
بخشبندی تصویر و هر آنچه که لازم است در این باره بدانید
 تیم تحریریه
تیم تحریریه- ۲۴ مهر ۱۴۰۰
1. بخشبندی تصویر چیست و انواع آن کدامند؟
2. معماریهای بخشبندی تصویر
3. توابع زیان در حوزه بخشبندی تصویر
4. چارچوبهایی که در آن میتوان پروژههای بخشبندی تصویر را تعریف و اجرا کرد.
بخش بندی تصویر چیست؟

معماریهای بخشبندی تصویر
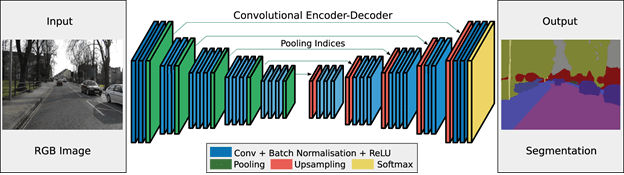
بخش کدگذار ویژگیهای خاص هر تصویر را به کمک فیلترها استخراج میکند. بخش کدگشا نیز مسئولیت تولید خروجی نهایی را برعهده دارد که بهطورمعمول در آن یک ماسک بخشبندیکننده، طرح کلی شیء را مشخص میکند. معماری فرآیندهای بخش بندی تصویر، در اکثر مواقع، مشابه این معماری هستند.
معماری U-Net
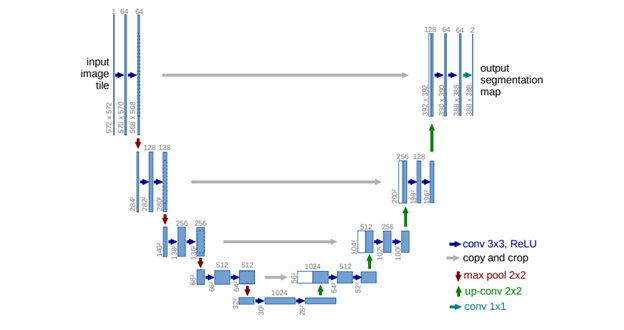
معماری U-Net دارای یک مسیر گسترشسازی در سمت راست و یک مسیر فشردهسازی در سمت چپ میباشد. مسیر فشردهسازی متشکل از 2 لایه سه به سه پیچشی است. هر یک از این لایههای پیچشی، یک تابع فعالسازی Relu و یک الگوریتم max-pooling دو در دو برای کاهش نمونهگیری کاهش نمونهگیری Downsampling نگاشت ویژگی دارد.
یک مثال از کاربرد معماری U-Net را میتوانید در این لینک مشاهده نمایید.
شبکه سریع تماماً متصل یا FastFCN
در این معماری از یک ماژول افزایش نمونهگیری UpSampling هرم مشترک (JPU) برای جایگزین کردن پیچشی منبسطشده یا گسترده Dilated convolution استفاده میشود، زیرا این پیچشی به حافظه و زمان زیادی نیاز دارند. هسته اصلی این معماری یک شبکه تماماً متصل است که یک ماژول JPU نیز برای افزایش نمونهگیری در آن تعبیه شده است. در روش JPU، حجم نمونههایی که وضوح نگاشت ویژگی کمتری دارند، افزایش مییابد.
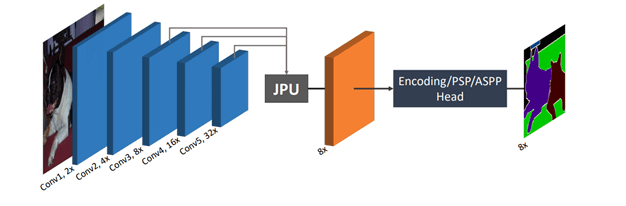
اگر میخواهید کدهای مربوط به این معماری را اجرا کنید، به این لینک مراجعه نمایید.
