
درک زبان طبیعی برای همه با بهرهگیری از BERT
تیم تحریریه
- ۳۰ مرداد ۱۴۰۰
BERT معادل واژه «نمایش رمزگذاری دوطرفه از ترانسفورمرها Bidirectional Encoder Representations from Transformers» است. زمانیکه برای اولینبار این تعریف را خواندم، مفهوم آن را درک نکردم. بنابراین اگر شما هم معنای آن را درک نکردهاید جای نگرانی نیست. زمانی که راجع به BERT مطالعه میکردم، متوجه شدم که بیشتر مقالات حاوی دانش پسزمینهای زیادی هستند که ممکن است درک آنها برای بسیاری از خوانندگان دشوار باشد، به همین دلیل تصمیم گرفتم مقالهای بنویسم و در آن BERT را به گونهای توضیح دهم که درک آن برای همه آسان باشد.
در ابتدا چرایی آن را توضیح میدهم. درک زبان طبیعی Natural Language Understanding (NLU) یکی از زیرشاخههای پردازش زبان طبیعی است. NLU با بهرهگیری از روشها و فنآوریهای گوناگون امکان درک زبان را برای ماشینها فراهم میکند. علاوه بر این NLU با بسیاری دیگر از جنبههای زبان از جمله گفتار و تولید سروکار دارد.
زبان وسیله برقراری ارتباط میان انسانها و همچنین وسیله کسب دانش است. چنانچه امکان درک زبان را برای ماشینها فراهم کنیم، رابط کاربری طبیعی و واقعی را فعال کردهایم و ماشینها میتوانند از دانشی که انسانها طی سالیان دراز در قابل متن جمعآوری کردهاند استفاده کنند. در این حالت نمیتوانیم ارزش تجاری چنین قابلیتهایی را ناچیز جلوه دهیم. اما زبان پیچیده است یا اگر بخواهیم دقیقتر بگوییم، درک متون زبان طبیعی برای ماشینها دشوار است.جمله زیر را در نظر بگیرید.
“My bank is on the other side of the river bank, I got there, but it was closed.”
معنای این جمله برای انسانهای ساده و بدیهی است، اما آیا برای ماشینها هم همینگونه است؟ همانگونه که میبینید، واژه “bank” دو بار و با دو معنای کاملاً متفاوت در جمله به کار رفته است. این حالت چندمعنایی نامیده میشود. مشکلی که در اینجا با آن مواجه هستیم این است که به دشواری میتوانیم تفاوت معنایی میان این دو واژه (Bank) و همچنین واژه «آن» را در این جمله توضیح دهیم. این حالت ابهام نامیده میشود. ما (انسانها) میدانیم که تفاوت معنایی در نتیجه تفاوت در بافت به وجود میآید، اما توضیح این مطلب برای یک الگوریتم، به گونهای که بتواند آن را درک کند، خیلی دشوار است.
چگونگی ادراک بافت زبانی
هرچند در زمینه عصبشناسی فعالیتی ندارم اما با استناد به مطالعاتی که در این زمینه داشتهام میدانم که نظریههای امروزی مدعی هستند پایه و مبنای درک انسان، تصورات است. ما با بهرهگیری از حافظه تجارب گذشته – اتفاقاتی که ممکن است تجربه کرده باشیم – داستانهایی که ممکن است شنیده باشیم و مناظری که ممکن است دیده باشیم و غیره زبان را درک میکنیم. به عبارت دیگر زمانی که جمله ذکرشده (مثال Bank) را می خوانیم، ساحل (Bank)، رودخانه، گذشتن از رودخانه و رسیدن به بانک و بسته بودن آن را تصور میکنیم. استنتاج معانی کلمات شبیه درست کردن یک پازل است. ما معنای مفاهیمی که میدانیم را درک میکنیم (مؤسسه مالی، یک سوی رودخانه و غیره) و با استفاده از تخیلاتمان آنها را در داستان جای میدهیم (عبور کردن، سوی دیگر، بستهبودن). اگر با موفقیت این کار را انجام دهیم، مفهوم جمله بالا را درک میکنیم. بافت داستان (یا بخشی از آن) است که ایجاد میکنیم تا معنای جمله را استنتاج کنیم.
