شرکت های بزرگ فناوری مؤلفههای یادگیری ماشین مخصوص به خود را میسازند
 تیم تحریریه
تیم تحریریه- ۹ فروردین ۱۴۰۱
یادگیری ماشین نقش بسیار مهمی در عملکرد تمام شرکت های بزرگ دارد. بسیاری از شرکتها در حال ساخت سامانه یادگیری ماشین مخصوصبهخود هستند. با اینکه این سامانهها از فناوریهای متنباز بهره میبرند، اما تعدادی از عملکردها نیاز به راهحلهای شخصیسازیشده دارند، به همین دلیل شرکتها در زمینه ساخت مؤلفههای مخصوص برای سامانههای یادگیری ماشین خود سرمایهگذاری میکنند. در این مقاله، تعدادی از این شرکتها را معرفی میکنیم.
شرکت اوبر (Uber)
این شرکت در سال 2017 سامانه Michelangelo را عرضه کرد. هدف از ساخت این سامانه اختصاصی «یادگیری ماشین بهعنوان سرویس» این است که مقیاسپذیری هوش مصنوعی را به اندازه رزرو تاکسی، آسان کند. سرویس تاکسیرانی شرکت، در سه ماهه نخست سال 2020، روزانه بهطور متوسط 1658 میلیون سفر انجام داد؛ این امر به این معناست که شرکت روی گنجینهای از دادههای غنی خوابیده بوده است.
سرویس تاکسیرانی شرکت در ابتدا برای حل مشکلات مختلف به مدلهای پیشبینی مجزا یا سیستمهای کوچکتر، متکی بود؛ اما این سیستمها، راهحلهای کوتاهمدتی بودند که پاسخگوی سرعت رشد سیستمهای هوش مصنوعی اوبر نبودند. از این رو Michelangelo به صحنه آمد. این سامانه، در حال حاضر در چندین مرکز داده اوبر بهمنظور پیشبینی خدمات آنلاین بارگذاریشده شرکت به کار گرفته شده است.
Michelangelo شامل چند سیستم متنباز است که از مؤلفههایی مانند HDFS ،Spark ،Cassandra ،MLLib ،XGBoost ،Samza و TensorFlow تشکیل شده است. شرکت اوبر در کنار استفاده از سیستمهای متنباز، تعدادی از مؤلفههای Michelangelo را خود تولید کرده است.
Horovod؛ یک چارچوب آموزشی توزیعشده متنباز برای کتابخانههای TensorFlow، PyTorch و MXNet است. وظیفه آن، سرعت بخشیدن و تسهیل یادگیری عمیق توزیعشده است. این چارچوب از الگوریتم ring-allreduce استفاده میکند و به کمترین اصلاحات برای کد کاربر نیاز دارد. بهوسیله Horovod، میتوان اسکریپت آموزشی را به قدری گسترش داد که با استفاده از چند خط کد پایتون، بر روی صدها GPU، اجرا شود. Horovod را میتوان هم بر سامانههای در محل (on-premise) و هم بر روی سامانههای ابری نصب کرد؛ به علاوه، میتوان آن را روی Apache Spark هم اجرا کرد و اینگونه پردازش داده و آموزش مدل را یکی کرد. پس از پیکربندی، از همان زیرساخت یکسان میتوان برای آموزش مدلها در هر چارچوبی استفاده کرد و بین کتابخانههای TensorFlow، PyTorch و MXNet جابهجا شد.
Ludwig هم یک جعبهابزار یادگیری عمیق متنباز از شرکت اوبر است که بر روی TensorFlow ساخته شده است. این سامانه به کاربران امکان میدهد که بدون کدنویسی، مدلهای یادگیری عمیق را آموزش داده و آزمایش کنند. Ludwig یک سامانه AutoML است که مجموعهای از معماریهای مدل را فراهم میکند. این معماریها را میتوان در موارد خاص، برای ایجاد یک مدل نقطهبهنقطه، ترکیب کرد. این سامانه از عملکردهایی مانند طبقهبندی متن، تحلیل احساسات، طبقهبندی تصویر، ترجمه ماشینی، نوشتن زیرنویس تصویر و غیره، پشتیبانی میکند.
