
Qwen 2.5 Max در برابر DeepSeek V3
تیم تحریریه
- ۱۶ اسفند ۱۴۰۳
علیبابا بهتازگی مدل هوش مصنوعی جدید خود یعنی Qwen2.5-Max را منتشر کرده است که پیشرفتهترین مدل این شرکت تاکنون محسوب میشود. این مدل برخلاف DeepSeek R1 یا o1 شرکت OpenAI، یک مدل استدلالی نیست، به این معنا که نمیتوان فرآیند تفکر آن را مشاهده کرد.
بهتر است Qwen2.5-Max را یک مدل عمومی و رقیبی برای GPT-4o، Claude 3.5 Sonnet و DeepSeek V3 در نظر بگیریم. در این مقاله، بررسی خواهیم کرد که Qwen2.5-Max چیست، چگونه توسعه یافته، در مقایسه با رقبا چه عملکردی دارد و چگونه میتوان به آن دسترسی پیدا کرد.
Qwen2.5-Max چیست؟
Qwen2.5-Max قدرتمندترین مدل هوش مصنوعی علیبابا تا به امروز است که برای رقابت با مدلهای سطح بالایی مانند GPT-4o، Claude 3.5 Sonnet و DeepSeek V3 طراحی شده است.
علیبابا که یکی از بزرگترین شرکتهای فناوری در چین محسوب میشود، بیشتر به خاطر پلتفرمهای تجارت الکترونیک خود شناخته شده است، اما در حوزه رایانش ابری و هوش مصنوعی نیز حضور قدرتمندی دارد. سری Qwen بخشی از اکوسیستم گستردهتر هوش مصنوعی این شرکت است که شامل مدلهایی از نسخههای کوچک و متنباز تا سیستمهای مقیاس بزرگ و انحصاری میشود.
برخلاف برخی از مدلهای قبلی Qwen، مدل Qwen2.5-Max متنباز نیست، به این معنا که وزنهای آن بهصورت عمومی در دسترس قرار ندارند.
Qwen2.5-Max با استفاده از 20 تریلیون توکن آموزش داده شده و دارای پایگاه دانش گسترده و قابلیتهای هوش مصنوعی عمومی قدرتمندی است. با این حال، این مدل یک مدل استدلالی نیست، به این معنا که برخلاف مدلهایی مانند DeepSeek R1 یا o1 شرکت OpenAI فرآیند تفکر خود را بهطور شفاف نشان نمیدهد.
باتوجهبه گسترش روزافزون فعالیتهای علیبابا در حوزه هوش مصنوعی، احتمال دارد که در آینده شاهد یک مدل استدلالی اختصاصی (شاید در قالب Qwen-3) از این شرکت باشیم.

Qwen2.5-Max چگونه کار میکند؟
Qwen2.5-Max از معماری MoE (Mixture-of-Experts) استفاده میکند، روشی که در DeepSeek V3 نیز بهکار گرفته شده است. این تکنیک باعث میشود که مدل در مقیاسهای بالا عمل کند و درعینحال هزینههای محاسباتی را در سطح معقولی نگه دارد. بیایید این مفهوم را به زبان ساده بررسی کنیم.
معماری MoE
برخلاف مدلهای سنتی هوش مصنوعی که از تمام پارامترهای خود برای هر وظیفه استفاده میکنند، مدلهای MoE مانند Qwen2.5-Max و DeepSeek V3 تنها بخشهای مرتبط با هر وظیفه را فعال میکنند.
میتوان این روش را به یک تیم از متخصصان تشبیه کرد، اگر شما سوالی پیچیده درباره فیزیک بپرسید، فقط متخصصان فیزیک پاسخ خواهند داد، درحالیکه بقیه تیم غیرفعال باقی میمانند. این فعالسازی انتخابی باعث میشود که مدل بتواند پردازشهای مقیاس بزرگ را بهطور موثرتری انجام دهد، بدون اینکه به توان محاسباتی بیش از حد نیاز داشته باشد.
این روش باعث میشود که Qwen2.5-Max هم قدرتمند باشد و هم قابلیت مقیاسپذیری بالایی داشته باشد. همچنین، به آن اجازه میدهد که با مدلهای متراکم (Dense Models) مانند GPT-4o و Claude 3.5 Sonnet رقابت کند، درحالیکه از نظر مصرف منابع، بهینهتر عمل میکند. مدلهای متراکم مدلهایی هستند که تمام پارامترهای خود را برای هر ورودی فعال میکنند.