بدیهی است که ماشینها قدرت تخیل و تصور ندارند. حتی اگر از بهترین الگوریتمهای NLU هم استفاده کنیم باز هم یک ماشین نمیتواند معنای Bank را درک کند (همانگونه که ما معنای آن را درک میکنیم)، اما این الگوریتم میتواند با استفاده از انواع گوناگون بافت پازلی ایجاد کند تا درک جمله آسان شود. این پازل مشابه پازلی که انسانها استفاده میکنند نیست اما NLU میداند چه کلماتی ارتباط معنایی بیشتری با کلمات دیگر دارند و اینکه چگونه این ترکیبات در زبان استفاده میشوند. به همین دلیل باید نمود متنی Text representation را به نمودی ساده برای ماشین تبدیل کنیم که: 1) از یک مقدار متفاوت برای هر کلمه (مفهوم) استفاده کند، 2) شامل بافت هم باشد.
تعبیه کلمه Word embedding به فرایند تبدیل متن به نمودی ساده برای ماشین گفته میشود. برای تعبیه کلمات روشهای متفاوتی از جمله Word2Vec ،GloVe و ELMO وجود دارد و میزان بافتی که ذخیره میکنند با دیگری متفاوت است. روشهای مختلفی برای ذخیره بافت وجود دارد، برای مثال اگر بسامد و همرخدادی واژگان را در مجموعه بزرگی از متون محاسبه کنیم، الگوریتمها میتوانند بافت را استنتاج کنند. واژگان در قالب بردارهای فرابُعدی نمایش داده میشوند (به عبارت دیگر در قالب فهرستهای طولانی از اعداد). با استفاده از برخی معادلات جبری خطی Linear algebra ساده میتوانیم فاصله میان این بُردارها را محاسبه کنیم و در نتیجه خواهیم دید که واژگان تعبیهشده – همانگونه که مفاهیم اصلی با زبان طبیعی ارتباط دارند – به روشهای یکسان با یکدیگر ارتباط دارند.

مفهموم دیگری که باید یاد بگیریم دنباله به دنباله است. این فرایند در دو مرحله انجام میشود: رمزگذاری و رمزگشایی. در مرحله رمزگذاری، دنبالهای از مقادیر را (برای مثال کلمات) به دنبالهای از مقادیر دیگر (برای مثال نمودهای قابل درک برای ماشینها) تبدیل میکنیم. در مرحله رمزگشایی هم مقادیر ر به فرمت اصلی (برای مثال زبان طبیعی) تبدیل میکنیم فقط ارزش تجاری آنها بیشتر می باشد. نمونه بارز فرایند دنباله به دنباله ترجمه ماشینی Machine Translation است. در ترجمه ماشینی دنبالهای از کلمات انگلیسی را دریافت میکنیم و سپس تعبیه کلمات را اجرا میکنیم و آنها را به دنبالهای از کلمات اما به زبان انگلیسی تبدیل میکنیم.
مبانی شبکههای عصبی
BERT معماری شبکه عمیق است، به همین دلیل در این مقاله برخی مبانی توپولوژی شبکه عصبی را مورد مطالعه قرار میدهیم تا در آینده بتوانیم درک بهتری از مبانی BERT داشته باشیم. ابتدا لازم است برخی مفاهیم پایه را تعریف کنیم: عصب، وزن و توپولوژی شبکه. عصب به واحد پایه محاسبات گفته میشود که چندین ورودی و یک خروجی دارد. عصب تابع سادهای، معمولاً میانگین وزنی ورودیهای خود را که اغلب مواقع یک تابع فعالسازی غیرخطی Non-linear activation function به دنبال آنها قرار دارد را به اجرا در میآورد و نتیجه را به صورت یک خروجی واحد ارائه میدهد. وزنها به ازای هر ضریب عصب هستند (که میانگین وزنی محاسبه میکند) که در طول فرایند آموزش شبکه آن را فرا میگیریم. و در آخر توپولوژی شبکه نوعی پیکربندی است که از آن برای متصل کردن عصبها به یکدیگر استفاده میکنیم تا یک شبکه ایجاد کنیم. توپولوژی شبکه مشخص میکند اطلاعات چگونه در شبکه جریان پیدا میکنند.
