بستهها برای حل مسائل عملی استفاده کردهاند.
پروژه AutoML شرکت گوگل بر پایه تکنیک جستوجوی معماری شبکه عصبی (NAS) طراحی شده است. این تکنیک در سال 2016 طراحی شده و در سال 2017 در همایش بینالمللی بازنماییهای یادگیری (ICLR) برای اولین بار به دنیای هوش مصنوعی معرفی شد. در این مقاله مروری خواهیم داشت بر تاریخچه یادگیری ماشین خودکار و مفاهیم اساسی تکنیک جستوجوی معماری شبکه عصبی.
تاریخچه
طوفان هوش مصنوعی از سال 2012 جهان را درنوردید. واژه «یادگیری ماشین» تبدیل به یک وِرد جادویی شد، وردی که میتوانست راهگشای مسائل و مشکلاتی باشد که انسان قادر به حل آنها نبود. استفاده از یادگیری ماشین در حوزه تبلیغات آنلاین، ارائه پیشنهاد به کاربران سامانههای مختلف، پیشبینی و شناسایی تراکنشهای جعلی، و چیزهایی نظیر این باعث شد تا عبارت «یادگیری ماشین» تقریباً به مترادفی برای خودکارسازی (اتوماسیون) تبدیل شود. اما جالب است بدانید در واقعیت، فرایند یادگیری ماشین تا حد زیادی به صورت دستی انجام میشود!
فرایندهای دستی در یادگیری ماشین: گزینش ویژگی
در یادگیری ماشین آماری (statistical machine learning) (همچون درخت تصمیم (Decision tree)، مدل ماشین بردار پشتیبان (SVM) و رگرسیون لجستیک (Logistic Regression)) ورودیهای لازم را برای پیشبینی انتخاب میکنیم. مثلاً برای پیشبینی اینکه چقدر احتمال دارد فردی یک قوطی نوشابه بخرد، دادههایی ازجمله سن فرد، جنسیت، درآمد، و غیره را به مدل میدهیم. در این فرایند در واقع تصمیم میگیریم کدام «ویژگیها» برای این موقعیت مناسب هستند و باید استفاده شوند. اما در این میان گاهی ممکن است برخی از ویژگیهای مهم، مثل موقعیت جغرافیایی فرد را از قلم بیندازیم. اصولاً میتوانیم هر تعداد ویژگی را که بخواهیم به مدل اضافه کنیم، اما این کار ممکن است عملکرد مدل یادگیری ماشین را تضعیف کند زیرا همه ویژگیها با مسئلهای که قرار است بررسی شود ارتباط ندارد. حتی اگر مدل قادر باشد تعداد زیادی ورودی دریافت کند، باز هم این ورودیها و ویژگیها باید بهصورت دستی به مدل وارد شود.
کار یک دانشمندِ داده این است که با نگاهکردن به دادهها، انجام آزمایشها و مصاحبه با متخصصان ویژگیهای خوب و مناسب را پیدا کند.
محققین حوزه بینایی ماشین دهههاست که در تلاشاند تا ویژگیهای خوب از قبیل کنتراست، میزان روشنایی، و هیستوگرام رنگها را برای خلاصهسازی یک تصویر پیدا کنند. اما هنوز هم یافتن ویژگیهای مناسب کاری دشوار است. وقتی ویژگیها (ورودیها) توسط انسان به مدل داده شوند، دقت فرایند بازشناسی تصویر حدود 70% و دقت فرایند بازشناسی گفتار بهندرت از 80% بالاتر خواهد رفت. برای سایر مسائل نیز همینطور است.
یادگیری عمیق: خودکارکردن فرایند گزینش ورودیها
تغییر و تحولاتی که در حوزه یادگیری عمیق (Deep Learning) رخ داده، این فرایند گزینش ویژگی را، که توسط انسان انجام میشد، خودکار کرده است. در حوزه بازشناسی تصاویر، تنها کافی است تصاویر را در سطح پیکسل به مدل بدهیم و دیگر نیازی نیست که به ویژگیهای مناسب فکر کنیم. ویژگیهای تصویر در لایههای نهان شبکه و در میان ارتباطات قدرتمند آن شناسایی میشوند. در حوزه ترجمه ماشینی نیز ما یک جمله را بهصورت کلمهبهکلمه یا حتی حرفبهحرف به مدل میدهیم و مدل، چینش کلمات این جمله را در زبانهای مختلف یاد میگیرد.
