
تفکر یا پردازش؟ جدال بر سر هوش مصنوعی o1
 تیم تحریریه
تیم تحریریه- ۲۰ مهر ۱۴۰۳
مدل جدید OpenAI با نام «o1» به تازگی منتشر شده و ادعا میکند که قادر به «استدلال» و حتی «تفکر» است، اما این ادعا با شک و تردید مواجه شده است.
شک میکنم پس هستم
افراد سرشناسی مانند «گری مارکوس» که از بزرگترین منتقدان این حوزه است، به همراه «کلِم دلانگ»، مدیرعامل هاگینفیس (Hugging Face)، این ادعا را به چالش کشیدهاند. کلم دلانگ در خصوص نحوه تصویرسازی نادرست OpenAI از تواناییهای این مدل جدید میگوید: «یک سیستم هوش مصنوعی در حال «تفکر» نیست، بلکه در حال «پردازش» و «اجرای پیشبینیها» است، درست مانند یک موتور جستجو یا کامپیوتر.» او اضافه میکند: «ایجاد این تصور که سیستمهای فناوری مانند انسانها عمل میکنند، نوعی فریب بازاریابی است که شما را به اشتباه میاندازد تا تصور کنید این سیستمها هوشمندتر از چیزی هستند که واقعاً هستند.»
از سوی دیگر، این سؤال مطرح میشود که آیا واقعاً این همان چیزی نیست که به آن «تفکر» میگوییم؟ «فیلیپ رودز»، به این پرسش چنین پاسخ میدهد: «مغز انسانها هم در حال «تفکر» نیستند، بلکه در حال اجرای عملیات پیچیده بیوشیمیایی و بیوالکتریکی در مقیاس گسترده هستند.»
o1 چگونه فکر میکند؟
سم آلتمن، مدیرعامل OpenAI، عرضۀ این مدل را «آغاز پارادایمی جدید و هوش مصنوعی که میتواند استدلال پیچیدۀ عمومی انجام دهد» توصیف میکند. برخلاف مدلهای قبلی که به محض دریافت دستور شروع به تولید متن میکردند، مدل o1 قبل از پاسخدهی به سؤالات مدتی «فکر» میکند تا استدلالهای پیچیدهتری ارائه دهد. این ویژگی باعث میشود استفاده از این مدل برای حل مسائل پیچیده، بهویژه در سطوح علمی بالا مانند دکترا، مناسبتر باشد. توانایی این مدل در استدلال پیچیده نه تنها در برنامهنویسی و ریاضیات، بلکه در سایر زمینهها نیز به چشم میخورد. آلتمن این قابلیتها را بهعنوان مرحلهای جدید در توسعۀ هوش مصنوعی معرفی کرده بود و اکنون به نظر میرسد که این ادعاها در حال تحققاند.
طبق گزارش وبلاگ «یادگیری استدلال با LLMها»، الگوریتم یادگیری تقویتی OpenAI به مدل کمک میکند تا فرآیند «تفکر» خود را بهبود بخشد و بتواند مسائل را مؤثرتر حل کند. با گذشت زمان، عملکرد مدل o1 بهبود پیدا میکند، زیرا آموزش آن به طور مداوم ادامه مییابد. این روش با شیوههای سنتی که بر افزایش حجم مدلها تمرکز دارند، تفاوت دارد و بر تقویت مهارتهای استدلال در یک مدل کوچک تمرکز میکند.

مدل o1 با استفاده از یادگیری تقویتی، مسائل پیچیده را تحلیل کرده، اشتباهات خود را اصلاح میکند و روشهای جدیدی را امتحان میکند. این فرآیند به o1 کمک میکند تا با سؤالات دشوار بهتر مقابله کند؛ چرا که این مدل تنها پیشبینی کلمه بعدی را انجام نمیدهد، بلکه میتواند به عقب بازگردد و «تفکر» کند.
یکی از چالشهای بزرگ این است که کاربران نمیتوانند ببینند این مدل چگونه فکر میکند، حتی اگر بخواهند هزینهای برای درک نحوۀ استدلال آن پرداخت کنند. هزینههایی که برای دسترسی به این اطلاعات پرداخت میشود، «توکنهای استدلال» نام دارد. بهعبارتدیگر، کاربران حتی در صورت پرداخت هزینه نیز نمیتوانند نحوه دستیابی مدل به پاسخها را به طور دقیق مشاهده کنند.
مدل o1: چگونه «تفکر» میکند؟
مدل o1 به طور خاص طراحی شده است تا اطلاعات پنهان خود را نشان ندهد. این کار از طریق «توکنهای استدلال» انجام میشود. در واقع، o1 نمیتواند فریب بخورد و قادر به ارائه پاسخهای مرحلهبهمرحله نیست.
OpenAI توضیح داده است که پنهانکردن مراحل استدلال به دلایل مهمی صورت میگیرد. اولاً، این اقدام برای ایمنی و رعایت قوانین ضروری است؛ زیرا مدل نیاز دارد بدون نمایش مراحل حساس، اطلاعات را پردازش کند. ثانیاً، این کار به OpenAI اجازه میدهد تا از مزیت رقابتی خود محافظت کند و مانع از استفادۀ دیگر مدلها از فرآیندهای استدلالی آنها شود. بهاینترتیب، OpenAI میتواند بر الگوهای تفکر مدل نظارت داشته باشد، بدون اینکه مستقیماً در استدلال داخلی آن دخالت کند.
این مدل برای همه مناسب نیست و تمرکز آن بر روی استدلال است. «جف فن»، یکی از کارشناسان این حوزه، مدل «استروبری» یا o1 را روشی جدید در کار با هوش مصنوعی معرفی میکند. او میگوید: «این مدل، به جای اینکه فقط اطلاعات را یاد بگیرد، تلاش میکند در زمان پاسخ به سؤالات بهتر فکر کند.»
