
Scikit-learn و 6 ترفند مفید برای متخصصان علم داده برای استفاده از این کتابخانه
 تیم تحریریه
تیم تحریریه- ۱۲ خرداد ۱۴۰۰
Scikit-learn (یا Sklearn) یک کتابخانه یادگیری ماشین متنباز و قدرتمند مبتنی بر زبان برنامهنویسی پایتون است. این کتابخانه شامل ابزارهای کارآمدی برای یادگیری ماشینی و مدلسازی آماری است و برای نمونه میتوان به الگوریتمهای گوناگون طبقهبندی، رگرسیون (پیشبینی) و خوشه بندی اشاره کرد.
در این نوشتار 6 ترفند برای کار با کتابخانه Scikit-learn را معرفی میکنیم که برخی از امور مرتبط با برنامهنویسی را تسهیل خواهد کرد.
1. دادههای ساختگی و تصادفی تولید کنید
برای تولید دادههای ساختگی طبقهبندی از تابع make_classification() و برای دادههای رگرسیونی از make_regression() استفاده میکنیم. این کار هنگام مشکلیابی یا برای زمانی که میخواهید روی دادههای دیتاستی کوچک و تصادفی آزمایش انجام دهید، مفید خواهد بود.
با استفاده از تابع زیر، 10 نمونه برای دستهبندی تولید کردیم که 4 ویژگی (در x) و یک برچسب دسته (در y) دارند. این نقاط به دسته منفی (0) و یا به دسته مثبت (1) تعلق دارند:
from sklearn.datasets import make_classification import pandas as pd X, y = make_classification(n_samples=10, n_features=4, n_classes=2, random_state=123)
اینجا X چهار ستون ویژگی برای نمونههای تولید شده را دربرمیگیرد:
pd.DataFrame(X, columns=['Feature_1', 'Feature_2', 'Feature_3', 'Feature_4'])

و y شامل برچسب مربوط به هر نمونه است:
pd.DataFrame(y, columns=['Label'])

2. مقادیر گمشده را جایگزین کنید
در Scikit-learn چندین راه برای جایگزینی مقادیر گمشده وجود دارد. در این بخش دو مورد از این روشها را بررسی میکنیم. کلاس SimpleImputer استراتژیهایی ساده برای جایگزینی مقادیر گمشده فراهم میکند (برای مثال با محاسبهی میانه یا میانگین مقادیر موجود). کلاس KNNImputer رویکرد پیچیدهتری برای جایگزینی مقادیر گمشده پیش پا میگذارد که در آن از ” K نزدیکترین همسایه ” استفاده میشود. در این روش هر مقدار گمشده با استفاده از مقادیر n_neighbors (که برای ویژگی مدنظر مقداری دارند) جایگزین میشود. سپس میانگین مقادیر این همسایهها را به صورت یکسان یا با در نظرگرفتن وزن آنها (که براساس فاصله با هر همسایه میباشد) محاسبه میکنیم و به جای مقدار گمشده قرار میدهیم.
در این قسمت نمونهای از کاربرد هر دو روش جایگزینی را مشاهده میکنید:
from sklearn.experimental import enable_iterative_imputer from sklearn.impute import SimpleImputer, KNNImputer from sklearn.datasets import make_classification import pandas as pd X, y = make_classification(n_samples=5, n_features=4, n_classes=2, random_state=123) X = pd.DataFrame(X, columns=['Feature_1', 'Feature_2', 'Feature_3', 'Feature_4']) print(X.iloc[1,2])
>>> 2.21298305
[irp posts=”8191″]مقدار X[1, 2] را به یک مقدار گمشده تبدیل کنید:
X.iloc[1, 2] = float('NaN')
X
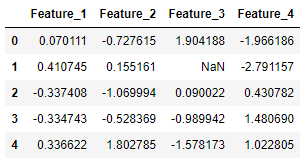
ابتدا از روش جایگزینکنندهی ساده استفاده میکنیم:
imputer_simple=SimpleImputer() pd.DataFrame(imputer_simple.fit_transform(X))

و در نهایت مقدار -0.143476 به دست میآید.
سپس از روش جایگزینکنندهی KNN استفاده میکنیم که طی آن دوتا از نزدیکترین همسایهها را که با توزیع یکسان وزندهی شدهاند، وارد معادله میکنیم:
imputer_KNN = KNNImputer(n_neighbors=2, weights="uniform") pd.DataFrame(imputer_KNN.fit_transform(X))

