7 تکنیک برتر انتخاب ویژگی در یادگیری ماشینی
تیم تحریریه
- ۳۰ خرداد ۱۴۰۱
از اصول مهم علوم داده این است که با استفاده از دادههای آموزشی بیشتر میتوان مدل یادگیری ماشین بهتری به دست آورد. شاید بتوان در خصوص نمونهها چنین چیزی گفت، اما این نکته درباره تعداد ویژگیها صدق نمیکند. دیتاستهای دنیای واقعی، ویژگیهای زائد فراوانی دارند که میتوانند بر عملکرد مدل تأثیر منفی بگذارند. متخصصین علوم داده باید در انتخاب ویژگیهایی که برای مدلسازی به کار میبرند، دقت به خرج دهند. دیتاستها تعداد زیادی ویژگی دارند که تنها برخی از آنها مفید هستند. تعیین همه ترکیبهای ممکن از ویژگیها و سپس انتخاب بهترین آنها، یک راهکار چندجملهای Polynomial solution است و به همین دلیل، مستلزم یک پیچیدگی زمانی چندجملهای Polynomial time complexity است. در این نوشتار، قصد داریم 7 روش برای انتخاب بهترین ویژگیهای مدل انتخاب کنیم که به آموزش مدلی قدرتمند کمک میکنند.
دانش تخصصی از حوزه مدنظر
متخصص علوم داده یا تحلیلگر باید راجع به مسئلهای که پیش رو دارد و ویژگیهای آن مسئله، دانش لازم را داشته باشد. دانش تخصصی در حوزه مربوطه و آگاهی از ویژگیها میتواند در مهندسی ویژگی و انتخاب بهترین ویژگیها به متخصصین علوم داده کمک کند.
برای مثال، متخصص مربوطه باید بداند که در مسئله پیشبینی قیمت خودرو، سال ساخت یا رُند بودن شماره پلاک ویژگیهایی هستند که در تعیین قیمت خودرو نقش مهمی دارند.
مقادیر گمشده

دیتاستهای دنیای واقعی، بهخاطر ناقص بودن دادهها یا ثبت ناموفق آنها، اغلب شامل مقادیر گمشده Missing values میشوند. تکنیکهای متعددی برای جایگذاری Imputing مقادیر گمشده وجود دارند، اما در دیتاستهای واقعی، جایگذاری همیشه راهکار مناسبی به شمار نمیرود. به همین دلیل، اگر برای آموزش مدل از ویژگیهایی استفاده کنیم که مقادیر گمشده فراوانی دارند، مدل نهایی احتمالاً عملکرد چندان خوبی نخواهد داشت.
هدف این تکنیک، حذف ستونها یا ویژگیهایی است که تعداد مقادیر گمشده در آنها از سطح آستانه عبور میکند. با توجه به تصویر بالا که برای دیتاست titanic تولید شده است، میتوان گفت ویژگی cabin مقادیر گمشده زیادی دارد؛ بنابراین میتوان آن را از دیتاست حذف کرد.
همبستگی با برچسب کلاس هدف
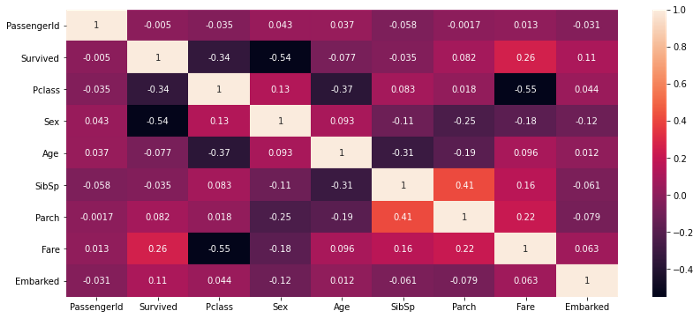
این تکنیک میزان همبستگی هریک از ویژگیها با برچسب کلاس هدف را مشخص میکند. تکنیکهای همبستگی متعددی وجود دارند که برای محاسبه همبستگی بین دو ویژگی به کار میروند؛ از جمله آنها میتوان به همبستگی پیرسون، اسپیرمن، کندال و… اشاره کرد.
تابع df.corr() ، ضریب همبستگی پیرسون بین ویژگیها را محاسبه میکند. نقشه حرارتی بالا برای دیتاست titanic رسم شده است؛ با توجه به این نمودار میتوان دریافت ویژگیهای ‘sex’، ‘Pclass’ و ‘fare’ همبستگی بالایی با برچسب کلاس هدف دارند؛ به همین دلیل، آنها را بهعنوان ویژگیهای مهم در نظر میگیریم. از سوی دیگر، ویژگیهای ‘PassengerId’ و ‘SibSp’ با برچسب کلاس هدف همبستگی ندارند، پس برای مدلسازی اهمیتی ندارند و میتوان آنها را حذف کرد.
همبستگی بین ویژگیها
همبستگی بین ویژگیها منجر به ایجاد رابطه همخطیCollinearity بین آنها میشود و بدین ترتیب روی عملکرد مدل تأثیر میگذارد. در صورتی که ضریب همبستگی بین دو ویژگی بالا باشد، آن دو ویژگی همبستگی بالایی دارند و تغییر در یک ویژگی منجر به تغییر در ویژگی دیگر میشود.
