پارسبنچ: ابزاری نوین برای ارزیابی مدلهای بزرگ زبانی فارسی
پریسا سلامتی
- ۲۸ مرداد ۱۴۰۳
«شهریار شریعتی»، برنامهنویس و محقق حوزه هوش مصنوعی با بیش از ده سال تجربه، پروژهای به نام «پارسبنچ» را راهاندازی کرده است. این ابزار باز متن (open source)، برای ارزیابی عملکرد مدلهای زبان بزرگ (LLM) در وظایفی مانند ترجمه، درک مطلب و تحلیل، با تمرکز ویژه بر زبان فارسی طراحی شده و هدف آن تقویت مدلهای زبان فارسی و توسعه هوش مصنوعی در این زمینه است.
شروع علاقهمندی و ورود به برنامهنویسی
شهریار شریعتی از حدود ده سالگی به برنامهنویسی علاقهمند شد. او در ابتدا با توسعه اپلیکیشنهای موبایل و دسکتاپ کار خود را آغاز کرد و به تدریج در این مسیر رشد کرد. او میگوید: «تقریباً از ده سالگی شروع کردم و تا الان که بیش از ده سال است در این حوزه فعال هستم. با زبانهای مختلف برنامهنویسی کار کردهام و کارم را با توسعه اپلیکیشنهای موبایل و دسکتاپ آغاز کردم. اما به تدریج وارد حوزههای دیگری همچون هوش مصنوعی شدم.»
او با ورود به دوران دبیرستان، علاقهمندیاش به هوش مصنوعی را کشف کرد و با آغاز تحصیل در رشته علوم کامپیوتر در دانشگاه، این علاقه را جدیتر دنبال کرد. او به تدریج به سمت پردازش زبان طبیعی (NLP) کشیده شد و از همان زمان شروع به کار و تحقیق در این حوزه کرد.
علاقهمندی به پردازش زبان طبیعی و کار بر روی مدلهای زبان
شریعتی در ادامه توضیح میدهد که چرا به پردازش زبان طبیعی (NLP) علاقهمند شد و چگونه این علاقه به پروژههای اخیرش منجر شد. او میگوید:« من از اوایل دوران دبیرستان به هوش مصنوعی علاقهمند شدم و به تدریج به سمت NLP گرایش پیدا کردم. اخیراً هم به مدلهای زبان بزرگ (LLM) علاقهمند شدم و حدود یک سال است که در این حوزه تحقیق و کار میکنم.»
او توضیح میدهد که تجربه کاریاش در این زمینه باعث شد علاقهاش به تحقیقات و توسعه مدلهای زبان بیشتر شود و در نهایت به پروژههایی مانند توسعه ابزارهای سنجش عملکرد مدلهای زبان، بهویژه برای زبان فارسی، کشیده شود.
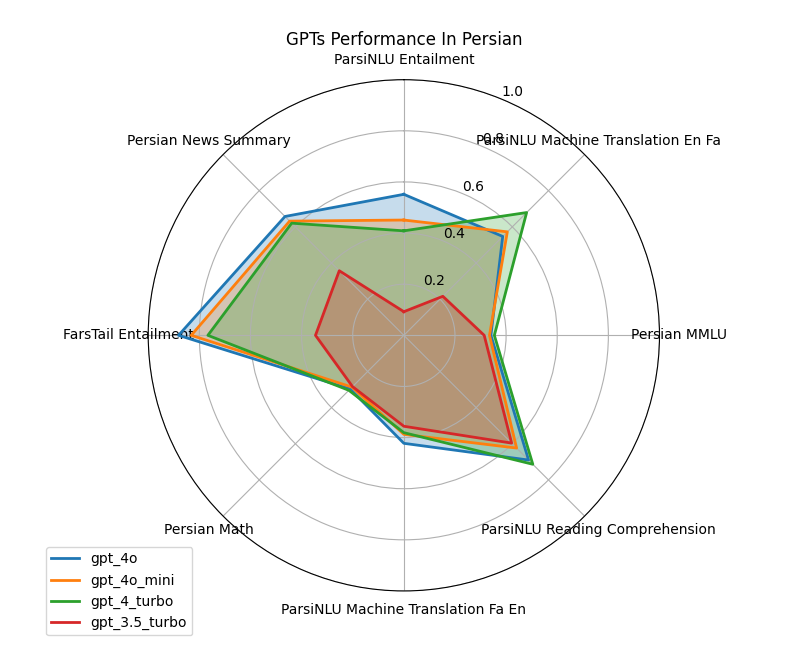
توسعه ابزار پارسبنچ (Pars-Bench) و هدف از آن
یکی از پروژههای مهم شهریار شریعتی، توسعه ابزار پارسبنچ است که هدف آن ارزیابی مدلهای زبان بزرگ (LLM) در وظایف مختلف است. او در این باره گفت:« کاری که ما در پارسبنچ انجام دادیم، توسعه یک ابزار بود که مدلهای زبانی، بهخصوص LLMها، را در وظایف مختلف میسنجد. این وظایف شامل انجام سوالات ریاضی، ترجمه ماشینی، درک مطلب، استدلال و تحلیل هستند.»
