
کاهش سوگیری و ارتقای عدالت در عرصه هوش مصنوعی
 تیم تحریریه
تیم تحریریه- ۱۸ دی ۱۴۰۰
سوگیریهای الگوریتمی و خروجیهای ناعادلانه و مبهم آنها در اشکال گوناگون ظاهر میشوند؛ اما راهبردها و تکنیکهای فراوانی برای مبارزه با آنها و ارتقای عدالت وجود دارد.
سوگیری الگوریتمی یکی از موضوعات مهم هوش مصنوعی است و مستلزم توجه و بازبینی دقیق است. خطاهای ناخواسته سیستمی میتوانند منجر به خروجیهای ناعادلانه و مبهم شوند و همین امر است که بر ضرورت توسعه استاندارد فناوریهای اخلاقی و مسئولیتپذیر میافزاید؛ خطرات اخلاقی با رشد بازار هوش مصنوعی که طبق پیشبینیها تا سال 2024 به 110 میلیارد دلار میرسد، تشدید خواهند شد.
هوش مصنوعی میتواند به طرق گوناگون دچار سوگیری شده و آسیبزا باشد. در این نوشتار، چندین مورد از این راهها را بررسی میکنیم.
اولین مورد مربوط به فرایندهای کاری است که هوش مصنوعی آنها را ارتقا میدهد یا جایگزینشان میشود. اگر این فرایندها، بافتی که در آن کار میکنند یا افرادی که با آنها سروکار دارند، علیه گروه خاصی سوگیری داشته باشند، فارغ از اینکه این سوگیری برنامهریزیشده باشد یا ناخواسته، الگوریتم هوش مصنوعی نیز به سوگیری مبتلا خواهد شد.
مورد دوم، فرضیات ذهنی خالقان هوش مصنوعی در خصوص اهداف سیستم، کاربران و سیستم ارزشیشان و نحوه به کارگیری سیستم است. این فرضیات میتوانند به سوگیریهایی آسیبزا بینجامند. مورد دیگر، دیتاستی است که برای آموزش و ارزیابی سیستم هوش مصنوعی به کار میرود. در صورتی که دادهها نماینده همه کسانی نباشد که با سیستم سروکار دارند یا نوعی سوگیری تاریخی و سیستماتیک علیه گروههای خاص نشان دهند، خروجی چیزی جز آسیب نخواهد بود.
مورد آخر، سوگیری خود مدل است که در صورتی اتفاق میافتد که متغیرهای حساس (همچون سن، نژاد یا جنسیت) یا پراکسیها (مثل اسم، کدپستی و…) در پیشبینیها و پیشنهادات مدل نقش ایفا کنند. توسعهگرها باید تشخیص دهند سوگیری از چه راهی به سیستم نفوذ کرده و سپس با رویکردی عینی (و بیطرف)، سیستمهای ناعادلانه و فرایندهایی را که به این بیعدالتی منتهی شدهاند، موردبازبینی قرار دهند؛ البته نباید فراموش کرد که همه اینها به زبان ساده هستند، وگرنه حداقل بیستویک تعریف مختلف از عدالت وجود دارد.
در مسیر دستیابی به مسئولیتپذیری هوش مصنوعی، آنچه از درمان سوگیری ارزشمندتر است، تعبیه اخلاقیات در فرایند طراحی و سراسر چرخه زندگی هوش مصنوعی است. در قسمت بعدی، به این چرخه نگاهی میاندازیم.