نتفلیکس
نتفلیکس که در سال 1997 کار خود را بهعنوان یک سامانه اجاره DVD آغاز کرد، با بیش از 209 میلیون مشترک، تبدیل به غول صنعت نمایش شده است. در اوج همهگیری کرونای سال گذشته، بیش از 500 برنامه جدید به نتفلیکس ایالات متحده اضافه شده است. یکی از اصلیترین عوامل تسریع رشد این شبکه، سیستم توصیهگر آن بوده است که از بهترینهای این صنعت محسوب میشود. این الگوریتم توصیهگر شخصیسازیشده که نقش اصلی را در حفظ مخاطب ایفا میکند، موجب شده است که نتفلیکس، سالانه یک میلیارد دلار سود کند. علاوه بر این، بیش از 80 درصد برنامههایی که افراد در نتفلیکس تماشا میکنند، از طریق سیستم توصیهگر آن پیدا میشوند.
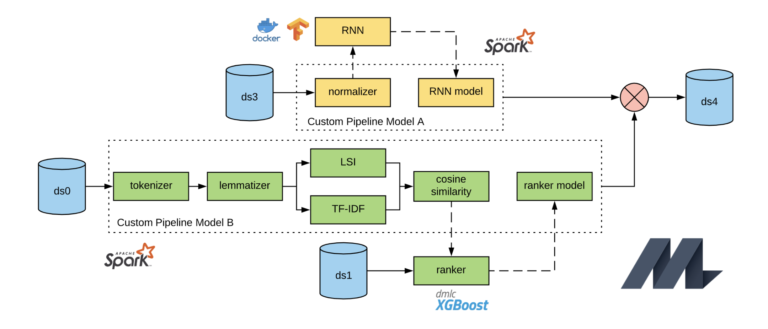
برخی از مؤلفههای داخلی که بهوسیله گروه یادگیری ماشین نتفلیکس توسعه یافتهاند، عبارتاند از:
Metaflow که طی چهار سال توسعه یافته است، چارچوبی فولاستک برای علم داده است. این کتابخانه که در سال 2019 به صورت متنباز منتشر شد، به شرکت نتفلیکس امکان میدهد که مراحل کاری یادگیری ماشین را تعریف کند، آنها را آزمایش کند، در فضای ابری قرار دهد و در نهایت از آن برای تولید استفاده کند. Metaflow یک کتابخانه کاربرپسند پایتون و R است که دانشمندان و مهندسان میتوانند پروژههای واقعی علم داده را روی آن بسازند و مدیریت کنند. این کتابخانه بهراحتی، توانایی انتخاب روش مدلسازی مناسب، مدیریت داده و ساخت مراحل کاری را به دانشمندان علم داده ارائه میدهد و همچنین تضمین میکند که نتیجه پروژه بهسرعت بر روی زیرساخت تولید، اجرا میشود.
نتفلیکس در اصل این پروژه را بهمنظور افزایش بهرهوری دانشمندان علم دادهای توسعه داد که بر روی پروژههای مختلف، از آمار سنتی گرفته تا یادگیری عمیق پیشرفته فعالیت میکردند. چندین شرکت دیگر نیز برای تقویت یادگیری ماشین در حال تولید خود از آن استفاده کردهاند.
Polynote: نتفلیکس دارای یک نوتبوک چندزبانه به نام Polynote است که از زبان اسکالا (Scala) نیز پشتیبانی میکند. این نوتبوک در بر دارنده موتور آپاچی اسپارک (Apache Spark) است که از زبانهای مختلفی مانند اسکالا، پایتون، SQL و غیره، پشتیبانی میکند. Polynote، برای دانشمندان علم داده و مهندسان یادگیری ماشین، محیط نوتبوکی را فراهم میکند که میتواند بهصورت یکپارچه با سامانه یادگیری ماشین نتفلیکس که مبتنی بر ماشین مجازی جاوا (JVM) است و کتابخانههای محبوب یادگیری ماشین و بصریسازی پایتون ادغام شود.
