بررسی جامعِ تشخیص اشیاء و بخش بندی نمونه
 تیم تحریریه
تیم تحریریه- ۱۴ تیر ۱۴۰۱
تشخیص اشیاء Object Detection یکی از مهمترین حوزههای تحقیق در «بینایی رایانه Computer Vision» به شمار میآید. محققان از مدتها پیش علاقهمند به انجام تحقیق در این حوزه بودهاند، اما در سالهای اخیر به لطف ابداع «Convents» که نقش استخراجکننده ویژگی را دارد و همچنین «یادگیری انتقال Transfer learning» که روشی برای انتقال دانش قبلی است،
تشخیص شیء
نتایج بزرگی حاصل آمده است. نخستین ابزارهای تشخیص شیء بر پایه ویژگیهای دستی استوار بودند و از روش مبتنی بر پنجره متحرک استفاده میکردند. این روش به لحاظ محاسبه ناکارآمد بود و دقت پایینی داشت. از جمله روشهای جدید میتوان به «روشهای Region Proposal» «روشهای تکشات Single shot Methods»، «روشهای بدون لنگر Anchor Free Methods» و غیره اشاره کرد.
الف. تشخیص شیء: به روشی برای شناسایی و برچسب زدن دقیقِ همه اشیای موجود در فریم عکس اشاره میکند. این روش از دو مرحله تشکیل یافته است:
1. مکان یابی شیء Object Localization: در این روش، یک ناحیه محصورکننده و تا حد ممکن فشرده، تعیین میشود تا موقعیت دقیق شیء در تصویر تعیین شود.
2. طبقه بندی عکس Image Classification: شیء مکان یابی شده در اختیار طبقه بند قرار میگیرد تا شیء برچسب بگیرد.
ب. بخشبندی معنایی Semantic Segmentation: این روش به فرایند پیوند دادنِ هر پیکسل در عکس به یک چسب کلاس معین اشاره میکند. برای مثال، در عکس زیر، پیکسلها با عنوان اتومبیل، درخت، عابر پیاده و غیره برچسب زده میشود. این بخشها برای یافتنِ برهمکنشها و روابط میان اشیای مختلف مورد استفاده قرار میگیرد.
ج. بخشبندی نمونه: در این رویکرد، به مانند بخشبندی معنایی یک برچسب به هر کدام از پیکسلها زده میشود؛ با این تفاوت که اشیای مختلفِ یک کلاس به عنوان اشیای منحصر به فرد یا واحدهای جداگانه در نظر گرفته میشوند.
د. بخشبندی Panoptic: این روش ترکیبی از بخشبندی معنایی و نمونه است و هر یک از پیکسلها را با دو مقدار مرتبط میکند: یعنی برچسب دستۀ آن و یک عدد نمونه. این روش به شناسایی آسمان، جاده و سایر عناصر پسزمینهای میپردازد.
مفاهیم مهم
1. Bounding Box: یک مستطیل تا حد ممکن کوچک، که برای احاطه کردنِ شیء مورد نظر استفاده میشود. این کادر عموماً با چهار مقدار توصیف میشود: (bx, by, bh, bw).
بر این اساس، (bx, by) مختصات مرکز کادر است؛ bh و bw به ترتیب ارتفاع و عرض کادر هستند. 2. کادرهای محصورکننده (Anchor Boxes): اینها مجموعهای از کادرهای محصورکنندۀ از پیشتعریف شده با ارتفاع و عرض مشخص هستند. این کادرها برای بررسی مقیاس و نسبت دستههای مشخص اشیاء تعریف شده و معمولاً بر اساس اندازه اشیاء در دیتاست های آموزشی انتخاب میشوند. در طول فرایند تشخیص، کادرهای محصورکنندۀ از پیشتعریف شده در سراسر عکس به کار برده میشوند. شبکه به پیشبینیِ احتمال و سایر ویژگیها از جمله پسزمینه، اشتراک پیرامون اجتماع (IoU) Intersection over Union و غیره میپردازد. پیشبینیها برای ارتقای تکتکِ کادرهای محصورکننده مورد استفاده قرار میگیرند.
2. کادرهای محصورکننده (Anchor Boxes): اینها مجموعهای از کادرهای محصورکنندۀ از پیشتعریف شده با ارتفاع و عرض مشخص هستند. این کادرها برای بررسی مقیاس و نسبت دستههای مشخص اشیاء تعریف شده و معمولاً بر اساس اندازه اشیاء در دیتاست های آموزشی انتخاب میشوند. در طول فرایند تشخیص، کادرهای محصورکنندۀ از پیشتعریف شده در سراسر عکس به کار برده میشوند. شبکه به پیشبینیِ احتمال و سایر ویژگیها از جمله پسزمینه، اشتراک پیرامون اجتماع (IoU) Intersection over Union و غیره میپردازد. پیشبینیها برای ارتقای تکتکِ کادرهای محصورکننده مورد استفاده قرار میگیرند.
امکان تعریفِ چندین کادر محصورکننده برای اندازههای مختلف اشیاء وجود دارد.
نسبت ابعاد Aspect Ratio ، به عرض / ارتفاع کادر گفته میشود.