در نهایت مقدار 0.997105 به دست میآید. (=0.5×)1.904188+0.90022))
3. از پایپ لاین برای ادغام چندین گام استفاده کنید
پایپ لاین در Scikit-learn ابزاری مفید است که به سادهسازی مدل یادگیری ماشین کمک میکند. از پایپ لاینها میتوان برای ادغام گامها استفاده کرد. بدین ترتیب همهی دادهها توالی ثابتی از گامها را طی کنند. به بیان دیگر، پایپ لاین به جای فراخوانی هر گام به صورت مجزا، همهی گامها را در یک سیستم متمرکز میکند. برای تولید این روال از تابع make_pipeline استفاده میکنیم.
در این قسمت نمونهای از یک پایپ لاین را مشاهده میکنید که از یک روش جایگزینکننده (که در صورت لزوم مقادیر گمشده را جایگزین میکند) و یک دستهبند رگرسیون لجیستیک تشکیل شده است.
from sklearn.model_selection import train_test_split from sklearn.impute import SimpleImputer from sklearn.linear_model import LogisticRegression from sklearn.pipeline import make_pipeline from sklearn.datasets import make_classification import pandas as pd X, y = make_classification(n_samples=25, n_features=4, n_classes=2, random_state=123) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123) imputer = SimpleImputer() clf = LogisticRegression() pipe = make_pipeline(imputer, clf)
حال میتوانیم برای آموزش دادههای آموزشی و پیشبینی دادههای آزمایشی از پایپ لاین استفاده کنیم. دادههای آموزشی ابتدا از جایگزینکننده عبور کرده و سپس با استفاده از دستهبند رگرسیون لجستیک شروع به آموزش مدل میکند.
pipe.fit(X_train, y_train)
y_pred = pipe.predict(X_test)
pd.DataFrame({'Prediction': y_pred, 'True': y_test})

4. با استفاده از joblib یک مدل پایپ لاین ذخیره کنید
با استفاده از joblib میتوان مدلهای پایپ لاین که از طریق Scikit-learn ساخته شدهاند را به آسانی ذخیره کرد. در صورتی که مدلتان آرایههای بزرگی از داده¬ها داشته باشد، هر آرایه در یک فایل مجزا ذخیره خواهد شد. بعد از ذخیرهی محلی مدل، میتوانید به سادگی آنرا بارگذاری (یا بازیابی ) کنید و در برنامههای جدید به کار ببرید.
from sklearn.model_selection import train_test_split from sklearn.impute import SimpleImputer from sklearn.linear_model import LogisticRegression from sklearn.pipeline import make_pipeline from sklearn.datasets import make_classification import joblib X, y = make_classification(n_samples=20, n_features=4, n_classes=2, random_state=123) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123) imputer = SimpleImputer() clf = LogisticRegression() pipe = make_pipeline(imputer, clf) pipe.fit(X_train, y_train) joblib.dump(pipe, 'pipe.joblib')
بدین ترتیب با استفاده از تابع joblib.dump مدل پایپ لاین برازشیافته روی کامپیوتر ذخیره میشود. با تابع joblib.load میتوانید این مدل را بازیابی کرده و مطابق معمول به کار ببرید.
new_pipe = joblib.load('.../pipe.joblib')
new_pipe.predict(X_test)
5. یک ماتریس در همریختگی ترسیم کنید
ماتریس در همریختگی جدولی است که به منظور توصیف عملکرد یک دستهبند روی مجموعهای از دادههای آزمایشی استفاده میشود. اینجا به مسئلهی دستهبندی دودویی میپردازیم؛ در مسئلهی دستهبندی دودویی، دو دسته (بله (1) و خیر (0)) وجود دارد که مشاهدات ثبت شده میتوانند به آنها تعلق داشته باشند.
اجازه دهید یک مسئلهی دستهبندی دودویی را به عنوان نمونه طراحی کنیم و ماتریس درهمریختگی را با استفاده از تابع plot_confusion_matrix روی آن نمایش دهیم.
from sklearn.model_selection import train_test_split from sklearn.metrics import plot_confusion_matrix from sklearn.linear_model import LogisticRegression from sklearn.datasets import make_classification X, y = make_classification(n_samples=1000, n_features=4, n_classes=2, random_state=123) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123) clf = LogisticRegression() clf.fit(X_train, y_train) confmat = plot_confusion_matrix(clf, X_test, y_test, cmap="Blues")

