PEGASUS جدیدترین مدل خلاصه سازی انتزاعی گوگل
 تیم تحریریه
تیم تحریریه- ۱۸ اردیبهشت ۱۴۰۰
« PEGASUS: پیشآموزش با جملات استخراج شده برای خلاصه سازی انتزاعی »هوش مصنوعی گوگل این مقاله را پیشنهاد داده است. خلاصه سازی انتزاعی، مفهوم مهمی به شمار میآید. در مطلب حاضر میخواهیم مقالهای را بررسی کنیم که به تازگی منتشر شده است:
شاید بهترین راه برای سنجش هوش افراد، توانایی آنها در خلاصهسازی باشد.لیتون استریچی
PEGASUS: پیشآموزش با جملات استخراج شده برای خلاصه سازی انتزاعی
مدل PEGASUS مانند هر مدل تبدیل جمله sequence transduction دیگری از معماری seq2seq استفاده میکند. نوآوری این مدل در معیار پیشآموزش خودنظارتیش نهفته است. یادگیری خودنظارتی Self-Supervised Learning ابزار جدید و کارآمدی در یادگیری عمیق است. این نوع یادگیری ما را از وابستگی دادهها به نمونههای برچسبدار بینیاز میکند و باعث میشود حجم قابل ملاحظهای از دادههای بدون برچسب در فرایند آموزش در دسترس قرار گیرد. ترکیب مدلهای مبتنی بر Transformer با روش پیشآموزش خودنظارتی (مثل BERT، GPT-2، XLNet، ALBERT، T5 و ELECTRA) در مدلسازی زبان تاثیر بسزایی بر جای گذاشته است.
روش Gap Sentences Generation: هدف خودنظارتی برای خلاصه سازی

ایده اصلی روش فوق این است که هر قدر روش پیشآموزش خودنظارتی به هدف و وظیفه اصلی نزدیکتر باشد، تنظیم دقیق به شکل بهتری انجام خواهد شد. همان طور که در شکل ملاحظه میکنید، در مدل PEGASUS، جملات کامل از سند حذف میشوند و مدل برای پیشبینی این جملات آموزش داده میشود. البته محققان بر این باورند که این کار حتی توسط انسان تقریباً امکانناپذیر است. اما باید به این موضوع توجه داشت که این نوع آموزش باعث میشود درک بالاتری از تولید جملات به دست آوریم. این فرایند با عنوان Gap Sentences Generation یا به اختصار GSG نامیده میشود. افزون بر این، محققان اعلام کردهاند که گزینشِ مهمترین جملات از سند میتواند بسیار کارآمد باشد. در همین راستا، بر اساس معیار سنجش ROUGE باید به دنبال جملاتی بود که شباهت بالایی به متن کامل دارند. ROUGE معمولاً برای ارزیابی کیفیت خلاصه مورد استفاده قرار میگیرد.
مدل زبان ماسک شده (MLM)
اگر چه ایده اصلی PEGASUS یک GSG است، اما معماری اصلی آن از یک رمزگشا decoder و یک رمزگذار encoder تشکیل یافته است؛ از این رو، منطقی است که بخواهیم رمزگذار را در قالب مدل زبان ماسکشده پیشآموزش دهیم.

بر این اساس، واژهها را بطور تصادفی از توالی جدا کرده و از دیگر واژههای توالی برای پیشبینی واژههای ماسک شده استفاده میکنیم. طبق ایدهای که از مقالات گرفتهایم، 15 درصد از واژههای توالی به صورت تصادفی ماسک شدهاند و مدل هم برای پیشبینی این واژهها آموزش داده میشود.
آموزش ترکیبی
هر دو روشی که در بخشهای قبل در موردشان بحث شد، به کار گرفته میشوند. همچنین، Transformer به صورت ترکیبی آموزش داده میشود.
