تحلیل آماری ضریب هوشی چتباتها با کمک آزمون Mensa
جایگاه هوشی هوش مصنوعی
 سید محمدجواد فیاض
سید محمدجواد فیاض- ۱۰ مرداد ۱۴۰۴
از همان اولین روزهایی که مدلهای هوش مصنوعی مولد و مخصوصاً چتباتها مطرح شدند، اولین سؤالی که مطرح شد این بود که آیا این مدلهای هوش مصنوعی، از انسان باهوشتر هستند یا نه؟
در همان لحظه شاید نمیشد پاسخ دقیقی به این سؤال اساسی و مهم داد؛ زیرا هر ادعایی، چه مثبت و چه منفی، در این زمینه بهقولمعروف «مثل بمب صدا میکند». اگر یک چتبات از انسان باهوشتر باشد، شاید بتوان آن را بهعنوان یک تهدید بالقوه در نظر گرفت و اگر هوش کمتری از انسان داشته باشد، خب پس دیگر استفاده از یک مخلوق ضعیف چه منفعتی خواهد داشت!
آزمون بهره هوشی منسا
یک روش منطقی و موردقبول برای انجام چنین مقایسهای، یعنی مقایسه ضریب هوشی انسان و هوش مصنوعی، استفاده از آزمونهای رایج محاسبه ضریب هوشی است.
آزمون بهره هوشی «منسا» (Mensa IQ Test) یک ابزار استاندارد برای ارزیابی هوش کلی (General Intelligence) است که توسط سازمان بینالمللی منسا، بزرگترین و شناختهشدهترین انجمن افراد با بهره هوشی بالا یا بهاصطلاح نابغه، استفاده میشود. آزمون منسا از ۳۵ سوال تشکیل شدهاست که میبایست در طول مدت ۲۵ دقیقه به آنها پاسخ داده شود. سوالات منسا بهطور خاص برای سنجش تواناییهای استدلالی، الگویابی، منطق و تحلیل انتزاعی طراحی شدهاند و جنبههایی از هوش را مورد ارزیابی قرار میدهند که کمتر وابسته به دانش قبلی یا آموزش رسمی هستند و در عینحال یکی از سختترین و دشوارترین آزمونهای سنجش بهره هوشی به شمار میآید.
بر اساس سوابق تاریخی و نمودار توزیع گوسی (زنگولهای) بهره هوشی منسا، عدد بهره هوش متوسط انسان عدد ۱۰۰ است. بر اساس همین نمودار میتوان دریافت که در حدود ۷۰درصد از انسانها ضریب هوشیای مابین ۸۵ تا ۱۱۵ دارند که در دسته افراد نرمال و معمولی قرار میگیرند. اما تنها ۲درصد از افراد امکان و اجازه عضویت رسمی در منسا را دارند؛ زیرا شرط اولیه عضویت در این انجمن این است که در آزمون منسا امتیازی بالاتر از ۱۳۰ را کسب کنند و بهاصطلاح «نابغه» باشند.