Airbnb
تا سال 2016، شرکت Airbnb با مدلهای یادگیری ماشین در حال تولید، دستوپنجه نرم میکرد؛ توسعه این مدلها نهتنها وقت زیادی میبرد بلکه نامنسجم هم بودند. علاوه بر این، تناقضهای عمدهای بین دادههای آنلاین و آفلاین وجود داشت. Airbnb با در نظر گرفتن این چالشها، سامانه یادگیری ماشین مخصوص به خود با نام BigHead را تولید کرد. هدف این سامانه که بر اساس زبانهای پایتون و اسپارک ساخته شده است، ترکیب چندین پروژه متنباز و داخلی است، تا از پیچیدگی اتفاقی ناشی از مراحل کاری یادگیری ماشین، جلوگیری کند. چرخه تولید، محیط آموزشی و فرایندهای جمعآوری و انتقال دادهها، استانداردسازی شدهاند و هر کدام از این مراحل قابل بازتولید و تکرار هستند. برخی از مؤلفههایی که در شرکت Airbnb تولید شدهاند، شامل موارد زیر هستند:
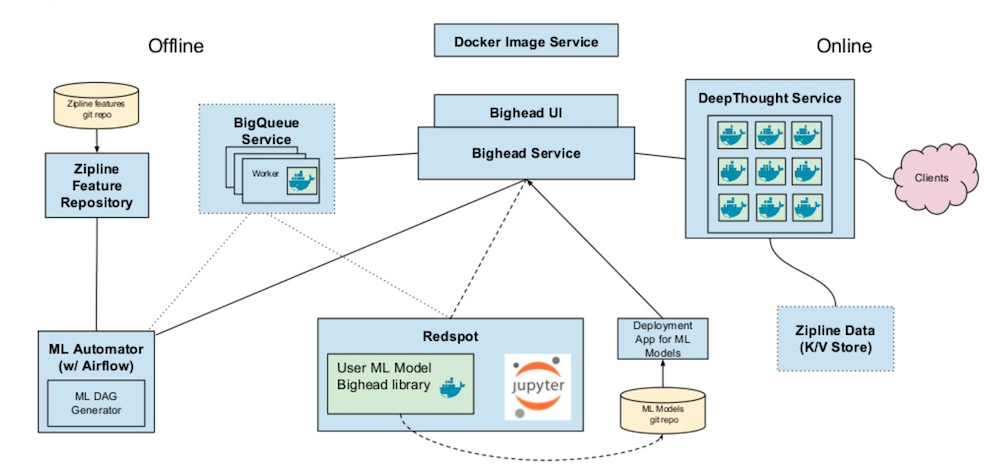
Zipline: سامانه مدیریت داده Airbnb است که برای موارد استفاده یادگیری ماشین ساخته شده است. این سامانه به تعیین ویژگیها، انجام عمل backfilling مجموعهدادههای آموزشی و اشتراکگذاری ویژگیها کمک میکند و بهطور مؤثری مشکل نامنسجم بودن دیتاستهای آفلاین را حل میکند. شرکت Airbnb با استفاده از Zipline توانسته است عمل کنترل کیفیت و نظارت را بهتر انجام دهد.
Redspot یکی از سرویسهای نوتبوک چندکاربره (multi-tenant) و کانتینرشده ژوپیتر است که در آن، محیط هر کابر از طریق داکر (docker)، کانتینر میشود. این سرویس به کاربران امکان میدهد که بدون تأثیرگذاری بر دیگر کاربران، محیط نوتبوک خود را شخصیسازی کنند.
Deep Thought: یک سرویس مشترک رابط برنامهنویسی اپلیکیشن REST برای استنتاج آنلاین است که از تمام چارچوبهای ادغامشده در سامانه یادگیری ماشین پشتیبانی میکند. این سرویس بهمنظور نظارت و تحلیل عملکرد مدل، امکان لاگ کردن، هشدار و طراحی پنل مدیریت استاندارد را فراهم میکند.
اسپاتیفای (Spotify)
اسپاتیفای که در سال 2008 راهاندازی شد، بهسرعت بهعنوان فهرست جهانی موسیقی، مطرح شد. در واقع اسپاتیفای طی سالها از یک پیشنهاددهنده ساده فاصله گرفته است و با افزودن ویژگیهایی مانند ساخت فهرستهای پخش منحصربهفرد و Discover Weekly، پیشرفت کرده است. همه این ویژگیها بهخاطر استانداردسازی بهترین عملکردها و ساختن ابزارهایی جهت پر کردن شکاف بین داده، یادگیری ماشین و برنامه بکاند از طریق سامانه یادگیری ماشین ممکن شدهاند.