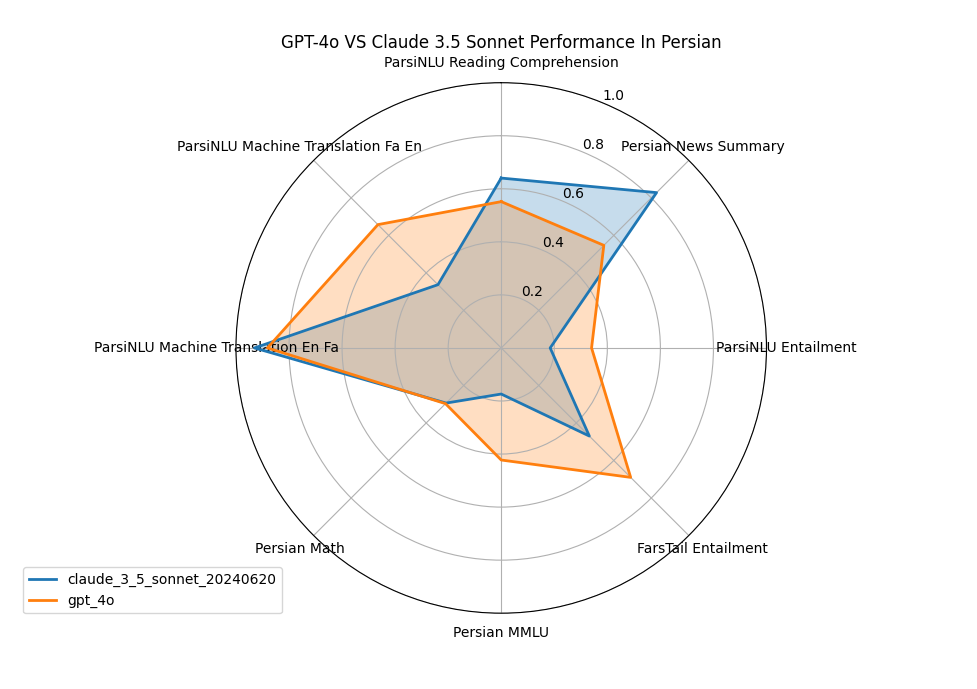
هدف از توسعه این ابزار، کمک به شرکتها، استارتاپها و حتی افراد معمولی است تا بتوانند بر اساس نیاز خود، بهترین مدل زبانی را انتخاب کنند. شریعتی میگوید:« این ابزار به افراد کمک میکند تا بتوانند تصمیم بگیرند که کدام مدل زبانی برای کار خاص آنها مناسبتر است. بهعنوان مثال، اگر فردی بخواهد یک دستیار صوتی یا متنی برای دانشآموزان توسعه دهد، باید مدلی را انتخاب کند که در موضوعات درسی دبیرستانی خوب عمل کند.»
انگیزه ورود به حوزه زبان فارسی
شهریار شریعتی درباره انگیزهاش برای تمرکز بر روی زبان فارسی در این پروژه توضیح میدهد:« یکی از مشکلاتی که هنگام کار با مدلهای آزاد و بزرگ زبانی مثل GPT-3 یا BERT وجود دارد، این است که اکثر این مدلها برای زبان انگلیسی بهینهسازی شدهاند. وقتی به زبانهای دیگر مثل فارسی میرسیم، عملکرد آنها ممکن است خیلی خوب نباشد. این بود که من به این فکر افتادم که برای زبان فارسی نیز یک ابزار ارزیابی دقیق و قابل اعتماد توسعه دهم.»
