دفترچه راهنمای کتابخانه Matplotlib در پایتون؛ آموزش کامل مصورسازی دادهها
 تیم تحریریه
تیم تحریریه- ۲۲ خرداد ۱۴۰۰
کتابخانه Matplotlib پرکاربردترین ابزار پایتون در حوزه مصورسازی Visualization داده ها است. این کتابخانه در محیطهای مختلف از جمله سرورهای کاربردی Application servers، ابزارهای رابط کاربری گرافیکی Graphical user interface toolkits، Jupyter notebook، iPython و iPython shell پشتیبانی میشود.
معماری کتابخانه Matplotlib
کتابخانه Matplotlib دارای 3 لایه است که عبارتند از: لایه backend ، لایه artist و لایه scripting. لایه سمت سرور سه کلاس رابط دارد: 1. figure canvas که فضایی که نمودار در آن رسم خواهد شد را تعریف میکند، 2. renderer که مسئول رسم نمودار در figure canvas است و 3. event که با ورودیهای کاربر مثل کلیکها سروکار دارد. لایهartist برای رسم نمودار روی صفحه از renderer استفاده میکند. بنابراین، هر چیزی که در نمودار رسمشده توسط کتابخانه Matplotlib مشاهده میکنید، در حقیقت، مصداقی از یک لایهartist است. یعنی هر عنوان، برچسب، علامت و حتی خود نمودار یک لایهartist مجزا هستند. لایه scripting یک رابط سبکتر است که برای استفاده روزانه مناسب میباشد. در این مقاله، همه مثالها با استفاده از لایه scripting به شما نشان داده میشوند و همچنین از محیط Jupyter notebook استفاده خواهم کرد.
اگر هدفتان از خواندن این مقاله یادگیری کار با کتابخانه Matplotlib است، پیشنهاد میکنم که حتماً خودتان کدها را اجرا کنید تا طرزکار آن را ببینید.
آمادهسازی دادهها
معمولاً در همه پروژهها پیش از به تصویر کشیدن دادهها یا شروع تحلیل، فرآیند آمادهسازی دادهها صورت میگیرد. زیرا دادهها هیچوقت در قالب و شکلی که ما میخواهیم، نیستند. دیتاستی که در این مقاله آموزشی از آن استفاده خواهیم کرد حاوی اطلاعاتی در خصوص مهاجرت به کانادا است. ابتدا باید پکیجهای ضروری و دیتاست را وارد محیط کاری خود کنیم.
import numpy as np
import pandas as pd
df = pd.read_excel('https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/DV0101EN/labs/Data_Files/Canada.xlsx',
sheet_name='Canada by Citizenship',
skiprows=range(20),
skipfooter=2)
df.head()
من 20 سطر اول و 2 سطر آخر دیتاست را رد میکنم، چون این سطرها حاوی متن هستند، نه دادههایی که ما نیاز داریم. این دیتاست، بسیار بزرگ است و به همین دلیل، نمیتوانم از صفحه حاوی دادهها عکس بگیرم و برای شما نمایش دهم. در زیر میتوانید نام ستونهای دیتاست را ملاحظه فرمایید:
در این مقاله مربوط به کتابخانه Matplotlib قرار نیست همه این ستونها را استفاده کنیم. بنابراین، باید ستونهای بلااستفاده را حذف کنیم تا دیتاست کوچکتر و کار با آن راحتتر شود.
df.columns
#Output:
Index([ 'Type', 'Coverage', 'OdName', 'AREA', 'AreaName', 'REG',
'RegName', 'DEV', 'DevName', 1980, 1981, 1982,
1983, 1984, 1985, 1986, 1987, 1988,
1989, 1990, 1991, 1992, 1993, 1994,
1995, 1996, 1997, 1998, 1999, 2000,
2001, 2002, 2003, 2004, 2005, 2006,
2007, 2008, 2009, 2010, 2011, 2012,
2013],
dtype='object')
df.drop(['AREA','REG','DEV','Type','Coverage'], axis=1, inplace=True) df.head()

