گوگل جما ۲ – مدل جدید گوگل
Gemma 2، جدیدترین LLM متنباز گوگل
تیم تحریریه
- ۲۱ تیر ۱۴۰۳
گوگل به تازگی Gemma 2 را به عنوان LLM متنباز خود منتشر کرده است. این مدل آخرین نسخه از پیشرفتهترین LLMهای متنباز به شمار میرود.
Gemma 2 آخرین نسخه از مدلهای زبان بزرگ متنباز گوگل است که در دو اندازه ۹میلیارد و ۲۷ میلیارد پارامتر با نسخههای پایه (از پیش آموزش داده شده) و تنظیم شده ارائه شده است. این نسخه بر اساس Google Deepmind Gemini ساخته شده است و از ۸۰۰۰ توکن پشتیبانی میکند و شامل موارد زیر میشود:
gemma-2-9b: مدل پایه ۹ میلیارد، 9B
gemma-2-9b-it: نسخه پیشرفته مدل پایه ۹ میلیارد، 9B
gemma-2-27b: مدل پایه ۲۷ میلیارد، 27B
gemma-2-27b-it: نسخه پیشرفته مدل پایه ۲۷ میلیارد، 27B
نسخه تازه منتشر شده بر اساس مجوز نسخه اولیه خود عرضه شده است که امکان توسعه بیشتر آن را فراهم میکند.
پیشرفتهای فنی در Gemma 2
علیرغم شباهت بسیار زیاد نسخه جدید با نسخه اولیه مانند پشتیبانی از بیش از ۸۰۰۰ توکن، این نسخه در برخی پارامترها در مقایسه با نسخه اولیه پیشرفتهایی داشتهاست. بر اساس پیشرفتهای جدید اتفاق افتاده در این نسخه، گوگل ادعا میکند که این نسخه توانایی رقابت با مدلهای دوبرابر بزرگتر از خود را دارد.
برخی از ویژگیهای این نسخه عبارتند از:
1- برخورداری از ویژگی Logit soft-capping: این ویژگی باعث میشود تا بدون قطع کردن لجیتها از رشد بیش از حد آنها، جلوگیری شود که این امر به بهبود آموزش کمک میکند.
2- تقطیر دانش: این روش، یک روش بسیار پرطرفدار و محبوب برای آموزش یک مدل کوچک با استفاده از یک مدل بزرگتر است که برای بهبود عملکرد مدلهای یادگیری عمیق استفاده میشود. بر اساس آنچه گوگل بیان کرده است این شرکت از تقطیر دانش برای پیشآموزش مدل 9B استفاده کرده است.
3- ترکیب دو یا چند LLM با یکدیگر در یک مدل: این روش که شامل ادغام دو یا چند LLM در یک مدل جدید است، در نسخه جدید Gemma با استفاده از روش Warp به انجام رسیده است. در این روش فرآیند ادغام طی سه مرحله، میانگین متحرک نمایی (EMA)، درونیابی خطی-کروی (SLERP) و درونیابی خطی به سمت مقداردهی اولیه (LITI) صورت میگیرد.
4- استفاده از قابلیت پنجره کشویی: روش پنجره کشویی به عنوان یکی از روشهای کاهش حافظه و زمان مورد نیاز در محاسبات توجه (attention computations) در مدلهای ترنسفورمر به شمار میرود که در مدلهایی مانند میسترال استفاده میشود. گوگل اعلام کرده است که از این روش در مدل جدید Gemma استفاده شده است. این امر باعث میشود تا کیفیت کارایی این مدل در مقایسه با مدل گذشته افزایش یابد.
آموزشهای اولیه در این مدل با استفاده از JAX و ML صورت گرفته است. این مدل به منظور استفاده در کاربردهای مختلف مبتنی بر تعامل و گفتگو بهینهسازی شده است. به عبارت بهتر میتوان گفت جهت گیری مدل بیشتر به سمت قابلیتهای مکالمه و ادغام مدل با استفاده از WARP برای بهبود عملکرد کلی است.
ارزیابی Gemma 2
برای ارزیابی عملکرد Gemma 2 در مقایسه با سایر مدلهای متنباز، در جدول زیر این مدل به لحاظ فنی با سایر مدلهای متنباز مقایسه شده است. نکته قابل توجه در درمورد این مقایسه آن است که مدلهای زبان بزرگ و زبان کوچک به تفکیک با یکدیگر مقایسه شدهاند که به ترتیب در جدول 1 و 2 ارائه شدهاند.