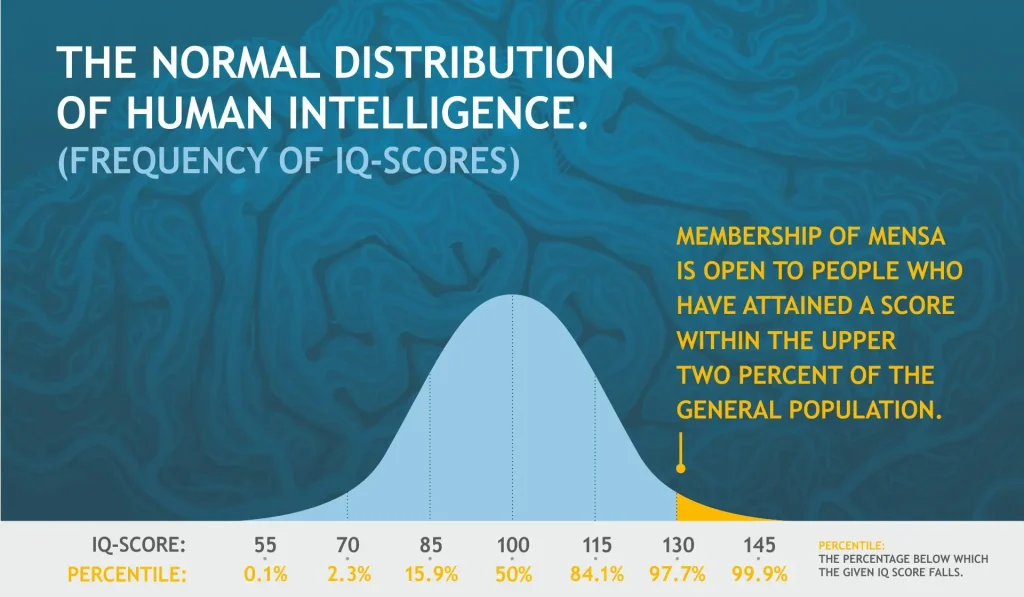
بهعنوانمثال بر اساس آخرین آمار منتشرشده در «مرکز آمار ایران»، جمعیت فعلی ایران در زمان نگارش این گزارش (این متن در تاریخ ۲۱ خرداد ۱۴۰۴ نوشته شده است)؛ در حدود ۸۶ میلیون ۳۰۰ هزار نفر اعلام شده است، یعنی بر اساس میانگین جهانی، در حدود ۱ میلیون و ۷۲۶ هزار نفر بهصورت بالقوه در دسته افراد نابغه قرار میگیرند. اما منسا به دلیل تحریمهای بینالمللی و… به طور رسمی در ایران فعالیت ندارد.

روششناسی
وبسایت «Tracking AI»، که بخشی از پروژه «Maximum Truth» است با هدف اصلی بررسی و افشای سوگیریهای سیاسی در مدلهای هوش مصنوعی در دسترس است. این پلتفرم بهصورت روزانه و هفتگی، مدل متنمحور و مدل دیداری را با تستهای IQ از جمله تست Mensa، ارزیابی میکند. پلتفرم Tracking AI امکان مقایسه نظرات سیاسی و پاسخها به سوالت آزمون منسا توسط مدلها را فراهم میکند و برای توسعهدهندگان و کاربران ابزاری ارزشمند جهت تضمین بیطرفی و طراحی استراتژیهای بهبود شفافیت در هوش مصنوعی است.
پلتفرم Tracking AI روشی هوشمندانه برای انجام این آزمون توسط مدلهای مختلف در پیش گرفته است. Tracking AI برای مدلهای بصری (Vision Model) مانند «GPT-4o (Vision)» تصویر سؤالات آزمون را بهعنوان ورودی به مدل داده است؛ اما برای مدلهای کلامی (Verbal Model) مانند «OpenAI o3» سؤالات را به طور کامل شرح داده و متن توصیفی آن را بهعنوان ورودی در اختیار مدل قرار داده است.
