
10 چیزی که درباره مدل BERT و معماری Transformer نمیدانید!
 تیم تحریریه
تیم تحریریه- ۲۹ تیر ۱۴۰۰
در این مقاله میخواهیم به مواردی درباره مدل BERT و معماری Transformer که احتمالا نمیدانید اشاره کنیم. در حال حاضر، پردازش زبان طبیعی از محبوبیت زیادی برخوردار است و فقط تعداد کمی از زیرشاخههای هوش مصنوعی یارای برابری با آن را دارند. طی سالهای اخیر، مدلهای زبانی تکامل یافتند و در حل مسائل زبانی عملکردی بهتر و فراتر از حد انتظار داشتند.
در حقیقت، عملکرد این مدلها به اندازهای بهبود یافته که برخی معتقدند یا این مدلها در حال نزدیکشدن به هوش عام (general intelligence) هستند و یا معیارهایی که ما برای ارزیابی آنها استفاده میکنیم، دیگر کارایی لازم را ندارند. زمانیکه چنین فناوریهایی، خواه الکتریسیته باشد، خواه خطوط راه آهن، اینترنت یا iPhone، پا به عرصه ظهور میگذارند، نمیتوانیم وجود و اهمیتشان را نادیده بگیریم. در نهایت این فناوریها تمامی جنبههای دنیای مدرن را تحت تأثیر قرار میدهند.
از این روی، باید به مطالعه و بررسی این فناوریها بپردازیم و از آنها به سود خود و در جهت رسیدن به مقاصدمان استفاده کنیم.
در این نوشتار، برای یافتن پاسخ سؤالاتی از جمله: سرمنشاء این فناوریها کجاست؟ چگونه توسعه یافتند؟ کارکردشان به چه صورت است؟ در آینده نزدیک چه دستاوردهایی برای ما خواهند داشت؟ و غیره، ده مورد را با یکدیگر بررسی میکنیم:
- اهمیت شناخت مدل BERT و Transformer در چیست؟ در حال حاضر، مدلهایی همچون مدل BERT تأثیرات شگرفی بر حوزههای دانشگاهی و کسبوکار دارند و به همین دلیل لازم میدانیم نحوه استفاده از آنها را شرح دهیم و برخی اصطلاحات تخصصی مرتبط با آنها را تعریف کنیم.
- پیش از روی کار آمدن این مدلها، چگونه مسائل زبانی را حل میکردیم؟ برای درک بهتر این مدلها، لازم است مسائل زبانی را بررسی کنیم و ببینیم پیش از روی کار آمدن مدلهایی همچون مدل BERT چگونه آنها را حل میکردیم. در این صورت، متوجه میشویم مدلهای قبلی چه محدودیتهای داشتند و علاوه بر این، به درک بهتری از معماری Transformer، که زیربنای بیشتر مدلهای SOTA همچون مدل BERT را تشکیل میدهد، میرسیم.
- مدلهای پیش آموزش داده شده ImageNet در NLP: پیش از این، یا هر فردی به طور جداگانه مدلی برای خود آموزش میداد و یا مجبور بود مدلش را از اول برای انجام مسئلهای خاص آموزش دهد. ساخت مدلهای از پیش آموزش داده شده را میتوان نقطه عطفی در تکامل و بهبود سریع عملکرد مدلها دانست. در فرایند یادگیری انتقالی میتوانیم از این مدلها به صورت آماده (off-the-shelf) استفاده کنیم و با صرف تلاش و دادهی کمتر آنها را برای حل مسئلهی مورد نظرمان تنظیم کنیم. به همین دلیل، این مدلها همواره در حل مسائل NLP عملکرد خوبی داشتند.
- آشنایی با Transformer: احتمالاً با مدل BERT و GPT-3 آشنایی دارید، اما آیا تا به حال نام Roمدل BERTa، ALمدل BERT، XLNET، LONGFORMER، REFORMER یا T5 Transformer را شنیدهاید؟ تعداد مدلهای جدید، بیش از حد زیاد است، اما اگر با معماری Transformer آشنایی داشته باشید، درک عملکرد داخلی آنها دشوار نخواهد بود. درست مثل این است که اگر با فناوری RDBMS آشنایی داشته باشید، میتوانید با نرمافزارهایی همچون MySQL، PostgreSQL، SQL Server یا Oracle کار کنید. مدلی که پایه تمامی نرمافزارهای DB را تشکیل میدهد از جهات بسیاری شبیه به معماری Transformer است که زیربنای مدلهای ما را تشکیل میدهد. حال متوجه میشوید که تفاوت Roمدل BERT یا XLNet تنها در استفاده از MySQL یا PostgreSQL است. یادگیری تفاوتهای جزئیای که میان این مدلها وجود دارد، به صرف زمان نیاز دارد، اما مهم این است که شما اطلاعات پایه زیادی دارید و دیگر لازم نیست به جزئیات بپردازید.
- اهمیت دو سویه بودن: انسانها متون را از یک سَمت به سَمت دیگر نمیخوانند. به عبارت دیگر، ما جملات را لغت به لغت و در یک جهت نمیخوانیم. در عوض، به جملات و عبارات بعدی نیز توجه داریم و بافت را از روی واژهها و حروف بعدی یاد میگیریم. یکی از مهمترین ویژگیهای معماری Transformer دو سویه بودن است. معماری Transformer مدلها را قادر میسازد متن را به صورت دو سویه، از اول تا آخر و از آخر به اول، پردازش کنند. این مورد یکی از اصلیترین محدودیتهای مدلهای قبلی بوده است؛ به عبارت دیگر این مدلها فقط میتوانستند متن را از اول به آخر پردازش کنند.
- مدل مدل BERT و Transformer چه تفاوتی با یکدیگر دارند؟ مدل BERT از معماری Transformer استفاده میکند، اما از چند جهت با آن تفاوت دارد. نکتهای که باید به آن توجه داشته باشید این است که تمامی این مدلها با Transformer تفاوت دارند و همین تفاوتها است که تعیین میکند چه مدلی برای حل یک مسئله خاص مناسب است و چه مدلهایی در حل این مسائل به مشکل میخورند.
- توکنساز– مدلها چگونه متن را پردازش میکنند: مدلها متن را مثل انسانها نمیخوانند، به همین دلیل باید متن را به نحوی رمزگذاری کنیم تا الگوریتم های یادگیری عمیق بتوانند آن را پردازش کند. چگونگی رمزگذاری متن تأثیر شگرفی بر عملکرد مدل دارد. به طور کلی، با نگاهی به توکنسازی مدل میتوانید چیزهای زیادی در مورد آن یاد بگیرید.
- ماسکگذاری – هوش در برابر تلاش: برای رسیدن به یک هدف یا باید سخت کار کنید و یا هوشمندانه عمل کنید. مدلهای NLP یادگیری عمیق نیز از این قاعده مستثنی نیستند. در اینجا منظور از سختکوشی این است که از رویکرد Transformer ساده استفاده کنید و برای اینکه مدل عملکرد خوبی داشته باشد، آن را بر روی حجم بالایی از دادهها آموزش دهید. مدلهایی همچون GPT-3 پارامترهای بیشماری دارند و به همین دلیل میتوانند عملکرد خوبی داشته باشند. از سوی دیگر، میتوانید تغییراتی در رویکرد آموزشی مورد نظرتان ایجاد کنید و مدلتان را «مجبور کنید» تا در عین اینکه بر روی دادههای کمی آموزش میبیند، چیزهای زیادی بیاموزد. مدلهایی همچون مدل BERT با تکیه بر عملیات ماسکگذاری چنین کاری انجام میدهند. آیا این مدلها با تکیه بر تکنیکهای خلاقانه، میزان «دانشی» که مدلها از داده ها استخراج میکنند را افزایش میدهند؟ و یا اینکه رویکرد سختگیرانه تری در پیش گرفتهاند و مقیاس مدل را تا زمانیکه دیگر کارایی نداشته باشد ، افزایش میدهند؟
- تنظیم دقیق و یادگیری انتقالی: یکی از مزایای کلیدی مدل BERT این است که میتوانیم آن را برای حوزههای خاصی به صورت دقیق تنظیم کنیم و آن را بر روی چندین مسئله متفاوت آموزش دهیم. مدلهایی همچون مدل BERT و GPT-3 چگونه حل چندین مسئله مختلف را یاد میگیرند؟
- صندلیهایی به شکل آواکادو–مدلهای مدل BERT و Transformer چه دستاوردهایی برای ما به همراه خواهند داشت؟ برای مطالعه معماریهای مدل BERT و Transformer به بررسی دستاوردهای این مدلها در آینده خواهیم پرداخت.
-
فهرست مقاله پنهان
اهمیت شناخت مدل BERT و Transformer در چیست؟

برای درک گستره و سرعت مدل BERT و Transformer بهتر است تاریخچه آنها را بررسی کنیم:
- 2017: معماری Transformer برای اولین بار در ماه دسامبر سال 2017 و در یکی از مقالات ترجمه ماشینی گوگل تحت عنوان “Attention Is All You Need” به معنای اینکه توجه همه آن چیزی است که نیاز دارید» معرفی شد. نویسندگان در این مقاله تلاش کردند مدلهایی با توانایی ترجمه خودکار متون چند زبانی پیدا کنند. پیش از این، بیشتر تکنیکهای ترجمه ماشینی نسبتاً نیمه خودکار بودند، اما این تکنیکها برای اینکه مطمئن شوند کیفیت ترجمه به اندازهای خوب و قابل قبول است که بتوان از آن در سرویسهایی همچون Google Translate استفاده کرد، از قوانین و ساختارهای زبانی مهمی پیروی میکردند.
- 2018: مدل BERT (مخفف Bidirectional Encoder Representations from Transformers) برای اولین بار در ماه اکتبر سال 2018 در مقالهای تحت عنوان “Pre-Training of Deep Bidirectional Transformer for Language Understanding” به معنای پیش آموزش ترنسفورمر عمیق و دوسویه برای درک زبان» معرفی شد.