آموزش و تنظیم دقیق
Qwen2.5-Max با استفاده از 20 تریلیون توکن آموزش داده شده است که طیف وسیعی از موضوعات، زبانها و زمینهها را پوشش میدهد.
برای درک بهتر 20 تریلیون توکن باید بدانید که این مقدار تقریباً معادل 15 تریلیون کلمه است، رقمی چنان عظیم که تصور آن دشوار است. برای مقایسه، کتاب 1984 نوشته جورج اورول حدود 89,000 کلمه دارد، به این معنا که Qwen2.5-Max بر روی معادل 168 میلیون نسخه از این کتاب آموزش دیده است!
البته داشتن حجم عظیمی از دادههای آموزشی بهتنهایی تضمینکننده کیفیت بالای یک مدل هوش مصنوعی نیست. به همین دلیل، علیبابا مدل را با روشهای زیر بهینهسازی کرده است:
- تنظیم دقیق تحت نظارت (Supervised Fine-Tuning – SFT): تیمی از متخصصان انسانی پاسخهای باکیفیتی ارائه دادهاند تا مدل را در تولید خروجیهای دقیقتر و مفیدتر راهنمایی کنند.
- یادگیری تقویتی با بازخورد انسانی (Reinforcement Learning from Human Feedback – RLHF): این روش باعث میشود که پاسخهای مدل همسو با ترجیحات انسانی باشند و نتایج طبیعیتر و متناسب با زمینه گفتگو ارائه شوند.
معیارهای ارزیابی Qwen2.5-Max
Qwen2.5-Max برای سنجش قابلیتهای خود در انجام وظایف مختلف، با دیگر مدلهای برتر هوش مصنوعی مقایسه شده است. این ارزیابیها شامل مدلهای دستورپذیر (Instruct Models) که برای وظایفی مانند مکالمه و برنامهنویسی بهینه شدهاند و مدلهای پایه (Base Models) که نسخه خام و آموزشدیده قبل از تنظیم دقیق هستند، میشود. درک این تفاوت به تفسیر بهتر نتایج کمک میکند.
ارزیابی مدلهای دستورپذیر
مدلهای دستورپذیر برای کاربردهای دنیای واقعی مانند مکالمه، کدنویسی و وظایف دانش عمومی تنظیم دقیق شدهاند. در این بخش، Qwen2.5-Max با GPT-4o، Claude 3.5 Sonnet، Llama 3.1-405B و DeepSeek V3 مقایسه شده است. نتایج کلیدی این مقایسه عبارتند از:
- Arena-Hard (معیار ترجیح انسانی): Qwen2.5-Max با امتیاز 89.4 از DeepSeek V3 با 85.5 امتیاز و Claude 3.5 Sonnet با 85.2 امتیاز پیشی گرفته است. این معیار میزان ترجیح پاسخهای مدل توسط انسان را ارزیابی میکند.
- MMLU-Pro (دانش و استدلال): امتیاز Qwen2.5-Max در این بخش 76.1 است که کمی بالاتر از DeepSeek V3 75.9 ولی پایینتر از Claude 3.5 Sonnet با 78.0 امتیاز و GPT-4o با امتیاز 77.0 قرار دارد.
- GPQA-Diamond (سوالات دانش عمومی): امتیاز Qwen2.5-Max برابر 60.1 بود که از DeepSeek V3 59.1 امتیاز جلوتر است، اما Claude 3.5 Sonnet با امتیاز 65.0 پیشتاز است.
- LiveCodeBench (توانایی کدنویسی): امتیاز Qwen2.5-Max برابر 38.7 است که تقریباً برابر با DeepSeek V3 با امتیاز 37.6 است اما پایینتر از Claude 3.5 Sonnet با امتیاز 38.9 قرار دارد.
- LiveBench (تواناییهای کلی): Qwen2.5-Max با امتیاز 62.2 پیشتاز است و از DeepSeek V3 با امتیاز 60.5 است و Claude 3.5 Sonnet با امتیاز 60.3 پیشی گرفته است. این آمار نشاندهنده عملکرد گسترده آن در وظایف هوش مصنوعی دنیای واقعی است.