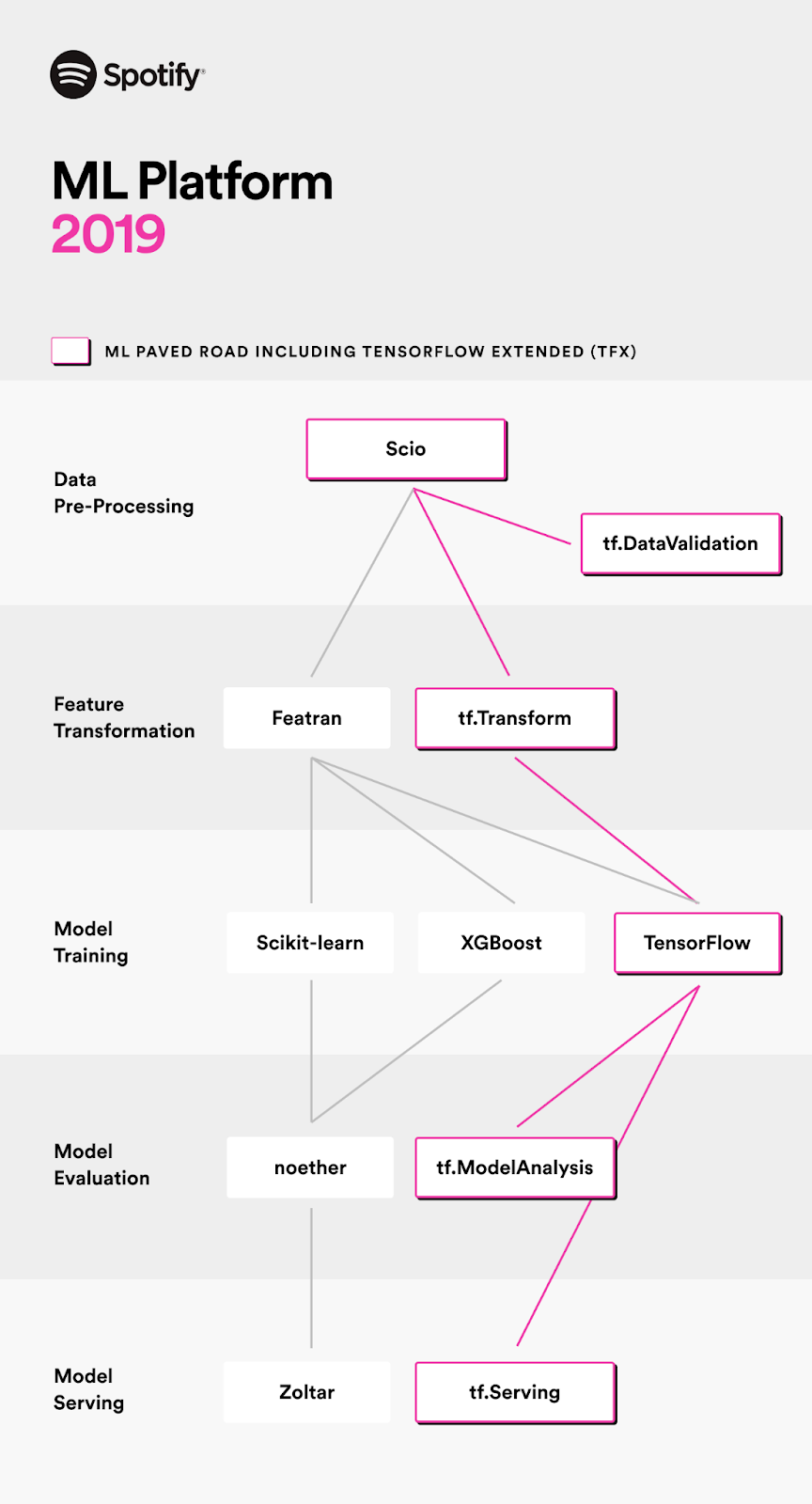
Scio: این سامانه، یک رابط برنامهنویسی اپلیکیشن Scapa برای بسته توسعه نرمافزار جاوای Apache Beam است که بهوسیله شرکت اسپاتیفای ساخته شده است. طبق آنچه که در وبلاگ شرکت گفته شده است، این سامانه از Spark و Scalding، بسیار الهام گرفته است و ویژگیهایی مانند تعادل مناسب بین بهرهوری و عملکرد، دسترسی به اکوسیستم بزرگتری از زیرساخت در جاوا، کد کاربردی و نوع ایمن را فراهم میکند.
Zoltar کتابخانهای عمومی برای ارائه مدلهای درحالتولید TensorFlow و XGBoost است. این کتابخانه به بارگیری مدلهای یادگیری ماشین پیشبینیکننده در JVM کمک میکند و چندین ایده کلیدی ارائه میکند. از Zoltar میتوان برای بارگذاری یک مدل سریالی، مشخص کردن داده ورودی و ارائه پیشبینیهای مدل، استفاده کرد.
Apollo مجموعهای از کتابخانههای جاوا است که هنگام نوشتن میکروسرویسها به کار میرود. این کتابخانه که دارای سه بخش اصلی apollo-api، apollo-core و apollo-http-service است، شامل ویژگیهایی مانند سرور HTTP و سیستم مسیریابی URI است که اجرای سرویسهای RESTful را کماهمیت میسازد.
جدیدترین اخبار هوش مصنوعی ایران و جهان را با هوشیو دنبال کنید