با توجه به تعاریفی که از این مفاهیم پایه ارائه دادیم اکنون میتوانیم اولین نوع توپولوژی شبکه یعنی شبکههای کاملاً متصل Fully Connected (FC) networks را تعریف کنیم. در شبکههای FC عصبها در قالب لایه نمایش داده میشوند. اولین لایه «لایه ورودی»، آخرین لایه «لایه خروجی» و تمامی لایههای میانی «لایههای پنهان» نامیده میشوند. تمامی عصبهایی که خروجی لایه قبلی هستند به عصبهای لایه کنونی متصل میشوند. معمولاً از شبکههای FC برای محاسبه تابع غیرخطی پیچیده ورودیها استفاده میشود؛ شبکههای FC را به سادگی میتوان موازی کرد اما در صورتیکه تعداد ورودیها زیاد باشد، انجام این کار بسیار دشوار خواهد بود.

دومین نوع توپولوژی، شبکه عصبی پیچشی است. برخی مواقع اندازه ورودی خیلی بزرگ است اما منطقی نیست که هر چیزی را به چیز دیگری متصل کنیم. برای مثال یک عکس معمولی از هزاران پیکسل تشکیل شده که به این معنا است اندازه عکس بزرگ است، با وجود این در عکسهای معمولی «بخشهایی» وجود دارد که زیاد وابسته نیستند (برای مثال ماشین سمت راست، بالا تأثیر کمی بر روی گل سمت چپ دارد)، در نتیجه بهتر است بخشهای مختلف تصویر را به صورت جداگانه پردازش کرد. در این حالت بهتر است از CNN استفاده کرد.

توپولوژی CNN نسبت به زمان آگاهی ندارد و همچون FC به سادگی میتوان آن را موازی کرد و علاوه بر این به لحاظ تغییرات در چندین بعد (تغییرات فضایی) قوی هستند و به همین دلیل CNNها مبنای پردازش تصویر مدرن هستند.
سومین توپولوژی شبکه عصبی بازگشتی Recurrent Neural Network (RNN) است. اگر دادهها به زمان وابسته باشند در معماری شبکه باید این مورد را لحاظ کنیم. در RNN ،شبکه دنبالهای از ورودیها به همراه خروجی تکرار قبلی دریافت میکند. در این حالت، RNN میتواند حافظه را ذخیره کند چرا که علاوه بر ورودیها، خروجیهای قبلی را هم پردازش میکند. متن دنبالهای از کلمات است و همانگونه که دیدیم معنای واژههای کنونی تا حد زیادی به متن قبلی وابسته است، از این روی RNNها اولین گزینه برای انجام مسائل مربوط به NLU هستند. ماهیت دنبالهای RNNها باعث میشود که به سختی بتوانیم آن را موازی بکنیم و به همین دلیل اجرای حافظه بلند هم دشوار است. علاوه بر این دیدیم متن قبلی و همچنین متن بعدی در ایجاد بافتی که معنای واژه کنونی را تعریف میکند نقش دارند و RNNها تلاش میکنند آن را ذخیره کنند.

