
شناخت دیپ فیک و تشخیص تصاویر توسط هوش مصنوعی (بخش دوم)
 تیم تحریریه
تیم تحریریه- ۲۹ بهمن ۱۳۹۹
در این مطلب قصد داریم به نحوه شناخت دیپ فیک بپردازیم. امروزه تعداد زیادی از بستههای نرمافزاری به صورت رایگان در اختیار کاربران قرار میگیرند و کاربرد آنها بسیار آسان است و در همانحال استفاده از آنها مستلزم کسب دانش و تخصص در زمینه هوش مصنوعی نیست، مجموع این عوامل باعث شده دیپ فیک توجهات بسیاری را به سوی خود جلب کند. اگر به مبانی پایه ویرایش ویدئو تسلط دارید و یک کارت گرافیک با کیفیت قابل قبول در اختیار دارید به آسانی میتوانید یک ویدئو یا کیفیت خوب تولید کنید. هرچند فنآوریهای دیگری نیز وجود دارند که ویدئوهای جعلی تولید میکنند و شناخت دیپ فیک و یا حقیقی بودن این ویدئوها بسیار دشوار است. در بخش دوم از این سری مقالات به بحث و گفتوگو راجع به آنها خواهیم پرداخت.
دیپ فیک
برای شناخت دیپ فیک باید بدانید، دیپ فیک برای ساخت و تولید ویدئو به رویکردهای مبتنی بر یادگیری عمیق متکی است، در مقابل فنآوریهای دیگر با بهرهگیری از دانش تخصصی در زمینه دستکاری سه بعدی چهره 3-D facial manipulation، واقعیت مجازی و اعوجاج Warping ویدئو تولید میکنند. علاوه بر این، اگر بتوانید با استفاده از فریمهای ویدئوی اصلی، محتوای جدیدی تولید کنید تا حدودی میتوانید مسائل مربوط به روشنایی، رنگ پوست و غیره را تحت کنترل خود در آورید. در بسیاری موارد، برای اینکه این فریمها با صوتی (صداگذاری بر روی ویدئو) که جدا تولید شده است برای همگام بودن با لب دستکاری میشوند و یا مجدداً ایجاد میشوند . معمولاً بیشتر تغییرات در ناحیه دهان مشاهده میشود.
در مقاله پیش رو به بررسی و مطالعه مباحث فنی و سطح بالا خواهیم پرداخت. اگر به مطلبی علاقه ندارید میتوانید به آسانی از کنار آن عبور کنید و در صورت نیاز به اطلاعات و جزئیات بیشتر میتوانید به مقاله پژوهشی رجوع کنید.
RecycleGAN
برای شناخت دیپ فیک لازم است به این قسمت توجه ویژهای داشته باشید. یکی از کاربردهای رایج و متداول GAN تبدیل تصاویر یک حوزه به حوزه دیگر است. برای مثال، میتوانیم مولدهایی بسازیم که تصاویر واقعی را به سبک نقاشیهای ونگوگ درآورند. برای انجام این کار CycleGAN تصاویر واقعی و ساختگی را به صورت جداگانه به متمایزکننده Discriminator تغذیه میکند و بدین وسیله متمایزکننده را آموزش میدهد تا تفاوتهای میان تصاویر ساختگی و نقاشیهای ون گوگ را تشخیص دهد. سپس نکات و تفاوتهایی که متمایزکننده تشخیص داده برای مولد منتشر میشود تا مولد بتواند تصاویر بهتری تولید کند. هدف از انجام این کار آموزش مولد و همچنین متمایزکننده است تا این دو بتوانند به صورت مداوم به یکدیگر کمک کنند. در نهایت، مولد ارتقا پیدا میکند و میتواند تصاویر واقعی را به سبک نقاشیهای ون گوگ بازآفرینی کند.