در ابتدا، Transformer عمدتاً در حوزه ترجمه ماشینی مورد استفاده قرار میگرفت. اما پیشرفتهای ناشی از این رویکرد جدید به سرعت مورد توجه قرار گرفتند. اگر مدل Transformer به همان حوزه ترجمه محدود میماند، نیازی به نگارش و خواندن این مقاله نبود.
ترجمه یکی از هزاران مسئله NLP است؛ تگگذاری اجزای جمله (POS)، تشخیص موجودیتهای اسمی (NER)، طبقهبندی عواطف و احساسات، پرسش و پاسخ، تولید متن، خلاصهسازی، یافتن شباهتهای میان دو متن و غیره نیز نمونههایی از مسائل NLP هستند. پیش از این، برای حل هر یک از این مسائل میبایست یک مدل جداگانه آموزش میدادیم و به همین دلیل، نیازی به یادگیری تمامی این مسائل نبود و هر کس به حوزه تخصصی و مسئلهای خاص محدود میماند.
اما برخی تصمیم گرفتند از معماری Transformer برای انجام کارهایی به غیر از ترجمه متن استفاده کنند و در نتیجه شرایط به کلی تغییر کرد. آنها متوجه شدند که این معماری میتواند توجه خود را به لغات خاصی معطوف کند و در مقایسه با مدلهای دیگر میتواند متنها بیشتری پردازش کند و به همین دلیل تصمیم گرفتند از این معماری در حل مسائل دیگر کمک بگیرند.
در بخش 5 به معرفی مکانیزم «توجه» معماری Transformer میپردازیم و به شما نشان میدهیم که چگونه مدلها با استفاده از این مکانیزم توانستند متون را به صورت دو سویه پردازش کنند و توجه خود را به بخشهای مرتبط با بافت جمله معطوف کند و به صورت همزمان متن را پردازش کند.
تأثیر و اهمیت معماری Transformer زمانی افزایش یافت که این افراد متوجه شدند میتوان این معماری را به چندین بخش تقسیم کرد و از آن برای حل مسائل گوناگونی کمک گرفت:


از زمان انتشار این مقالات چند سال میگذرد، اما در همین زمان کوتاه هم توانستنهاند در دسته تأثیرگذارترین و مقالاتی با بیشترین تعداد ارجاع قرار بگیرند | منبع: تأثیرگذارترین مقالات Googel Scholar در سال 2020
در همین زمان، معماری Transformer به خارج از حوزه NLP راه پیدا کرد. پس از راهیابی معماری Transformer به حوزههای دیگر، آینده هوش مصنوعی دیگر در گرو رباتهای حساس و اتومبیلهای خودران نبود.
این مدلها میتوانند بافت و معنا را با تکیه بر متن بیاموزند و تعداد زیادی از مسائل زبانی را حل کنند؛ آیا این به این معناست که آنها متن را میفهمند و درک میکنند؟ آیا این مدلها میتوانند شعر بگویند؟ میتوانند لطیفه بگویند؟ اینکه این مدلها توانستهاند در حل مسائل NLP عملکردی بهتر از انسانها داشته باشند، بدین معنا نیست که به هوش عام دست پیدا کردهاند؟
سؤالاتی از این دست بدین معنا است که کاربرد این مدلها دیگر به رباتها و ترجمه ماشینی محدود نیست و در عوض آنها بخشی از یک چشمانداز بزرگتر، یعنی هوش مصنوعی عام (AGI) هستند.
همانند دیگر فناوریهای تحولآفرین، باید ببینیم آیا در مورد قابلیتهای این فنآوری اغراق شده یا آنگونه که باید و شاید به قابلیتهای ان توجه نشده است. زمانیکه الکتریسیته اختراع شد، هیچ کس فکر نمیکرد این فنآوری بتواند دنیا را متحول کند، زیرا فکر میکردند مدت زمان زیادی طول میکشد تا برق به محیطهای کاری و شهری راه پیدا کند و به طور گسترده مورد استفاده قرار بگیرد.
روند پذیرش خطوط راهآهن و اینترنت نیز متفاوت از الکتریسیته نبود. نکته حائز اهمیت این است که چه مخالف باشید و چه موافق، باید با فناوریهایی که به سرعت مسیر رشد و پیشرفت را طی میکنند، آشنایی داشته باشید.
در حال حاضر، با مدلهایی همچون مدل BERT در چنین شرایطی به سر میبریم. حتی اگر ال آنها استفاده نکنید، باز هم باید با تأثیرات احتمالی آنها بر روی آینده AI و اینکه آیا این فناوریها ما را به توسعه هوش مصنوعی عام نزدیکتر میکنند، آگاهی داشته باشید.
2. پیش از روی کار آمدن مدل BERT، از چه مدلهایی برای حل مسائل استفاده میکردیم؟
مدل BERT و معماری Transformer را میتوان در چارچوب مسائلی که درصدد حل آن برآمده بودند، بررسی کرد. پیشرفت یادگیری ماشین و NLP در گرو تکامل فناوریهایی است که سعی دارند کاستیها و محدودیتهای فناوری کنونی را برطرف و جبران کنند. اتومبیلهای مقرون به صرفه و ایمنی که هنری فورد تولید کرد توانستند جای اسبها را بگیرند. مردم میتوانند از طریق تلگراف و بدون نیاز به حضور فیزیکی با دیگران ارتباط برقرار کنند و همین مورد تلگراف را از فنآوریهای پیشین خود متمایز میکند.
پیش از روی کار آمدن مدل BERT، مهمترین دستاوردهای حوزه NLP عبارت بودند از:
- 2013: مقاله Word2Vec تحت عنوان Efficient Estimation of Word Representation in Vector Space منتشر شد و به منظور تشخیص معنا و یافتن شباهتهای میان لغات، تعبیههای پیوسته کلمه ایجاد شد.
- 2015: رویکرد Seq2seq و تولید متن در مقالهای تحت عنوان A Neural Conversation Model معرفی شد. اساس این رویکرد را فنآوریهایی تشکیل میدهند که برای اولین بار در Word2Vec استفاده شدند؛ به عبارت دیگر، این رویکرد بر پایه توان بالقوه شبکههای عصبی DL در یادگیری اطلاعات معنایی و نحویِ حجم بالایی از متون ساختارنیافته استوار است.
- 2018: مقاله تعبیههای مدلهای زبانی (ELMo) تحت عنوان Deep contextualized word representatios منتشر شد. ELMo گام بزرگی در تعبیهی کلمات به شمار میآمد. این رویکرد کوشید به جای اینکه همانند Word2Vec فقط به یک کلمه و یک معنا توجه کند، بافتی که کلمه در آن استفاده میشد را نیز در نظر بگیرد.
پیش از معرفی تکنیک Word2Vec، تعبیههای کلمات یا به صورت مدل سادهای متشکل از چندین بُردار پراکنده ظاهر میشوند که به شیوه one-hot کدگذاری شده بودند و یا برای ایجاد تعبیههای بهتر و نادیده گرفتن کلمات معمولی همچون “the”، “this”، “that” که حاوی اطلاعات کمی بودند، از رویکردهای TF-IDF استفاده میکردیم.

