
پایگاه داده MLDB ؛ رویای همه دانشمندان داده
 تیم تحریریه
تیم تحریریه- ۱۸ اسفند ۱۴۰۰
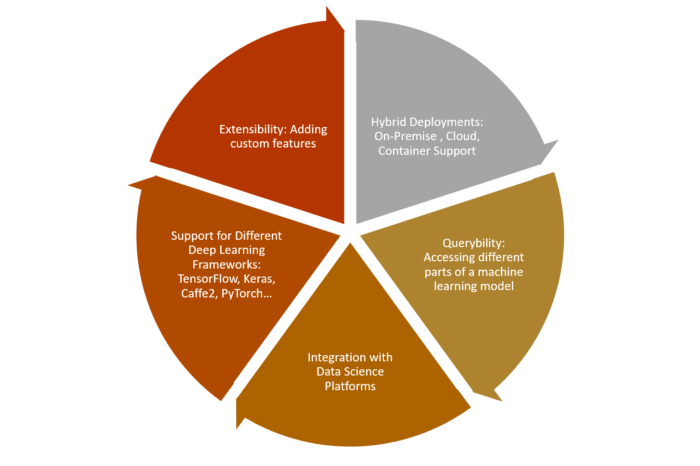
به پایگاه داده MLDB خوش آمدید
MLDB به یک پایگاه داده متن باز برای ذخیره و جستجوی مدل یادگیری ماشین اطلاق میشود. این پلتفرم برای نخستین بار در Datacratic به کار گرفته شد. مرکز هوش مصنوعی Elementai به تازگی این پلتفرم را خریداری کرده است. MLDB در اَشکال مختلفی نظیر سرویس ابری، VirtualBox VM یا نمونه Docker قابل دسترس میباشد. در معماری MLDB، ویژگیهای مختلفی در نظر گرفته شده است. این ویژگیها در خلاصهسازیِ عناصر مختلف چرخه عمر راهحل یادگیری ماشین به ایفای نقش میپردازند. از دیدگاه فنی، میتوان مدل MLDB را در شش مولفه ساده خلاصه کرد: فایل، دیتاست، راهکار، نقش، جستجو و API.
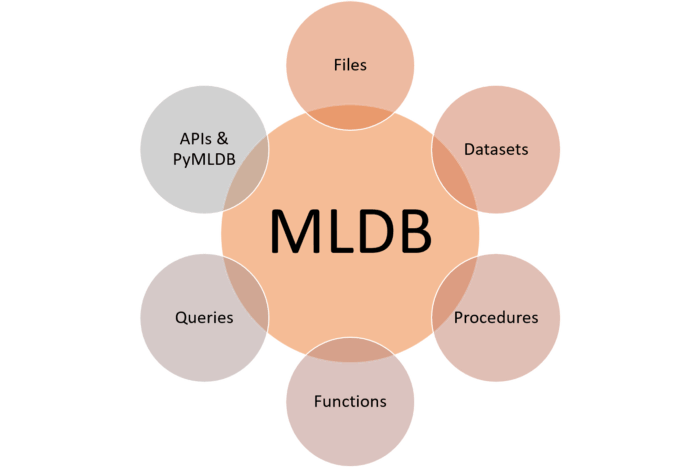
فایل
در مدل MLDB، امکان استفاده از فایلها برای بارگذاری داده در مدل وجود دارد. MLDB میتواند زمینه را برای ادغام محلی با سیستمهای فایل مشهور از قبیل HDFS و S3 فراهم کند.
دیتاست
دیتاست MLDB بر واحد داده اصلی تاکید دارد که مدلهای یادگیری ماشین از آن استفاده میکنند. به لحاظ ساختاری، دیتاست به مجموعهای بدون طرح از نقاط دادهای میگویند که درون سلولها جای گرفتهاند. خودِ این سلولها نیز از ردیف و ستون تشکیل یافتهاند. نقاط دادهای از مقدار و نشانگر زمانی تشکیل یافتهاند. بنابراین، هر نقطه داده میتواند به صورت چندتایی نشان داده شود (ردیف، ستون، مقدار، نشانگر زمانی). همچنین، میتوان دیتاستها را به عنوان متریکهای پراکندهی سهبعدی در نظر گرفت. دادهها از طریق REST API به دیتاستها ضمیمه میشوند.
راهکار
از راهکارها در MLDB برای اجرای جنبههای مختلف مدل یادگیری ماشین مثل آموزش یا تبدیل داده استفاده میشود. از دیدگاه فنی، راهکار به برنامههای نامداری با قابلیت استفاده مجدد اطلاق میشود که در اجرای عملیات دستهای طولانی به کاربرد دارد. راهکارها عموماً در دیتاستها به اجرا در میآیند و امکان پیکربندی آنها با عبارات SQL وجود دارد. خروجی راهکار یا Procedure عبارتست از دیتاست و فایل.