اندازه عبارتست از ارتفاع و عرض کادر.
مقیاس (Scale) ضریب تکثیر است که نسبت کادر مورد نیاز به کادر پایه را نشان میدهد.
3. اشتراک پیرامون اجتماع(IOU):
IOU یک متریک ارزیابی کننده است که برای بررسی دقت کادر محصورکنندۀ پیشبینی شده با توجه به کادر محصور کننده واقعی، استفاده میشود.
IOU of > 0.5 پیشبینی خوب به حساب میآید و برای تکامل بیشتر در نظر گرفته میشود.
4. تضعیف غیربیشینه Non- max suppressiont: اگر چندین کادر برای یک شیء تخمین زده شده باشد، این روش همه کادرها را کنار میگذارد، به جز کادری که دارای IOU بیشینه است.
5. ماسک دودویی Binary Mask: یک آرایه دو بعدی است که طول و عرض آن با طول و عرض عکس یکسان بوده و هر درایه اش متناظر با یک پیکسل از عکس است.
هر پیکسل در ماسک با عدد 0 یا 1 (True یا False ) برچسب زده شده است. درایه هایی که با 1 برچسب زده شده اند نشان دهنده قسمتی از عکس است که شامل نمونه مطلوب است.
معیارmAP Mean Average Precision
متریکی است که برای تعیین دقت ابزارهای تشخیص اشیاء مورد استفاده قرار میگیرد. mAP به صورت درصد بیان میشود.
 معیار فوق بیانگر میانگین دقت تشخیص تمام نمونه های اشیا در یک عکس است. برای راحتی mAP به صورت درصد بیان میشود.
معیار فوق بیانگر میانگین دقت تشخیص تمام نمونه های اشیا در یک عکس است. برای راحتی mAP به صورت درصد بیان میشود.
پیشنهادهای ناحیه
شبکه عصبی پیچشی ناحیهمحور (Region-based convolutional neural networks (RCNN: یک الگوریتم تشخیص اشیاء مبتنی بر پیشنهاد ناحیه است.
به مراحل دخیل در این الگوریتم توجه داشته باشید:
1. بخش بندی:
گیرشیک و همکارانش در مقاله ای که درباره RCNN نوشتهاند، از روش جستجوی انتخابی برای پیشنهاد 2000 ناحیه استفاده میکنند.
1.1. جستجوی انتخابی Selective Search:
جستجوی انتخابی از الگوریتم گروهبندی سلسلهمراتبی Hierarchical Grouping Algorithm برای پیشنهاد ناحیه استفاده میکند.
1.1.1. ایجاد ناحیههای اولیه:
الگوریتم بخشبندی عکس مبتنی بر گراف برای ایجاد ناحیههای اولیه استفاده میشود.
1.1.2. معیار شباهت:
وجه تشابه میان نواحی بر اساس معیارهای زیر به دست میآیند.
- رنگ
- بافت
- اندازه
- سازگاری شکل
متریک شباهت به صورت زیر به دست میآید.
s(ri,rj) =a1Scolour(ri,rj) +a2Stexture(ri,rj) +a3Ssize(ri,rj)+a4Sfill(ri,rj)
1.1.3 گروهبندی بازگشتی:
ابتدا کار را از نواحی اولیه شروع کرده و سپس نواحی را بر اساس متریک شباهت گروهبندی میکنیم. به مجرد اینکه تعداد پیشنهادهای دلخواه به دست آید، دست از این کار میکِشیم.
1.2 Warping: اندازه هر کدام از نواحی پیشنهادی تغییر داده میشود تا با اندازه ورودی های مورد نیاز Convnet سازگار باشد، سپس درون کادر فشردهای قرار میگیرند.
1.3 استخراج ویژگی: هر کدام از نواحی فوق که که اندازهشان تغییر داده شده، به همراه لیبل در اختیار Convnet قرار میگیرد که خروجی آن یک بردار ویژگی 4096 عنصری است.
1.4 طبقهبندی: بردار ویژگی 4096 عنصری به SVM داده میشود تا اشیاء را دستهبندی کرده و به آنها برچسب بزند.
1.5 رگرسور Bounding Box :
RCNN علاوه بر برچسب دسته از یک رگرسور خطی هم استفاده میکند که خروجی آن یک Bounding Box برای شی مورد نظر است.
6. IOU و تضعیف غیربیشینه: در صورتی که همپوشانی وجود داشته باشد، آن دسته از نواحی که بالاترین امتیاز را گرفتهاند، انتخاب میشوند و از بقیه صرفنظر میشود.
ب. RCNN سریع:
نسخه پیشرفتۀ RCNN که برخی از معایب RCNN را برطرف کرده است.
مزایا:
- کیفیت تشخیص بالاتر (mAP) از R-CNN، SPPnet
- زمان محاسبه کمتر به دلیل تکمرحلهای بودن
- بینیازی از فضای حافظه بیشتر برای ذخیره سازی ویژگیها میانی.