با یادگیری عمیق (فرایند یادگیری شبکههای عصبی عمیق) دیگر نیاز ما به اینکه ورودیها را بهصورت دستی به مدل وارد کنیم بهطور کامل برطرف شد. به همین دلیل، یادگیری عمیق به الگوریتمی جهانی تبدیل شد که میتوانست فرایند مدلسازی را سرعت ببخشد. در سال 2012 و در رقابتی به نام ImageNet، پس از حذف انسان از چرخه یادگیری ماشین، دقت فرایند بازشناسی تصویر با بیش از 10 درصد افزایش از 72% به 83% رسید.
فرایندهای دستی در یادگیری عمیق: انتخاب معماری شبکۀ عصبی
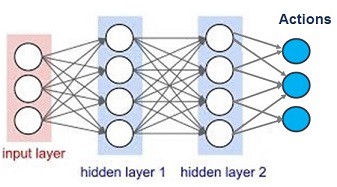
یادگیری عمیق با وجود تمامی نقاط قوت و توانایی تطبیقپذیری بالایی که دارد، همچنان به حضور و دخالت انسانها نیازمند است. اما این شبکهها در چه مقطعی نیاز به دخالت انسان دارند؟ در ادامه این مسئله را بررسی خواهیم کرد. تصویر زیر ساختار یک شبکه عصبی را نشان میدهد.
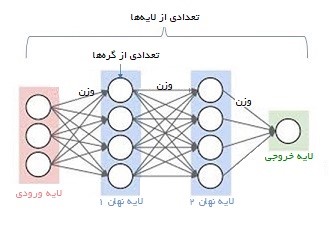
یک شبکه عصبی شامل نورونها، لایهها، و توابع فعالسازی میشود. قدرت اتصالات میان نورونها وزن نام دارد که مقدار آن در طول زمان و با یادگیری شبکه تعیین میشود.
معماری شبکۀ عصبی پیچشی (Convolutional Neural Network)
یک شبکه عصبی پیچشی از فیلترهایی (برای اجرای عملیات پیچشی) تشکیل شده است که تعداد نورونهای لایههای بعدی، لایهها، و تابع فعالسازی را تعیین میکنند.
فیلتر یک مکعب کوچک (مثلاً 5×5) است که وقتی روی تصویر اصلی اعمال شود، یک ناحیه با ابعاد 5×5 را به یک نقطه واحد در تصویر جدید تبدیل میکند. در تصویر زیر میتوانید این عملیات را مشاهده کنید.
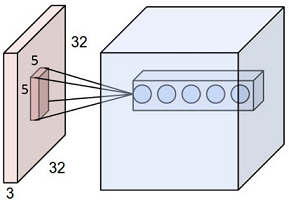
سایز تصویر اصلی 32×32 است و سایز فیلتر ما 5×5. این فیلتر یک ناحیه 5×5 از لایه اول را به یک نقطه در لایه بعدی تبدیل میکند. در اینجا 5 فیلتر داریم که در لایه دوم با 5 نقطه نمایش داده شدهاند.
گام (Stride) میزان حرکت فیلتر بر روی تصویر را تعیین میکند. برای مثال، وقتی گام برابر با 1×1 باشد، فیلتر به تعداد یک پیکسل به سمت راست و یک پیکسل به سمت پایین حرکت خواهد کرد و زمانی که گام برابر 1×2 باشد، فیلتر دو پیکسل به سمت راست و یک پیکسل به سمت پایین حرکت میکند.
اگر یک فیلتر 3×3 و یک گام 1×1 را به یک تصویر 6×6 اعمال کنیم، خروجی ما یک تصویر 4×4 خواهد بود.
بنابراین، یادگیری عمیق همچنان نیازمند حضور و دخالت انسان است تا درخصوص تعداد لایهها، اندازۀ فیلتر، عدد گام، و تابع فعالسازی تصمیم بگیرد.
جستوجو برای یافتن بهترین معماری شبکههای عصبی
ما تمام تحولات دنیای یادگیری عمیق را مدیون جستوجوی متخصصان برای یافتن بهترین معماری شبکه عصبی هستیم. در سال 2012، شبکه AlexNet تنها 8 لایه داشت؛ در سال 2014 برنده رقابتImageNet ، یعنی GoogleNet، 22 لایه داشت؛ و برنده این رقابتها در سال 2015Resnet بود که 152 لایه داشت.