در چنین رویکردهایی کوچکترین واحد معنایی بُردارها کدگذاری میشد. با استفاده از چنین رویکردهایی میتوانستیم متون را طبقهبندی کنیم و شباهتهای میان اسناد را مشخص کنیم، اما آموزش چنین رویکردهایی دشوار و نرخ دقت آنها پایین بود.
تکنیک Word2Vec دو معماری جدید برای شبکه های عصبی معرفی کرد و تغییراتی اساسی در این حوزه ایجاد کرد. این دو معماری که skip-gram و Continuous Bag-Of-Words (CBOW) نامیده میشوند ما را قادر میسازند تعداد متون بیشتری به تعبیههای کلمات آموزش دهیم. عملکرد این دو معماری بدین صورت است که نمونههایی از سایر کلمات و لغات تشکیلدهنده جمله در اختیار شبکه عصبی قرار میدهند و شبکه را وادار میکنند کلمات صحیح را پیشبینی کند.
نظریه زیربنایی چنین رویکردی این بوده که کلمات معمولی در کنار یکدیگر استفاده میشوند. برای مثال، اگر فردی بخواهد راجع به «تلفن» صحبت کند، احتمالاً کلماتی همچون «تلفن همراه»، «آیفون»، «اندروید»، «باتری»، «صفحه لمسی» و غیره را نیز در جملاتش به کار میبرد. احتمالاً این کلمات به صورت مکرر در کنار یکدیگر استفاده میشوند و بدین ترتیب مدل بُردار وزندار بزرگتری طراحی میکند. مدل به کمک این بُردار میتواند کلماتی که احتمال دارد به همراه «تلفن» یا «موبایل» و غیره استفاده شوند را پیشبینی کند. ضمناً با استفاده از این وزنها یا تعبیهها میتوانیم کلماتی که مشابه یکدیگر هستند را مشخص کنیم.
این رویکرد بر روی نمونههایی از تولید متن تعمیم داده شد و فرایندی مشابه بر روی توالیهای متنی طولانیتر، برای مثال جمله، انجام شد. این رویکرد با نام Seq2Seq شناخته میشود. در نتیجه معرفی این رویکرد، دامنه معماریهای DL گسترش یافت و از آنها برای حل مسائل پیچیدهتر NLP استفاده شد.
این رویکرد کوشید راهحلی برای این مشکل کلیدی که زبان جریانی پیوسته از کلمات است، بیابد. طول جملات متغیر است و از هیچ استانداردی پیروی نمیکنند. به طور کلی، مدلهای یادگیری عمیق باید طول توالی دادههایی که پردازش میکنند را بدانند. اما مشخص کردن طول متون غیرممکن است.
لذا، مدل Seq2seq از تکنیکی به نام RNNها کمک گرفت. این معماریها به کمک RNNها میتوانستند عملیات «حلقه زدن» را انجام دهند و متن را به طور پیوسته پردازش کنند.
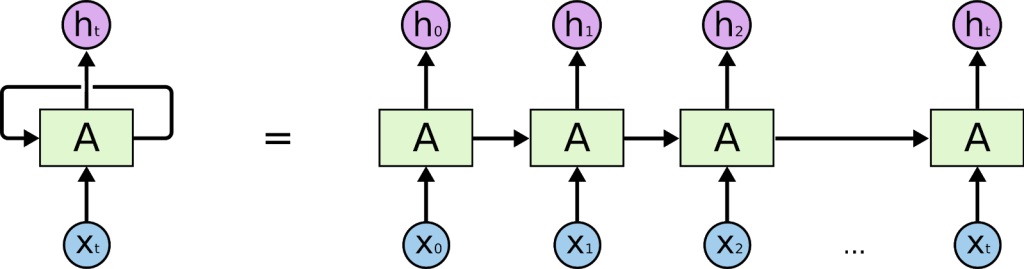
مدلهایی همچون Word2Vec و معماریهایی از قبیل RNN پیشرفتهای شگرفی در حوزه NLP به شمار میآیند اما نواقص و محدودیتهای مخصوص به خود را دارند. تعبیههای Word2Vec ایستا و ثابت بود؛ به عبارت دیگر، علیرغم اینکه کلمات بسته به بافت میتوانند معانی متفاوتی داشته باشند، در این تکنیک برای هر لغت یک تعبیه ثابت وجود داشت. فرایند آموزش RNNها نیز کُند و زمانبر بود و به همین دلیل دادههایی که برای آموزش آنها میتوانستیم به کار ببریم نیز محدود بودند.
همانگونه که گفتیم، تلاش مدلهای جدید بر این است که نواقص و کاستیهای مدلها و معماریهای قبلی را رفع کنند. ELMo کوشید مشکل ثابت بودن تعبیههای کلمات Word2Vec را برطرف کند و به همین دلیل مدل را با استفاده از رویکرد RNN آموزش داد تا مدل بتواند متغیر و پویا بودن معانی کلمات را تشخیص دهد.
به همین منظور، ELMo برای هر کلمه، بر مبنای جملهای که در آن به کار رفته، یک بُردار در نظر میگیرد. در مدل ELMo (برخلاف تکنیک Word2Vec که یک جدول look-up به همراه یک کلمه و تعبیه دارد) کاربران میتوانند متن را به مدل بدهند و مدل بر مبنای جمله یک تعبیه ایجاد میکند. بنابراین، مدل میتواند بسته به بافت، معانی متفاوتی برای کلمه ایجاد کند.

نکته دیگری که باید به آن توجه داشته باشید این است که ELMo اولین مدلی بود که متن را به صورت غیرمتوالی پردازش میکرد. مدلهای قبلی، برای مثال Word2Vec، کلمات را تک تک میخواندند و هر کلمه را به صورت جداگانه پردازش میکردند. ELMo کوشید متن را همانند انسانها بخواند و متن را به دو روش پردازش میکرد:
- از اول به آخر: بخشی از معماری متن را به صورت معمول، یعنی از اول به آخر، میخواند.
- از آخر به اول: بخشی دیگری از معماری متن را از آخر به اول میخواند. برخی معتقد بودند اگر مدل «پیشاپیش» قسمتهای بعدی متن را بخواند، یادگیریاش افزایش مییابد.
- ترکیبی: پس از خواندن متن، هر دو تعبیه با یکدیگر ادغام میشدند تا معانی با یکدیگر «ترکیب شوند».
تلاش ELMo بر این بوده که متن را به صورت دو سویه بخواند. هرچند این رویکرد کاملاً دو سویه نیست ( ELMo بیشتر یک رویکرد یک جهته معکوس است) اما میتوان آن را رویکردی نسبتاً دو سویه دانست.
در یک بازه زمانی کوتاه شاهد پیشرفتهای بسیاری بودیم؛ برای مثال، برای تولید متن، معماریهای جدیدی از جمله RNN برای شبکههای عصبی معرفی شد و ELMo توانست با توجه به بافت تعبیهی کلمات را ایجاد کند. البته، در این رویکردها کماکان با یک مشکل اساسی مواجه هستیم و آن آموزش حجم بالایی از دادهها به مدل است. این مشکل، مانع از بهبود عملکرد مدلها در حل مسائل NLP میشود. و اینجاست که مفهوم پیش آموزش مدلها زمینه را برای ورود مدلهایی همچون مدل BERT و تسریع فرایند تکامل مدلها آماده کرد.
-
مدلهای از پیش آموزش داده شده
مدل BERT (و تمامی مدلهای مبتنی بر معماری Transformer) موفقیت خود را مرهون مدلهای از پیش آموزش داده شده هستند. در حوزه یادگیری عمیق، مدلهای از پیش آموزش داده شده مفهوم جدیدی نیستند و سالها از آنها برای تشخیص تصویر استفاده میشد.

ImageNet دیتاست بسیار بزرگی است که از تصاویر برچسبگذاری شده تشکیل شده است. سالها از این دیتاست برای آموزش مدلهای تشخیص تصویر استفاده میشد. این مدلها به کمک این دیتابیسهای بزرگ توانستند ویژگیهایی که در تشخیص تصویر اهمیت دارند را بیاموزند. برخی از این ویژگیها عبارتند از حاشیههای تصویر، لبهها، خطوط، اشکال و اشیای معمولی.
این مدلهای آموزش دیده و قابل تعمیم را میتوانید دانلود کنید و دیتاستهای کوچکتر خود را به آنها آموزش دهید. فرض کنید میخواهید مدلی برای تشخیص چهره کارکنان شرکتتان آموزش دهید. برای انجام این کار لازم نیست فرایند آموزش مدل را از اول شروع کنید و مبانی و اصول پایه تشخیص تصویر را به مدل آموزش دهید. فقط کافی است یکی از مدلهای قابل تعمیمی که آموزش دیدهاند را انتخاب کنید و آن را بر روی دادههایتان تنظیم کنید.
مشکل مدلهایی همچون Word2Vec این بود که در عین حال که دادههای زیادی به آنها آموزش داده میشد، قابل تعمیم نبودند. برای آموزش مدلهای Word2Vec دو راه بیشتر نداشتید: یا مدل Word2Vec را از ابتدا بر روی دادههایتان آموزش دهید و یا Word2Vec را به عنوان اولین لایه به شبکه عصبیتان اضافه کنید، پارامترها را مقداردهی کنید و سپس لایههای بیشتری به شبکهتان اضافه کنید و مدل را برای حل مسئلهای خاص آموزش دهید. به عبارت دیگر، میتوانید با استفاده از Word2Vec ورودیهایتان را پردازش کنید و مطابق با نیاز خود لایههایی برای مدل طراحی کنید و به کمک آن مسائلی همچون طبقهبندی احساسات، POS یا NER را حل کنید. مشکلی اینگونه مدلها این بود که هر کس به صورت جداگانه مدل خود را آموزش میداد و افراد کمی منابع لازم را (برای مثال داده و منابع محاسباتی) جهت آموزش مدلهای خیلی بزرگتر در اختیار داشتند.