RecycleGAN برای ساخت و تولید ویدئو در CycleGAN هم این چنین روشی به کار میبندد. RecycleGAN ابتدا اطمینان حاصل میکند که تمامی فریمهای تولیدشده «سبک» حوزه موردنظر را به ارث خواهد برد. اما فقط این کافی نیست. برای اینکه فریمها انسجام زمانی داشته باشند، RecycleGAN امکان انتقال ملایمSmooth transition میان فریمهای متوالی را فراهم میکند. انتقال ملایم موجب میشود که تکانها و لرزشهای فیلم کاهش یابند و یا به طور کامل برطرف شوند.
برای شناخت دیپ فیک باید بدانید اغلب جعل عمیق با فنآوری GAN اشتباه گرفته میشود. در واقع بخش عظیمی از پیادهسازی و اجرا به GAN مربوط نمیشود. هرچند به عقیده من همزمان با ارتقا وضوح تصویر GAN میتواند – همانند تصاویری که ممکن است SytleGAN بسازد – به تولید تصاویری با کیفیت بهتر در ویدئوها کمک کند. برخی از پیادهسازیها اقدام به افزودن مدلهای GAN کردهاند. اما برای انجام این کار هنوز زود است و علاوه بر آن آموزش GAN کار دشواری است.
[irp posts=”19903″]طراحی RecycleGAN ( اختیاری)
مبحث را با تابع زیانLoss Function دیپ فیک و اینکه چگونه میتوان به چنین انسجام زمانی دست پیدا کرد آغاز میکنیم. تابع زیان انکودر و دیکودر جعل عمیق زیان بازسازی Reconstruction loss را به حداقل میرساند.
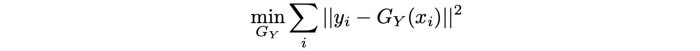
در GAN، تابع هدف Objective function نوعی بازی مینیماکس Min-max game است که به صورت متناوب باعث ارتقا و پیشرفت مولد و متمایزکننده میشود.
![]()
در این حالت هدف RecycleGAN این است که تابع زیانی اضافه کند که فریمهای متعلق به دامنه Y ( انسجام مکانیSpatial consistency) را تولید کند و در همان حال انسجام زمانی را هم حفظ کند.
فرض کنید P یک پیشبینیکننده موقتی است ( که با نام مولد هم شناخته میشود) و با در نظر گرفتن تمامی فریمهای قبلی، فریمهای ویدئو را پیشبینی میکند. برای آموزش این پیشبینیکننده، RecycleGAN زیان بازگشتی Recurrent loss را به حداقل میرساند؛ زیان بازگشتی فریمهای پیشبینیشده را با فریمهای اصلی مقایسه میکند.

فرض کنید GY (xi) مولدی است که فریم xi را به فریم yi تبدیل میکند. در این حالت میتوانیم یک تابع زیان دیگر موسوم به زیان بازیابیRecycle loss ارائه دهیم که تعریف آن از این قرار است:

زیان بازیابی در تولید تصاویر از مولد و پیشبینیکننده استفاده میکند و بدین وسیله زیان بازآفرینی را محاسبه میکند. تابع زیان، انسجام زمانی و همچنین انسجام مکانی را تقویت میکند.
آخرین تابع زیان RecycleGAN شامل تابع هدف در GAN، زیان بازیابی و زیان بازگشتی میشود.

Face2Face
در ادامه به بخش دیگری از مقاله مربوط به شناخت دیپ فیک پرداخته شده است. Face2Face حالات چهره بازیگر مبدأ ( بازیگری که در قسمت بالا، سمت چپ قرار دارد) را به بازیگر مقصد (دونالد ترامپ) منتقل میکند. برای مثال، اگر بازیگر مبدأ دهان خود را باز کند، Face2Face همان حالات را بر روی ویدئوی مقصد به اجرا در میآورد. برای تماشای این ویدئو کلیک کنید.
طراحی Face2Face (اختیاری)
Face2Face با سکانسهای ویدئویی آموزش میبیند و از یک مدل تحلیل مؤلفههای اصلی تقلید میکند تا در یک فریم ویدئویی که فضایی پنهان با ابعاد کم دارد ، چهرهای را نشان دهد. در پایین این مدل، چهره با استفاده از پارامترهای مدل چهره از جمله شکل صورت، بازتابندگی پوست و حالات چهره پارامتری میشود. دو عامل اول فرد را تشخیص میدهند، در حالیکه حالات چهره در فریمهای مختلف تغییر میکنند.