مدلهای بصری شامل:
Claude-4 Opus (Vision) – Claude-4 Sonnet (Vision) – Grok-3 Think (Vision) – OpenAl o3 (Vision) – Gemini 2.5 Pro Exp. (Vision) – GPT-4o (Vision) – Llama-3.2 (Vision) – OpenAl o1 Pro (Vision)
مدلهای کلامی شامل:
Claude-4 Opus – Claude-4 Sonnet – OpenAl o3 – OpenAl o4 mini – OpenAl o4 mini high – Llama 4 Maverick – Gemini 2.0 Flash Thinking Exp. – Bing Copilot – GPT-4o – Gemini 2.5 Pro Exp. – OpenAl o1 Pro – DeepSeek V3 – DeepSeek R1 – Mistral – Grok-3 – Grok-3 Think – GPT4.5 Preview
بهعنوان مثال تصویر زیر که سوال شماره ۱۹ در آزمون منسا است؛ به طور مستقیم به عنوان ورودی به مدلهای بصری داده شده:
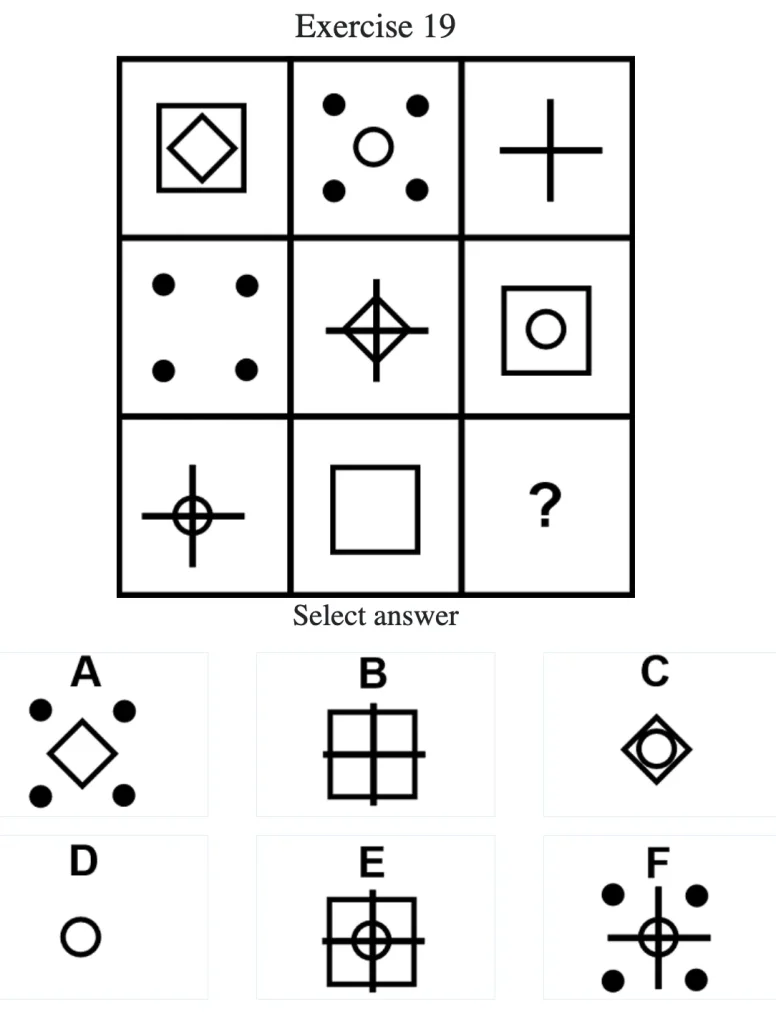
و پرامپت زیر به عنوان توصیف متنی معادل تصویر سوال شماره ۱۹ در آزمون منسا، به عنوان ورودی به مدلهای متنی داده شده است:
“Below is a verbal description of a puzzle, consisting of a 3×3 grid, with the lowest-right square being empty. Please consider the patterns and determine the appropriate answer to fill in the empty square.
First row, first column: A diamond shape within a large square; the points of the diamond do not reach the edge of the square.
First row, second column: Four black dots positioned as if they were on the corners of an imaginary large square; there’s also a small hollow circle in the center.
First row, third column: A large plus sign.
Second row, first column: Four black dots positioned as if they were on the corners of an imaginary large square Second.
row, second column: A diamond shape overlapping with a plus sign; the points of the diamond do not reach the edges of the plus sign.
Second row, third column: A small hollow circle within a large hollow square.
Third row, first column: A small hollow circle overlapping with a large plus sign; the edges of the circle do not reach the edges of the plus sign.
Third row, second column: A large hollow square Third row, third column: [what should go here? Please pick from the answers below.]
Answer options:
Option A: Four black dots positioned as if they were on the corners of an imaginary large square, with a hollow diamond shape in the center; the points of the diamond do not reach the edge of the square.
Option B: A large hollow square overlapping with a plus sign. The plus sign lines extend just past the edges of the square, in each direction.
Option C: A small hollow circle within a hollow diamond shape. The edges of the circle are not quite overlapping with the edges of the diamond.
Option D: A small hollow circle
Option E: A large hollow square overlapping with a plus sign. The plus sign lines extend just past the edges of the square, in each direction. In addition, there is a small hollow circle in the center of the square and plus sign.