چالشهای فنی و مسیر توسعه پروژه
شریعتی در توضیح بیشتر درباره چالشهای فنی میگوید:« ما برای توسعه این ابزار، از مدلها و کارهایی که در سطح جهانی انجام شده الگوبرداری کردیم. به عنوان مثال، ابزارهایی مثل OpenAI’s Benchmark و Leaderboards که برای زبان انگلیسی توسعه داده شدهاند. با این حال، چون این مدلها بهطور عمده برای زبان انگلیسی طراحی شدهاند، ما مجبور شدیم بسیاری از آنها را برای زبان فارسی سفارشیسازی کنیم.»
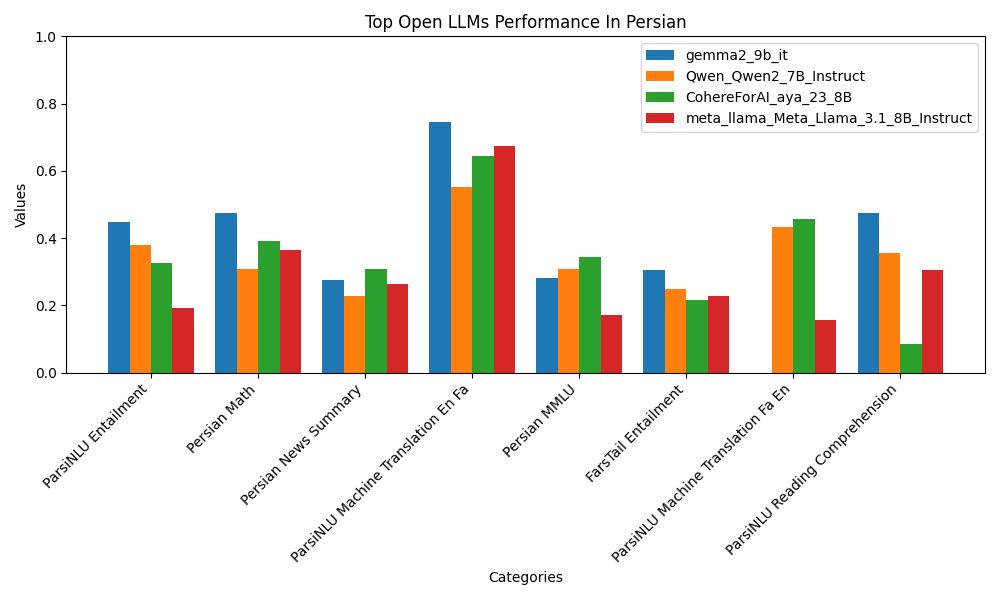
یکی از مشکلات عمدهای که او و تیمش با آن مواجه بودند، نبود منابع و دادههای مناسب برای زبان فارسی بود. او افزود:« بسیاری از کارهای مشابهی که در سطح جهانی انجام شدهاند، بر روی زبان انگلیسی تمرکز دارند و زبانهای دیگری مثل فارسی در آنها به خوبی پوشش داده نشدهاند. این باعث شد که ما مجبور شویم خودمان دادهها و ابزارهای مناسبی را برای زبان فارسی توسعه دهیم.»
روش ارزیابی مدلها در پارسبنچ
او توضیح میدهد که روش ارزیابی مدلها در پارسبنچ چگونه کار میکند:« ما در پارسبنچ از روشهای ارزیابی خودکار (Automation) استفاده میکنیم. به این صورت که مدلهای مختلف را در وظایف مختلف مثل ترجمه، درک مطلب و استدلال تست میکنیم. به عنوان مثال، ما سوالات چهارگزینهای به مدلها میدهیم و آنها باید پاسخ صحیح را انتخاب کنند. سپس براساس تعداد پاسخهای صحیح، مدلها ارزیابی و امتیازدهی میشوند.»
شریعتی همچنین تأکید میکند که تمامی ابزارها و دادههایی که در این پروژه استفاده میشوند بهصورت اوپنسورس در دسترس عموم قرار دارند تا افراد و شرکتها بتوانند از آنها استفاده کنند و خودشان مدلهایشان را ارزیابی کنند.