در زمان اجرا، Face2Face با استفاده از پارامترهای حالات چهره از حالات چهره فریمهای ویدئوی مبدأ و همچنین ویدئوی مقصد تقلید میکند. در مرحله بعد Face2Face انتقال تغییر شکل Deformation transfer را در پارامترهای حالت میان مبدأ و مقصد اجرا میکند. در نتیجه حالتهای چهره مقصد تغییر میکنند تا حالتهای بازیگر مبدأ را بازآفرینی کنند.
سپس Face2Face چهره ساختگی مقصد را با استفاده از ضرایب حالات منتقلشده و همچنین پارامترهای ویدئوی مقصد ایجاد میکند؛ در اینجا منظور از پارامترهای ویدئو مقصد سایر پارامترهای مدل چهره، نور تخمینی محیط و اطلاعات ژست است. علاوه بر این از پارامترهای دوربین نیز استفاده میشود.
Face2Face برای آنکه قسمت دهان در ویدئوی مقصد حالتی طبیعی داشته باشد، سکانسهای ویدئوی مقصد را برای یافتن دهانی که فضای داخلی آن بیشترین شباهت را به حالت مورد نظر داشته باشد، جستوجو میکند. با این وجود به منظور برقراری انسجام زمانی میان فریم قبلی دهان و فریمی که بیشترین شباهت را با آن داشته هماهنگیهایی ایجاد میشود. به لحاظ فنی Face2Face فریم سکانسهای آموزشی را که مجموع وزنهای لبه را به آخرین فریم بازیابی شده و فریم کنونی گراف ظاهر به حداقل میرساند پیدا میکند. بسیاری از جزئیات آن در گراف نشان داده نشده است. در پایان Face2Face از طریق ادغام آلفا، فریمهای ویدئوی اصلی، فریم دهان و مدل چهره ارائهشده را با هم ترکیب میکند و فریم ورودی جدیدی به وجود میآورد.
[irp posts=”7852″]یادگیری هماهنگسازی لب از صوت
در ادامه توضیح درباره شناخت دیپ فیک، فرض کنید یک ویدئو و یک فایل صوتی جداگانه در اختیار داریم، آیا میتوانیم قسمت دهان (حرکت لبها) را بازآفرینی کنیم تا حرکت لب و دهان با صوتی که در اختیار داریم هماهنگ شود؟ اگر انجام این کار ممکن شود، آسیبها و خطرات بسیاری به همراه خواهد داشت. برای مثال، برخی افراد میتوانند متن یک فایل صوتی جعلی و ساختگی را بر روی یک ویدئو واقعی بگذارند.
در این بخش از مال شناخت دیپ فیک به بحث و گفتوگو راجع به فنآوری هماهنگسازی لب خواهیم پرداخت که در دانشگاه واشنگتن انجام شده است. دیاگرام مقابل فرایند هماهنگ کردن حرکت لب و دهان با فایل صوتی را نشان میدهد. در دیاگرام مقابل فایل صوتی یکی از سخنرانیهای هفتگی ریاست جمهوری با فایل صوتی دیگری (ورودی صوتی) جا به جا شده است. در طول این فرایند قسمت دهان، گونه و چانه بازآفرینی شدهاند تا حرکت آنها با فایل صوتی جعلی هماهنگ شود.

هماهنگسازی لب از طراحی فایل صوتی (اختیاری)
دیاگرام ابتدا با در نظر گرفتن فایل صوتی سخنرانی اوباما، از شبکههای حافظه کوتاه مدت طولانی LSTM network استفاده میکند تا 18 نقطه راهنمای دهان را مدلسازی کند.

سپس با استفاده از نقاط راهنما بافت دهان و قسمت پایینی صورت (که بعداً بیشتر به آن خواهیم پرداخت) را ایجاد میکند. سپس بخشی را که در آن بافت جدید دهان باید با ویدئوی مقصد ترکیب شود را مجدداً زمانبندی میکند. برای مثال، اوباما معمولاً زمانی که مکث میکند، سر خود را هم دیگر تکان نمیدهد. اینگونه همردیفسازیها موجب میشود که حرکات سر طبیعیتر به نظر برسند و با حرکات لب همگام باشند. در آخر نیز همهچیز را با هم ترکیب میشود.
در ادامه این فرایند را با ارائه جزئیات بیشتری شرح میدهیم. فایل صوتی با ضریب کپسترال فرکانس مل MFCC coefficients نشان داده میشود که به طور گسترده در تشخیص گفتار مورد استفاده قرار میگیرند.
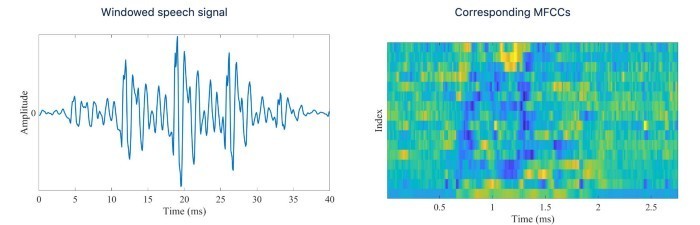
شکل دهان با استفاده از 18 نقطه راهنمای دهان که در ادامه میتوانید تصویر آن را مشاهده کنید، نشان داده میشود. دیاگرام با در اختیار داشتن ساعتهای زیادی از ویدئوهای سخنرانیهای هفتگی اوباما ، یک LSTM آموزش میدهد تا یک ضریب MFCC را به عنوان ورودی دریافت کند و سکانسی از نقاط راهنمای دهان به عنوان خروجی ارائه دهد.