شبکه عصبی پیچشی دارای دروازه شناسایی شکل شیء (Gated-SCNN)
ساختار شبکههای عصبی پیچشی (CNN) در این معماری، دارای 2 شاخه است. در این مدل، شاخه جداگانهای برای پردازش اطلاعات اشکال درون تصویر وجود دارد. از شاخه دستهبندی شکل در این معماری برای پردازش اطلاعات مرزبندیها استفاده میشود.
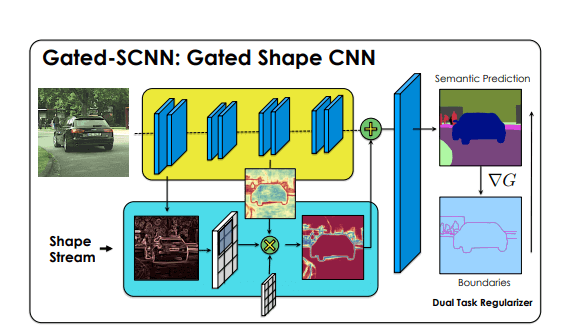
در این لینک میتوانید کدهای لازم برای اجرای این معماری را بیابید.
معماری DeepLab
در این معماری، شبکه پیچشی با فیلترهای افزایش نمونهگیری ترکیب شده تا در انجام پیشبینیهای پرتراکم مورد استفاده قرار گیرد. در این فرآیند، بخش بندی اشیاء در چندین مقیاس و به وسیله تجمیع هرمی فضایی آتروس انجام میشود و درنهایت نیز با استفاده از شبکههای عصبی پیچشی عمیق، مرزهای اطراف اشیاء در تصاویر مکانیابی خواهند شد. در شبکه پیچشی آتروس با افزودن نمونههای صفر یا پراکنده از نگاشت ویژگیِ ورودی، نمونهگیری از فیلترها افزایش مییابد.
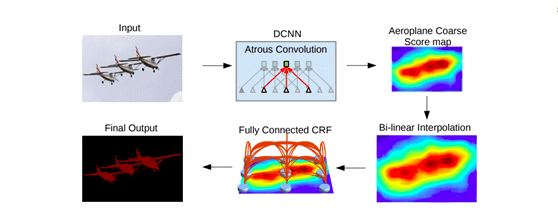
برای استفاده از این معماری میتوانید از کتابخانههای PyTorch و TensorFlow استفاده کنید.
معماری شبکه عصبی پیچشی ماسک ناحیهای (Mask R-CNN)
در این معماری، میتوان با استفاده از یک کادر محاطی و روش بخش بندی معنایی که پیکسلهای تصویر را در دستههای مختلف قرار میدهد، اشیاء را طبقهبندی و مکانیابی کرد. بدین ترتیب، هر بخش یک ماسک بخشبندی خواهد داشت. به عنوان خروجی نهایی نیز یک برچسب کلاس و یک کادر محاطی تولید میشود. این معماری نسخه تکامل یافته تر معماری Faster R-CNN است. معماری Faster R-CNN از یک شبکه پیچشی عمیق ساخته شده است که نواحی مختلف تصویر را به ما پیشنهاد میدهد و یک ردیاب نیز برای بهکارگیری این نواحی دارد.
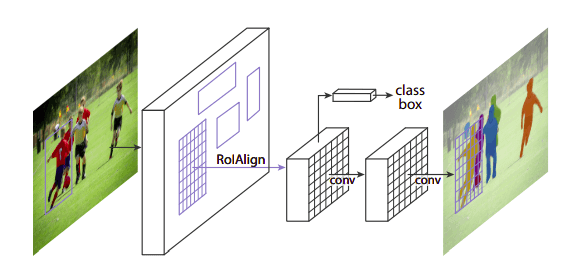
در این تصویر میتوانید نتایج حاصل از اعمال این معماری روی مجموعه تصاویر دیتاست COCO را ملاحظه فرمایید.