بهطور کلی، Qwen2.5-Max یک مدل هوش مصنوعی همهجانبه است که در وظایف مبتنی بر ترجیح انسانی و تواناییهای عمومی عملکرد بالایی دارد، درحالیکه در دانش عمومی و برنامهنویسی نیز رقابت نزدیکی با بهترین مدلها دارد.
ارزیابی مدلهای پایه
ازآنجاییکه GPT-4o و Claude 3.5 Sonnet مدلهای اختصاصی هستند و نسخه پایه آنها عمومی نیست، مقایسه این بخش محدود به مدلهای متنباز مانند Qwen2.5-Max، DeepSeek V3، Llama 3.1-405B و Qwen 2.5-72B است. نتایج این مقایسه به سه بخش تقسیم میشود:
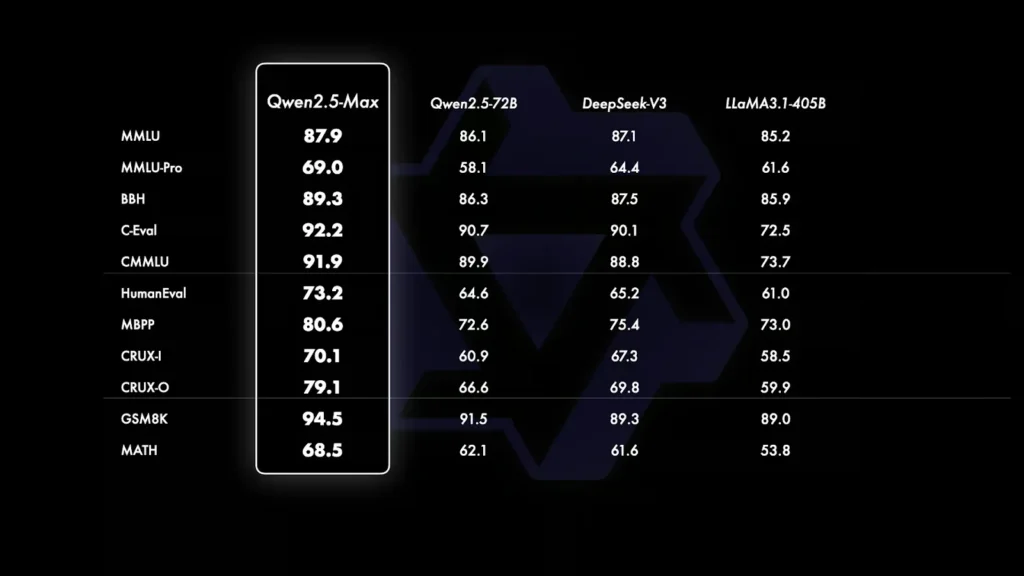
- دانش عمومی و درک زبان (MMLU, MMLU-Pro, BBH, C-Eval, CMMU): مدل Qwen2.5-Max در تمامی این معیارها برتری دارد. این مدل در MMLU امتیاز 87.9 و در C-Eval امتیاز 92.2 را کسب کرد که بالاتر از DeepSeek V3 و Llama 3.1-405B است. این معیارها گستره دانش، عمق درک مفاهیم و توانایی استدلال مدل را ارزیابی میکنند.
- برنامهنویسی و حل مسئله (HumanEval, MBPP, CRUX-I, CRUX-O): مدل Qwen2.5-Max در تمامی این معیارها پیشتاز است و در وظایف کدنویسی عملکرد بسیار خوبی دارد. این مدل با امتیاز 73.2 در HumanEval و 80.6 در MBPP، کمی از DeepSeek V3 جلوتر و بهطور قابلتوجهی از Llama 3.1-405B بهتر است. این بخش توانایی مدل در کدنویسی، حل مسائل و دنبال کردن دستورات برای تولید راهحلهای مستقل را اندازهگیری میکند.