از شبکههای عصبی بازگشتی تا ترانسفورمرها
تا چندی پیش اکثر شبکههای NLU مبتنی بر RNN یا CNN بودند تا اینکه در سال 2017 گوگل ایده ترانسفورمرها را مطرح کرد. ترانسفروماتور معماری جدیدی است (که از FC، CNN و RNN الهام گرفته شده است) و رویکرد جدیدی اتخاذ میکند و ثابت کرده که برای بسیاری از مسائل NLU نتایج بهتری به وجود میآورد. ترانسفورمرها نیز همانند CNN نسبت به زمان آگاهی ندارند و تمامی ورودیها (برای مثال متن) یکباره نمایش داده میشوند و سپس با استفاده از سازوکار خودتوجه سازوکار خودتوجه Self-attention mechanism, عملیات اجرایی را به صورت وزن دار بر روی کلمات مختلف موجود در متن تابع وزنی را اجرا میکند. به عبارت دیگر، ترانسفورمرها همچون عملیاتهایی که CNN بر روی تصاویر انجام میدهد، همزمان بر روی بخشهای مختلف ورودی کار میکنند اما همچون کاری که RNNها میکند، ماهیت دنبالهای متن را ذخیره میکنند. ترانسفورمرها دو تفاوت اصلی با RNNها دارند. اول اینکه ترانسفورمرها میتوانند با در نظر گرفتن یک کلمه خاص از متن بعدی ویژگیهایی بگیرند تا بافتی تولید کنند و به آسانی میتوان آنها را موازی کرد که در این حالت در مدت زمان مناسبی میتوان یادگیری بیشتری داشت. سازوکاری که تمامی این موارد را ممکن میسازد، خود توجه نامیده میشود.
توجه، تنها چیزی که به آن نیاز دارید
خود توجه روشی برای ذخیره ماهیت دنبالهای زبان (برای مثال اینکه کلمات چگونه بر سایر کلمات موجود در متن تأثیر میگذارند) بدون توپولوژی دنبالهای RNNها است. هدف خود توجه این است که با در نظر گرفتن سایر کلمات موجود در دنباله، یک کلمه را رمزگذاری کند، از این روی «درک» سایر کلمات مرتبط به رمزگذاری کلماتی بستگی دارد که در همان لحظه با آنها سر و کار داریم. به بیانی دیگر: در زمان رمزگذاری یک کلمه خاص، چه میزان به باقی جمله وروی توجه میشود. در این مقاله راجع به چگونگی محاسبه توجه توضیح نخواهم داد (مبحثی جالب اما دشوار) اما به شما پیشنهاد میکنم برای کسب اطلاعات بیشتر مقاله گوگل یا سایر مقالات مرتبطی که بر روی اینترنت وجود دارد را مطالعه کنید.
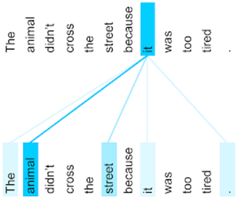
ترنسفورماتورها توجه چندگانه را پشتیبانی میکنند؛ به عبارت دیگر از چندین مجموعه ماسک توجه Attention mask که با مقداردهیهای تصادفی Random initialization محاسبه شدهاند به صورت موازی استفاده میکند. توجه چندگانه میتواند تشخیص دهد که یک کلمه خاص با توجه به سایر بخشهای جمله میتواند مجموعه تأثیرات و وابستگیهای متفاوتی داشته باشد. یکی دیگر از ویژگیهای مهم توجه این است که میتوان آن را به تصویر کشید، در این حالت میتوانیم وابستگیهای میان کلمات را که الگوریتم یاد گرفته، مشاهده کنیم.
ترانسفورمر
حالا تمامی اطلاعات و دانش مورد نیاز برای توصیف و درک ترانسفورماتوها را در اختیار داریم. ترانسفورمر جز سازنده BERT است. ترانسفورمر یک توپولوژی شبکه است که با استفاده از شبکههای کاملاً متصل مبتنی بر توجه رمزگذار و رمزگشا Encoder-decoder flow را پیادهسازی و اجرا میکند.