توابع زیان در حوزه بخشبندی تصویر
مدلهای بخش بندی معنایی بهطورمعمول در طول دوران یادگیری از یک تابع زیان آنتروپی میان رستهای بسیار ساده استفاده میکنند. اما اگر اطلاعات جزئیتری از یک تصویر میخواهید، باید توابع زیان پیشرفتهتری را بهکار بگیرید.
در ادامه به بررسی برخی از توابع زیان پیشرفته میپردازیم.
تابع زیان کانونی (Focal Loss)
این تابع زیان درواقع نسخه بهبودیافته مقیاس استاندارد آنتروپی متقاطع است. بهبود این تابع با تغییر شکل آن انجام گرفته و به نحوی اعمال شده که زیان نسبت داده شده به نمونههایی که به خوبی طبقهبندی شدهاند، کاهش مییابد. بدین ترتیب، تمام کلاسها درنهایت با یکدیگر همتراز خواهند شد. در این تابع زیان، مقیاسبندی تابع زیان آنتروپی متقاطع به کمک مقیاسبندی عواملی انجام شده که مقدار آنها با افزایش احتمال درستبودن کلاسها به صفر نزدیک میشود. مقیاسبندی عوامل بهطور خودکار سهم نمونههای آسان را از فرآیند یادگیری کاهش میدهد و فرآیند یادگیری را بر روی نمونههای دشوار متمرکز میکند.
![]()
تابع زیان تاس (Dice Loss)
این تابع زیان از محاسبه تابع هموار ضریب تاس به دست میآید و پرکاربردترین تابع زیان در حوزه بخشبندی تصویراست.
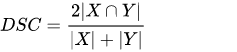
تابع زیان اشتراک در اجتماعِ متقارن (IoU)
هدف «تابع زیان اشتراک در اجتماعِ متقارن» از طبقهبندی تصاویر عبارت است از: افزایش گرادیان نمونههایی که مقدار اشتراک در اجتماع آنها بالاست و کاهش گرادیان نمونههایی که مقدار اشتراک در اجتماع آنها کم است. بدین ترتیب، دقت مکانیابی مدلهای یادگیری ماشینی افزایش خواهد یافت.
![]()
تابع زیان کرانی (Boundary Loss)
توابع زیان کرانی زمانی به کار میآیند که با بخشبندیهای بهشدت نامتقارن سروکار داشته باشیم. این نوع از توابع زیان یک معیار برای تعیین فاصله میان خطوط (کانتورهای) فضاست، نه ناحیهها. به این ترتیب، میتوان از از دست رفتن نواحی طی فرآیند بخش بندی تصاویر بهشدت نامتقارن را جلوگیری کرد.
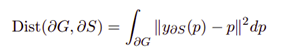
تابع زیان آنتروپی متقاطع وزنی
در این دسته از توابع آنتروپی متقاطع، تمامی نمونههای مثبت توسط یک ضریب مشخص وزندهی میشوند. این تابع زمانی مورد استفاده قرار میگیرد که با مسئله عدمتقارن در کلاس روبهرو باشیم.
تابع زیان بیشینه هموار لاووس (Lovász-Softmax Loss)
این تابع در شبکههای عصبی، بهینهسازی میانگین تابع زیان اشتراک در اجتماع را بهطور مستقیم و براساس بسط محدب توابع زیان فرعی لاووس، انجام میدهد.
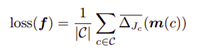
شناخت سایر توابع زیان نیز خالی از لطف نخواهد بود:
تابع زیان TopK: این تابع شبکهها را در طول دوران یادگیری بر روی نمونههای دشوارتر متمرکز میکند.
تابع زیان آنتروپی متقاطعِ حذف فواصل (Distance penalized CE loss): این تابع زیان شبکه را به سوی نواحی مرزی هدایت میکند که بخشبندی آنها دشوار است.
تابع زیان حساسیت-وضوح (SS): این تابع زیان عبارت است از مجموع وزنیِ میانگین مربعات تفاضلِ مربوط به حساسیت و وضوح تصاویر.