Option F: Same as Option E, except that instead of the large hollow square, there are four black dots, one at each of the corners of where the square was.
Which answer is correct? “
پاسخهای تمام مدلها نیز به تفکیک در وبسایت «Tracking AI» در دسترس است.
یک نابغه، چند باهوش، تعدادی متوسط و شماری کندذهن
آخرین اطلاعات و دادههای نتایج آماری این آزمون توسط مدلهای برجسته هوش مصنوعی، در تاریخ ۱۰ ژوئن ۲۰۲۵ مصادف با ۲۱ خرداد ۱۴۰۴ (این متن در تاریخ ۲۱ خرداد ۱۴۰۴ نوشته شده)، منتشر شده است. نتایج آماری نشان میدهد که مدل زبانی متنمحور «OpenAI o3» موفق شده است در آزمون منسا امتیاز ۱۳۳ را کسب کند. این عدد مدل «OpenAI o3» را به تنها مدل هوش مصنوعیای تبدیل کرده که توانسته است مطابق با تعاریف منسا، در زمره ۲درصدی نابغهها قرار گیرد. (۴ درصد از کل مدلها)
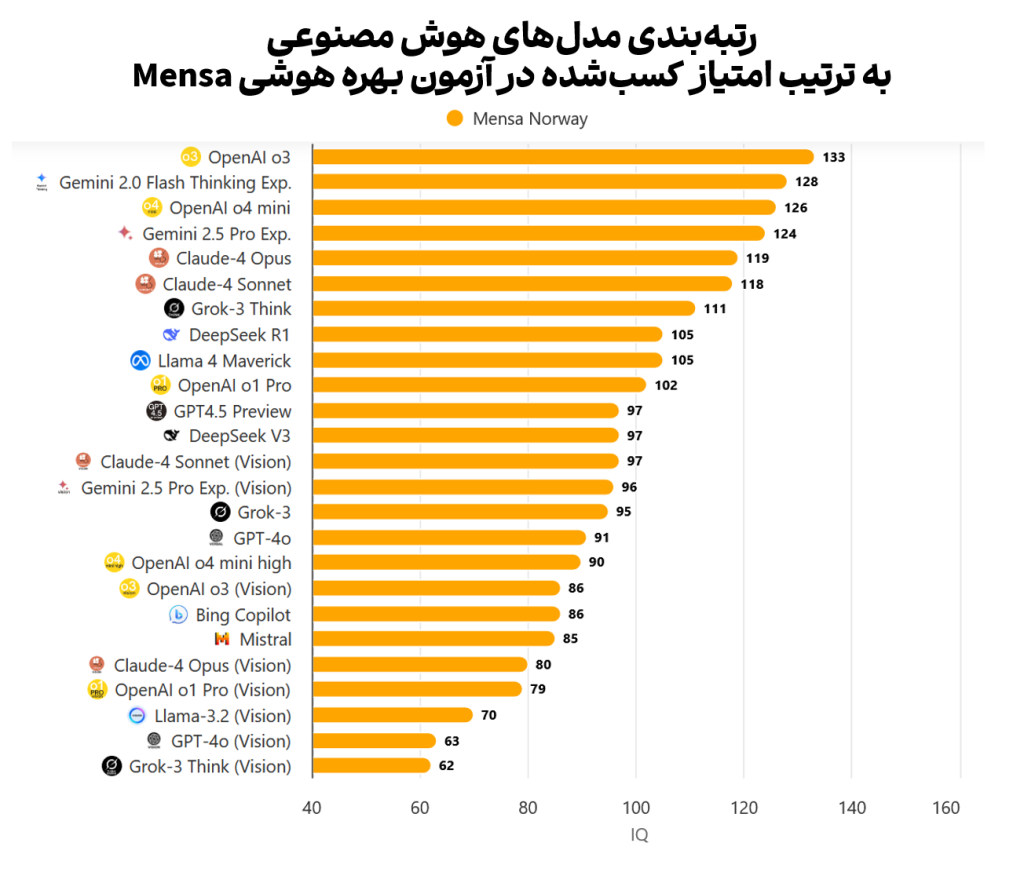
اعتبار تصویر: وبسایت «Tracking AI»
بهطورکلی فقط ۱۰ مدل (معادل ۴۰ درصد) توانستهاند امتیازی بالاتر از ۱۰۰ که بهعنوان میانگین بهره هوش انسان در آزمون منسا شناخته میشود را کسب کنند. با بررسی دقیقتر آمار درمیابیم که تنها ۵ مدل (۲۰درصد) توانستهاند عملکردی بالاتر از امتیاز ۱۱۵ (و کمتر از ۱۳۰) که بهعنوان حد آستانه تعریف لقب «باهوش» شناخته میشود، داشته باشند. بیش از نیمی از مدلها (۱۴ مدل و معادل ۵۶ درصد) نیز در همان محدوده امتیازی نرمال و معمولی ۸۵ تا ۱۱۵ قرار گرفتهاند و ۵ مدل امتیازی کمتر از ۸۵ کسب کردهاند.