مسیر بازاریابی و گسترش پروژه
با توجه به اینکه پروژه پارسبنچ بهصورت اوپنسورس عرضه شده است، شهریار درباره روشهای بازاریابی و گسترش آن توضیح میدهد: “در پروژههای اوپنسورس معمولاً بحث مارکتینگ خیلی گسترده نیست، چرا که بیشتر کار بهصورت داوطلبانه و توسط کامیونیتی انجام میشود. تا به حال، ما بیشتر از طریق شبکههای اجتماعی و ارتباط با افراد مطرح در این حوزه پروژه را معرفی کردهایم و خوشبختانه استقبال خوبی هم از آن شده است.”
او اشاره میکند که یکی از اهداف اصلی این پروژه، تقویت جامعه اوپنسورس و تحقیقاتی فارسی است تا شرکتها و دانشگاهها تشویق شوند که مدلهای زبانی خود را با استفاده از این ابزار ارزیابی کنند و نتایج را بهصورت عمومی منتشر کنند.
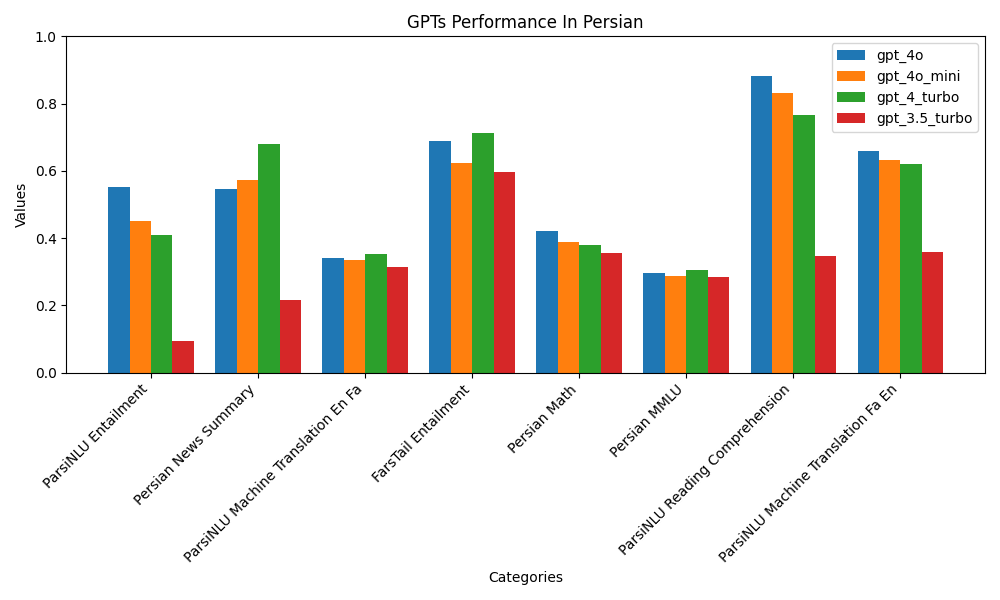
برنامههای آینده و ادامه راه
شهریار شریعتی در پایان به برنامههای آیندهاش اشاره میکند و میگوید:«ما قصد داریم که پارسبنچ را گسترش دهیم و با همکاری دانشگاهها و شرکتها، دادههای بهتری برای ارزیابی مدلها جمعآوری کنیم. همچنین به دنبال توسعه ابزارهای پیشرفتهتری هستیم که بتوانند عملکرد مدلها را در وظایف پیچیدهتر نیز ارزیابی کنند.»
او همچنین اضافه میکند که مکاتباتی با دانشگاههای مختلف و شرکتها انجام داده است تا از حمایت آنها برای ادامه توسعه پروژه برخوردار شود. شریعتی در اینباره در حال حاضر با دانشگاههای مختلفی مثل امیرکبیر، شریف و علم و صنعت در حال مکالمه هستم و امیدواریم که این همکاریها به ما کمک کنند تا ابزارهای بهتری برای ارزیابی مدلهای زبان فارسی توسعه دهیم.»
درمجموع، این ابزار برای کمک به شرکتها و محققان در ارزیابی مدلهای زبان و انتخاب بهترین مدل برای وظایف خاص طراحی شده و بهصورت اوپنسورس عرضه شده است. شریعتی بهدنبال گسترش این پروژه با همکاری دانشگاهها و شرکتهای ایرانی است تا دادههای بهتری جمعآوری و ابزارهای پیشرفتهتری توسعه دهد.
علاقهمندان میتوانند برای مشاهده لیدربرد عملکرد مدلهای زبانی در فارسی به این آدرس مراجعه کنند.