به نام ستونها دقت کنید، ستون OdName حاوی نام کشورها، AreaName نام قارهای که کشور مذکور در آن قرار دارد و RegName نیز نام منطقهای که کشور مربوطه در آن واقع شده، میباشند. اما من میخواهم نام ستونها را تغییر دهم تا گویاتر و قابلفهم باشند.
df.rename(columns={'OdName':'Country', 'AreaName':'Continent', 'RegName':'Region'}, inplace=True)
df.columns
#Output:
Index([ 'Country', 'Continent', 'Region', 'DevName', 1980,
1981, 1982, 1983, 1984, 1985,
1986, 1987, 1988, 1989, 1990,
1991, 1992, 1993, 1994, 1995,
1996, 1997, 1998, 1999, 2000,
2001, 2002, 2003, 2004, 2005,
2006, 2007, 2008, 2009, 2010,
2011, 2012, 2013],
dtype='object')
به این ترتیب، نام ستونهای دیتاست به Country به معنی کشور، Continent به معنی قاره، Region به معنی منطقه و DevName که بیانگر توسعهیافته یا درحالتوسعه بودن کشور است، تغییر پیدا کردند. ستونهایی که نام آنها نشاندهنده یک سال خاص است، حاوی شمار مهاجرانی که هستند که در آن سال وارد کانادا شدهاند. حالا میخواهم یک ستون جدید به نام total اضافه کنم که به ما بگوید چه تعداد مهاجر بین سال 1980 تا 2013 به کانادا آمدهاند.
[irp posts=”25866″]df['Total'] = df.sum(axis=1)

همانطور که مشاهده میکنید، یک ستون جدید به نام Total به انتهای دیتاست افزوده شده است.
حالا باید بررسی کنیم و ببینیم آیا سلول خالی یا سلولی حاوی مقدار null در ستونها وجود دارد؟
df.isnull().sum()
خروجی این خط از کد تعداد مقادیر در همه ستونها را صفر نشان میدهد. من دوست دارم همیشه ستون شاخص به جای یک سری عدد بیمعنی، ستونی باشد که مقادیر آن معنادارند. بنابراین، ستون را به عنوان شاخص تعیین میکنم.
این دیتاست از همان ابتدا تمیز و مرتب بود، بنابراین، عملیات پاکسازی دادهها را در همینجا به پایان میرسانیم. البته اگر عملیات دیگری نیاز باشد، در طی مسیر آن را انجام خواهیم داد.
df = df.set_index('Country')

تمرینهای رسم نمودار در کتابخانه Matplotlib
در این مقاله، رسم انواع نمودارها از جمله نمودار خطی، نمودار ناحیهای، نمودار دایرهای، نمودار پراکنش، نمودار میلهای و هیستوگرام را تمرین خواهیم کرد.
%matplotlib inline import matplotlib.pyplot as plt import matplotlib as mpl
اگر از همان ابتدا سبک نمودار خود را انتخاب کنید، دیگر لازم نخواهد بود روی جنبههای هنری آن زمان زیادی بگذارید. در زیر لیست گزینههای موجود را مشاهده میفرمایید:
plt.style.available #Output: mpl.style.use(['ggplot']) 'classic', 'dark_background', 'fast', 'fivethirtyeight', 'ggplot', 'grayscale', 'seaborn-bright', 'seaborn-colorblind', 'seaborn-dark-palette', 'seaborn-dark', 'seaborn-darkgrid', 'seaborn-deep', 'seaborn-muted', 'seaborn-notebook', 'seaborn-paper', 'seaborn-pastel', 'seaborn-poster', 'seaborn-talk', 'seaborn-ticks', 'seaborn-white', 'seaborn-whitegrid', 'seaborn', 'Solarize_Light2', 'tableau-colorblind10', '_classic_test']
من در اینجا گزینه ggplot را برای نمودارم انتخاب میکنم. شما میتوانید گزینههای دیگر را نیز امتحان کرده و سبک موردعلاقه خود را برگزینید.
نمودار خطی
به نظر من به تصویر کشیدن تمایل کشورهای مختلف به مهاجرت به کانادا جالب خواهد بود. به این منظور، ابتدا یک لیست از سالهایی که در دیتاست داریم (یعنی1980 تا 2014) ایجاد میکنم.
years = list(map(int, range(1980, 2014)))
برای این نمودار کشور سوئیس را انتخاب کردم و میخواهم دادههای مربوط به آن را روی نمودار نمایش دهم. پس باید دادههای مهاجرت مردم سوئیس به کانادا را در هر سال تهیه کنم.
df.loc['Switzerland', years]