همانگونه که در بخش 2 گفتیم، تا سال 2018، یعنی تا زمان روی کار آمدن مدلهایی همچون ELMo مجبور بودیم مدلها را به صورت جداگانه و برای انجام مسئلهای خاص آموزش دهیم. در این دوره، مدلهایی همچون ULMFit و اولین مدل مبتنی بر Transformer شرکت Open AI ، مدلهایی ایجاد کردند که از قبل آموزش دیده بودند.
سباستین رودر، پژوهشگر برجسته NLP، آن را دوران طلایی ImageNet میخواند. در این زمان پژوهشگران NLP توانستند با تکیه بر مدلهای از پیش آموزش داده شده، برنامههای NLP جدید و بسیار قدرتمندی بسازند. این پژوهشگران برای ساخت چنین برنامههایی به داده و منابع مالی کلان نیاز نداشتند و بالافاصله میتوانستند از این مدلها استفاده کنند.
دلایل اهمیت آن برای مدلهایی همچون مدل BERT را در دو مورد میتوانیم جستوجو کنیم:
- اندازه دیتاست: زبان نظامی پیچیده و نامنظم است و یادگیری آن برای کامپیوترها دشوارتر از تشخیص تصویر است. کامپیوترها برای تشخیص بهتر الگوهای زبانی و روابط میان کلمات و عبارات به دادههای بیشتری نیاز دارند. مدلهایی از جمله GPT-3 بر روی 45 ترابایت داده آموزش دیدهاند و از 45 میلیارد پارامتر تشکیل شدهاند و افراد و حتی سازمانهای کمی منابع لازم برای آموزش چنین مدلهای عظیمی را در اختیار دارند. اگر هر کسی مجبور بود به صورت جداگانه یک مدل مدل BERT برای خود آموزش دهد، سرعت پیشرفت کاهش پیدا میکرد و پژوهشگران نمیتوانستند توانایی و قابلیتهای این مدلها را ارتقا دهند. به عبارت دیگر، پیشرفت کُند و محدود به بازیگران بزرگی خواهد بود که البته تعدادشان کم است.
- تنظیم دقیق: مدلهایی که از قبل آموزش دیدهاند، دو مزیت دارند: اول اینکه میتوان به صورت آماده (off-the-shelf) یعنی بدون اعمال هیچگونه تغییری، از آنها استفاده کرد. برای مثال یک کسبوکار میتواند مدل BERT را در روال پردازشی خود به کار گیرد و در چت بات و یا هر برنامه دیگری از آن استفاده کند. دوم اینکه میتوان این مدلها را به صورت دقیق، و بدون نیاز به دادههای بیشتر و یا دستکاری مدل، برای حل مسئلهای خاص تنظیم کرد. برای مثال، با استفاده از چند هزار نمونه میتوانید مدل مدل BERT را به صورت دقیق بر روی دادههایتان تنظیم کنید. علاوه بر این، پیش آموزش، این امکان را برای مدلهایی همچون GPT-3 فراهم کرده تا بر روی دادههای زیادی آموزش ببینند و بتوان با استفاده از تکنیکهایی موسوم به یادگیری چند مرحلهای و یادگیری بدون نمونه آنها را آموزش داد. به عبارت دیگر، برای آموزش این مدلها کافی است تعداد کمی نمونه به آنها نشان دهیم تا آنها بتوانند یک مسئله جدید، برای مثال نوشتن یک برنامه کامپیوتری، را یاد بگیرند.
با روی کار آمدن مدلهای از پیش آموزش داده شده و پیشرفتهایی که در امر آموزش و معماریها حاصل شد (برای مثال ELMo جایگزین Word2Vec شد)، زمینه برای نقشآفرینی مدل BERT مهیا شد. در این برهه از زمان، نیاز به روشی که با استفاده از آن بتوانیم دادههای بیشتری را پردازش کنیم، بافت بیشتری یاد بگیریم و این دادهها را به صورت مدلی که از قبل آموزش دیده در اختیار دیگران قرار دهیم، احساس میشد.
-
معماری Transformer
امیدوارم پس از مطالعه این نوشتار، شناخت کاملی از معماری Transformer و نقش و اهمیت آن در مدلهای مدل BERT و GPT-3 به دست آورید. در این صورت میتوانید مدلهای مختلف Transformer را بررسی کنید؛ متوجه تغییراتی که در معماری ساده Transformer اعمال شده بشوید و مسائل و مشکلاتی که این مدلها درصدد حل آنها برآمدهاند را بررسی کنید. و در نهایت متوجه خواهید شد این معماری برای چه مسائل و حوزههایی مناسبتر است.
همانگونه که میدانید معماری Transformer برای اولین بار در مقالهای تحت عنوان «توجه، هر آنچه که بدان نیاز دارید» معرفی شد. نام این مقاله به خودی خود اهمیت دارد، زیرا تفاوت این رویکرد با رویکردهای قبلی را نشان میدهد. در بخش 2 گفتیم مدلهایی همچون ELMo برای پردازش متن به صورت متوالی از RNNها استفاده میکردند.

به این جمله ساده توجه کنید: “The cat ran away when the dog chased it down the street”. درک این جمله برای انسانها آسان است، اما اگر بخواهید آن را به صورت متوالی پردازش کنید به مشکل میخورید. برای مثال، چگونه میتوان مرجع واژه “it” را تشخیص داد؟ ممکن است مجبور شوید چندین حالت ذخیره کنید تا متوجه شوید شخصیت اصلی این جمله “cat” است. در گام بعدی باید مشخص کنید چه ارتباطی میان “it” و “cat” وجود دارد.
فرض کنید جملهای طولانیتر دارید و به این فکر کنید در زمان پردازش متون طولانی تر چگونه میتوانید اتفاقاتی که در جملات قبلی روی داده را به خاطر بسپارید و مرجع کلمات را در جملات پیدا کنید.
مدلهای ترتیبی این مشکل را دارند.
مدلهای ترتیبی بسیار محدود بودند. این مدلها فقط میتوانستند کلماتی که اخیراً پردازش کرده بودند را به خاطر بسپارند. مدلها ترتیبی همزمان با اینکه ادامه جمله را میخواندند، اهمیت و ربط کلمات قبلی را فراموش میکردند.
برای درک بهتر این موضوع به این مثال توجه کنید. فرض کنید فهرستی دارید و قصد دارید همزمان با پردازش کلمات جدید اطلاعاتی به آن اضافه کنید. هر چه تعداد کلماتی که پردازش میکنید بیشتر باشد، ارجاع دادن به کلماتی که در ابتدای فهرست ذکر شده بودند هم دشوارتر خواهد بود. در اصل، باید به عقب برگردید، یعنی تک تک کلمات را بخوانید تا زمانی که به اولین کلمات برسید و ببینید این کلمات با هم مرتبط هستند یا خیر.
آیا “it” به “cat” اشاره دارد؟ این مشکل با نام مشکل محوشدگی گرادیان شناخته میشود و ELMo با استفاده از شبکههای خاصی که LSTM نامیده میشوند سعی دارد مشکلات ناشی از این پدیده را کاهش دهد. LSTMها به این موضوع پرداختند، اما نتوانستند به طور کامل آن را برطرف کنند.
این شبکه ها نتوانستند راهی برای «تمرکز کردن» بر روی کلمات بااهمیت جمله بیایند. شبکه Transformer با استفاده از مکانیزمی موسوم به مکانیزم «توجه» این مشکل را رفع کرده است.

نویسندگان مقاله «توجه، هر آنچه که بدان نیاز دارید.» با استفاده از مکانیزم توجه عملکرد ترجمه ماشینی را ارتقاء دادند. آنها مدلی ساختند که از دو قسمت تشکیل میشد:
- انکدر: انکدر متن ورودی را پردازش میکند، قسمتهای مهم آن را جستوجو میکند و بر اساس میزان ارتباط هر کلمه با سایر کلمات تشکیلدهنده جمله، برای تک تک آنها یک تعبیه ایجاد میکند.
- دیکدر: دیکدر، خروجیِ انکدر که یک تعبیه است، دریافت میکند و مجدداً آن را به یک خروجی متنی تبدیل میکند؛ به بیان دیگر، نسخه ترجمهشده ورودی متنی را خروجی میدهد.
با این حال، اصلیترین بخش این مقاله انکدر و یا دیکدر نیست، بلکه لایههایی است که برای ساخت آنها استفاده شده است. انکدر و دیکدر برخلاف RNNهای سنتی از تکنیک حلقهزدن و یا بازگشتی (recurrence) استفاده نکردند. در عوض از لایههای «توجه» استفاده کردند؛ اطلاعات از این لایهها به صورت خطی عبور میکند. Transformer چندین بار بر روی ورودی حلقه نمیزند بلکه ورودی را از چندین لایه توجه عبور میدهد.
هر یک از لایههای توجه اطلاعات زیادی در مورد ورودی میآموزند؛ این لایهها به بخشهای مختلف جمله نگاه میکنند و تلاش میکنند اطلاعات معنایی و نحوی بیشتری یاد بگیرند. این فرایند در رفع مشکل محوشدگی گرادیان که پیشتر راجع به آن صحبت کردیم، اهمیت پیدا میکند.
هرچه طول جمله طولانیتر باشد، پردازش آن و فراگیری اطلاعات برای RNNها دشوارتر میشود. هر کلمه جدید برای شبکه به مثابه دادههای بیشتر (برای ذخیره) است و به همین دلیل بازیابی آنها برای درک بهتر بافت جمله دشوار خواهد بود.

