
با 7 روش فیلتر کردن دیتافریم های Pandas آشنا شویم
 تیم تحریریه
تیم تحریریه- ۲۵ اسفند ۱۴۰۰
Pandas یک کتابخانه پایتون همه منظوره و قدرتمند است و عمدتاٌ در تحلیل داده کاربرد دارد و فرایند تحلیل و کشف دادهها را تسریع میبخشد. یکی از مزایای Pandas در این است که برای انجام یک مسئله چندین روش مختلف ارائه میدهد. در طول فرایند تحلیل داده همیشه مجبور میشویم بسته به موقعیت یا با انتخاب زیرمجموعهای از دیتافریم عملیات فیلتر کردن را انجام دهیم. در این نوشتار، به معرفی 7 روش فیلتر کردن دیتافریم های Pandas میپردازیم.
من برای انجام این پروژه از دیتاست مسکن کالیفرنیا California housing dataset استفاده میکنم که در پوشه نمونهداده در google colab قرار داده شده است.
import numpy as np
import pandas as pd
df =
pd.read_csv("/content/sample_data/california_housing_train.csv"
,
usecols =['total_rooms','total_bedrooms','population', 'median_income','median_house_value'])
df.head()

متداولترین روش برای فیلتر کردن یک دیتافریم
متداولترین روش برای فیلتر کردن یک دیتافریم این است که حالت مورد نظر، برای مثال انتخاب ستون، را در کروشه قید کنیم.
#1 df[df['population'] > 10][:5]

با اِعمال این روش فقط ستونهایی که جمعیت در آنها بیش از 1000 است به ما نشان داده میشود.
با اجرای تابع nlargest میتوانیم سطرهایی را که مقدارشان در یک ستون خاص بیشتر است فیلتر کنیم.
#2 df.nlargest(5, 'population')

در نتیجه اجرای این متد سطرهایی که در ستون جمعیت 5 مقدار بزرگتر را به خود اختصاص دادهاند، حذف میشوند.
به همین ترتیب میتوانیم سطرهایی با کوچکترین مقادیر را انتخاب کنیم.
#3 df.nsmallest(5, 'population')

روش دیگر برای انتخاب بزرگترین یا کوچکترین مقدار یک ستون این است که سطرها را مرتب (sort) کنیم و بخشی از آن را انتخاب کنیم.
#4 df.sort_values(by='median_income', ascending=False)[:5]

در نتیجه استفاده از این متد، دیتافریم به صورت نزولی و با توجه به ستون median_income مرتب شد و 5 سطر اول انتخاب شدند.
تابع query یکی دیگر از متدهای فیلتر کردن است که انعطافپذیری بالایی دارد. query این امکان را برای شما فراهم میکند تا یک حالت را در قالب یک رشته (string) تعیین کنید.
#5
df.query('5000 < total_rooms < 5500')[:5]

گاهی اوقات ممکن است بخواهیم به صورت تصادفی یک نمونه از دیتافریم های Pandas انتخاب کنیم. این عمل بیشتر به انتخاب کردن شباهت دارد تا فیلتر کردن اما ارزش آن را دارد که معرفیاش کنیم. تابع sample یک نمونه تصادفی با اندازه مشخص را باز میگرداند.
#6 df.sample(n=5)

این نمونه شامل 5 سطر است. علاوه بر این میتوانیم یک شی کسری (fraction) هم مشخص کنیم. برای مثال، کد زیر نمونهای با اندازه 1% از دیتافریم اصلی به ما باز میگرداند.
df.sample(frac=0.01)
علاوه بر مواردی که گفته شد میتوانیم طیف مشخصی از اندیسها را انتخاب کنیم. این متد نیز همانند تابع sample بیشتر شبیه انتخاب کردن است تا فیلتر کردن بر مبنای یک حالت. اما در مواردی که با دادههای ترتیبی (برای مثال دادههای سری زمانی) سر و کار داریم میتوان آن را روشی برای فیلتر کردن در نظر بگیریم.
این متد iloc نامیده میشود و سطرها و ستونهایی را که در طیف مشخصی از شاخص قرار دارند به ما باز میگرداند.
#7 df.iloc[50:55, :]

سطرهایی با اندیسهایی در بازه (50:55) بازگردانده شدهاند. در ضمن میتوانیم فقط برخی از ستونها را انتخاب کنیم.
df.iloc[50:55, :3]

اگر توجه کردید باشید میبینید که اندیس سطرهایی که بازگردانده شدهاند، تغییر نکرده است. اندیس این سطرها مشابه دیتافریم اصلی است. اگر میخواهید پس از فیلتر کردن یک دیتافریم جدید ایجاد کنید، ممکن است لازم باشد اندیسها را reset کنید. برای انجام این کار میتوانید از تابع reset_index کمک بگیرید.
#without reset_index
df_new = df.query('total_rooms > 5500')
df_new.head()
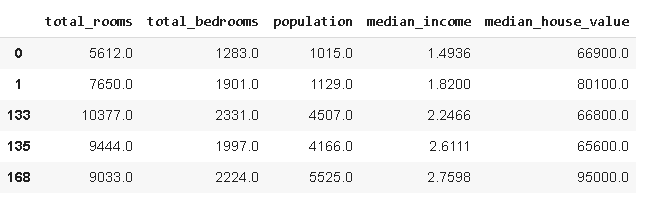
#with reset_index
df_new = df.query('total_rooms > 5500').reset_index()
df_new.head()

در این نوشتار متدهای مختلف فیلتر کردن یک دیتافریم و یا انتخاب بخشی از آن را با یکدیگر بررسی کردیم. هرچند با بسیاری از آنها میتوانید یک عملیات مشخص را انجام دهید، اما ممکن است به خاطر نحو (Syntax) یا به دلایل دیگر یکی را بر دیگری ترجیح دهید.
اینکه بتوانیم یک عملیات را به چندین روش مختلف انجام دهیم برای همه مطلوب و خوشایند است و کتابخانه Pandas هم چنین قابلیتی دارد.