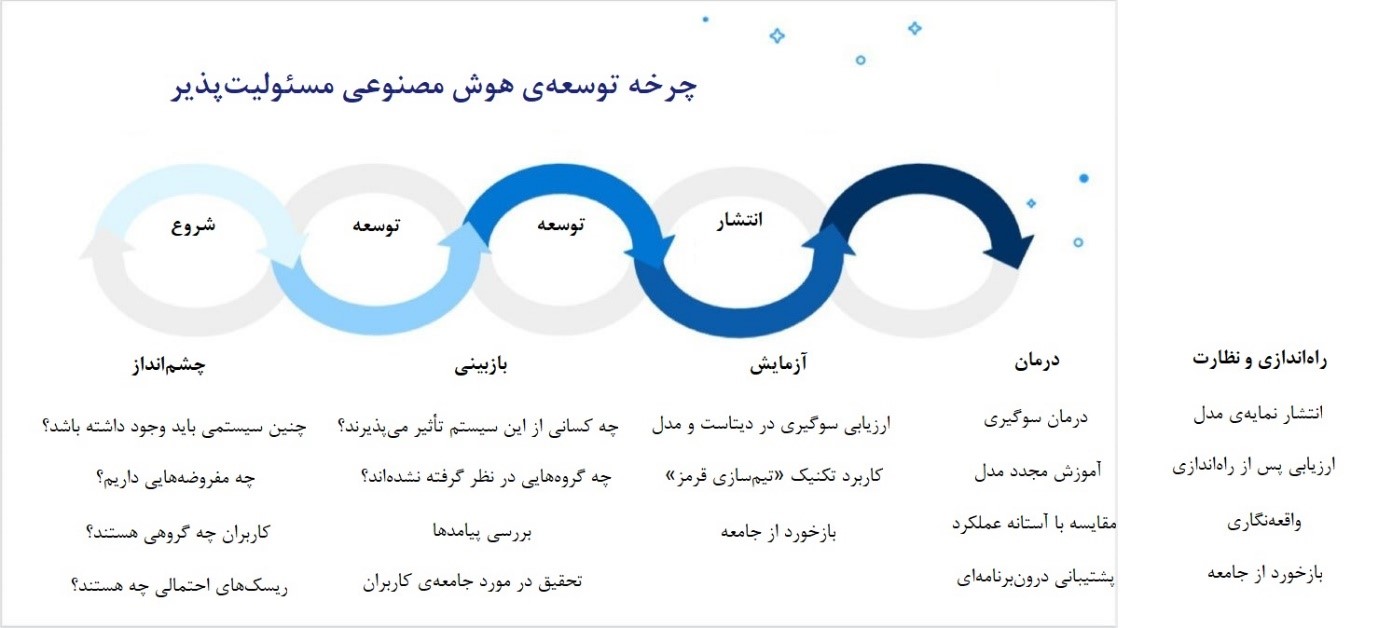
چشمانداز
همهی پروژههای فناوری با این پرسش آغاز میشوند: «آیا واقعاً لازم است چنین سیستمی وجود داشته باشد؟» پرسش «آیا میتوانیم این سیستم را بسازیم؟» نباید جای پرسش اصلی را بگیرد.
بهعبارتی، نباید در دام Technosoultionism بیفتیم: باوری که فناوری را یگانه راهکار همه مسائل و چالشها میداند. بهخصوص در عرصه هوش مصنوعی، باید از خود بپرسیم، آیا این فناوری راهکار درستی برای دستیابی به هدف موردنظر هست یا خیر؟ چه مفروضههایی در خصوص هدف هوش مصنوعی، افرادی که از آن متأثر میشوند و بافتی که در آن استفاده میشود، شکل گرفته است؟ آیا ریسک یا سوگیریهای اجتماعی و تاریخی وجود دارند که بر دادههای آموزشی این سیستم تأثیر بگذارند؟ همه ما سوگیریهایی داریم. جنسیتزدگی، نژادپرستی، سوگیری سنی، سوگیری علیه افراد کمتوان و ناتوان و انواع دیگر سوگیریهای تاریخی در هوش مصنوعی تشدید خواهند شد، مگر اینکه گامهایی جدی برای رفعشان برداریم.
اما تا زمانی که سوگیری را تشخیص نداده باشیم، نمیتوانیم آن را حل کنیم. این، گام بعدی است که دربارهاش صحبت خواهیم کرد.