شبکه Transformer با اضافه کردن لایهها و یا «شاخههای توجه» بیشتر این مشکل را رفع کند. با توجه به اینکه، در Transformer عملیات حلقه زدن انجام نمیشود، مشکل محوشدگی گرادیان به وجود نمیآید. Transformer کماکان در پردازش متون طولانیتر مشکل دارد اما مشکل این شبکه با RNN فرق دارد که توضیح آن از حوصله این نوشتار خارج است. اما اگر بخواهیم این مدلها را به یکدیگر مقایسه کنیم، باید بگوییم که بزرگترین مدل مدل BERT از 24 لایه توجه، GPT-2 از 12 لایه توجه و GPT-3 از 96 لایه توجه تشکیل شده است.
در این نوشتار، از توضیح کارکرد مکانیزم توجه صرف نظر میکنیم و در مقاله دیگری به آن خواهیم پرداخت. در ضمن، میتوانید مطالبی که لینک آنها را در زیر نمودارهای فوق قرار دادیم مطالعه کنید، این مطالب حول موضوع توجه و کارکرد آن هستند. نکتهای که باید به آن توجه داشته باشید این است که معماری Transformer با تکیه بر مکانیزم توجه میتواند بسیاری از مشکلاتی که در هنگام استفاده از RNNها برای حل مسائل NLP با آنها مواجه میشویم را برطرف کند. اگر به یاد داشته باشید گفتیم که یکی از محدودیتهای RNNها، توانایی پردازش متون به صورت متوالی بود. Transformer با استفاده از مکانیزم توجه این امکان را برای مدلها فراهم میکند تا متون را به صورت غیر متوالی و به صورت دو سویه (از اول به آخر، از آخر به اول) پردازش کنند.
5. اهمیت پردازش دو سویه
پیش از معرفی Transformer از معماری RNNها برای پردازش متون استفاده میشد. RNNها برای پردازش ورودیهای متنی، از متد حلقه زدن یا recurrence استفاده میکنند. پردازش متن به شیوه RNNها دو مشکل دارد:
- کُند بودن فرایند پردازش: پردازش متون به صورت متوالی و در یک جهت (اول به آخر یا آخر به اول)، به دلیل ایجاد گلوگاه (bottleneck) هزینهبر است. این فرایند را میتوان به جادهای تک بانده در اوج ساعات تردد تشبیه کرد که ترافیک سنگینی را به وجود آورده است. به طور کلی، اگر دادههای بیشتری به این مدلها آموزش داده شود، عملکرد بهتری خواهند داشت. بنابراین، اگر به دنبال مدلهای با عملکرد بهتر باشیم، این گلوگاهها نقطه ضعفی اساسی در آنها به حساب میآیند.
- حذف اطلاعات کلیدی: انسانها به صورت متوالی متن را نمیخوانند. دانیال ویلینگهام روانشناس در کتاب خود تحت عنوان «ذهنخوانی» میگوید: «ما انسانها کلمه را حرف به حرف نمیخوانیم، بلکه آن را به صورت انبوهی از حروف میخوانیم و چندین حرف را با هم و به صورت همزمان تشخیص میدهیم». به این دلیل که ما برای درک متنی که در حال خواندن آن هستیم، باید راجع به کلمات و عبارات بعدی هم اطلاعاتی داشته باشیم. مدلهای زبانی NLP به همین شیوه عمل میکنند. پردازش متن در یک جهت توانایی آنها برای یادگیری از دادهها را محدود میکند.

ELMo سعی کرد با استفاده از متدی «نسبتاً» دو سویه ، این مشکل را برطرف کند. ELMo متن را در یک جهت پردازش میکرد و سپس آن را برعکس میکرد؛ به عبارت دیگر، یک بار هم متن را از آخر به اول پردازش میکرد. سپس این دو تعبیه را با هم ادغام میکرد و سعی میکرد معانی متفاوت کلمات تشکیلدهنده جمله را تشخیص دهد:
- The mouse was on the table near the laptop
- The mouse was on the table near the cat
واژه “mouse” در هر دو جمله، بسته به اینکه در جمله “laptop” استفاده شده یا “cat” به دو موجودیت کاملاً متفاوت اشاره دارد. ELMo جمله را بر عکس میکند و از واژه “cat” شروع میکند و تلاش میکند بافت را یاد بگیرد و معانی مختلف واژه “mouse” را رمزگذاری کند. ELMo ابتدا “cat” را پردازش میکند و در نتیجه میتواند معانی مختلف واژه را در تعبیه «برعکس» بگنجاند. اینگونه ELMo توانست تعبیههای بهتری نسبت به Word2Vec ایجاد کند؛ Word2Vec تعبیههایی ایستا و سنتی ایجاد میکرد که برای هر کلمه یک معنی رمزگذاری میکردند.
بدون نیاز به بررسی دقیق این فرایند هم متوجه میشویم که ELMo رویکرد ایدهآلی نیست.
ترجیح ما بر این است که از مکانیزمی استفاده کنیم که مدل با تکیه بر آن بتواند در طول فرایند کدگذاری به سایر کلمات حاضر در جمله نیز نگاه کند. این دقیقاً همان کاری است که مکانیزم توجهِ معماری Transformer انجام میدهد.

مدلهای Transformer از جمله مدل BERT میتوانند متن را به صورت دو سویه بخوانند و به همین دلیل در انجام مسائل NLP به نتایج خارقالعادهای دست پیدا کنند. همانگونه که در مثال فوق مشاهده میکنید، اگر متن را از یک جهت بخوانیم، تشخیص مرجع “it” دشوار خواهد بود و لازم است تمامی حالتها را به صورت متوالی ذخیره کنیم.
و اصلاً جای تعجب ندارد که دو سویه بودن یکی از ویژگیهای کلیدیِ مدل مدل BERT است و حرف B در نام این مدل معادل واژه Bidirectional (دو سویه) بودن است. مکانیزم توجه معماری Transformer به چندین روش مدلهایی همچون مدل BERT را قادر میسازد متن را به صورت دو سویه پردازش کنند:
- امکان پردازش موازی: مدلهای مبتنی بر Transformer میتوانند متن را به صورت موازی پردازش کنند، به همین دلیل همانند مدلهای مبتنی بر RNN مجبور نیستند حتماً متن را به صورت متوالی پردازش کنند. به بیان دیگر، هر بار که مدل به کلمهای در جمله نگاه میکند، آن را پردازش میکند. اما در این حالت نیز با چالشهای دیگری مواجه میشویم. اگر کُل متن را به صورت موازی پردازش کنید، چگونه ترتیب قرارگیری جملات در متن اصلی را تشخیص میدهید؟ ترتیب قرارگیری کلمات در جمله مسئله مهمی است. اگر ترتیب قرارگیری کلمات را ندانیم، مدلی از کلمات خواهیم داشت که نمیتواند معنا و بافت را از جمله استخراج کند.
- ثبت موقعیت ورودی: برای رفع مشکل مربوط به ترتیب قرارگیری کلمات، معماری Transformer موقعیت کلمات را مستقیماً در تعبیه کدگذاری میکند. موقعیتهای کدگذاری شده برای لایههای توجه مدل نقش نشانه را ایفا میکنند و آنها را قادر میسازند جای کلمه یا توالی متنی که به آن نگاه میکنند را تشخیص دهد. این ترفند کوچک به این معناست که مدلها میتوانند توالیهای متنی با حجم و طول متفاوت را به صورت موازی پردازش کنند و در عین حال ترتیب قرارگیری آنها را در جمله تشخیص دهند.
- جستوجوی آسانتر: اگر به خاطر داشته باشید گفتیم یکی از مشکلات اساسی مدلهای مبتنی بر RNN این است که اگر لازم باشد متنها را به صورت متوالی پردازش کنند، در بازیابی کلمات اولیه به مشکل میخورند. بنابراین در مثال “mouse”، RNN باید ربط آخرین کلماتی که در جمله قرار دارند، یعنی “laptop” و “cat” و اینکه چطور به بخش اول جمله ارتباط پیدا میکنند را بداند. برای انجام این کار، مدل باید از کلمه N-1 به کلمه N-2 و N-3 و الیآخر برود تا زمانی که به ابتدای جمله برسد. در این صورت جستوجو دشوار خواهد بود و به همین دلیل یادگیری بافت برای مدلهای تک سویه دشوار است. در مقابل، مدلهای مبتنی بر Transformer به سادگی میتوانند هر کلمهای را در جمله جستوجو کنند. در این حالت، مدل از تمامی کلمات به کار رفته در توالی و لایههای توجه «ذهنیتی» دارد. به همین دلیل در زمان پردازش بخشهای اولیه جمله میتواند «جلوتر» و تا پایان جمله را ببیند و بالعکس (البته در اینجا نحوه پیادهسازی لایههای توجه نیز اهمیت دارد؛ به عبارت دیگر، انکودرها میتوانند موقعیت و محل قرارگیری هر یک از کلمات را نگاه کنند، در مقابل دیکودرها فقط میتوانند به «عقب» و به کلماتی که پردازش کردهاند، توجه کنند.)
تمامی این عوامل در کنار یکدیگر مدل را قادر میسازند متن را به صورت موازی پردازش کند، موقعیت ورودی را در تعبیه تثبیت کند و ورودیها را به آسانی جستوجو کند. مدلهایی از قبیل مدل BERT میتوانند متن را به صورت دو سویه «بخوانند».
در واقع این مدل دو سویه نیست، زیرا این مدلها به صورت یکجا به متن نگاه میکنند و به همین دلیل، بی جهت است. اما برای ارتقای عملکرد مدل و برای اینکه اطلاعات بیشتری از ورودیها بیاموزد، فرض را بر این میگذاریم که مدل متن را به صورت دوسویه پردازش میکند.
توانایی پردازش دو سویه متن مشکلاتی را پیشروی مدل مدل BERT قرار میدهد و این مدل تلاش میکند با استفاده از تکنیکی به نام «ماسکگذاری» این مشکلات را رفع کند. در بخش 8 به معرفی تکنیک «ماسکگذاری» خواهیم پرداخت. اکنون که شناخت کافی از معماری Transformer به دست آوردهایم میتوانیم تفاوتهایی که میان مدل BERT و معماری Transformer ساده وجود دارد را تشخیص دهیم.
-
چه تفاوتی میان مدل مدل BERT و Transformer وجود دارد؟
جدیدترین مدلها اغلب با نام مدلهای «ترنسفورمر» شناخته میشوند. گاهی اوقات مدلهای مدل BERT و GPT-3 را به اشتباه مدل «ترنسفورمر» مینامند. اما این دو مدل از جهات گوناگونی با مدلهای «ترنسفورمر» تفاوت دارند.