در نقشه حرارتی بالا که مربوط به دیتاست titianic است، مشاهده میکنیم که ضریب همبستگی پیرسون بین ‘Pclass’ و ‘Fare’ بالا و منفی است؛ به همین دلیل، این دو ویژگی رابطه عکس دارند و تغییرات یکی از آنها منجر به تغییر دیگری در جهت مخالف خواهد شد.
تحلیل مؤلفه اصلی (PCA)
PCA Principal Component Analysis یک تکنیک کاهش بُعد Dimensionality reduction است که برای استخراج ویژگی از دیتاست به کار میرود. PCA از طریق فاکتورگیری ماتریسی Matrix factorization ، ابعاد دیتاست را کاهش میدهد. در این روش، همزمان با کاهش ابعاد دیتاست، واریانس حفظ میشود.
زمانی که تعداد ابعاد دیتاست خیلی بالا باشد یا تحلیل و حذف ویژگیهای زائد کار زمانبری باشد، میتوان از PCA برای کاهش ویژگیها استفاده کرد. با استفاده از PCA میتوان تعداد ویژگیها را به تعداد مطلوب رساند، البته این به قیمت کاهش حدودی واریانس انجام میشود.
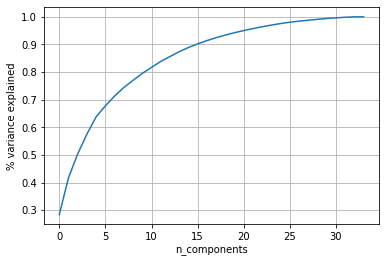
نمودار PCA بالا مربوط به دیتاست Ionosphere است که از منبعکد یادگیری ماشینی UCI گرفته شده است.
تعداد کل ابعاد: 34 (با توجه به نمودار بالا)
در کاهش ابعاد به 15 بُعد، 90% واریانس حفظ شده است.
در کاهش ابعاد به 9 بُعد، 80% واریانس حفظ شده است.
بنابراین باکاهش ابعاد به 15 بُعد میتوان با حفظ 90 درصد از واریانس، بهترین ویژگیها را انتخاب کرد.
انتخاب ویژگی رو به جلو
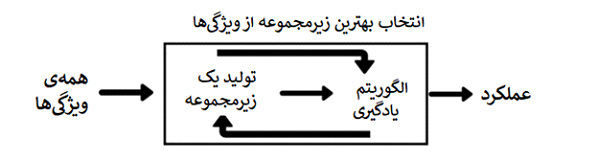
تکنیکهای انتخاب ویژگی رو به جلو و رو به عقب، به منظور یافتن زیرمجموعهای از ویژگیها که منجر به بهترین عملکرد مدل یادگیری ماشینی میشوند، به کار میروند. تکنیک انتخاب ویژگی رو به جلو بر پایه استنتاج خروجیهای قبلی انجام میشود. بنابراین برای دیتاستی با n ویژگی، گامهای تکنیک انتخاب ویژگی رو به جلو از این قرار خواهد بود:
- آموزش مدل با استفاده از هر کدام از n ویژگی و ارزیابی عملکرد مدل؛
- نهایی کردن ویژگی یا ویژگیهایی که منجر به بهترین عملکرد شدهاند؛
- تکرار گامهای 1 و 2 تا زمانی که زمان دست یافتن به تعداد مطلوب از ویژگیها.
انتخاب ویژگی رو به جلو یک تکنیک wrapper است که برای انتخاب بهترین زیرمجموعه ممکن از ویژگیها به کار میرود. تکنیک انتخاب ویژگی رو به عقب دقیقاً برعکس انتخاب ویژگی رو به جلوست؛ یعنی بعد از انتخاب همه ویژگیها (گام 1)، در هر گام بیهودهترین ویژگیها حذف میشوند.
اهمیت ویژگی
اهمیت ویژگی Feature Importance فهرستی از ویژگیهاست که برای مدل مهم هستند. این فهرست به هر ویژگی یک نمره اهمیت Importance score اختصاص میدهد که اهمیت آن ویژگی خاص را برای پیشبینی نشان میدهد. اهمیت ویژگی یکی از توابع تعبیهشده کتابخانه Scikit-learn است که در پیادهسازی بسیاری از مدلهای یادگیری ماشینی استفاده میشود.
برای تشخیص بهترین زیرمجموعه ممکن از ویژگیها میتوان از مقادیر اهمیت ویژگی استفاده کرد و بر اساس آن زیرمجموعه، مدلی قوی ساخت.
جمعبندی
انتخاب ویژگی جزئی مهم از روال پردازشی ساخت مدل به شمار میرود، زیرا ویژگیهای اضافی را که میتوانند بر عملکرد مدل تأثیر منفی بگذارند، حذف میکند. در این نوشتار 7 تکنیک معرفی کردیم که به کمک آنها میتوان بهترین زیرمجموعه از ویژگیهای دیتاست را انتخاب کرد و مدلی قدرتمند ساخت.
بهجز مواردی که در متن بیان شد، روشهای دیگری هم برای حذف ویژگیهای زائد وجود دارند که از جمله آنها میتوان به آزمون خیدو Chi-square test یا حذف ویژگیهایی اشاره کرد که واریانس کمی دارند.