بازبینی
بهمنظور واکاوی دقیق مفروضههای ذهنی افراد باید جامعه کاربران را بهصورت عمیق موردمطالعه قرار داد. چه افرادی در دیتاستها حضور دارند؟ دیتاستها نماینده چه گروهی هستند و چه گروهی از آن، جا ماندهاند؟ چه کسی از هوش مصنوعی متأثر میشود و چطور؟ در این گام، روشهایی همچون کارگاههای بررسی توالی و مدلسازی آسیب به کار میروند. این روشها مشخص میکنند سیستمهای هوش مصنوعی به چه طرقی میتوانند آسیبهای ناخواسته ایجاد کنند، چه به دست بازیگران (افراد) بدخواه چه به دست افرادی که نیت خوبی دارند، اما سادهلوحانه عمل میکنند.
هوش مصنوعی چطور میتواند در کاربردهایی که معتبر به نظر میرسند، آسیبهای غیرعمدی ایجاد کند؟ چطور میتوان این آسیبها، بهخصوص آسیبهایی را که متوجه گروههای آسیبپذیر (مثل کودکان، سالمندان، ناتوانها، گروههای به حاشیه راندهشده) میشوند، رفع کرد؟ اگر نتوان چارهای برای درمان محتملترین و شدیدترین آسیبها اندیشید، باید کار را متوقف کرد. این نشانهای است از اینکه سیستم هوش مصنوعی موردنظر نباید اصلاً وجود داشته باشد.
آزمایش
درحالحاضر، ابزارهای متنباز فراوانی برای تشخیص سوگیری و عدالت دیتاستها و مدلها وجود دارند؛ از جمله این ابزارها میتوان به ابزار What if از گوگل، ML Fairness Gym، AI 360 Fairness از IBM، Aequitas، و FairLearn اشاره کرد. ابزارهای دیگری هم هستند که تعاملی بوده و دادهها را به تصویر میکشند، تا راحتتر بتوان محتوا و توازن آنها را درک کرد؛ Facets از گوگل و AI 360 Explainability از IBM از جمله این ابزارها هستند. برخی از این ابزارها میتوانند سوگیری را درمان کنند، اما بیشترشان چنین قابلیتی ندارند. پس آمادگی خرید ابزارهای جداگانه برای این هدف را داشته باشید.
رویکرد «تیم قرمز» مربوط به حوزه امنیت است؛ اما وقتی در بافت اخلاقیات به کار میرود، به متخصصان اجازه میدهد از سیستم هوش مصنوعی بهنحوی استفاده کنند که آسیبزا باشد. بدین ترتیب، ریسکهای اخلاقی (و گاهی قانونی) آشکار میشوند. بعد از مشخص شدن این خطرات، باید چارهای برای حلشان اندیشید. رویکرد «هیئتمنصفه مردمی» هم روشی دیگر برای تشخیص آسیبهای بالقوه یا پیامدهای ناخواسته سیستمهای هوش مصنوعی است. در این روش، نمایندگانی از گروههای حاضر در جامعه گرد هم میآیند (بهخصوص گروههای به حاشیه راندهشده) تا درک بهتری از چشمانداز و دیدگاهشان در خصوص تأثیراتی که سیستم بر آنها خواهد گذاشت، به دست آید.
درمان
راههای گوناگونی برای کاهش شدت آسیبها وجود دارد. ممکن است توسعهدهندگان تصمیم بگیرند پرریسکترین کارکرد را به کل حذف کنند یا از هشدارها و پیامهای داخلی (داخل برنامه) استفاده کنند، تا آگاهی افراد در خصوص کاربرد مسئولانه هوش مصنوعی را ارتقا دهند. راه دیگر، نظارت سختگیرانه بر نحوه به کارگیری سیستمهاست، تا بلافاصله بعد از تشخیص آسیب، غیرفعال شوند. گاهی اوقات، چنین نظارت و کنترلی ممکن نیست؛ برای مثال، در مدلهای سفارشی (tenant-specific) که کاربران با استفاده از دیتاستهای خود، مدلهایی را توسعه و آموزش میدهند.