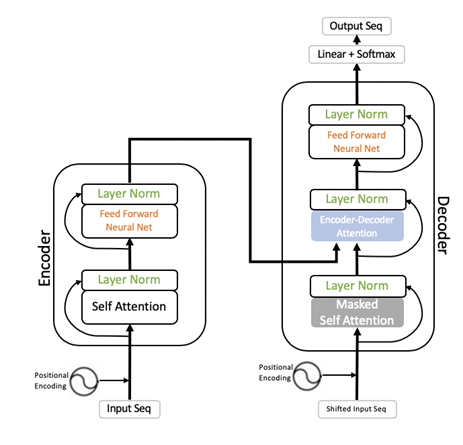
ورودیها تعبیه کلمات به همراه رمزگذاری مکانی Positional encoding است. ترانسفورمر با بهرهگیری از خودتوجه تمامی کلمات را با در نظر گرفتن سایر کلمات حاضر در دنباله رمزگذاری میکند. در مرحله بعد، ترانسفورمر از طریق نرمالسازی لایه Layer normalization ورودیها در سرتاسر ویژگیها نرمالسازی میکند (توجه داشته باشید که کلمات به فضای برداری چندبعدی نگاشت شدهاند). در رمزگشا ورودی را با استفاده از یک کلمه تغییر میدهیم، در نتیجه میتوانیم ترانسفورمر را آموزش دهیم که چگونه میتواند کلمه بعدی در جمله را پیشبینی کند. برای پیشبینی کلمه، ورودی رمزگشا باید پنهان شود (در نتیجه کلماتی که باید پیشبینی کند را نمیبیند)، پس رمزگشا از یک خودتوجه پوشیده برای ورودیهای خود استفاده میکند. توجه رمزگذار و رمزگشا پیش از فرایند پیشبینی، اطلاعات بافت را ترکیب میکند. در آخر، رمزگشا یک لایه نرمالسازی دیگر خواهد داشت و خروجیها نرمالسازی میشوند و در نتیجه نرمالسازی خروجیها چندین ترانسفورمر میتوانند با یکدیگر پشته شوند. اگر درک این مبحث برایتان دشوار بود، جای نگرانی نیست. تنها چیزی که لازم است بدانید این است که ترانسفورمرها جز سازنده شبکههای مدرن NLU هستند چرا که تمامی مزایا و نکات مثبت سه توپولوژی شبکه را با یکدیگر در خود جمع کردهاند. ترانسفورمرهای مبتنی بر شبکه توانمند اما هزینهبر هستند؛ این شبکهها معمولاً فضای زیادی از حافظه را اشغال میکنند و توان محاسباتی زیادی برای آموزش و همچنین استنتاج استفاده میکنند.
نمایش رمزگذاری دوطرفه از ترانسفورمرها (BERT)
در این بخش از مقاله BERT را معرفی خواهیم کرد. هر شبکه آرایهای از 12 لایه ترانسفورمر است که بر روی یکدیگر پشته شدهاند. این شبکه با سایر شبکههای مبتنی بر ترانسفورمر از جمله GPT متعلق به Open AI یا ELMO متعلق به AllenNLP که پیش از BERT معرفی شدند، تفاوت چندانی ندارد. چیزی که BERT را از سایر شبکهها متمایز میکند مسائل و مشکلاتی است که در طول فرایند آموزش، آموزش دیده تا آنها را حل کند. ویژگی دیگری که BERT را از سایر شبکهها متمایز میکند نحوه رمزگذاری ورودی مدل است است که شرایط آموزش را دچار تحول میکند.
ورودیها و خروجیها
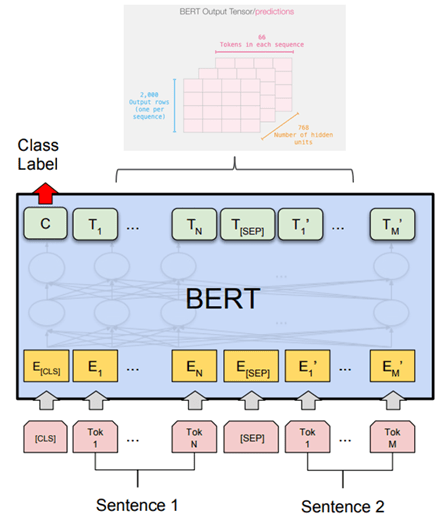
هر ورودی کلمه با استفاده از تعبیه خام Raw embeddings BERT در یک توکن Token تعبیه میشود؛ این توکن بستهای از کلمات، حدود 30000 کلمه، است. ورودی باید با یک توکن طبقهبندی خاص [CLS] آغاز شود و به دنبال آن یک یا چندین جمله که با یک توکن جداسازی [SEP] خاص جدا شدهاند، قرار بگیرد. واحدساز به هر یک از توکنهایی که رمزگذاری شدهاند یک مقدار اضافه میکند؛ این مقدار نشاندهنده شاخص جمله و شاخص ورودی مکانی است.