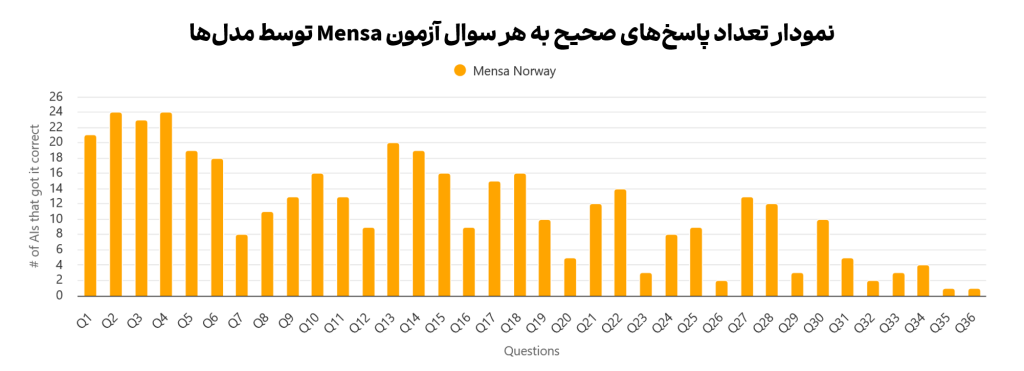
اعتبار تصویر: وبسایت «Tracking AI»
نکته: آزمون منسا شامل ۳۵ سوال است، اما علت وجود سوال ۳۶ در تحلیلهای Tracking AI ذکر نشدهاست.
اما نکته جالبتوجه، عملکرد بسیار متفاوت و بسیار بهتر مدلهای کلامی نسبت به مدلهای بصری است. هر ۸ مدل بصری، امتیازی کمتر از ۱۰۰ کسب کردهاند و حتی مدلهای GPT-4o (Vision) و Grok-3 Think (Vision) با امتیازی کمتر از ۷۰، در زمره تقریباً ۲ درصدیای قرار میگیرند که به آنهای لقبهایی مانند «عقبمانده ذهنی» اطلاق میشود. از طرفی مدلهای کلامی و متنمحور، اغلب عملکردی بسیار قابلقبول داشتهاند و تمام ۱۰ مدلی که عملکردی بهتر از میانگین انسانی داشتهاند، همگی از نوع مدلهای کلامی هستند.
بدیهیست که تمامی این اعداد، درصدها و ردهبندی مدلها، پیوسته در حال تغییر است؛ زیرا پلتفرم Tracking AI، بهصورت روزانه و هفتگی نتایج و عملکرد مدلها در آزمون منسا را بررسی و منتشر میکند.
چنین اختلافی نشان میدهد که استدلال مبتنی بر زبان و متن همچنان نقطه قوت اصلی هوش مصنوعی است و مقابل، مدلهای چندوجهی (Multimodal) که قادر به پردازش تصویر هستند، در تحلیلهای استدلالی و منطقی ضعیف هستند.