در تصویر بالا بخشی از دادههای مربوطه را مشاهده میکنید. حال زمان رسم نمودار است. کار بسیار آسانی است. تنها کافی است تابع plot را فراخوانی کنید، دادههایی که اماده کردهاید را به آن بدهید و در آخر نیز عنوان و برچسبهای محور x و y را تعیین کنید.
df.loc['Switzerland', years].plot()
plt.title('Immigration from Switzerland')
plt.ylabel('Number of immigrants')
plt.xlabel('Years')
plt.show()

حال اگر بخواهیم روند مهاجرت چند کشور به کانادا را طی این سالها مشاهده و با هم مقایسه کنیم، باز هم کار سختی نخواهد بود. تنها کافیست در لیست دادهها به جای یک کشور، نام کشورهای مدنظر را همراه با سال بیاوریم. در اینجا من میخواهم سه کشور هند، پاکستان و بنگلادش را با هم مقایسه کنم.
ind_pak_ban = df.loc[['India', 'Pakistan', 'Bangladesh'], years] ind_pak_ban.head()
فرمت دادهها در اینجا با مثال قبلی متفاوت است. اگر تابع plot را روی همین دیتافریم اعمال کنیم، روی محور xها تعداد مهاجران هر کشور و روی محور yها، سال را خواهیم داشت. پس باید فرمت دیتاست را تغییر دهیم:

ind_pak_ban.T

در این تصویر تنها بخشی از دیتاست را مشاهده میکنید، اما میتوانید ببینید که فرمت آن چگونه تغییر کرده است. حال با فراخوانی تابع plot، سال روی محور xها و شمار مهاجران هر کشور روی محور yها رسم خواهد شد.
در این مثال لازم نبود نام نمودار را ذکر کنیم، زیرا پیشفرض این تابع، نمودار خطی است.
[irp posts=”25814″]ind_pak_ban.T.plot()

نمودار دایرهای
در این مثال میخواهم شمار مهاجران هر قاره را روی نمودار دایرهای به تصویر بکشم. ما دادهها را برای هر کشور داریم، پس اگر کشورها را براساس قارهای که در آن واقع شدهاند گروهبندی کنیم و تعداد مهاجران هر گروه را به دست آوریم، در واقع شمار مهاجران هر قاره را خواهیم داشت.
cont = df.groupby('Continent', axis=0).sum()
بسیار خب، به این ترتیب دیتاستی داریم که شمار مهاجران هر قاره را به ما نشان میدهد. این دیتاست بسیار بزرگ است و در این صفحه جای نمیگیرد، اما شما میتوانید این دیتاست را فراخوانی و چاپ کنید تا ببینید دادهها در آن به چه صورت هستند. حالا بیایید نمودار آن را رسم کنیم.
cont['Total'].plot(kind='pie', figsize=(7,7),
autopct='%1.1f%%',
shadow=True)
#plt.title('Immigration By Continenets')
plt.axis('equal')
plt.show()
اگر به این کد دقت کنید، میبینید که تابع ما دارای پارامتری به نام «kind» است. غیر از نمودار خطی، باید نوع سایر نمودارها را با این پارامتر تعیین کنید. همچنین پارامتر جدیدی به نام «figsize» در تابع تعریف کردهام که ابعاد نمودار را تعیین میکند.

این نمودار دایرهای واضح و قابلفهم است، اما با اندکی تلاش میتوان آن را بهتر و زیباتر کرد. به این منظور میخواهم رنگها و زاویه شروع نمودار را خودم تعیین کنم.
colors = ['lightgreen', 'lightblue', 'pink', 'purple', 'grey', 'gold']
explode=[0.1, 0, 0, 0, 0.1, 0.1]
cont['Total'].plot(kind='pie', figsize=(17, 10),
autopct = '%1.1f%%', startangle=90,
shadow=True, labels=None, pctdistance=1.12, colors=colors, explode = explode)
plt.axis('equal')
plt.legend(labels=cont.index, loc='upper right', fontsize=14)
plt.show()

نمودار جعبهای
در این مثال ابتدا نمودار جعبهای برای شمار مهاجران چینی رسم میکنیم.
china = df.loc[['China'], years].T
این از دادههای موردنیازمان؛ حالا برویم سراغ رسم نمودار جعبهای:
china.plot(kind='box', figsize=(8, 6))
plt.title('Box plot of Chinese Immigratns')
plt.ylabel('Number of Immigrnts')
plt.show()