آرایه ترانسفورمرها اندازه ورودی و خروجی را تعیین میکند. معمولاً اندازه ورودی و خروجی 125، 256، 386 یا 512 کلمه است. اگر ورودی بیش از اندازه کوچک باشد، با صفر پر میشود و در صورتی که بیش از اندازه بزرگ باشد، باید آن را کوتاه کرد.
خروجیها (پیش از مرحله تنظیم دقیق Fine-tuning که در آینده راجع به آن توضیح خواهیم داد) فهرستی از بردارها هستند که اندازه آنها با فهرست ورودی برابر است. هر بُعد بردار (1، تعداد لایههای پنهان شبکه) برای مثال در مقیاس پایه BERT این مقدار 768 است. “C” اولین مقدار خروجی یک خروجی طبقهبندی است. شبکه آموزش دیده است، بنابراین مقدار طبقهبندی بر مبنای تمامی اطلاعاتی ساخته شده است که از ورودیها به دست آمده است. مقدار طبقهبندی را خلاصهای از متن در نظر بگیرید که از آن برای طبقهبندی متن همچون تحلیل احساسات استفاده میکنیم. باقی خروجیها بُردارهایی هستند که نشاندهنده تعبیه کلمه هستند (از جمله توکن خاص [sep]) که همانگونه که BERT آن را یاد گرفته است، شامل بافت است.
پیشآموزش
BERT دو کار بانظارت را از ویکیپدیا و BookCorpus آموزش دیده است:
1- کلماتی که به صورت تصادفی در جمله نشان داده نشدهاند را پیشبینی کند.
مدلسازی زبانی پوشیدهMasked Language Modeling (MLM)
2- مشخص کند که آیا جمله B میتواند در متن به دنبال جمله A قرار بگیرد یا خیر.
پیشبینی جمله بعدی Next Sentence Prediction
BERT از پیش آموزش دیده است که «معنا»ی کلمات حاضر در یک بافت را درک کند. درک معانی کلمات در وزنهای (~ میلیون) شبکه ذخیره میشود. پیش اموزش فرایندی طولانی و هزینهبر است. چنانچه قصد ساخت نوع جدیدی از BERT را ندارید، نیازی به پیشآموزش نیست، کافی است یکی از مدل از پیش آموزش دیدهشده را دانلود کنید و از آن استفاده کنید.
انواع BERT
گوگل انواع گوناگونی از BERT را عرضه کرده است. مدلهای BERT مشابه یکدیگر است اما تعداد ترانسفورمرها یا لایههای پنهان آن با یکدیگر تفاوت دارد (در شبکه FC ترانسفورمر). علاوه بر این به لحاظ متونی که برای آموزش استفاده شده نیز با هم تفاوت دارند؛ برای مثال، برخی مدلهای BERT با متونی به زبانهای مختلف آموزش دیدهاند در حالیکه برای آموزش برخی دیگر از مدلهای BERT از متونی استفاده میشود که برای حوزه و یا موارد کاربرد خاصی لازم است و غیره. بدیهی است که انواع مختلف BERT به لحاظ اندازه (تعداد وزنها) و عملکرد نیز با یکدیگر تفاوت دارند و به همین دلیل به سختافزارهای متفاوتی نیاز است. برای انتخاب بهترین مدل باید شرایط و ویژگیهای سختافزار، سرعت استنتاج، اندازه حافظه، سرعت آموزش و عملکرد مسائل خاص NLU (نحوه عملکرد مدل) را مد نظر قرار دهید. از زمانیکه گوگل انواع مختلف BERT را عرضه کرده است، شرکتهای دیگری از جمله فیسبوک و مایکروسافت هم انواع دیگری از BERT را عرضه کردهاند، در نتیجه مجموعه متنوع و غنیای از مدلهای BERT وجود دارد و میتوانید یکی از آنها را انتخاب کنید.