افزایش تعداد لایهها و پارامترها به افزایش توان محاسباتی لازم و کاهش سرعت فرایند آموزش منجر شد. فرض کنید یک شبکه عصبی 100 لایه، و در هر لایه 100 نورون دارد. تعداد اتصالات میان نورونها در این شبکه برابر خواهد بود با یا همان یکمیلیون! در واقع شبکه Resnet دارای 1.7 میلیون پارامتر است. به عبارت دیگر، آموزش یک شبکه عصبی بسیار هزینهبر و زمانبر است. اگر شما نیز درحال انجام آزمایشهای مختلف برای یافتن بهترین شبکههای عصبی باشید، میدانید که برای دریافت نتایج هر شبکه باید چند روز تا چند هفته صبر کنیم و پس از آن با افزودن لایههای بیشتر به شبکه یا نورونهای بیشتر به یک لایه، فرایند آموزش را مجدداً تکرار کنیم و باز چندین روز صبر کنیم.
از طرفی ما میخواهیم به بالاترین دقت ممکن برسیم. آیا این بدین معناست که باید تعداد لایههای شبکه Resnet را افزایش دهیم؟ باید چند لایه برای این شبکه در نظر بگیریم؟ چه تعداد نورون (یا فیلتر) باید در هر لایه قرار بدهیم؟
یافتن پاسخ این سؤالات، یعنی تعیین تعداد درست لایهها و نورونها، مساوی است با پیداکردن بهترین معماری برای شبکه عصبی! از آنجا که هزینه محاسبات لازم برای جستوجو و بررسی تمام پارامترها یا پیکربندیها بسیار بالاست، باید راه هوشمندانهتری برای حل این مسئله پیدا کنیم.
ایدۀ اساسی جستوجوی معماری شبکه عصبی
فرض کنید یک عامل (کنترلکننده) داریم که میخواهد بهترین پیکربندی را پیدا کند. معماری یک شبکه عصبی را میتوان با چند پارامتر توصیف کرد: تعداد لایهها، تعداد گرهها و غیره. برای یک شبکه عصبی پیچشی (CNN)، معماری به معنای تعداد فیلترها و سایز فیلترهاست. کنترلکننده میتواند تعداد این پارامترها را انتخاب کند.
1- استفاده از الگوریتمهای یادگیری تقویتی (Reinforcement Learning) برای آموزش کنترلکننده
در دنیای یادگیری تقویتی، عامل اقدامی را انجام میدهد و نتیجه آن را مشاهده میکند. اگر یک اقدام منجر به دریافت نتیجه مثبت شود، عامل آن اقدام را بیشتر برمیگزیند و درعینحال اقدامات جدید را نیز بررسی میکند. عامل پس از بررسی چندین اقدام محتمل، اقدامی را که بیشترین پاداش را به همراه داشته انتخاب خواهد کرد.
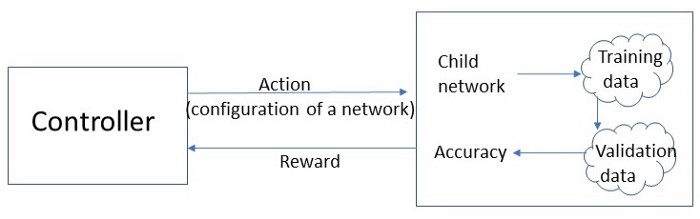
حال کنترلکننده باید مجموعهای از اقدامات را در پیش بگیرد، یعنی انتخاب ابعاد پارامترها. شبکه عصبی با در نظر گرفتن انتخاب کنترلکننده (اقدامات) ساخته میشود (در این مرحله هنوز وزنی به اتصالات تخصیص داده نشده است). این شبکه سپس توسط دادههای آموزش برای بهروزرسانی وزنها آموزش میبیند.
وقتی انتخابمان را انجام دهیم، یک شبکه ایجاد میشود. عملکرد این شبکه براساس دقت آن و بهوسیله مجموعهای از آزمونها در فرایندی با نام اعتبارسنجی سنجیده میشود که درنهایت پاداش ما را تعیین خواهد کرد.