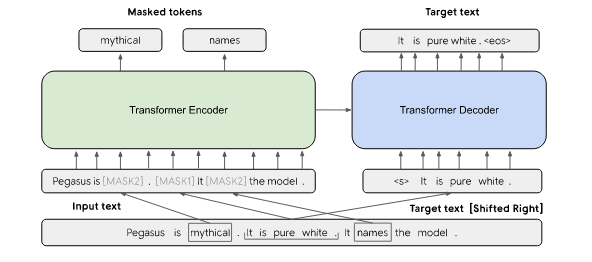
در مثال فوق هر دو روش MLM و GSG به صورت همزمان به عنوان اهداف پیش آموزش داده شده کار برده میشوند. در ابتدا، سه جمله وجود دارد. یکی از جملات با [MASK1] ماسک شده و به عنوان متن تولیدی هدف GSG استفاده میشود. دو جمله دیگر در ورودی باقی میمانند، اما برخی کلمات به صورت تصادفی توسط [MASK2] ماسک میشوند.
نتایج
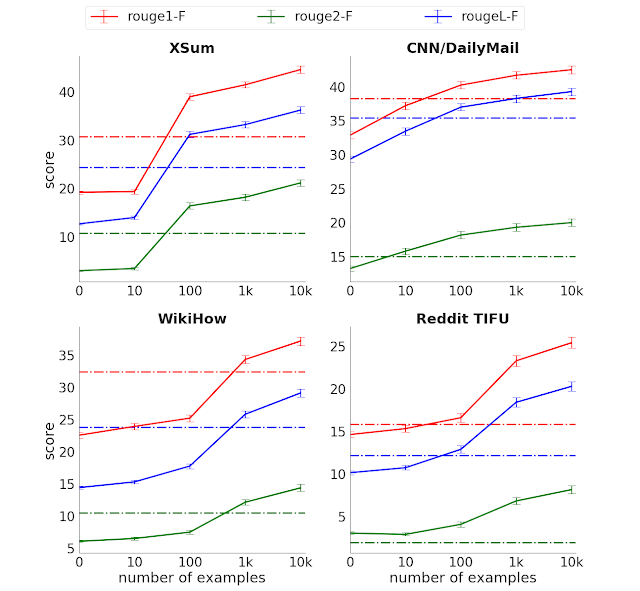
مدل بر روی 12 دیتاست خلاصه سازی انتزاعی عمومی به صورت دقیق تنظیم میشود. همانطور که ملاحظه میکنید پیشرفت قابل توجهی در این زمینه حاصل شده و آموزش با نمونههای بسیار کمتری انجام شده است.
تنطیم دقیق
خلاصهسازی توسط انسان
مدل PEGASUS در 3 دیتاست موفق شده به نتایجی همسنگ با انسان دست پیدا کند. فرایند ارزیابی با امتیازدهی به خلاصهسازی انسان و خلاصهسازی مدل انجام گردیده است. در این فرایند، اصلاً معلوم نیست که کارها توسط مدل خلاصه شدهاند یا توسط انسان. این آزمایش با سه دیتاست مختلف انجام شد. بر اساس نتایج، افرادی که به کارها امتیاز دادند، خلاصهسازی مدل را به انسان ترجیح دادند.
شمردن کشتیها
استفاده از مدل PEGASUS باعث شد نتیجه جالب دیگری هم حاصل آید. مقاله مربوط به دیتاست Xsum، نام چهار کشتی را پیشنهاد داد. این کشتیها عبارتند از HMS Cumberland، HMS Campbeltown، HMS Chatham و HMS Cornwall. مدل PEGASUS به درستی این مسئله را با عنوان «چهار فروند کشتی ناوگان سلطنتی» بررسی میکند، اگرچه اصلاً به عدد «چهار» در نمونه اشاره نمیشود. اگر 2 تا 5 نام وجود داشته باشد، مدل به درستی تعداد را خلاصه میکند. البته این مدل 6 کشتی را با 7 کشتی اشتباه گرفته بود. این نتیجه نشان میدهد که مدل فقط قادر است اسامی محدودی را در لیست خلاصه کند. حقیقت جالب اینکه مدل به نتایج بهتری نسبت به مدل اولیه مانند T5 دست یافت، این در حالی است که تنها از 5% از تعداد پارامترهای T5 را شامل میشود.
نتیجهگیری
در مقاله حاضر، جدیدترین مدل خلاصه سازی انتزاعی گوگل بررسی شد. همچنین ما نشان دادیم که پیش آموزشی که شبیه به وظیفه نهایی است چگونه کارایی مدل را در تنظیم دقیق افزایش میدهد. اکنون زمینه برای مدلسازیِ فعالیتهای پیشآموزش خودنظارتی فراهم شده است.