با استفاده از ماتریس در همریختگی، نحوهی دستهبندی مشاهدات را میتوان به خوبی مصورسازی کرد:
• 93 مثبت حقیقی (TP)
• 97 منفی حقیقی (TN)
• 3 مثبت کاذب (FP)
• 7 منفی کاذب (FN)
طبق این ارقام میتوان گفت میزان دقت مدل 95% ((93+97)/200 = 95%) است.
6. درخت تصمیم رسم کنید
درخت تصمیم یکی از شناختهشدهترین الگوریتمهای دستهبندی است. خصوصیت بارز درختهای تصمیم، مصورسازیهای شبهدرختی آنهاست که بینش خوبی به دست میدهد. این الگوریتم، دادهها را بر اساس ویژگیهای توصیفی به بخشهای کوچکتر تقسیم میکند. هنگام پیشبینی داده، دستهای به عنوان پیشبینی انتخاب میشود که بیشترین تکرار دادههای آموزشی را در ناحیهای که دادهی آزمایشی قرار گرفته، داشته باشد. از معیار تقسیم به منظور تعیین میزان ارتباط و اهمیت هر یک از ویژگیها استفاده میکنیم و بدین ترتیب در مورد نحوهی تقسیم دادهها به نواحی تصمیمگیری میکنیم. بعضی از معیارهای تقسیم عبارتاند از: Information Gain، Gini index، و Cross-entropy.
اینجا مثالی از نحوهی استفاده از تابع plot_tree در sickit-learn را مشاهده میکنید:
from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier, plot_tree from sklearn.datasets import make_classification X, y = make_classification(n_samples=50, n_features=4, n_classes=2, random_state=123) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123) clf = DecisionTreeClassifier() clf.fit(X_train, y_train) plot_tree(clf, filled=True)

در این مثال، درخت تصمیم را براساس 40 مشاهدهی آموزشی (که به دسته مثبت (1) و یا به دسته منفی (0) تعلق دارند) آموزش میدهیم؛ پس میتوانیم بگوییم این مسئله از نوع دستهبندی دودویی است. در این درخت دو نوع گره داریم: گرههای داخلی (که در آن فضای پیشبین به تقسیم ادامه میدهد) و گرههای انتهایی (نقطهی نهایی). قسمتی از درخت که دو گره را به هم متصل میکند شاخه نامیده میشود.
حال میخواهیم به اطلاعات مربوط به هر گره در درخت تصمیم نگاهی دقیقتر بیاندازیم:
• معیار تقسیم در یک گرهی خاص، به صورت (برای مثال) ‘F2 <= -0.052’ نشان داده میشود؛ بدین معنی که هر نمونهای که این شرط را (مقدار ویژگی دوم (F2) زیر -0.052 باشد) برآورده کند به ناحیهی تازه شکلگرفتهی سمت چپ تعلق دارد و هر نقطهدادهای که این شرط را برآورده نکند، در ناحیهی سمت راست گرهی داخلی جای خواهد گرفت.
• اینجا از شاخص Gini به عنوان معیار تقسیم استفاده میکنیم. شاخص Gini (که معیار ناخالصی نامیده میشود) میزان یا احتمال دستهبندی اشتباه یک مؤلفهی خاص که به صورت تصادفی انتخاب شده را محاسبه میکند.
• قسمت samples در هر گره نشاندهندهی تعداد مشاهدات آموزشی موجود در آن گرهی خاص است.
• قسمت value در هر گره تعداد مشاهدات آموزشی موجود در طبقهی دسته (0) و دسته مثبت (1) را نشان میدهد. بنابراین وقتی value=[19,21] باشد، بدین معنی است که در آن گرهی خاص 19 مشاهدهی آموزشی در طبقهی منفی و 21 مشاهدهی آموزشی در طبقهی مثبت داریم.
نتیجهگیری
در این نوشتار 6 شگرد مفید برای کار با کتابخانهی Scikit-learn را توضیح دادیم که به ارتقای مدلهای یادگیری ماشینی را در sklearn کمک خواهند کرد.