نقش
نقش یا Function در MLDB به خلاصهسازیِ فعالیتهای روزمره محاسبه داده میپردازد. به عبارت دیگر، نقش به برنامه نامدار با قابلیت استفاده مجدد گفته میشود که در اجرای محاسبات اصلی نقش دارد. در این محاسبات، دریافت مقادیر ورودی و ارائه مقادیر خروجی در دستور کار قرار دارد.
جستجو
یکی از مزایای اصلی MLDB این است که از SQL به عنوان سازوکاری برای جستجوی دادههای ذخیره شده در پایگاه داده استفاده میکند. این پلتفرم از دستور زبان نسبتاً کاملی که حاوی ساختهای آشنایی مثل SELECT، WHERE، FROM، GROUP BY، ORDER BY و غیره است، پشتیبانی به عمل میآورد. برای نمونه، در MLDB میتوان از جستجوی SQL برای آماده کردنِ دیتاست در مدل طبقهبندی تصاویر استفاده نمود:
mldb.query("SELECT * FROM images LIMIT 3000")
APIs & Pymldb
تمامی قابلیتهای MLDB با REST API نشان داده میشود. این پلتفرم حاوی کتابخانهای موسوم به pymldb است که قابلیتهای API را به زبان ساده خلاصه میکند. شیوه استفاده از pymldb و جستجوی دیتاست در کد زیر نشان داده شده است.
from pymldb import Connection
mldb = Connection("http://localhost")mldb.put( "/v1/datasets/demo", {"type":"sparse.mutable"})
mldb.post("/v1/datasets/demo/rows", {"rowName": "first", "columns":[["a",1,0],["b",2,0]]})
mldb.post("/v1/datasets/demo/rows", {"rowName": "second", "columns":[["a",3,0],["b",4,0]]})
mldb.post("/v1/datasets/demo/commit")df = mldb.query("select * from demo")
print type(df)
پشتیبانی از الگوریتمهای یادگیری ماشین
MLDB از تعداد زیادی الگوریتم پشتیبانی میکند. این پلتفرم از گراف محاسبهی موتورهای یادگیری عمیق مختلف (مِن جمله تنسورفلو) پشتیبانی میکند.
حال بیایید یک چرخه کاری مشترک در راهحلهای یادگیری ماشین (مثل آموزش و امتیازدهی به مدل) را بررسی کنیم؛ شکل زیر نحوه اجرای آن را در MLDB نشان میدهد:
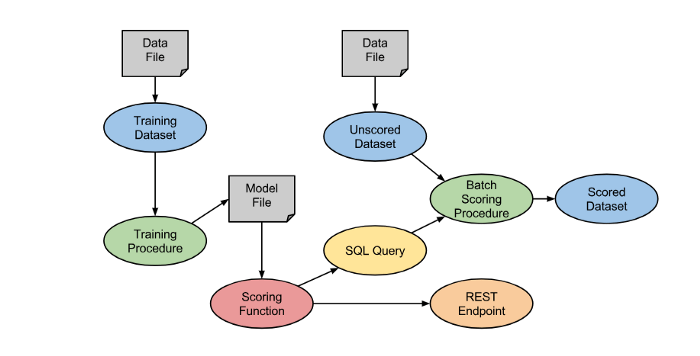
1. این فرایند با فایلی مملو از دادههای آموزشی آغاز میشود. این دادهها در دیتاست آموزش بارگذاری میشوند.
2. راهکار آموزش برای ایجاد فایل مدل به اجرا در میآید.
3. از مدل فایل برای تعیین پارامتر «امتیازدهی » استفاده میشود.
4. گزینه امتیازدهی از طریق REST Endpoint قابل دسترس است.
5. گزینه امتیازدهی از طریق SQL Query نیز قابل دسترس است.
6. در گزینه امتیازدهی دستهای از SQL برای بکارگیری Scoring Function در دیتاستهایی که به آنها امتیاز داده نشده است، استفاده میشود.
نتیجهگیری
MLDB یکی از نخستین پایگاههای دادهای به شمار میرود که برای بررسی راهحلهای یادگیری ماشین طراحی گردیده است. باید ارتقای این پلتفرم را در دستور کار قرار داد تا از روشهای جدید یادگیری عمیق و یادگیری ماشین پشتیبانی نماید. این پلتفرم از انعطافپذیری و توسعهپذیری برخوردار است.