- پارامترهای کمتر در مقایسه با rcnn و SPPnet
فرایند:
- ایجاد نگاشت ویژگی: کل عکس به همراه پیشنهاد اشیا به Convnet داده میشود. با گذر از لایههای Conv و لایههای ادغام بیشینه (Max Pooling)، نگاشت ویژگی به دست میآید.
- ROI Pooling: ناحیه مورد نظر (ROI) در نگاشت ویژگی با مختصات y (r,c,h,w) بدست میآید. این ناحیه از لایه ادغام ROI عبور میکند تا نگاشت ویژگی H×W به دست آید.
- لایههای کاملاً متصل: این نگاشت ویژگی استخراج شده و از لایههای FC عبور داده میشود. هدف از این کار، پیشبینی احتمال و رگرسور برای خروجیهای رگرسیون کادر محصورکننده است.
ج. RCNN سریعتر:
راس گیرشیک و همکارانش مدل RCNN سریعتر را به عنوان راهحلی کارآمد برای تشخیص اشیاء پیشنهاد کردند.
مزایا:
- پیشنهاد نواحی در عکس را آسان میکند.
- از یک شبکه عصبی کاملاً پیچشی برای این منظور استفاده میکند.
- RPN که در این مقاله پیشنهاد شد، ویژگیها را به خوبی با ابزار تشخیص اشیاء به اشتراک میگذارد.
معماری و عملیات
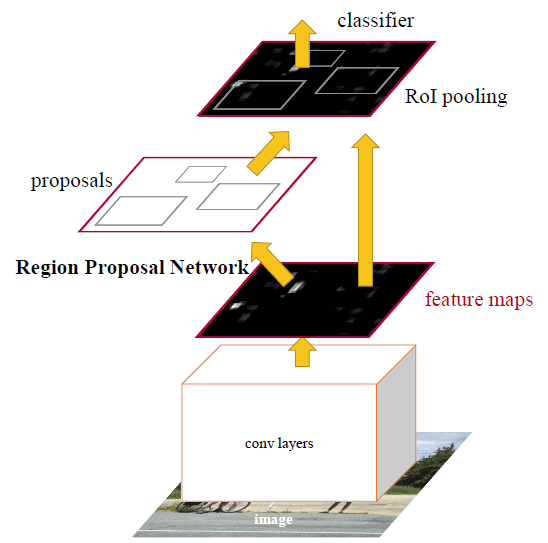
- ایجاد نگاشت ویژگی: عکس به درون لایههای Conv فرستاده میشود که خروجی آنها یک نگاشت ویژگی است.
- شبکه پیشنهاده ناحیه: از یک پنجره لغزان Sliding Window در RPN برای هر بخش پیرامون نگاشت ویژگی استفاده میشود.
- کادر: برای هر بخش، k (k=9) کادر محوری برای پیشنهاد ناحیه استفاده میشوند.
- طبقهبندی: لایه cls از 2k امتیاز خروجی، برای تعیین اینکه این k کادر شامل شی مودر نظر هست یا خیر استفادهم میکند.
- رگرسیون: لایه رگرسیون از 4k خروجی (مختصات مرکز کادر، طول و عرض باکس) جهت تعیین k کادر استفاده میکند.
- شبکه تشخیص: به جز بخشِ مربوط به RPN، شبکه تشخیص مثل rcnn سریع عمل میکند.
- آموزش دیگر: RPN و تشخیص به صورت متناوب آموزش داده میشوند و ویژگیهای یاد گرفته شده را با هم به اشتراک میگذارند.
د. Mask RCNN:
این روشِ مهم در بخشبندی نمونه مورد استفاده قرار میگیرد.
بررسی ویژگیها:
- Rcnn سریعتر، Yolo و سایر الگوریتمهای تشخیص اشیا، کادر محصورکننده و برچسب احتمال کلاس متناظر را به عنوان خروجی ارائه میدهند.
- ما انسانها محل اشیاء را با کشیدن کادر به دورشان مشخص نمیکنیم؛ بلکه به شکل ظاهری آن برای تشخیصاش نگاه میکنیم.
- mask rcnn میتواند اشیاء را تا حد زیادی مثل انسان تشخیص دهد.
- تحقیقات بیشتر درباره mask rcnn انگیزهای مضاعف برای بررسی مواردی از قبیل بخشبندیِ panoptic، تشخیص نقاط کلیدی انسان و غیره ایجاد میکند.
- همه اتومبیلهای خودران از این مفهوم اساسی با محوریتِ mask rcnn استفاده میکنند.
معماری و عملیات:
- Mask RCNN از همان راهکار دومرحلهای استفاده میکند.
- در مرحله دوم، Mask RCNN از ماسک دوتایی برای هر RoI استفاده میکند.
تحقیقات فعلی و چشمانداز آتی
بخشبندیِ Panoptic: مقالههای اخیر CVPR از مدل mask rcnn استفاده میکنند نتایج جدیدی درباره مجموعهدادههای پرکاربردی مثل City-Scapes بدست آورند.
Mesh Rcnn: جورجیا کیوکاری و همکارانش این سیستم بسیار دقیق را که برای پیشبینیِ شکل سهبعدی استفاده میشود، پیشنهاد کردند.