آگاهی از این تفاوتها به شما کمک میکند متناسب با هدفتان، بهترین مدل را انتخاب کنید. کلید شناخت مدلهای مختلف این است که ببینید این مدلها چرا و چگونه با معماری اصلی ترنسفورمر تفاوت دارند. به طور کلی، در انتخاب مدل باید به این نکات توجه کنید:
- آیا این مدل از انکودر دارد؟ در معماری اصلی ترنسفورمر برای ترجمه متون به دو روش مختلف از مکانیزم توجه استفاده میشود. در روش اول زبان مبدأ رمزگذاری میشود و در روش دوم تعبیهای که رمزگذاری شده به زبان مقصد رمزگشایی میشود. نکتهای که در هنگام استفاده از مدلهای جدید باید به آن توجه کنید این است که آیا این مدل انکودر دارد یا نه. به بیان دیگر، این معماری تلاش میکند با استفاده از خروجی مسئله دیگری را حل کند. برای مثال با استفاده از خروجی لایههای دیگر یک کلاسیفایر را آموزش میدهد و یا کارهایی از این دست انجام میدهد.
- آیا این مدل دیکودر دارد؟ استفاده از دیکودر در مدل کاملاً اختیاری است؛ به عبارت دیگر در طراحی مدل میتوانیم فقط از انکودر استفاده کنیم. دیکودر، مکانیزم توجه را با کمی تفاوت از انکودر پیادهسازی میکند. کارکرد دیکودر بیشتر شبیه به یک مدل زبانی سنتی است و در زمان پردازش متن فقط به کلمات قبلی نگاه میکند. البته این روش در انجام مسائلی همچون تولید زبان بسیار مناسب است و به همین دلیل مدلهای GPT-3 از دیکودر استفاده میکنند، چراکه ورودی این مدلها عمدتاً یک توالی متنی و خروجیشان متنی تولیدشده است.
- چه لایههای آموزشی جدیدی به این مدل اضافه شده است؟ و در آخر، آیا برای آموزش لایههای جدیدی به مدل اضافه شده است (چه لایههایی؟) یا خیر. همانگونه که پیش از این نیز گفتیم، مکانیزم توجه میتواند متن را به صورت موازی و به صورت دو سویه پردازش کند و به همین دلیل توانمندیها و قابلیتهای بیشماری دارد. بر همین مبنا میتوان لایههای زیادی ایجاد کرد و مدل را برای حل مسائل مختلف از جمله پرسش و پاسخ و خلاصهسازی متن آموزش داد.

مدل مدل BERT چه تفاوتی با معماری ساده ترنسفورمر دارد؟
- مدل مدل BERT از انکودر استفاده میکند: هدف مدل مدل BERT ساخت مدلهایی است که بتوانند مسائل NLP را حل کنند و به همین دلیل است که از دیکودر معماری ترنسفورمر استفاده میکند. مدل مدل BERT با استفاده از انکودر اطلاعات نحوی و معناییِ تعبیه را – که برای انجام تعداد زیادی از مسائل لازم و ضروری هستند- رمزگذاری میکند. بنابراین هدف از طراحی مدل مدل BERT انجام مسائلی همچون تولید متن و ترجمه نبوده است، زیرا این مدل از انکودر استفاده میکند. علاوه بر این، در عین حال که مدل BERT یک مدل ترجمه ماشینی نیست میتوانیم چندین زبان مختلف را به آن آموزش دهیم. با توجه به اینکه این مدل قادر به پیشبینی کلمات است، میتوانیم از آن به عنوان یک مدل تولید متن استفاده کنیم. اما توجه داشته باشید که این مدل برای انجام مسائلی همچون تولید متن بهینهسازی نمیشود.
- مدل BERT از دیکودر استفاده نمیکند: همانگونه که پیش از این نیز گفتیم، مدل BERT از دیکودرِ معماری ساده ترنسفورمر استفاده نمیکند. لذا، خروجی مدل BERT یک تعبیه است نه متن؛ به عبارت دیگر، مهم نیست که از مدل BERT برای حل چه مسئلهای استفاده میکنید، مهم این است که در نهایت باید عملیاتی بر روی تعبیه انجام دهید. برای مثال میتوانید به کمک تکنیکهایی از جمله شباهت کسینوسی، تعبیهها را با یکدیگر مقایسه کنید و میزان شباهت آنها را مشخص کنید. در مقابل، اگر مدل مدل BERT دیکودر داشت، یک متن خروجی میداد و شما میتوانستید مستقیماً و بدون انجام عملیاتهای اضافی بر روی خروجی، از آن استفاده کنید.
- مدل BERT از یک لایه آموزشی جدید استفاده میکند: مدل مدل BERT خروجی انکودر را دریافت میکند و آن را به همراه لایههای آموزشی، که دو تکنیک خلاقانه ماسکگذاری و پیشبینی جمله بعدی (NSP) را انجام میدهند، استفاده میکند. لایههای آموزشی با تکیه بر این تکنیکها، اطلاعات نهفته در تعبیههای مدل BERT را مشخص میکنند تا مدل اطلاعات بیشتری از خروجی به دست آورد. در بخش 8 به طور مفصل به معرفی این دو تکنیک خواهیم پرداخت. مدل مدل BERT با استفاده از انکودرِ ترنسفورمر کلمات نهفته و ماسکگذاری شده را پیشبینی میکند و بدین ترتیب مدل را وادار میکند اطلاعات بیشتری راجع به متن «یاد بگیرد» و کلمات نهفته و ماسکگذاری شده را پیشبینی کند. در تکنیک دوم (یعنی ماسکگذاری)، مدل با استفاده از انکودر و با توجه به جمله قبلی، جمله بعدی را پیشبینی میکند. مدل مدل BERT برای بهرهمندی از مزایای ترنسفورمر، به ویژه مکانیزم توجه از این دو تکنیک استفاده میکند و مدلی ایجاد میکند که در انجام بسیاری از مسائل NLP به نتایجی همانند مدلهای SOTA دست پیدا میکند.
اکنون که متوجه تفاوتهای مدل مدل BERT با معماری ساده ترنسفورمر شدهایم میتوانیم بخشهای مختلف مدل BERT را با دقت بیشتری بررسی کنیم. اما پیش از هر چیز باید ببینیم مدل BERT چگونه متن را میخواند.
-
توکنسازها: مدل BERT چگونه متون را میخواند
زمانی که صحبت از مدلهایی همچون مدل BERT به میان میآید، اغلب از یک نکته مهم غافل میمانیم: این مدلها چگونه ورودی را «میخوانند» تا از حجم بالای متونی که به آنها آموزش داده میشود چیزهایی بیاموزند؟
شاید فرایند خواندن ورودی در ظاهر ساده باشد: مدل تک تک کلمات را پردازش میکند، کلمات را به وسیله فاصلههایی که میان آنها قرار دارد تشخیص میدهد و سپس آنها را به لایههای توجه منتقل میکند تا عملیاتهای مورد نظر بر روی آنها انجام شود.

با این وجود، اگر بخواهیم متن ورودی را بر مبنای کلمات و یا تکنیکهای ساده دیگر دیگر (برای مثال، علامتگذاری) توکنسازی کنیم، با مشکلاتی مواجه میشویم. برخی از آنها عبارتند از:
- در برخی زبانها برای تفکیک کلمات از فاصله استفاده نمیشود: استفاده از رویکردهایی که در سطح کلمه هستند به این معنا است که مدل در زبانهایی همچون زبان چینی کاربرد نخواد داشت؛ در این زبانها تفکیک کلمات از یکدیگر کار آسانی نیست.
- به دایره لغات بالایی نیاز دارید: اگر بخواهیم تمام ورودیها را به کلمات تجزیه کنیم، باید به ازای هر کلمهی احتمالی یک تعبیه جداگانه داشته باشیم. در این صورت تعداد بیشماری تعبیه خواهیم داشت. علاوه بر این، چگونه میتوانیم مطمئن شویم که تک تک کلمات موجود در دیتاست آموزشی را دیدهایم؟ اگر تمامی کلمات موجود در دیتاست آموزشی را نبینیم، مدل نمیتواند کلمات جدید را پردازش کند. این مشکل در مدلهای قبلی رخ میداد؛ این مدلها برای تشخیص کلمات جدید و ناشناخته، به توکن <UNK> وابسته بودند.
- هر چه دایره لغات گستردهتر باشد، مدل کُندتر میشود: توجه داشته باشید که هدف ما از پردازش دادههای بیشتر این است که مدل اطلاعات بیشتری راجع به زبان کسب کند و در حل مسائل NLP موفقتر عمل کند. یکی از مزیتهای اصلی ترنسفورمر نیز همین است؛ به کمک این مدل میتوانیم متون بیشتری (نسبت به مدلهای قبلی) پردازش کنیم و بدین ترتیب میتوانیم عملکرد آنها را ارتقاء دهیم. با این وجود ، اگر از توکنهایی که در سطح کلمه هستند استفاده کنیم، به دایره لغات گستردهتری نیاز خواهیم داشت. دایره لغات گستردهتر به معنای افزایش اندازه مدل است و در نتیجه تعداد متون کمتری برای آموزش آن میتوانیم استفاده کنیم.