در مرحله بعد، بر مبنای نقاط راهنما قسمت پایینی صورت ایجاد میشود.

برای هر یک از فریمهای ویدئوی مقصد، مدل سه بعدی صورت را بازسازی میکند و شکل دهان را استنباط میکند.

سپس فریمها n که کوچکترین فاصله L2 را میان فریمهای شکل دهان و فریمهای شکل دهان مقصد دارند، انتخاب میشوند. مقدار n با دقت انتخاب میشود چرا که همزمان با افزایش n، انسجام زمانی نیز افزایش پیدا میکند اما کیفیت تصویر کاهش پیدا میکند. در مرحله بعد میانه وزنی Weighted median بافت دهان به ازای هر پیکسل از فریمهای n محاسبه میشود؛ در فریمهای n وزنها نشان میدهند که تا چه میزان شکل دهان در فریمهای منتخب و ویدئوی مقصد با یکدیگر شباهت دارند.
همانگونه پیشتر در مقالههای مربوط به شناخت دیپ فیک عنوان شده:
«ایجاد ناحیه دهان به صورتی که طبیعی و واقعی به نظر برسد، فرایندی چالش برانگیز است. دندانها باید محکم، واضح و مرتب باشند، رنگ آنها یکسان باشد و خوب با لب جفت شوند.»
برای ارتقای کیفیت ناحیه دهان، دیاگرام فرکانسهای پایین بافت میانه وزنی را با جزئیات فرکانس بالای دندان در ویدئوی مقصد ادغام میکند. سپس وضوح ناحیه دندان را افزایش میدهد تا دندانها طبیعی و واقعی به نظر برسند.

علاوه بر این در هنگام صحبت کردن، حرکات سر نیز تغییر میکنند. برای مثال، زمانی که اوباما مکث میکند، سر و ابروهای او از حرکت باز میایستند. حرکت سر در ویدئوی مقصد با بافت جدید دهان – که با گفتار جدید (فایل صوتی جدید) هماهنگ است – هماهنگ نخواهد بود. به منظور حل این مشکل بافت جدید دهان بار دیگر با ویدئوی مقصد و مطابق با حرکات سر هماهنگ میشود. برای مثال، زمانی که گوینده فایل صوتی جدید مکث میکند، حرکات سر هم متوقف میشوند.

در مرحله بعد، برای ارتقای کیفیت ترکیب زاویه فک – بافت پایینتر صورت با سر مقصد – از اعوجاج استفاده میکند. همانگونه که در تصویر پائین مشاهده میکنید، در تصویر دوم اوباما، کیفیت خط فک ارتقا پیدا کرده و دو زاویه ندارد.

با توجه به ویدئوی مقصد و بافت دهان ایجادشده، دیاگرام لایههای (a) تا (d) را ایجاد میکند و برای ترکیب آنها با یکدیگر از روش هرم لاپلاسیان Laplacian pyramid استفاده میکند.

این روش باعث کاهش برخی نکات و موارد غیرطبیعی از جمله دو چانه و پخششدن رنگ در ناحیه چانه میشود.

ردیف بالا ویدئوی فایل صوتی ورودی است و ردیف پایین ویدئوی ساخته شده است.

ویرایش متنی ویدئوهای Talking-head
در ادامه مقاله شناخت دیپ فیکم به این موضوع توجه کنید. جمله « شاخص داو جونز صد و پنجاه واحد سقوط کرد» با جمله «شاخص داو جونز دو هزار و بیست واحد سقوط کرد» تفاوتهای زیادی دارد، جمله آخر ممکن است منجر به فروش هیجانی شود. در مقاله ویرایش متنی ویدئوهای Talking-head، متن اصلی در ویرایشگر متن ویرایش میشود و تصاویر ویدئو تغییر میکنند تا با محتوای متنی ویرایش شده هماهنگ شوkد. برای تماشای این ویدئو کلیک کنید.
طراحی ویرایش متنی ویدئوهای Talking-head ( اختیاری)
ویدئوی اصلی و متن ویرایششده به عنوان ورودی به سیستم داده میشوند.

مرحله اول – واجآرایی
برای شناخت دیپ فیک باید بدانید در مرحله واج آرایی ابتدا ویدئو به بخشهای مختلفی تقسیم میشود و هر کدام از این بخشها دارای برچسب واج و زمان شروع و زمان پایان خواهند بود. برای مثال واج کلمه “people” – “/ˈpēpəl/” است. واج کلمات به ما نشان میدهد که چگونه باید یک کلمه رو تلفظ کنیم.