هدف ما پیداکردن اقداماتی است که وقتی آنها را در چند زمان یا موقعیت مختلف تکرار کنیم پاداش نهایی را حداکثر کند.
2- استفاده از روش سیاست گرادیان (Policy Gradient Method): روش برخط یادگیری تقویتی
الگوریتمهای رایج یادگیری تقویتی برای دنبالکردن و ارزیابی عملکرد هر اقدام از Q-value استفاده میکنند. Q-value برابر است با مجموع پاداشهای موردانتظار در زمانهایی که عامل بهترین اقدامات را در پیش گرفته است. این کار نیازمند بررسی اقدامات و خروجیهای زیادی است که بسیار زمانبر خواهد بود. بهجای این کار، میتوانیم با مشاهده تغییرات پاداش فعلی، مستقیماً تأثیر اقدام را یاد بگیریم. این مفهوم، بنیان روش سیاست گرادیان است. در اینجا واژه «گرادیان» به معنای حرکت با تندترین شیب ممکن برای رسیدن به پاداش محتمل است.
وقتی برای یادگیری اقدامات از یک شبکه عصبی استفاده میکنیم، در واقع یک شبکه سیاست گرادیان یا شبکه سیاست (policy network) خواهیم داشت. این نوع شبکهها در الگوریتم آلفاگو (AlphaGo) نیز به کار گرفته شدهاند و به همین دلیل اخیراً بسیار مورد توجه قرار گرفتهاند.
این شبکه در مقاله اصلی شبکه فرزند (child network) نامیده شده است. واژه «فرزند» در اینجا در معنی بسیار دقیقی به کار رفته است. زیرا کنترلکننده (والد) یک شبکه خالی با تعدادی گره و لایه میسازد که وزنهای آن آموزش ندیدهاند. سپس این شبکه توسط دادههای آموزش برای بهروزرسانی وزنها آموزش میبیند و میتواند در زمان مواجهه با دادههای اعتبارسنجی عملکرد خوبی داشته باشد.
شبکه سیاست به هر اقدام یک احتمال نسبت میدهد و وزنهایش را بر اساس شیب (گرادیان) تغییر پاداش موردانتظار بهروزرسانی میکند. برای مثال، اگر در یک وضعیت 4 اقدام مختلف امکانپذیر باشند، احتمال هر یک 25/0 و خروجی به شکل [25/0, 25/0, 25/0, 25/0] خواهد بود و با T بار نمونهگیری بر اساس این توزیع اقدام، هر بار مقداری پاداش دریافت خواهید شد. سپس این پاداشها با هم جمع میشوند و وزنهای شبکه عصبی (سیاست) بر اساس شیب (گرادیان) پاداشها بهروزرسانی خواهند شد.
در این مقاله به فرمولهای پیچیده ریاضی این مباحث نمیپردازیم، اما بهطور خلاصه باید گفت که هر وزن بر اساس تابع لگاریتمی که روی پاداش کل اعمال شده، بهروزرسانی میشود.
کنترلکننده یک شبکه سیاست است
کنترلکننده بهخودیخود یک شبکه سیاست است که برای هر اقدام، بر اساس احتمالات، یک شبکه فرزند ایجاد میکند. این شبکه پس از دریافت پاداش، وزنهای داخلی را بهروزرسانی میکند. بهطور خلاصه، شبکه فرزندی که دقت بیشتری داشته باشد پاداش بیشتری دریافت میکند و بدین ترتیب، احتمال انتخابشدنش در شبکه سیاست بالاتر میرود.
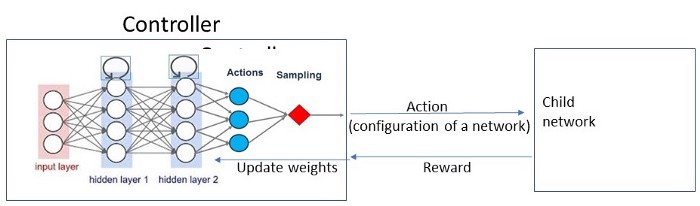
شبکه عصبی بهکاررفته در کنترلکننده، شبکه عصبی بازگشتی (recurrent neural network) است که امکان متغیربودن تعداد لایهها بین شبکههای فرزند را فراهم میکند.