HuggingFace یک کتابخانه توکنساز فوقالعاده دارد. این وبسایت مطالب آموزشی بسیار خوبی راجع به رویکردهای مختلف فراهم آورده است. برای مثال، در یکی از این مطالب آموزشی چگونگی ساخت کلمات پایه بر مبنای بسامد کلمات تشکیلدهنده دیتاست آموزشی را توضیح میدهد و در یکی دیگر از این مطالب نشان میدهد که چگونه واژه “hug” به صورت “hug” توکنسازی میشود اما واژه “pug” به دو زیرکلمه “p” و “ug” توکنسازی میشود.
مدل مدل BERT چگونه این مشکل را رفع میکند؟ مدل مدل BERT برای رفع این مشکل رویکرد جدیدی برای توکنسازی اتخاذ میکند؛ این روش WordPiece نام دارد و در فرایند توکنسازی رویکردی در سطح زیرکلمه اعمال میکند. WordPiece با تکیه بر روشهای زیر، بسیاری از مشکلات مربوط به توکنسازی را حل کرده است:
- استفاده از زیرکلمات به جای کلمه: WordPiece به جای نگاه کردن به کُل کلمه، کلمه را به بخشهای کوچکتر و یا اجزای سازنده تقسیم میکند و با استفاده از آنها کلمات جدیدی میسازد. برای مثال، واژه “Learning” را در نظر بگیرید. میتوانیم این واژه را به سه بخش “lea”، “rn” و “ing” تقسیم کنیم. با استفاده از این زیرکلمات میتوانیم طیف وسیعی از کلمات بسازیم:
- Learning = lea + rn + ing
- Learn = lea +rn
و یا میتوانید آنها را با زیرکلمات دیگر ترکیب کنید و کلمات جدید بسازید:
- Burn = bu + rn
- Churn = Chu + rn
- Turning = tur + rrn + ing
- Turns = tu + rn + s
برای لغات و واژگان متداولتر میتوانید کلمهی کامل و برای کلماتی که بسامد کمتری دارند میتوانید زیرکلمه ایجاد کنید. در این حالت، به کمک اجزای سازنده کلماتی که تجزیه کردهاید میتوانید هر کلمهای را توکنسازی کنید. در صورت مواجهه با یک کلمه کاملاً جدید نویسههای آن را در کنار یکدیگر قرار دهید، برای مثال، LOL = l + o + l، زیرا کتابخانه توکنهای زیرکلمه، شامل نویسهها هم میشود. حتی اگر تا به حال کلمهای را ندیده باشید هم میتوانید آن را بسازید. برای ساخت این کلمات فقط به تعدادی زیرکلمه نیاز دارید و در صورت لزوم باید چندین نویسه به آنها اضافه کنید.
- ایجاد دایره لغات کوچک: با توجه به اینکه لازم نیست برای هر کلمه یک توکن جداگانه داشته باشیم، دایره لغات نسبتاً کوچکی داریم. برای مثال، در کتابخانه مدل BERT، در حدود 30000 توکن وجود دارد. این تعداد توکن ممکن است زیاد به نظر برسد اما این عدد در مقایسه با تمامی کلماتی که تاکنون ابداع و استفاده شدهاند، بسیار کوچک است. به همین منظور، به دایره لغاتی با میلیونهای توکن نیاز دارید و با این حال هنوز هم نمیتوانید تمامی کلمات و لغات را پوشش دهید. مدل BERT این کار را فقط با 30000 توکن انجام میدهد! به عبارت دیگر، برای داشتن مدلی با اندازه کوچک و آموزش آن بر روی حجم بالایی از دادهها لازم نیست از توکن <UNK> استفاده کنیم.
- این رویکرد کماکمان فاصله را مبنای تفکیک کلمات قرار میدهد اما … در رویکرد WordPiece نیز فرض بر این است که کلمات به وسیله فاصلهها از یکدیگر جدا میشوند. SentencePiece و Multilingual Universal Sentence Encoder (MUSE) دو کتابخانه جدید شامل توکن زیرکلمات هستند؛ این دو کتابخانه نسخههای ارتقایافتهی رویکرد WordPiece هستند و به صورت متدوال در مدلهای جدید استفاده میشوند.
-
ماسکگذاری: عمل زیرکانه در مقابل سختکوشی
همانگونه که در بخش 6 گفتیم، هدف ما از نگارش مقاله پیشرو، بررسی مدلهای مبتنی بر معماری ترنسفورمر بوده است. بنابراین شاید جالب باشد که ببینیم شیوه آموزش این مدلها چه تفاوتی با یکدیگر دارد. رویکرد و فرایند آموزش مدل مدل BERT بسیار خلاقانه است. معماری مدلهای ترنسفورمر به اندازهای پیشرفته است که میتوانید به شیوه مدلهای زبانی سنتی آنها را آموزش دهید و به نتایج خارقالعادهای دست پیدا کنید.

در این حالت میتوانید توکنهای بعدی را با توجه به توکنهای قبلی پیشبینی کنید. RNNهای قبلی برای آموزش مدلهای خود از تکنیکهای اتورگرسیو استفاده میکردند. مدلهای GPT نیز برای آموزش مدلهای خود از تکنیکهای اتورگرسیو استفاده میکنند. اما معماری ترنسفورمر برای آموزش مدلهای خود رویکرد متفاوتی اتخاذ کرده است ( همانگونه که پیش از این گفتیم، این معماری از دیکودر استفاده میکند)؛ از این روی، نسبت به قبل دادههای بیشتری را میتوان به مدلهای مبتنی بر ترنسفورمر آموزش داد. این مدلها با تکیه بر مکانیزم توجه بهتر میتوانند بافت را فرا بگیرند و علاوه بر این میتوانند ورودی را به صورت دوسویه پردازش کنند.

مدل BERT برای اینکه مدل را «وادار» کند اطلاعات بیشتری از دادهها بیاموزد، از تکنیکی خلاقانه استفاده میکند. این تکنیک جنبههای جالبی از تعامل مدلهای DL با تکنیکهای آموزشی آشکار میکند:
- چرا به تکنیک ماسکگذاری نیاز داریم؟ همانگونه که پیش از این گفتیم، مدل با تکیه بر معماری ترنسفورمر میتواند متن را به صورت دوسویه پردازش کند. در اصل، مدل همزمان میتواند تمامی کلمات تشکیلدهنده توالی ورودی را ببیند. اما مدلهای RNN فقط کلمات فعلی ورودی را میدیدند و نمیدانستند کلمه بعدی چیست. به آسانی میتوانستیم این مدلها را مجبور به پیشبینی کلمه بعدی کنیم؛ به عبارت دیگر، این مدلها کلمه بعدی را نمیدانستند و مجبور بودند تلاش کنند و آن را پیشبینی کنند و چیزهایی از آن بیاموزند. اما مدل مدل BERT ، که مبتنی بر ترنسفورمر است، میتواند «تقلب کند» و به کلمه بعدی نگاه کند و طبیعتاً چیزی یاد نمیگیرد. کارکرد مدل مدل BERT شبیه به این است که از دانشآموزان امتحان بگیریم و جواب سؤالات را در اختیار آنها قرار دهیم؛ اگر بدانید معلمتان جواب سؤالات را به شما میدهد، مطمئنا دیگر مطالعه نمیکنید. مدل BERT برای حل این مشکل از تکنیک ماسکگذاری استفاده میکند.
- منظور از ماسکگذاری چیست؟ در تکنیک ماسکگذاری ( که با نام Cloze test -پر کردن جای خالی- نیز شناخته میشود) به جای پیشبینی کلمه بعدی، کلمه را پنهان و یا «ماسکگذاری» میکنیم و از مدل میخواهیم آن را پیشبینی کند. در مدل مدل BERT (قبل از اینکه ورودی به مدل نمایش داده شود) 15 درصد از توکنهای ورودی ماسکگذاری میشوند ، در نتیجه هیچ راهی برای تقلب کردن وجود ندارد. در این تکنیک، کلمهای به صورت تصادفی انتخاب میشود و با توکن “[MASK]” جایگزین میشود و سپس به مدل داده میشود.
- نیازی به استفاده از برچسب نیست: نکته مهم دیگری که باید به یاد داشته باشید این است که تکنیکهای آموزشی جدید را به گونهای طراحی کنید که نیازی به برچسب و یا ساخت دستی دادههای آموزشی نباشد. تکنیک ماسکگذاری برای حل این مشکل رویکردی ساده در پیش گرفته و بر روی حجم فوقالعاده بالایی از دادههای ساختارنیافته آموزش میبیند. به عبارت دیگر، میتوان این تکنیک را به روش کاملاً غیرنظارت شده آموزش داد.
- 80 درصد از 15 درصد: شاید ماسکگذاری به ظاهر تکنیک سادهای باشد اما با دیگر تکنیکها تفاوتهایی جزئی دارد. از 15 درصد توکنی که برای ماسکگذاری انتخاب میشود، 80 درصدشان با توکن ماسک جایگزین میشوند. 10 درصد از آنها با کلمات تصادفی و 10 درصد باقیمانده با کلمه درست جایگزین میشوند.
- چرا تکنیک ماسکگذاری محبوب است؟ چرا به جای 15 درصد از ورودیها، تمامی آنها (100 درصد) را ماسکگذاری نکنیم؟ سؤال خوبی است. زیرا اگر تمامی ورودیها را ماسکگذاری کنید، مدل میداند که فقط باید کلمات ماسکگذاری شده را پیشبینی کند و بدین ترتیب چیزی در مورد سایر کلمات ورودی یاد نمیگیرد و این اصلا خوب نیست. مدل باید بتواند در مورد کُل ورودی چیزهایی بیاموزد ( نه فقط 15 درصد از ورودها که ماسکگذاری شدهاند). برای اینکه مدل را مجبور کنیم بافت کلماتی که ماسکگذاری نشدهاند را یاد بگیرد، باید برخی از توکنها را با کلمات تصادفی و تعدادی از آنها را با کلمات صحیح جایگزین کنیم. در این حالت، مدل BERT هیچ وقت نمیداند کلمهای که ماسکگذاری شده و از او خواسته شده آن را پیشبینی کند، کلمه صحیح است یا خیر. در عوض، اگر 90 درصد مواقع از توکن ماسک و 10 درصد مواقع از کلمه اشتباه استفاده میکردیم، مدل BERT در زمان پیشبینی کلمه میدانست توکنی که ماسکگذاری نشده، همیشه کلمه اشتباه است. به همین ترتیب، اگر 10 درصد مواقع از کلمه صحیح استفاده میکردیم، مدل BERT میدانست این کلمه همیشه صحیح است، لذا به صورت مداوم از تعبیه ثابت کلمهای که از آن چیزهایی آموخته استفاده میکرد. در چنین شرایطی، هرگز تعبیه مربوط به بافت آن کلمه را یاد نمیگیرد.
-
تنظیم دقیق و یادگیری انتقال
مدل مدل BERT چند سال پیش منتشر شد و به طور کلی برای حل مسائل رویکردهای مختلفی در پیش میگرفت. یکی از تفاوتهای مدل BERT با مدلهای پیش از خود این است که میتوانیم آن را برای حل مسئلهای خاص به صورت دقیق تنظیم کنیم. این قابلیت به لطف بسیاری از مواردی که در بخشهای قبل راجع به آنها گفتوگو کردیم، محقق میشود. برای مثال، مدل BERT مدلی است که از قبل آموزش داده شده است به همین دلیل افرادی که میخواهند از آن استفاده کنند لازم نیست آن را از اول و با دیتاستهای بزرگ آموزش دهند. به عبارت دیگر، میتوانیم از مدلهایی که بر روی دیتاستهای بزرگتر آموزش دیدهاند، استفاده کنیم و برای حل یک مسئله خاص دانش آنها را به مدل خود «منتقل کنیم».