فرض بر این است که فایل صوتی با یک رونوشت متنی صحیح و مناسب برچسبگذاری میشود. در ادامه باید مدت زمان هر واج را با استفاده از نرمافزار واجآرایی خودکار مشخص کنیم. مجموع این بخشها کتابخانهای از کلیپهای بصری تشکیل میدهند که به صورت غیرمستقیم چهرهای را که در ویدئو در حال صحبت کردن است بازسازی میکنند.
مرحله دوم – ردیابی و بازسازی سه بعدی چهره
سیستم از تک تک فریمهای ویدئو یک مدل پارامتریک و سه بعدی از چهره (شکل هندسی، ژست، بازتابندگی، حالت و نور و روشنایی) استخراج میکند. سپس کلیپهایی که نسبت به دیگر کلیپها هماهنگی بیشتری با واجها دارند را پیدا میکند و آنها را با مدلهای صورت که پیش از این استخراج کرده بود، ترکیب میکند.
مرحله سوم – جستوجوی وایزم
هدف از جستوجوی وایزمViseme Search یافتن آن دسته از سکانسهای واجی ویدئو است که میتوان آنها را با هم ترکیب کرد و ویدئویی را بازسازی کرد که با فایل صوتی متن ویرایششده تطابق داشته باشد. در اینجا فرض بر این است که واجهای مشابه ویدئو تصاویر مشابهی تولید میکنند. بنابراین اگر متن ویرایششدهای از توالی کلمات W در اختیار داشته باشیم، باید آن دسته از سکانسهای فرعی ویدئو که هماهنگی و تشابه بیشتری با واج مورد نظر ما دارند پیدا کنیم و به دنبال روشی باشیم تا به بهترین نحو آنها را با هم ترکیب کنیم تا با متن ویرایششده هماهنگ باشند. در مثالی که در مقابل آوردهایم، W به W1 و W2 تقسیم شده است ( در اینجا چگونگی یافتن بهترین بخش را توضیح نخواهیم داد) برای هر بخش (W1 یا W2) سیستم مشخص میکند که در چه قسمتهایی ممکن است ویدئوی اصلی همان توالی سکانسها را داشته باشد.
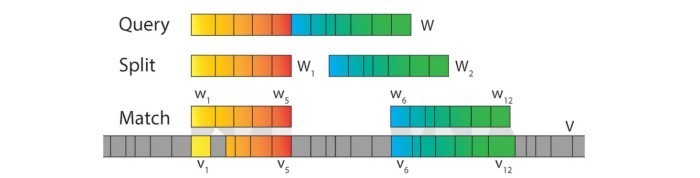
علاوه بر این، یک ترکیبکننده گفتاری Speech synthesizer مدت زمان واجها (پرسمانQuery ) را تعیین و مشخص میکند.
[irp posts=”5166″]مرحله چهارم – ترکیب و زمانبندی مجدد پارامترها
با این وجود این روش دو ایراد دارد. هنگام پیدا کردن سکانسهای مطابق، مدت زمان واجها در نظر گرفته نمیشود و بعید است که مشابه هم باشند. علاوه بر این، انتقال سکانسهای مطابق (میان W1 و W2) ملایم نخواهد بود.
زمانبندی مجدد پسزمینه: سیستم ناحیه پیرامون کلمه ویرایششده – که به اندازه کافی بزرگ باشد- را انتخاب میکند و بخش ویدئوی اصلی را استخراج میکند. سپس این بخش مجدداً زمانبندی میشود تا با بخشهای فرعی فایل صوتی جدید مطابقت داشته باشد. به منظور دستیابی به این هدف، اندازه فریمهای جدید با استفاده از نزدیکترین همسایه از فریمهای اصلی تغییر میکند تا ویدئویی تولید شود که طول آن با طول فایل صوتی جدید مطابقت داشته باشد؛ طول فایل صوتی جدید با استفاده از ترکیبکننده گفتاری محاسبه میشود. این فرایند زمانبندی مجدد سکانس پسزمینه Retimed background sequence نامیده میشود. در مقابل، نمونهای از این سکانس را آوردهایم. از آنجاییکه فریمها از قسمتهای مختلف ویدئو استخراج میشوند، ممکن است سایز سر و ژست در آنها متفاوت باشد. همین امر باعث تکان خوردن فریمها میشود.

در مرحله بعد، زمانبندی مجدد سکانسهای فرعی Subsequence retiming انجام میشود. در فرایند زمانبندی مجدد سکانسهای فرعی مدت زمان بخشهای مطابق نیز با طول بخشهای صوتی برابر خواهد بود (زمانبندی مجدد/ نگاشت Mapping در اولین ردیف مقابل نشان داده شده است).