موارد کاربرد BERT
BERT چه کاربردهایی دارد؟ جامعه NLU طی سالیان چندین معیار استاندارد معرفی کردهاند (برای مثال GLUE که معادل واژه معیار ارزیابی درک زبان عمومی است) و تعداد زیادی دیتاست ساختهاند تا عملکرد را بر روی مسائل NLU محک بزنند. گوگل اعلام کرد که BERT « عملکرد قابل ملاحظهای در 11 مسئله NLP از جمله دیتاست پاسخدهی به سؤالات استنفورد داشته است».
پس اگر این سؤال برای شما پیش آمده که BERT چه کاربردهایی میتواند داشته باشد، در ادامه فهرستی از مسائل NLP ارائه شده که BERT میتواند در پیادهسازی و اجرای آنها به شما کمک کند.
- پاسخدهی به سؤالات.
(SQUAD 2.0 پاسخدهی به سؤالات، سؤالات طبیعی گوگل)
- تشخیص موجودیتهای اسمی Multi-task learning. ( یادگیری چندوظیفهای GLUE)
- خلاصهسازی خودکار Automatic summarization
- تحلیل احساسات
- طبقهبندی متن
- استلزام متنی و پیشبینی جمله بعدی
- وضوح همارجاعی
(پیدا کردن تمامی عباراتی که به یک موجودیت واحد در متن اشاره دارند)
- وضوح چندمعنایی و ابهام زدایی از کلمات
(انتخاب تعاریف مناسب دیکشنری در بافت)
- مسائل خاص دامنه پزشکی (BioBERT)
سایر مسائل از جمله ترجمه ماشینی مناسب مرحله تنظیم دقیق نیستند. اما تحقیقاتی راجه به شیوههای استفاده از BERT در ترجمه ماشینی انجام شده است.
تنظیم دقیق
به منظور استفاده از BERT برای مسئله خاصی از NLU از جمله پاسخدهی به سؤالات، یک لایه اضافی ، مختص به همان مسئله، بر روی شبکه اصلی BERT قرار میگیرد. سپس کل شبکه با یک دیتاست، مختص به همان مسئله و با استفاده از یک تابع زیان مختص به همان مسئله آموزش میبیند. برای مثال، برای مسئله پاسخدهی به سؤالات، میتوانیم از SQUAD 2.0 به عنوان دیتاست میزانسازی دقیق استفاده کنیم. SQUAD (دیتاست پاسخدهی به سؤالات استنفورد) شامل سؤالاتی است که از مقالات ویکیپدیا طرح شدهاند. در SQUAD پاسخ به هر سؤال بخشی از متن یا قسمتی از متن اصلی است و یا ممکن است برای سؤال پاسخی در نظر گرفته نشده باشد.
مدل BERT را میتوان در دو مرحله ساخت: 1) پیشآموزش 2) تنظیم دقیق.

زمانیکه مدل به طور دقیق میزانسازی شد، خروجیای که نشاندهنده نتایج مسئلهای خاص از NLU است، فقط به تعبیه کلمه محدود نخواهد بود بلکه شامل مقادیر مختص به همان مسئله هم خواهد بود. برای مثال، برای مسئله پرسش و پاسخ، شبکه محتملترین شاخص جواب را در متن به عنوان خروجی ارائه میدهد.

چارچوبهای پیادهسازی
خوشبختانه پیادهسازی و اجرای یک مسئله NLU در نرمافزارهای کاربردی کار دشواری نیست چرا که متنبازها و بستههای زیادی وجود دارد که استفاده از آنها فرایند تجهیز توسعه نرمافزار کاربردی به BERT را راحتتر میکند. BERT نیز یک متنباز است و شامل متون و کدهای مفیدی است که میتوانید دوباره از آنها استفاده کنید. بسیاری از پروژهها ، همچون پیادهسازی رسمی گوگل، به زبان پایتون و بر مبنای Tensorflow یا Pytorch هستند.
در مقابل لیست نهایی کتابخانههای متن باز ارائه شده است که فرایند تنظیم دقیق و استنتاج با استفاده از مدلهای BERT را آسان میکنند.