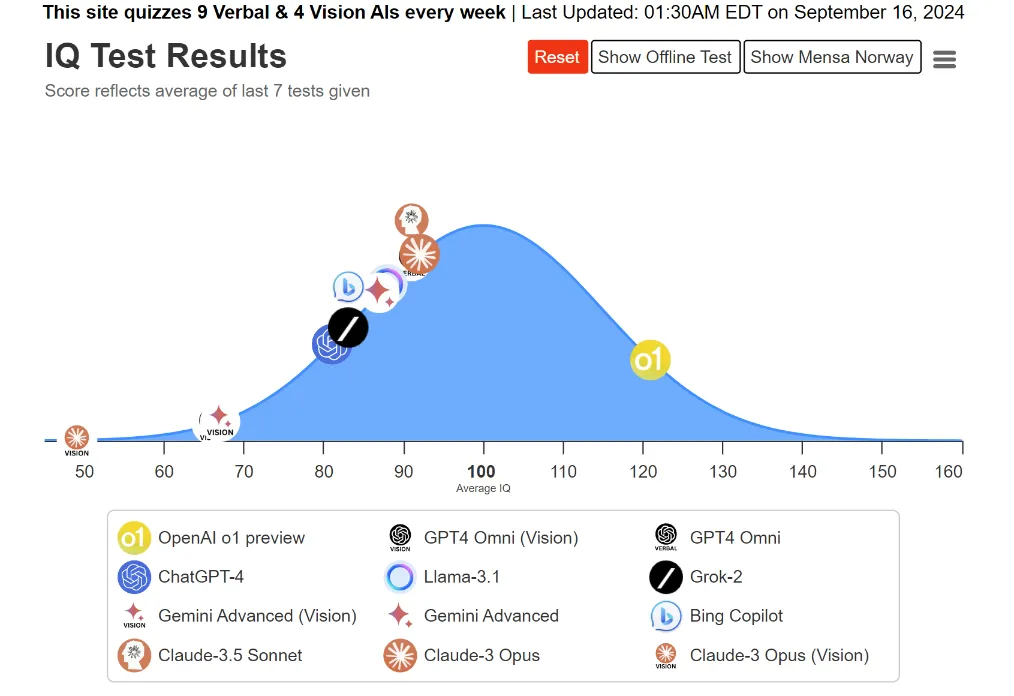
استدلال بدون نیاز به مدلهای بزرگ
استدلال نیازی به مدلهای بسیار بزرگ ندارد. امروزه بخشهایی از مدلها تنها برای ذخیرهسازی اطلاعات ساده استفاده میشوند. اما میتوان از یک بخش کوچکتر به نام «هسته استدلال» استفاده کرد که با ابزارهای دیگر مانند مرورگرها یا برنامههای بررسی کد همکاری میکند. بهاینترتیب، مدل میتواند بدون نیاز به بزرگشدن، سریعتر و کارآمدتر فکر کند.
این روش نیاز به حجم زیاد محاسبات برای آموزش اولیه را کاهش میدهد و در عوض بیشتر توان محاسباتی به زمان پاسخدهی مدل اختصاص مییابد، نه به زمانی که قبل یا بعد از آموزش صرف میشود. مدلهای زبان بزرگ (LLM) مانند AlphaGo نیز از رویکردهای مشابه استفاده میکنند تا به بهترین راهحلها دست یابند و با گذشت زمان، این روش کمک میکند که مدلها به بهینهترین پاسخها برسند.
چالشهای پیش روی مدل o1
«سببارو کامبهمپاتی» در یکی از پستهای خود توضیح داده که اطلاعات دقیقی دربارۀ چگونگی عملکرد مدل o1 ندارد؛ اما حدس میزند که این مدل چه کارهایی انجام میدهد. او اضافه میکند که پست او نکتۀ جدیدی را فاش نمیکند و تنها به استفاده از زبان برنامهنویسی پایتون در این مدل اشاره دارد.
OpenAI احتمالاً زودتر از دیگران به اهمیت مقیاسگذاری در زمان استنتاج پی برده است؛ درحالیکه تحقیقات علمی بهتازگی به این موضوع پرداختهاند. اگرچه o1 در آزمایشها نتایج خوبی ارائه میدهد؛ اما استفاده از آن برای کارهای استدلالی واقعی با چالشهایی همراه است. مواردی مانند زمان توقف جستوجو، نحوه تعریف عملکردهای پاداش و چگونگی مدیریت هزینههای محاسباتی برای کارهایی مانند تفسیر کد، همچنان به بررسی نیاز دارند تا بتوانیم از این مدل در موقعیتهای بیشتر و پیچیدهتر استفاده کنیم.

پاداشدهی و بهبود عملکرد o1
مدل o1 شبیه به یک چرخدنده عمل میکند. وقتی o1 پاسخهای درستی ارائه میدهد، این پاسخها بهعنوان دادههای آموزشی استفاده میشوند. اگر پاسخ درست باشد، مدل پاداش مثبتی دریافت میکند و اگر نادرست باشد، پاداش منفی میگیرد. این فرایند به o1 کمک میکند تا در طول زمان تفکر بهتری داشته باشد. این رویکرد شبیه به روش AlphaGo است که توانست با استفاده از دادههای خود عملکرد بهتری از خود نشان دهد و در نهایت دادههای باارزشتری تولید کند.
به همین دلیل، اگر مدت بیشتری با ChatGPT تعامل داشته باشید، احتمالاً با گذشت زمان پاسخهای دقیقتری دریافت خواهید کرد. به نظر میرسد OpenAI بیش از سرعت پاسخدهی، بر روی کیفیت پاسخها تمرکز دارد.