به عبارت دیگر در مرحله اول، بخشها در ویدئوی اصلی تبدیل میشوند تا طول آنها با W برابر شود. در مرحله دوم، بخشهای مطابق تغییر پیدا میکنند تا طول آنها نیز با W برابر شود.
ترکیب پارامتر: مدل پارامتریک و سه بعدی چهره شامل شکل صورت، بازتابندگی، نور و روشنایی، ژست و حالت میشود. در این حالت لازم است مدل جدیدی بسازیم که سکانسهای پسزمینه و بخشهای منطبق که مجدداً زمانبندی شدهاند را با یکدیگر ترکیب کند. ابتدا توضیح میدهیم کدام یک از پارامترهای مدل چهره سکانس پسزمینه باید ثابت بماند و حفظ شود.
- شکل صورت و بازتابندگی از فردی به فرد دیگر فرق میکند و به همین دلیل باید آنها را حفظ کرد و تغییری در آنها ایجاد نکرد.
- نور صحنه قبل و بعد از صحنه بخش ویرایششده به صورت خطی درونیابی Linear interpolation میشود. این کار باعث کاهش تکانها و لرزشها در نور و روشنایی میشود.
- حالت سر از سکانس پسزمینه که مجدداً زمانبندی شده است، مدلبرداری میشود.
- آخرین عاملی که باید حفظ شود حالت است که شامل 64 پارامتر میشود؛ این پارامترها شامل اطلاعاتی راجع به حرکات دهان و صورت هستند. این پارامترها از بخشهای منطبقی که مجدداً زمانبندی شدهاند استخراج میشوند. با این وجود برای جلوگیری از تکان خوردن و لرزش فریمها و همچنین برای ایجاد انتقال ملایم میان فریمها، در ناحیه 67 هزارم ثانیه اطراف انتقال فریم، درونیابی خطی انجام میشود.
در این مرحله، سیستم یک سکانس پارامتری تولید میکند که حرکات صورت جدیدی که به آنها نیاز است و همچنین سکانسهای پسزمینه که مجدداً زمانبندی شدهاند را توصیف میکند.
مرحله پنجم – ایجاد عصبی چهره
در مرحله بعد، سیستم قسمت پایینی صورت را در ویدئوی پسزمینه که مجدداً زمانبندی شده است ، میپوشاند و با استفاده از مدل ترکیبی چهره قسمت پایینی جدیدی برای چهره ایجاد میکند. در نتیجه ri به وسطهای برای نمایش ویدئو تبدیل میشود. سپس این نمایش به یک شبکه RNN منتقل میشود تا سکانس نهایی ویدئو را بازسازی کند. فریمهایی که در آنها قسمت پایینی صورت با خطوط مشکلی نشان داده شدهاند ri هستند. فریمهای سمت راست فریمهایی هستند که توسط RNN تولید شدهاند.

مدل RNN برای هر ویدئویی که به عنوان ورودی دریافت میکند به ازای هر شخص جداگانه آموزش داده میشود. مدل RNN به جای اینکه با سکانسهای مطابق آموزش داده شود، با ri آموزش داده میشود که از سکانس اصلی ایجاد شدهاند. هدف از آموزش RNN مشابه GAN است که در آن تلاش میشود سکانسی بازآفرینی شود که تشخیص آن از سکانس اصلی امکانپذیر نباشد.
یادگیری تخاصمی چند مرحلهای مدلهای عصبی واقعگرایانه Talking Head
در ادامه مقاله مربوط به شناخت دیپ فیک، فرض کنید یک ویدئوی مقصد در اختیار دارید ، آیا میتوان سبک آن را دوباره و مطابق با تصاویر مبدأ ( ردیف بالا) بازآفرینی کرد؟ برای مثال، در ویدئوی نهایی حرکات سر تغییری نخواهند کرد اما چهره و شیوه لباس پوشیدن از همان فرد و یا فردی متفاوت الگوبرداری خواهد شد. علاوه بر این، مولد باید تا جایی که امکان دارد با تعداد کمی تصویر آموزش داده شود و یاد بگیرد، در این حالت میتوان از 8 تصویر اصلی یا کمتر از این تعداد استفاده کرد. در اینجا هدف یادگیری با داده های محدود Few-shot learning یا انتقال یادگیری Transfer learning است.