اگر به دنبال نکات و تکنیکهای بیشتری در خصوص نمودارهای جعبهای میگردید، میتوانید به این لینک مراجعه فرمایید.
امکان رسم چندین نمودار جعبهای در یک نمودار هم وجود دارد. در اینجا با استفاده از دیتافریم قبلی یعنی «ind_pak_ban»، نمودار جعبهای هر سه کشور هند، پاکستان و بنگلادش را روی یک نمودار رسم میکنم.
ind_pak_ban.T.plot(kind='box', figsize=(8, 7))
plt.title('Box plots of India, Pakistan and Bangladesh Immigrants')
plt.ylabel('Number of Immigrants')

نمودار پراکنش
رسم یک نمودار پراکنش بهترین راه برای شناسایی رابطه میان متغیرهاست. نمودار پراکنش را رسم کنید تا روند مهاجرت به کانادا طی سالهای 1980 تا 2013 را مشاهده کنید.
برای رسم این نمودار یک دیتافریم جدید ایجاد میکنم که حاوی تعداد کل مهاجرانی است که در هر سال به کانادا مهاجرت کردهاند و متغیر years در آن به عنوان شاخص درنظر گرفته شده است.
totalPerYear = pd.DataFrame(df[years].sum(axis=0)) totalPerYear.head()

ما باید نوع متغیر years را به عدد صحیح یا int تبدیل کنیم. در ادامه قصد دارم اندکی دیتاست را دستکاری کنم تا درک آن آسانتر شود.
totalPerYear.index = map(int, totalPerYear.index) totalPerYear.reset_index(inplace=True) totalPerYear.head()
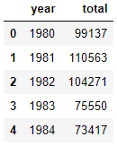
در نمودار پراکنش باید محور xها و yها را مشخص کنیم.
totalPerYear.plot(kind='scatter', x = 'year', y='total', figsize=(10, 6), color='darkred')
plt.title('Total Immigration from 1980 - 2013')
plt.xlabel('Year')
plt.ylabel('Number of Immigrants')
plt.show()

به نظر میرسد بین دو متغیر سال و تعداد مهاجران یک رابطه خطی وجود دارد و روند مهاجرت از سال 1980 تا 2013 روندی صعودی داشته است.
نمودار ناحیهای
نمودار ناحیهای در حقیقت سطح زیر منحنی خطی را نمایش میدهد. برای رسم این نمودار میخوام از دیتافریمی استفاده کنم که حاوی دادههای مربوط به 4 کشور هند، چین، پاکستان و فرانسه است.
top = df.loc[['India', 'China', 'Pakistan', 'France'], years] top = top.T

دیتاست ما آماده است، حالا نوبت رسم نمودار است.
colors = ['black', 'green', 'blue', 'red']
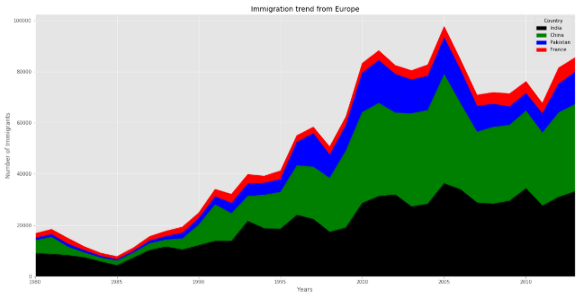
top.plot(kind='area', stacked=False,
figsize=(20, 10), colors=colors)
plt.title('Immigration trend from Europe')
plt.ylabel('Number of Immigrants')
plt.xlabel('Years')
plt.show()

در کتابخانه Matplotlib اگر میخواهید نمودار هر کشور به صورت جداگانه رسم شود، یادتان باشد که مقدار پارامتر «stacked» را حتماً برابر False قرار دهید، در غیر این صورت نمودار شما به شکل زیر خواهد شد:
وقتی مقداری برای stacked تعیین نشود، ناحیه متغیرها به صورت مجزا نمایش داده نمیشود، بلکه روی متغیر قبلی رسم میشود.
هیستوگرام
نمودار هیستوگرام توزیع یک متغیر را نشان میدهد. به مثال زیر توجه کنید:
df[2005].plot(kind='hist', figsize=(8,5))
plt.title('Histogram of Immigration from 195 Countries in 2010')
# add a title to the histogram
plt.ylabel('Number of Countries')
# add y-label
plt.xlabel('Number of Immigrants')
# add x-label
plt.show()