(جدول 1)
| Llama 3 (70B) | Qwen 1.5 (32B) | Gemma 2 (27B) | |
| MMLU | 79.2 | 74.3 | 75.2 |
| GSM8K | 76.9 | 61.1 | 75.1 |
| ARC-c | 68.8 | 63.6 | 71.4 |
| HellaSwag | 88.0 | 85.0 | 86.4 |
| Winogrande | 85.3 | 81.5 | 83.7 |
(جدول 2)
| Benchmark | Mistral (7B) | Llama 3 (8B) | Gemma (8B) | Gemma 2 (9B) |
| MMLU | 62.5 | 66.6 | 64.4 | 71.3 |
| GSM8K | 34.5 | 45.7 | 50.9 | 62.3 |
| ARC-C | 60.5 | 59.2 | 61.1 | 68.4 |
| HellaSwag | 83.0 | 82.0 | 82.3 | 81.9 |
| Winogrande | 78.5 | 78.5 | 79.0 | 80.6 |
دسترسی سریع به Gemma 2
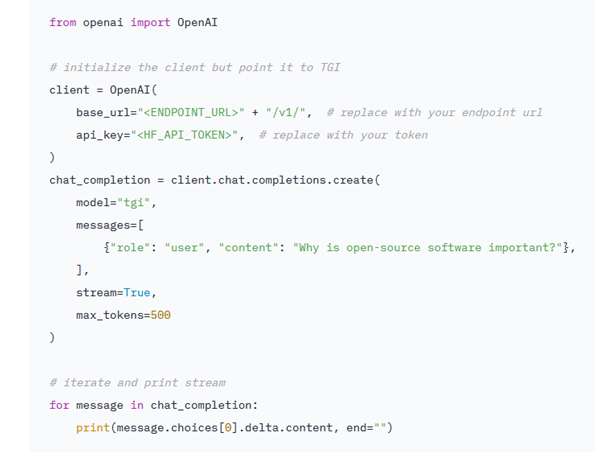
برخلاف آنکه مدلهای اولیه و پایه هیچگونه راه دسترسی سریعی ندارند نسخههای instruct از ساختار مکالمهای بسیار سادهای مانند آنچه در تصویر زیر میبینید برخوردارند.

لینک نسخه دمو و آزمایشی مدل Gemma 27B Instruct در حال حاضر در دسترس است و میتوانید با کلیک روی لینک زیر به صفحه مربوطه منتقل شده و از آن استفاده کنید.
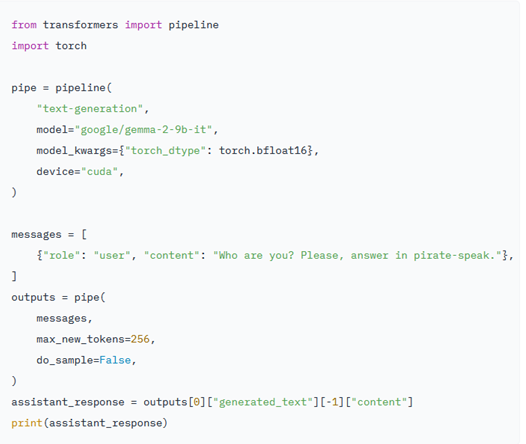
استفاده از Gemma 2 با استفاده از ترنسفورمر Hugging Face
برای استفاده از Gemma میبایست از آخرین نسخه ترنسفورمر یعنی نسخه (4.42) استفاده کرد تا تمام امکانات محیط Hugging Face برای شما قابل دسترس باشد.
تصویر زیر روش استفاده از gemma-2-9b-it را به کمک ترنسفورمرها نشان میدهد. برای استفاده از این سیستم به حدود ۱۸ گیگابایت RAM نیاز دارید. در حالی که برای اجرای gemma-2-27b-it به حافظهای نزدیک به ۵۶ گیگابایت RAM نیاز است. نکته جالب توجه آن است که میتوان میزان حافظه را با تغییر از حالت ۸ بیتی به حالت ۴ بیتی، کاهش داد.
برای تغییر از حالت ۸ بیتی به حالت ۴ بیتی به روش زیر عمل کنید. این کار باعث میشود تا حافظهی مورد نیاز برای نسخه 27B از ۵۴ به ۱۸ گیگابایت کاهش یابد.

ادغام با Inference Endpoints
برای ادغام و ترکیب کردن مدل Gemma 2 با Inference Endpoints هاگینگ فیس یا نقاط پایانی Hugging Face ، میتوانید از Text Generation Inference استفاده کنید. ابزار Text Generation Inference یک بستر آماده برای تولید است که توسط Hugging Face توسعه یافته است و امکان ادغام مدلهای زبان بزرگ را فراهم میکند.
برای ادغام مدلGemma 2، به صفحه مدل بروید و روی ویجت Deploy→ Inference Endpoints کلیک کنید. با توجه به اینکه Inference Endpoints از API پیامهای سازگار با OpenAI پشتیبانی میکند، به شما این امکان را میدهد تا به سادگی با تغییر URL آن را از مدل بسته به مدل باز تغییر دهید.