در مثال پیشرو، مولد برای تولید یک تصویر، سبک فرد دیگری را به فرد مقصد منتقل میکند. ابتدا با استفاده از نرمافزار رده عام Off-the-shelf software نمای چهره از تصویر مقصد استخراج میشود. سپس نقاط راهنما با سبک دامنه مبدأ بازسازی و بازآفرینی میشوند. در این مثال، فقط یک تصویر مبدأ در اختیار مولد قرار گرفته است (یادگیری تک مرحلهای).

طراحی یادگیری تخاصمی چند مرحلهای مدلهای عصبی واقعگرایانه Talking Head (اختیاری)
امیدوارم مقاله شناخت دیپ فیک تا اینجا شما را خسته نکرده باشد. آموزش سیستم در دو مرحله انجام میشود. در مرحله فرایادگیریMeta-learning سیستم با سکانسهای ویدئویی افراد مختلف آموزش میبیند. در مرحله تنظیم دقیق Fine-tunning stage سیستم با تعداد کمی از تصاویر آموزش داده میشود (یادگیری چند مرحلهای) تا برای فرد خاصی – که در مرحله فرایادگیری نشان داده نشده است – سکانسهای ویدئویی ایجاد کند.

تعبیهکننده Embedder، تصویری به همراه نقاط راهنمای چهره ،که نرمافزار رده عام آنها را تشخیص داده، به عنوان ورودی دریافت میکند و بردار N بُعدی e را ایجاد میکند. در مرحله فرایادگیری، فریمهای K به صورت تصادفی از یک ویدئو استخراج میشوند و به صورت جداگانه به تعبیهکننده تغذیه میشوند. سپس میانگین آنها را محاسبه میکند.

بردار ، اطلاعات مختص به فیلم ،از جمله هویت فردیای که قرار است در تمامی فریمها و ژستها یکسان باشد را کدگذاری میکند.
سپس فریم ویدئویی دیگری را از همان ویدئو به عنوان نمونه انتخاب میکند و نمای چهره را استخراج میکند. نمای استخراجشده به همراه میانگین e – که در بالا محاسبه شد – به مولد تغذیه میشود تا یک تصویر ایجاد کند. در اینجا هدف این است که مولد تصویری ایجاد کند که به لحاظ ادراکی با حقیقت مبنا مطابقت داشته باشد.

برای آنکه مولد بتواند به درستی با استفاده از نقاط راهنمای چهره یک تصویر ایجاد کند، e را در ماتریس P ( Pe) – ماتریس تصویر و قابل آموزش- ضرب میکند تا اطلاعات سبک را یاد بگیرد. برای مثال، رنگ پوست و ویژگیهای چهره از جمله سبکهایی هستند که یاد گرفته میشوند. به لحاظ فنی، Pe در عملیات AdaIn به عنوان یک پارامتر AdaIN عمل میکند که تعریف آن از قرار زیر است:

در سطح بالا، سیستم بخشهای مختلف اطلاعات سبک را در لایههای مکانی مختلف اجرا میکند تا به تولید پیکسل کمک کند. این فرایند جزئیات زیادی دارد.
در همان زمان، سیستم متمایزکننده را که یک تصویر و نقاط راهنمای چهره را به عنوان ورودی دریافت کند، آموزش میدهد. علاوه بر این، برای هر ویدئو بردار Wi را آموزش میدهد؛ بردار Wi را میتوان نمایش تعبیهشده این ویدئو قلمداد کرد (مشابه واژه تعبیهکردن در حوزه پردازش زبان طبیعی). متمایزکننده بردار V، خروجی CNN، را در مقدار تعبیهشده ضرب میکند تا امتیاز نهایی r را محاسبه کند.
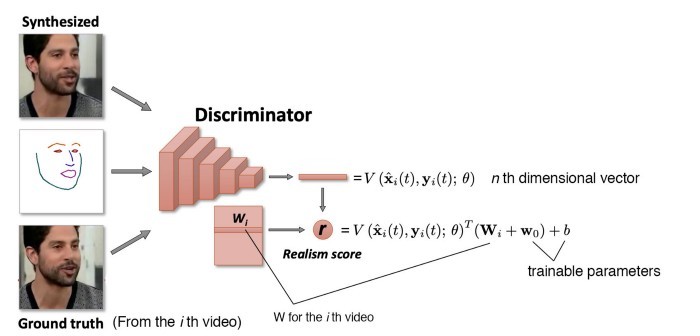
تابع زیان که از آن برای آموزش مدل استفاده شد، تفاوتهای بصری میان تصویری که مجدداً ایجاد شده و حقیقت مبنا و زیان GAN را شامل میشود. علاوه بر این، e و Wi هدف واحدی را دنبال میکنند – و به عنوان عاملی پنهان برای iامین ویدئو عمل میکنند. به همین دلیل یک زیان جفت Match loss تعریف میشود که آنها را تشویق کند مقادیر مشابهی داشته باشند.