روی این نمودار هیستوگرام 2005 داده را به تصویر کشیدهام. از این نمودار پیداست که کانادا از اکثر کشورها بین 0 تا 5000 مهاجر داشته است. و تنها تعداد محدودی کشور بودهاند که 20000 یا 40000 هزار مهاجر به کانادا داشتهاند.
حالا بیایید با استفاده از دیتافریم top که برای نمودار پراکنش تعریف کرده بودیم، توزیع مهاجران هر کشور را نیز رسم کنیم.
top.plot.hist()
plt.title('Histogram of Immigration from Some Populous Countries')
plt.ylabel('Number of Years')
plt.xlabel('Number of Immigrants')
plt.show()

در نمودار هیستوگرام قبلی دیدیم که کشورهای کمی بودند که 20000 یا 40000 هزار مهاجر به کانادا داشتند. بهنظر میرسد که چین و هند در میان این کشورها قرار دارند. در این نمودار، حاشیه میان «ستونها» واضح نیست. پس بیایید نمودار بهتری رسم کنیم.
[irp posts=”7626″]تعیین تعداد ستونها و مشخص کردن حاشیه ستونها در کتابخانه Matplotlib
در این نمودار 15 ستون رسم خواهم کرد. همچنین، یک پارامتر جدید به نام alpha به مدل اضافه میکنم که شفافیت رنگها را تعیین میکند. در نمودارهایی مثل این نمودار که ستونها روی هم قرار میگیرند، با تغییر میزان شفافیت میتوان شکل همه توزیعها را مشاهده کرد.
count, bin_edges = np.histogram(top, 15)
top.plot(kind = 'hist', figsize=(14, 6), bins=15, alpha=0.6,
xticks=bin_edges, color=colors)

من رنگ ستونها را دقیق مشخص نکردم، به همین دلیل، رنگها در این نمودار با نمودار قبلی متفاوت است. اما در این نمودار به لطف کاهش شفافیت رنگها، میتوانید هر توزیع را به وضوح ببینید.
همانطور که در نمودار ناحیهای دیدید، با تعریف مقدار True پارامتر stacked میتوان از روی هم قرار گرفتن نمودارها جلوگیری کرد.
top.plot(kind='hist',
figsize=(12, 6),
bins=15,
xticks=bin_edges,
color=colors,
stacked=True,
)
plt.title('Histogram of Immigration from Some Populous Countries')
plt.ylabel('Number of Years')
plt.xlabel('Number of Immigrants')
plt.show()

نمودار میلهای
برای رسم نمودار میلهای، از دادهها کشور فرانسه استفاده میکنم و تعداد مهاجران فرانسوی هر سال را روی نمودار میآورم.
france = df.loc['France', years]
france.plot(kind='bar', figsize = (10, 6))
plt.xlabel('Year')
plt.ylabel('Number of immigrants')
plt.title('Immigrants From France')
plt.show()

میتوانید اطلاعات بیشتری نیز به نمودار اضافه کنید. در این نمودار از سال 1997 به بعد و برای یک دهه کامل، شاهد روند صعودی هستیم که ذکر کردن آن خالی از لطف نخواهد بود. این کار را میتوان به کمک تابع annotate انجام داد.
france.plot(kind='bar', figsize = (10, 6))
plt.xlabel('Year')
plt.ylabel('Number of immigrants')
plt.title('Immigrants From France')
plt.annotate('Increasing Trend',
xy = (19, 4500),
rotation= 23,
va = 'bottom',
ha = 'left')
plt.annotate('',
xy=(29, 5500),
xytext=(17, 3800),
xycoords='data',
arrowprops=dict(arrowstyle='->', connectionstyle='arc3', color='black', lw=1.5))
plt.show()

گاهی اوقات، اگر میلهها بهصورت افقی قرار بگیرند، نمودار قابلفهمتر خواهد شد. همچنین، نوشتن اعداد روی میلهها نیز به بهبود نمودار کمک خواهد کرد. پس بیایید این دو مورد را نیز روی نمودار اعمال کنیم.
france.plot(kind='barh', figsize=(12, 16), color='steelblue')
plt.xlabel('Year') # add to x-label to the plot
plt.ylabel('Number of immigrants') # add y-label to the plot
plt.title('Immigrants From France') # add title to the plot
for index, value in enumerate(france):
label = format(int(value), ',')
plt.annotate(label, xy=(value-300, index-0.1), color='white')
plt.show()

در این مقاله به مفاهیم مقدماتی کتابخانه Matplotlib پرداختیم و به این ترتیب، شما دانش کافی برای استفاده از این کتابخانه را به دست آوردید.