- huggingface/ transformers (مشهورترین کتابخانه کنونی)
- fastbert
- Deeppavlov
- BERT as service
مدلهای زیادی وجود دارد که به طور دقیق تنظیم شدهاند در نتیجه برخی موارد حتی لازم نیست مدلی آموزش دهید. اگر بخواهید از دیتاست خودتان هم استفاده کنید با یک جستوجوی ساده در اینترنت نمونهها و راهنماییهایی زیادی برای میزانسازی دقیق یک مدل پیدا خواهید کرد.
فراتر از BERT
BERT نقطه عطف بزرگی در تحقیقات و پژوهشهای NLU است، اما این به این معنا نیست که میتوان دست از تلاش برداشت، چرا که «مشکلات NLU» هنوز به طور کامل حل نشدهاند. در ادامه سه مقوله پژوهشی مرتبط را معرفی میکنم.
1– مختصر کردن BERT
احتمالاً BERT بیش از اندازه پارامتری است. مدلی که امروزه در اختیار داریم بزرگ است و نیازمند سختافزارهای گران است و زمان زیادی برای محاسبه نیاز دارد. پژوهشگران به دنبال روشی هستند تا مدلهای کوچکتر اما با همان کیفیت در عملکرد بسازند. DistilBERT نمونهای از این مدلها است. امیدواریم در آینده بتوانیم مسائل NLU را اجرا کنیم.
2– معیارهای جدید برای مسائل پیچیدهتر NLU
معیارها و دیتاستها نقش یک قطبنما را برای توسعهدهندگان مدلها دارند. جوامع پژوهشی در حال تحقیق و پژوهش در زمینه مشکلات جدید با دیتاستهای منطبق هستند. جوامع پژوهشی امیدوارند توسعهدهندگان مدلها بتوانند راهکاری کارآمد طراحی و عرضه کنند. برای مثال:
- Long-Form Question Answering (ELI5 – Explain Like I am 5)
« در این فرایند با دو چالش مواجه هستیم: اطلاعات مرتبط در یک سند طولانی را تفکیک کنیم و در پاسخ به سؤالات مختلف و پیچیده به اندازه یک پاراگراف توضیح دهیم.»
- مدلسازی زبانی بلند مدت Long-range language modeling
به جای تحلیل 512 کلمهای که BERT امروزه پشتیبانی میکند، متن کتاب را تحلیل کنیم.
3– گشودن جعبهسیاه و آگاهی نسبت به عملکرد BERT
ما میدانیم که BERT کار میکند (کارایی لازم را دارد)، اما با این حال بخش زیادی از چگونگی عملکرد آن اصطلاحاً به صورت جعبهسیاه میباشد. یعنی فرایند آن برای انسان قابل درک نمی باشد. اگر بتوانیم به نحوی بهتر به سؤالاتی از قبیل «به چه چیزی باید توجه کنیم؟»، « درک زبان در کجا و چگونه رمزگذاری میشود؟» پاسخ دهیم میتوانیم راهکار را ارتقا دهیم.
BERT در محصولات کنونی
BERT نسبتاً جدید است اما در حال حاضر در محصولاتی که به صورت روزانه استفاده میکنیم، پیادهسازی و اجرا میشود. گوگل اعلام کرده که از BERT در موتور جستوجوی خود برای رتبهبندی و همچنین Featured snippets استفاده میکند.
«… یکی از چشمگیرترین پیشرفتها در تاریخ جستوجو.»
- در حال حاضر موتور جستوجوی گوگل بهتر میتواند بافت نتایج یافتشده را درک کند و آن را رتبهبندی کند.
مایکروسافت مدل ارتقایافتهای از BERT عرضه کرده است (MT-DNN)
- در LUIS استفاده میشود – سرویس شناختی MS NLU و QnA Maker
فیسبوک از BERT خود موسوم به RoBERTa استفاده میکند که به منظور طبقهبندی و پالایش پستها از آن استفاده میشود.
پس در عصر جدیدی زندگی میکنیم، عصر BERT






