داده کاوی سحاب ؛ توسعه ابزار برای توسعهدهندگان، شبکههای اجتماعی و متنکاوی
 تیم تحریریه
تیم تحریریه- ۱۱ مهر ۱۴۰۰
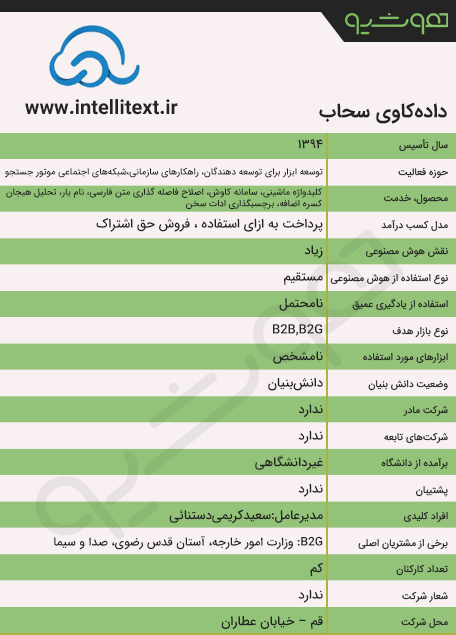
شرکت داده کاوی سحاب از سال 1394 فعالیت خود را در حوزه یادگیری ماشین و پردازش زبان طبیعی آغاز کرد. از جمله زمینههای فعالیت این شرکت دانشبنیان می توان به توسعه ابزار برای توسعهدهندگان، راهکارهای سازمانی، شبکههای اجتماعی و متنکاوی متون فارسی اشاره کرد.
داده کاوی سحاب، بازیابی اطلاعات متنی، داده کاوی و تحلیل شبکههای اجتماعی را به عنوان مهارتهای خود معرفی کرده است. کلیدواژه ماشینی، شناسایی موجودیتهای اسمی، سامانه کاوش، اصلاح فاصله گذاری متن فارسی، نام یار، تحلیل احساسات، تحلیل هیجان، برچسبگذاری ادات سخن و کسره اضافه از جمله محصولات این شرکت محسوب شده و از جمله مشتریان آن میتوان به وزارت امور خارجه، خبرگزاری فارس، آستان قدس رضوی، دفتر تبلیغات اسلامی حوزه علمیه قم، وزارت فرهنگ و ارشاد اسلامی، سازمان بسیج مستضعفین و صداوسیما اشاره کرد.
مشتریان شرکت داده کاوی سحاب
کلیدواژه ماشینی شاملترکیبی از روشهای مبتنی بر ناظر و بدون ناظر است. در این روش ابتدا لیست کلیدواژههای کاندید استخراج میگردد و پس از تعیین ویژگیهای هریک از آنها، کلیدواژهها بر اساس یک روش رنکینگ قوی مرتب میگردند. این روش رنکینگ با استفاده از نرمالسازی ویژگیها و الگوریتم ژنتیک نتایج را تا دو برابر بهتر کرده است.
سحاب پرداز مدعی استنتایج آزمایشها بر روی پیکرهای از متون خبری فارسی میزان 28.8% معیار f را نشان میدهد. سامانه کاوش، موتور جستجوی سازمانیِ تمام متنی است که برای زبان فارسی بومیسازی شده است. کاوش با نمایهسازی محتوای متنی و با بهرهگیری از فناوریهای هوشمند، نتایج مطلوب را استخراج، رتبهبندی و به نمایش میگذارد.
تحلیل هیجان (Emotion Analysis) محصول دیگری از داده کاوی سحاب است. این محصول برای تشخیص هیجان در متون فارسی طراحی شده که در نوع خود اولین محسوب میشود. در تحقیقات گذشته انواع متعددی از هیجان اسم برده شده است که معروفترین آنها عبارتند از شادی، غمگینی، ترس، نفرت، خشم، تعجب، اعتماد و انتظار. کسره اضافه محصولی از سحاب است که با استفاده از الگوریتم میدانهای مغناطیسی شرطی یا CRF کسره اضافه را به صورت اتوماتیک شناسایی میکند.
دقتاین محصول بیش از 98 درصد و سرعت آن بالغ بر ۱۰۰ هزار کلمه بر ثانیه است. کاربردهای متنوعی را برای این ابزار میتوان متصور بود. مانند استفاده در ابزارهای تبدیل متن به گفتار، استفاده در سیستمهای استخراج کلیدواژه ماشینی، ترجمه ماشینی، تشخیص موجودیتهای اسمی و بسیار کاربردهای دیگر.
شناسایی موجودیتهای اسمی با استفاده از یکی از الگوریتمهای برچسبگذاری دنبالهای با نام Conditional Random Fields (CRF) اسامی درون متن را شناسایی و برچسب گذاری میکند. از جمله کاربردهای این ابزار میتوان تگگذاری اخبار رسانه ها، تقویت موتورهای جستجو و سیستمهای مرجع ضمیر اشاره کرد. سرویس اصلاح فاصلهگذاری، متن فارسی را طبق قواعد سبک جدانویسی به صورت هوشمند، اصلاح میکند.
نامیار
نامیار محصولی است که با هدفایجاد یک دستیار در حوزه نام و نامگذاری، طراحی شده است. این محصول قادر است نامهای معتبر را از غیر معتبر شناسایی کرده و از ثبت نامهای غیر معقول جلوگیری نماید. تحلیل احساسات ابزاری است که قادر به شناسایی جملات از لحاظ احساسی بودن یا نبودن، نوع احساسات و درجه آن است.
شناسایی برچسب صرفی یک کلمه یا همان برچسب ادات سخن، یکی از پایهایترین نیازهای پردازش هوشمند متون محسوب میگردد. طیاین فرایند نوع کلمات از لحاظ اسم، فعل و حرف بودن شناسایی شده و جزئیات بیشتری نیز از آن در قالب برچسب ارائه میگردد. به گفته داده کاوی سحاب،این ابزار یکی از قویترین برچسبگذارهای حال حاضر زبان فارسی محسوب میشود که توانایی شناسایی 14 برچسب مهم صرفی را دارا است.
داده کاوی سحاب در یک نگاه