مدل مدل BERT مدلی است که از قبل آموزش دیده است و به همین دلیل میتوانیم آن را برای حل مسائل مختلف به صورت دقیق تنظیم کنیم، زیرا:
- مدل مدل BERT میتواند تکنیک یادگیری انتقال را اجرا کند: یادگیری انتقال تکنیک قدرتمندی است که در ابتدا در بینایی ماشین اجرا میشد. مدلهایی که بر روی ImageNet آموزش میدیدند، برای حل مسائل “downstream” استفاده میشدند؛ در این گونه مسائل مدل بر دانش مدلهایی که بر روی دادههای بیشتری آموزش دیده بودند تکیه داشت. به عبارت دیگر، مدلهایی که از قبل آموزش دیدهاند میتوانند دانشی را که در نتیجه آموزش بر روی دیتاستهای بزرگتر کسب کردهاند به مدلهای دیگر «منتقل» کنند؛ بنابراین، مدل جدید برای حل یک مسئله خاص به دادههای کمتری نیاز خواهد داشت. در بینایی ماشین، مدلهایی که از قبل آموزش دیدهاند میتوانند ویژگیهای مختلف تصویر را ، از جمله خطوط، لبهها، طرح چهره، اشیای موجود در تصویر و غیره، تشخیص دهند. این مدلها ریزجزئیات تصویر، برای مثال تفاوتهایی که میان چهره افراد وجود دارد، را نمیدانند. در چنین شرایطی به راحتی میتوان یک مدل کوچک آموزش داد تا با تکیه بر این دانش مسائل را حل کند و چهرهها و اشیایی که مرتبط به مسئله خود هستند را تشخیص دهد. برای مثال، برای تشخیص گیاهان بیمار لازم نیست مدلی را از اول آموزش دهید.
- میتوانید لایههای مرتبط با مسئله را انتخاب کنید و به صورت دقیق تنظیم کنید: هرچند پژوهشهایی در این زمینه در حال انجام است، اما به نظر میرسد لایههای فوقانی مدلهای مدل BERT دانش بیشتری راجع به بافت و معنا میآموزند، در حالیکه لایههای پایینی در انجام مسائل مرتبط با نحو عملکرد بهتری دارند. به طور کلی، لایههای فوقانی بیشتر به دانش خاص مسئله میپردازند. برای تنظیم دقیق، میتوانید لایهای به بالای مدل مدل BERT اضافه کنید و برای حل مسئلهای خاص، برای مثال، طبقهبندی، آن را بر روی حجم کمی از دادهها آموزش دهید. در چنین شرایطی، باید پارامترهای لایه بعدی را منجمد (freeze) کنید تا فقط پارامترهای لایهای که اضافه کردهاید امکان تغییر داشته باشند یا میتوانید لایههای فوقانی را منجمد کنید و با تغییر مقادیر، مدل BERT را به صورت دقیق تنظیم کنید.
- مدل BERT به دادههای کمتری نیاز دارد: با توجه به اینکه مدل مدل BERT دانشی کلی در مورد زبان دارد، برای تنظیم دقیق آن به دادههای کمتری نیاز است. به بیان دیگر، میتوانید با استفاده از دادههایی که برچسب ندارند کلاسیفایری آموزش دهید، اما به دادههای کمتری نیاز دارید، و یا میتوانید با استفاده از دادههای برچسبدار کلاسیفایر را آموزش دهید که در این حالت باید دادههای کمتری را برچسبگذاری کنید و یا میتوانید با استفاده از تکنیک اصلی آموزش مدل BERT، از جمله NSP، مدل را بر روی دادههایی که برچسب ندارند آموزش دهید. اگر 3000 جفت جمله داشته باشید، میتوانید مدل BERT را با دادههایی که برچسبگذاری نشدهاند، به صورت دقیق تنظیم کنید.
تمامی اینها به این معنا است که مدل BERT و بسیاری از مدلهای ترنسفورمر را میتوانیم به آسانی برای حوزه کاری خود به صورت دقیق تنظیم کنیم. با این حال، فرایند تنظیم دقیق محدودیتهایی دارد و بسیاری از مدلها مدل BERT را برای برخی از حوزهها، برای مثال، بازیابی اطلاعات مربوط به کووید 19، از ابتدا آموزش میدهند. در هر حال، اینکه میتوانیم این مدلها را به شیوه غیرنظارت شده بر روی حجم کمی از دادهها آموزش داده تحولی بزرگ در طراحی این مدلها محسوب میشود.
10. صندلیهای آواکادو: چه تغییراتی در انتظار مدل BERT و معماری ترنسفورمر است

در آخرین بخش از این نوشتار، به بررسی تغییر و تحولاتی میپردازیم که در انتظار مدل BERT، معماری ترنسفورمر و به طور کلی یادگیری عمیق است:
- سوالاتی پیرامون محدودیتهای مدلها: سؤالهای جالب و در عین حال فیلسوفانهای پیرامون محدودیتهای بالقوهی استخراج معنا از متن در جریان است. در مقالاتی که به تازگی منتشر شده نویسندگان ایدههای جدیدی راجع به آموختههای مدلهای DL از زبان ارائه دادهاند. آیا بازدهی این مدلها همزمان با آموزش بر روی دادههای بیشتر و بیشتر کاهش مییابد؟ اینها سؤالات جالبی هستند که ممکن است ذهن هر کسی را به خود مشغول کنند و پاسخ آنها را باید در خارج از حوزه NLP و حوزهای گستردهتر یعنی هوش مصنوعی عام جستوجو کرد.
- تفسیرپذیری مدلها: معمولاً ما انسان شروع به استفاده از یک فناوری میکنیم و بعداً کارکرد و عملکرد آن را یاد میگیریم. برای مثال، ما اول هواپیماها را به پرواز درآوردیم و بعد به مطالعه و بررسی عواملی همچون فاکتور آشفتگی و ایرودینامیک پرداختیم. در حوزه هوش مصنوعی نیز چنین شرایطی حاک است؛ از این مدلها استفاده میکنیم اما نمیدانیم چگونه و چه چیزی را یاد میگیرند. به شما پیشنهاد میکنم این مطلب از لنا وویتا را مطالعه کنید. لنا وویتا پژوهشهای فوقالعادهای در زمینه مدل BERT، GPT و دیگر مدلهای مبتنی بر ترنسفورمر انجام داده است و همینکه ما در حال مهندسی معکوس کارکرد این مدلها هستیم نشان میدهد تحقیق و پژوهش در این زمینه رو به افزایش است.
- یک تصویر معادل هزار واژه است: مدلهای ترنسفورمر در حال پیشرفت هستند، برای اثبات آن هم میتوانیم به سراغ پژوهشهایی برویم که در آنها متن و بینایی در کنار یکدیگر قرار میگیرند تا مدلها بتوانند بر اساس اعلانهای جمله، تصویر ایجاد کنند. به همین ترتیب، شبکههای عصبی کانولوشن تا چندی پیش و زمان روی کارآمدن مدلهای مبتنی بر ترنسفورمر، فناوری کلیدی در حوزه بینایی ماشین به شمار میرفتند. مدلهای مبتنی بر ترنسفورمر در این حوزه پیشرفت خارقالعادهای محسوب میشود، چراکه ترکیب متن و بینایی این پتانسیل را دارد که عملکرد این مدلها را ارتقا دهد. همانگونه که پیش از این نیز گفتیم، مدل ترجمه ماشینی به صورت یک فناوری درآمده و احتمال اینکه این فنآوری به هوش عمومی دست یابد بیشتر از دیگر زیرشاخههای هوش مصنوعی است.