همیشه راههایی برای بررسی و درمان مستقیم سوگیریهای موجود در دیتاستها و مدلها وجود دارد. در قسمت بعدی، فرایند درمان سوگیری را بر اساس چرخه زندگی مدل، به سه دسته خاص تفکیک میکنیم: پیشپردازش (درمان سوگیری در دادههای آموزشی)، حین پردازش (درمان سوگیری در کلسیفایرها) و پسپردازش (درمان سوگیری در پیشبینیها). جا دارد از IBM بابت پیشگام بودن در تعریف این دستهها قدردانی کرد.
درمان سوگیری و برقراری عدالت در پیشپردازش
درمان در مرحله پیشپردازش بر دادههای آموزشی تمرکز دارد؛ دیتاست آموزشی محور اصلیِ اولین مرحله از توسعه هوش مصنوعی است و سوگیریهای بنیادین مدل معمولاً همینجا شکل میگیرند. هنگام تحلیل عملکرد مدل ممکن است اثری نامتجانس رخ دهد؛ برای مثال، وقتی احتمال استخدام یا اعطای وام به یک جنسیت از جنسیت دیگر بیشتر باشد. این اثرات نامتجانس را باید به چشم سوگیریهایی آسیبزا و ناعادلانه در نظر گرفت: خانمی که میتواند از پس بازپرداخت وام برآید، اما به خاطر جنسیتش رد صلاحیت میشود یا عدم تعادل بین جنسیت نیروهای استخدامی.
انسانها نقش پررنگی در مرحله آموزش بر عهده دارند، اما خود به صورت ذاتی، سوگیریهای فراوانی دارند. هرچه گوناگونی در تیمهایی که مسئول ساخت و پیادهسازی فناوری هستند، کمتر باشد، احتمال خروجیهای منفی افزایش مییابد. برای مثال، اگر گروه خاصی از جامعه به صورت ناخواسته در دیتاست حضور نداشته باشند، سیستم بهصورت خودکار آن افراد را در معرض آسیبی چشمگیر قرار میدهد.
درمان سوگیری و برقراری عدالت حین پردازش
تکنیکهای درمان حین پردازش به ما اجازه میدهند در حین اجرای مدل، سوگیری در کلسیفایرها را درمان کنیم. در یادگیری ماشین، کلسیفایر به الگوریتمی گفته میشود که دادهها را مرتب و درون چند گروه دستهبندی میکند. با به کارگیری این روشها، به دقت مدل کفایت نمیکنیم و مطمئن میشویم که سیستمها عادلانه باشند.
در این گام، میتوان از تکنیک سوگیریزدایی تخاصمی استفاده کرد؛ این تکنیک همزمان با کاهش ردپای ویژگیهای امنیتی، دقت را به حداکثر میرساند. هدف نهایی «تسلیم سیستم» و وادار کردنش به انجام کاری است که نمیخواهد انجام دهد، تا بدین ترتیب، به تأثیر سوگیریهای منفی احتمالی نوعی ضدواکنش به سیستم آموخته شود.
بهعنوان مثال، فرض کنید مؤسسهای مالی میخواهد قبل از اعطای وام، توانایی بازپرداخت مشتریانش را بسنجد و سیستم هوش مصنوعی بهکاررفته متغیرهای حساس یا امنیتی همچون نژاد و جنسیت یا متغیرهای پراکسی (همچون کد ZIP که میتواند با نژاد مرتبط باشد) را در این تصمیم دخیل کند. اینها مواردی از سوگیریهای حین پردازش هستند که منجر به خروجیهایی اشتباه و ناعادلانه میشوند.
تکنیکهای حین پردازش با اجرای اصلاحاتی جزئی طی آموزش، امکان درمان سوگیری را فراهم میآورند و خروجیهایی صحیح را تضمین میکنند.

درمان سوگیری و برقراری عدالت در پسپردازش
درمان پسپردازشی زمانی مفید واقع میشود که توسعهگرها مدل را آموزش دادهاند و حالا میخواهند از برابری خروجیها اطمینان حاصل کنند. به عبارت دیگر، هدف از پسپردازش درمان سوگیریهای موجود در پیشبینیهاست و به جای کلسیفایر و دادههای آموزشی، صرفاً خروجیهای مدل بازبینی و سازگار میشوند.