اکنون مدل آموزش دیده تا تصاویری ایجاد کند که از ویدئوهای آموزشی تقلید میکنند. اما برای تقلید از یک فرد خاص، با استفاده از تصاویر آن فرد – مرحله تنظیم دقیق را بار دیگر پشت سر میگذارد. اما در اینجا مدل از طریق آموزش چند مرحلهای آموزش میبیند، به عبارت دیگر تعداد کمی ورودی، برای مثال 1 تا 8 تصویر، به سیستم تغذیه میشود.
ابتدا، طراحی مولد به آرامی تغییر میکند. در این حالت ورودی عملیات AdaIN که ψ’ نامیده میشوند را میتوان آموزش داد. در ابتدا ψ’ به عنوان Pe با نمونه تصاویر جدید اجرا خواهد شد.

علاوه بر این، متمایزکننده Wi را جایگزین مجموع wo و e خواهد کرد.

تولید فایل صوتی
برای شناخت دیپ فیک باید بدانید در بسیاری از ویدئوهای جعل عمیق از فایل صوتی جعلکننده هویت (ویدئوی مقصد) در ویدئوی نهایی استفاده میکنند. با این وجود، همانگونه که در Stable Voices کانال یوتیوب نشان داده شده با استفاده از مدلی که با فایلهای صوتی فرد مورد نظر آموزش دیده میتوان یک فایل صوتی جدید ایجاد کرد. در صورت عدم دسترسی به جعلکننده هویت و عدم امکان استفاده از فایل صوتی او میتوان از یک ترکیبکننده صوتVoice synthesizer استفاده کرد که به یادگیری ماشین و برخی مدلهای یادگیری عمیق مجهز باشد. برای راحتی و سهولت، چگونگی تولید فایل صوتی با استفاده از فنآوریهای یادشده را در اینجا توضیح نمیدهیم اما فرایند تولید فایل صوتی تا حدودی همانند تولید فایل بصری (تصویر و ویدئو) است با این تفاوت که در اینجا ورودی سیستم فایل صوتی است.
[irp posts=”8082″]ویدئو پرتره عمیق
در این مقاله شناخت دیپ فیک تلاش کردیم بسیاری از فنآوریهایی که در تولید ویدئو مورد استفاده قرار میگیرند را معرفی کنیم. فنآوریهای دیگری نیز وجود دارند که میتوان از آنها در تولید ویدئو استفاده کرد اما نمیتوانیم همه آنها را در اینجا معرفی کنیم. در ادامه، به معرفی برخی از آنها خواهیم پرداخت اما برای اختصار، جزئیات فنی و تخصصی آن را شرح نخواهیم داد.
در ویدئو پرترههای عمیق، سیستم حالات و حرکات سر، حالات چهره، حرکات چشم بازیگر مبدأ را به بازیگر مقصد منتقل میکند.
طراحی ویدئو پرتره عمیق (اختیاری)

ویرایش محاسباتی ویدئوهایی با صحنههای گفتوگو محور
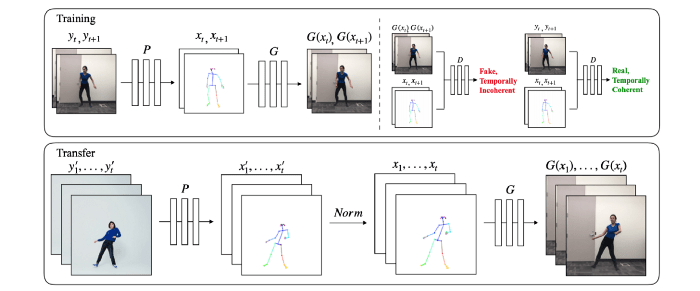
در رابطه با شناخت دیپ فیک تا به اینجا فقط صدا و یا چهره بازیگر مبدأ را در فیلم مقصد جایگزین و بازآفرینی کردهایم. اما میتوانیم ژست بازیگر مبدأ را برای بازیگر مقصد بازسازی کنیم. برای مثال ، میتوانیم ویدئویی تولید کنیم که در آن رقصندهای غیرحرفهای شبیه به رقصندهای ماهر برقصد.
در تصویر مقابل، مدلی نمایش داده شده که از GAN استفاده میکند.
برای تماشای بخش اول مطلب شناخت دیپ فیک به لینک زیر مراجعه کنید:





