
الگوریتم Wav2vec 2.0: تشخیص خودکار گفتار با استفاده از نمونه 10 دقیقهای
 تیم تحریریه
تیم تحریریه- ۳ آبان ۱۴۰۰
در این مقاله قصد داریم به الگوریتم Wav2vec 2.0 بپردازیم. تلاشهای بیوقفه پژوهشگران برای ارتقای عملکرد سیستمهای خودکار تشخیص گفتار Automatic speech recognition (ASR) system و پیشرفتهای عظیمی که در حوزه فنآوریهای یادگیری ماشین حاصل شده و همچنین افزایش میزان دسترسپذیری به دیتاستهای بزرگ گفتار موجب شده میزان محبوبیت، تأثیرگذاری و تعداد نرمافزارهای کاربردی گفتار نسبت به گذشته افزایش یابد.
سیستمهای تشخیص گفتار کنونی به منظور داشتن عملکرد قابل قبول میبایست هزاران ساعت گفتار رونویسیشده Transcribed speech داشته باشند. هر چند 7000 زبان و گویش در سراسر جهان وجود دارد که شمار افرادی که به آنها تکلم دارند کم است و به همان نسبت حجم دادههای گفتاری موجود برای آنها نیز کم است و همین امر آموزش سیستمهای تشخیص گفتار مقاوم را با مشکل مواجه میکند.
پژوهشگران هوش مصنوعی فیسبوک برای کمک به توسعه و ارتقای عملکرد سیستمهای ASR در این دسته از زبانها و گویشها، الگوریتم wav2vec 2.0 را برای یادگیری خودنظارتی زبان در دسترس عموم قرار دادهاند.
Wav2vec 2.0: چارچوبی برای یادگیری خودنظارتی نمودهای گفتاری
نویسندگان مقاله «Wav2vec 2.0 : چارچوبی برای یادگیری خودنظارتی نمودهای گفتاری Wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations» مدعی شدهاند که «برای اولین بار اثبات کردهاند یادگیری بازنماییهای برجسته گفتار و تنظیم دقیق آن بر روی گفتار رونویسیشده میتواند به مراتب عمکرد بهتری از روشهای نیمهنظارتی داشته باشد و در همان حال به لحاظ مفهومی نیز آسانتر است.» هوش مصنوعی فیسبوک در توییتی اعلام کرد الگوریتم Wav2vec 2.0 میتواند مدلهای تشخیص خودکار گفتار تنها با اتکا به 10 دقیقه گفتار رونویسیشده توانا سازد.
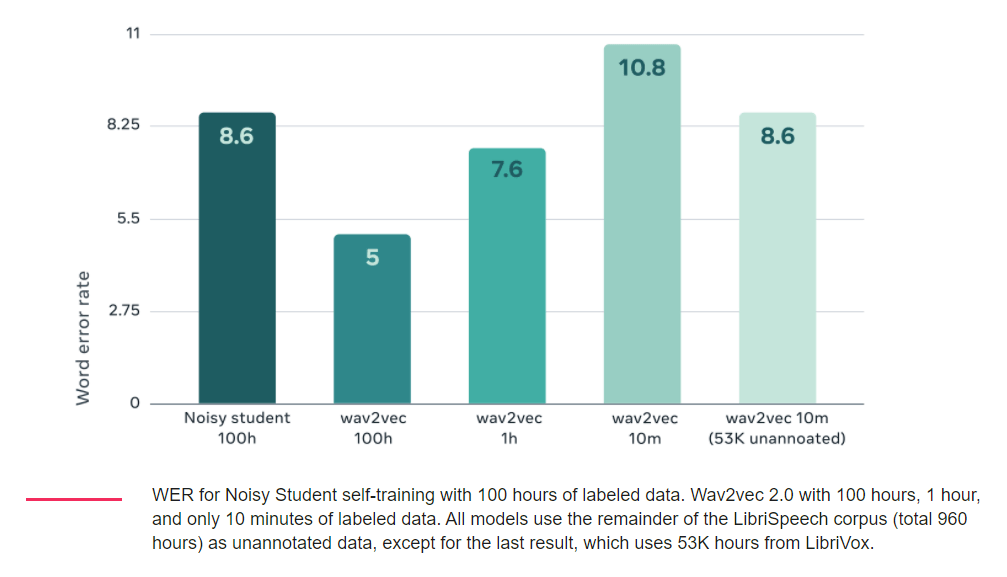
در مراحل آزمایشی Wav2vec 2.0 نسبت به روش کنونی تشخیص گفتار SOTA موسوم به Noisy Student در یک مجموعه 100 ساعته از پیکره مقیاسبزرگ Librispeech عملکرد بهتری داشت؛ حتی زمانیکه حجم دادههای برچسبگذاریشده به یک ساعت تقلیل یافت، عملکرد Wav2vec 2.0 بهتر از Noisy Student بود.