بااینحال، هنگام ارتقای خروجیها، ممکن است دقت مدل تحتتأثیر قرار گیرد. برای مثال، اگر هدف برقراری توازن بیشتر بین نیروهای استخدامی خانم و آقا باشد، الگوریتم به جای توجه به شایستگیها و مهارتهای مرتبط با شغل، صرفاً مردان کمتری استخدام کند. این پدیده را گاهی بهعنوان سوگیری مثبت یا اقدام تأییدی نیز میشناسند. در نتیجه، هدف که کاهش سوگیری است، میسر میشود؛ اما دقت مدل هم کاهش مییابد.
راهاندازی و نظارت، برقراری عدالت
بعد از اینکه مدل موردنظر آموزش دید و توسعهگرها از تأمین آستانههای عملکردی (در خصوص سوگیری و عدالت) اطمینان حاصل کردند، میتوان نحوه آموزش مدل، کارکرد، کاربردهای برنامهریزیشده و نشده، نتیجه سنجش سوگیریها و همه ریسکهای اجتماعی و اخلاقی احتمالی را مستند کرد. این سطح از شفافیت نهتنها به اعتماد مشتریان به هوش مصنوعی کمک میکند، بلکه در صورت کاربرد سیستم در صنایع تحت نظارت ممکن است ضروری هم باشد. خوشبختانه چندین ابزار متنباز برای کمک به این فرایند وجود دارند که از میان آنها میتوان به Modal Card Toolkit از گوگل، AI FactSheets 360 از IBM و Open Ethics Label اشاره کرد.
سیستمهای هوش مصنوعی را بههیچوجه نمیتوان بعد از راهاندازی به حال خود رها کرد. بلکه طی نظارتی پیوسته، باید به دنبال انحرافات مدل بود. این انحرافات هم بر دقت و عملکرد مدل تأثیر میگذارد و هم عدالت آن را به خطر میاندازند. مدل باید به صورت منظم ارزیابی شود و در صورت نیاز، مجدداً آموزش ببیند.
انتخاب گام درست
در عرصه هوش مصنوعی، گام برداشتن در مسیر درست میتواند دشوار باشد؛ اما اکنون بیش از هر زمان دیگری اهمیت دارد. کمیسیون فدرال تجارت اخیراً به این موضوع اشاره کرد که در آیندهای نهچنداندور، قوانینی تصویب خواهد کرد که فروش و استفاده از هوش مصنوعیهای سوگیرانه را ممنوع میکند. اتحادیه اروپا نیز مشغول کار بر روی چارچوبی برای قانونمندسازی هوش مصنوعی است. هوش مصنوعیِ مسئولیتپذیر برای جامعه مفید است، به کسبوکارها کمک میکند و خطرات قانونی و ریسک از دست رفتن ارزش برند را برای آنها کاهش میدهد.
نقش هوش مصنوعی در حل مسائل اقتصادی، اجتماعی و سیاسی به طور روزافزون افزایش مییابد. با اینکه هیچ رویکرد واحدی را نمیتوان در همه موقعیتهای تولید و به کارگیری هوش مصنوعی پیاده کرد، راهبردها و تکنیکهایی که در این مقاله مطرح شدند، میتوانند در مراحل گوناگون چرخه زندگی الگوریتمها مفید واقع شوند. درمان سوگیری ما را به فناوریهای اخلاقی بزرگمقیاستر نزدیک میکند.
درهرحال، آنچه نباید فراموش شود این است که همه مسئولاند از ساخت خیرخواهانه سیستمها اطمینان حاصل کنند و به فکر تشخیص آسیبهای ناخواسته و برنامهریزی نشده باشند.
منظور از ویژگیهای امنیتی یا Protected Attributes ویژگیهایی هستند که شاید در تصمیم اصلی سیستم نقشی نداشته باشند، اما به دلایل قانونی باید مدنظر قرار بگیرند.