- حل مسائل ریاضی (GSM8K, MATH): استدلال ریاضی یکی از قویترین نقاط Qwen2.5-Max به شمار میآید. این مدل توانسته در زمینه محاسبات ریاضی امتیاز 94.5 را در GSM8K کسب کند. در واقع این امتیاز بالاتر از DeepSeek V3 (89.3) و Llama 3.1-405B (89.0) است. البته در معیار MATH که روی مسائل پیچیدهتر تمرکز دارد، امتیاز 68.5 را کسب کرده که کمی بالاتر از رقبا است، اما همچنان جای پیشرفت دارد.
چگونه به Qwen2.5-Max دسترسی پیدا کنیم؟
دسترسی به Qwen2.5-Max بسیار آسان است و شما میتوانید آن را رایگان و بدون نیاز به تنظیمات پیچیده امتحان کنید.
سادهترین راه برای تجربه Qwen2.5-Max استفاده از پلتفرم Qwen Chat است. این یک رابط مبتنی بر وب است که به شما اجازه میدهد مستقیماً در مرورگر خود با این مدل تعامل داشته باشید. در واقع دسترسی به این مدل هوش مصنوعی مشابه نحوه استفاده از ChatGPT در مرورگر است. برای استفاده از مدل Qwen2.5-Max ابتدا وارد پلتفرم Qwen Chat شوید و سپس از منوی انتخاب مدل، گزینه Qwen2.5-Max را انتخاب کنید.
دسترسی به API از طریق Alibaba Cloud
برای توسعهدهندگان، مدل Qwen2.5-Max از طریق Alibaba Cloud Model Studio API در دسترس است. برای استفاده از این API، مراحل زیر را دنبال کنید:
- ثبتنام در Alibaba Cloud و ایجاد حساب کاربری.
- فعالسازی سرویس Model Studio.
- ایجاد کلید API برای ادغام با برنامههای خود.
نکته: ازآنجاییکه این API فرمت مشابهی با OpenAI دارد، ادغام آن برای توسعهدهندگانی که با مدلهای OpenAI آشنا هستند بسیار آسان خواهد بود. برای جزئیات بیشتر درباره تنظیمات، میتوانید به وبلاگ رسمی Qwen2.5-Max مراجعه کنید.
نتیجهگیری
Qwen2.5-Max قدرتمندترین مدل هوش مصنوعی علیبابا تاکنون است و برای رقابت با مدلهای پیشرو مانند GPT-4o، Claude 3.5 Sonnet و DeepSeek V3 طراحی شده است.
برخلاف برخی از مدلهای قبلی Qwen، این نسخه متنباز نیست اما میتوان آن را از طریق Qwen Chat بهصورت رایگان امتحان کرد. همچنین API در Alibaba Cloud برای ادغام در پروژههای توسعهدهندگان در دسترس است.
با توجه به سرمایهگذاریهای مستمر علیبابا در زمینه هوش مصنوعی، احتمالاً در آینده شاهد مدلهایی با تمرکز بیشتر بر استدلال و منطق پیشرفته (شاید تحت عنوان Qwen 3) باشیم.
سوالات متداول (FAQs)
آیا میتوان Qwen2.5-Max را بهصورت محلی اجرا کرد؟
خیر. این مدل متنباز نیست و امکان اجرای آن روی سختافزار شخصی وجود ندارد. البته علیبابا دسترسی از طریق Qwen Chat و API را فراهم کرده است.
آیا میتوان Qwen2.5-Max را تنظیم دقیق (Fine-Tune) کرد؟
خیر. ازآنجاییکه این مدل متنباز نیست، علیبابا امکان تنظیم دقیق برای کاربران را ارائه نکرده است. البته، ممکن است در آینده مدلهای تنظیمشده یا گزینههای شخصیسازی از طریق API ارائه شوند.
آیا Qwen2.5-Max در آینده متنباز خواهد شد؟
علیبابا هنوز برنامهای برای متنباز کردن این مدل اعلام نکرده است، اما باتوجهبه سابقه آن در انتشار مدلهای کوچکتر متنباز، ممکن است نسخههای آینده شامل نسخههای متنباز نیز باشند.
آیا Qwen2.5-Max میتواند تصویر تولید کند (مانند DALL·E 3 یا Janus-Pro)؟
خیر. این مدل یک مدل متنی است که بر روی دانش عمومی، کدنویسی و حل مسائل ریاضی تمرکز دارد و از قابلیت تولید تصویر پشتیبانی نمیکند.