[irp posts=”20456″]عوامل تأثیرگذار بر عملکرد الگوریتم Wav2vec 2.0
به عقیده پژوهشگران هوش مصنوعی فیسبوک یادگیری بازنماییهای مناسب گفتار کلید موفقیت است. «یادگیری صرفاً با استفاده از بازنماییهای برچسبگذاریشده هیچ شباهتی به فرایند یادگیری زبان در انسانها ندارد: نوزادان زبان را با گوش کردن به صحبتهای بزرگسالان یاد میگیرند، فرایندی که لازمه آن یادگیری بازنماییهای خوب زبانی است.» به همین دلیل، پژوهشگران چارچوبی برای یادگیری خودنظارتی بازنماییهای موجود در دادههای صوتی خام طراحی کردهاند. پژوهشگران فایل صوتی گفتار را با استفاده از یکی از شبکه های عصبی پیچشی چند لایه رمزگذاری میکنند و سپس مدت زمان بازنماییهای گفتاری نهفته را ماسکگذاری میکنند تا بازنماییهای نهفته را به شبکه Transformer وارد کنند: در نتیجه شبکه Transformer میتواند بازنماییهای بسازد که اطلاعات را از کل توالی دریافت کند.
در این حالت، مدل جدید آموزش میبیند تا واحد گفتاری صحیح را برای بخشهای ماسکگذایشده صوت پیشبینی کند و همزمان واحدهای گفتاری را یاد بگیرد. شیوه طراحی این مدل، امکان ایجاد بازنماییهای مفهومی Context representations را بر روی بازنماییهای گفتاری پیوسته و وابستگیها را بر روی کل توالی نمودهای نهفته فراهم میکند.
این چارچوب باعث میشود مدل آموزش مقاومی داشته باشد و بهتر امواج خام مرتبط با گفتار را درک کند.
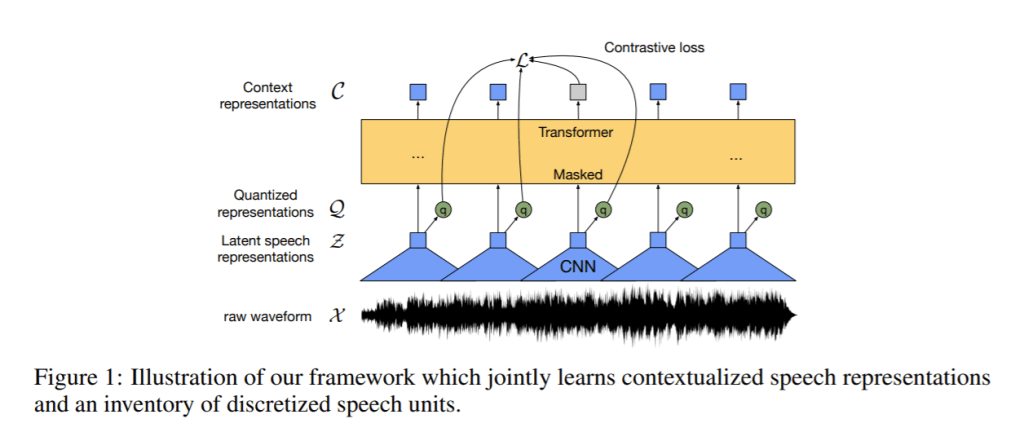
مدلهای تشخیص گفتار که الگوریتم wav2vec 2.0 در آنها اجرا شد توانستند به عملکردی مشابه SOTA دست پیدا کنند و نرخ خطای واژه Word error rate آنها در مجموعه داده LibriSpeech در گفتارهای نویزی 8.6 درصد و در گفتار بدون نویز 5.2 درصد باشد. این الگوریتم برای تنظیم دقیق فقط از ده دقیقه گفتار رونویسیشده یا همان دادههای برچسبگذاریشده استفاده کرد و برای پیشآموزش 53000 ساعت دادههای بدون برچسب استفاده شد.
نرخ دقت بالا
به عقیده پژوهشگران هوش مصنوعی فیسبوک الگوریتم خودنظارتی wav2vec 2.0 امکان ایجاد حجم کمی از دادههای حاشیهنویسی Annotated data را برای مدلهای تشخیص گفتار فراهم میکند و در همان حال نرخ دقت آن بالا خواهد بود. در این حالت مسائل مربوط به گویشها و زبانهایی که افراد کمی به آنها تلکم دارند و منابع آنها محدود است را بهتر میتوان اجرا کرد. علاوه بر این، الگوریتم wav2vec 2.0 میتواند تعداد زیادی از نرمافزارهای کاربردی این گونه از زبانها و گویشها را توانا میسازد. پژوهشگران هوش مصنوعی فیسبوک در تلاش هستند wav2vec 2.0 را برای اجرا بر روی Cloud TPUs آماده کند.