تابع زیان فاصله هادسدروف (HD): این تابع زیان فاصله هادسدروف را در شبکه عصبی پیچشی برآورد میکند.
این توابع تنها تعداد اندکی از توابع زیان مورد استفاده در حوزه بخشبندی تصاویر هستند. برای مطالعه بیشتر در این خصوص به این لینک مراجعه فرمایید.
مجموعههای دادهای در حوزه بخشبندی تصویر
پس از مطالعه مطالب پیشین، احتمالاً از خود میپرسید که دیتاست موردنیاز برای شروع را چگونه میتوان پیدا کرد.
در ادامه به بررسی برخی از دیتاستها خواهیم پرداخت.
دیتاست (COCO (Common Objects in COntext
COCO یکی از بزرگترین دیتاستها در حوزه تشخیص، بخش بندی و عنوانگذاری برای تصاویر است. این دیتاست شامل 91 کلاس است و اطلاعات و ویژگیهای خاص 250.000 فرد در آن ذخیره شده است. حجم موردنیاز برای بارگیری این مجموعه دادهای 37.57 گیگابایت است. اشیاء در دیتاست COCO در 80 دسته طبقهبندی شدهاند. این دیتاست تحت لیسانس Apache 2.0 است. COCO را میتوانید از اینجا بارگیری نمایید.
کلاسهای اشیاء دیداری پاسکال (PASCAL VOC)
پاسکال شامل 9963 تصویر است که در 20 کلاس مختلف دستهبندی شدهاند. سایز فایل مجموعه یادگیری/اعتبارسنجی آن 2 گیگ است و میتوان آن را از وبسایت رسمی پاسکال بارگیری نمود.
دیتاست Cityscapes
این دیتاست شامل تصاویری از مناظر شهری است و میتوان از آن برای ارزیابی عملکرد الگوریتمهای بینایی استفاده کرد که در نواحی شهری بهکار گرفته شدهاند. دیتاست CityScapes را میتوانید از این لینک بارگیری نمایید.
دیتاست فیلمهای رانندگی و برچسبدار کمبریج (CamVid)
دیتاست CamVid یک مجموعه دادهای مبتنی بر حرکت در حوزه بخشبندی و تشخیص تصاویر است که شامل 32 کلاس معنایی میباشد. برای کسب اطلاعات بیشتر و بارگیری این دیتاست به این لینک مراجعه نمایید.
حال که با دیتاستهای موجود آشنا شدید، به مرور برخی از ابزارها و چارچوبهای کاری میپردازیم که میتوانید از آنها بهره ببرید.
کتابخانه Fast AI
این کتابخانه پس از دریافت یک تصویر، برای هر شیء درون آن یک ماسک ایجاد میکند.
ابزار بخشبندی تصویر Sefexa
Sefexa یک ابزار رایگان و نیمه خودکار برای بخشبندی و تحلیل تصاویر و تهیه مجموعه دادههای آموزشی برچسبدار است.
Deepmask
Deepmask محصولی از شرکت تحقیقاتی فیسبوک است که با افزودن چارچوب کاری تورچ (Torch) به ابزارهای DeepMask و SharpMask توسعه یافته است.
OpenCV
OpenCV یک کتابخانه متن باز در حوزه بینایی ماشین است که بیش از 2500 الگوریتم بهینهسازی شده در آن وجود دارد.
MIScnn
این ابزار درواقع یک کتابخانه متن باز در حوزه بخش بندی تصاویر پزشکی است. به کمک این کتابخانه میتوان تنها با نوشتن چند خط کد، مدلهای یادگیری عمیق و کانالهای ارتباطی را در پیشرفتهترین شبکههای عصبی پیچشی ایجاد کرد.
Fritz
فریتز ابزارهای مختلفی در حوزه بینایی ماشین به ما ارائه میدهد که از جمله آنها میتوان به ابزارهای بخشبندی تصویر برای گوشیهای موبایل اشاره کرد.