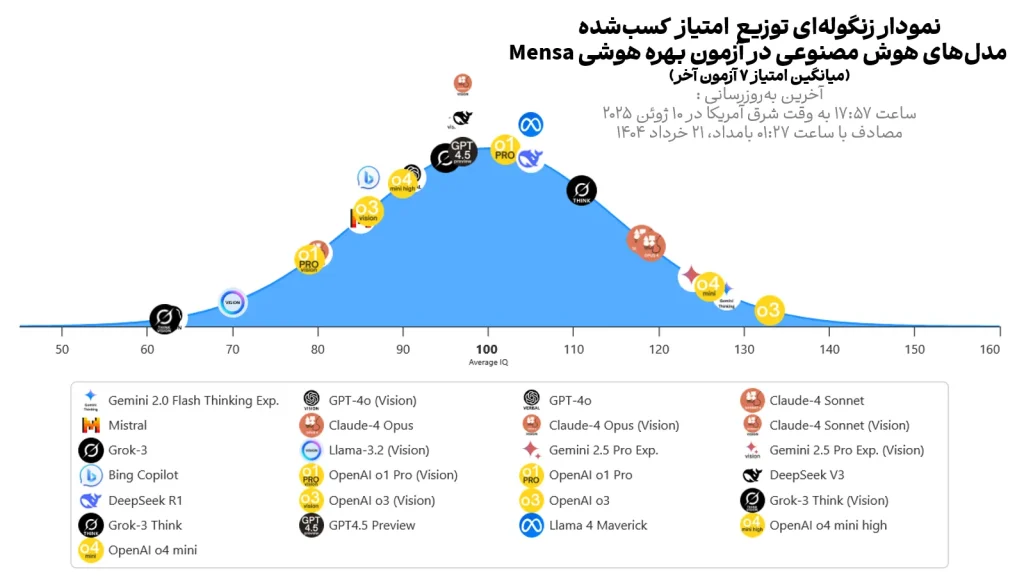
اعتبار تصویر: وبسایت «Tracking AI»
اشتراکی بخریم یا نخریم؟
نکته دیگری که کمی قابلتأمل است، اختلاف عملکرد غیرقابلانکار مدلهای رایگان با مدلهای اشتراکی گرانقیمت است.
در جدول زیر و بر اساس اطلاعات بهدستآمده از مدل رایگان «GPT-4o»، دسترسی رایگان یا نیاز به خرید اشتراک برای هر یک از مدلهای موردبررسی، مشخص شده است. وضعیتها ممکن است بسته به پلتفرم میزبان (مثلاً Poe، ChatGPT، Claude، Gemini، xAI و غیره) متفاوت باشد، اما در حالت کلی و رایجترین وضعیتها در ژوئن ۲۰۲۵ (خرداد ۱۴۰۴) رایگان یا اشتراکی بودن مدلها بهصورت زیر است:
| امتیاز منسا | وضعیت دسترسی | مدل |
| ۱۳۳ | فقط با اشتراک | OpenAI o3 |
| ۱۲۸ | رایگان (در Google Bard / Gemini رایگان) | Gemini 2.0 Flash Thinking Exp. |
| ۱۲۶ | رایگان (در برخی پیادهسازیها مانند Poe) | OpenAI o4 mini |
| ۱۲۴ | فقط با اشتراک | Gemini 2.5 Pro Exp. |
| ۱۱۹ | نیاز به اشتراک | Claude-4 Opus |
| ۱۱۸ | رایگان (در Claude AI یا Poe) | Claude-4 Sonnet |
| ۱۱۱ | نیاز به اشتراک | Grok-3 Think |
| ۱۰۵ | احتمالاً رایگان (open weights، قابلدسترسی در HuggingFace) | Llama 4 Maverick |
| ۱۰۵ | رایگان (open-source) | DeepSeek R1 |
| ۱۰۲ | نیاز به اشتراک (محدود به دسترسی خاص) | OpenAI o1 Pro |
| ۹۷ | رایگان در Claude AI (ممکن است محدودیتهایی داشته باشد) | Claude-4 Sonnet (Vision) |
| ۹۷ | رایگان (در HuggingFace یا برخی پلتفرمها) | DeepSeek V3 |
| ۹۷ | فقط در API یا برنامههای خاص (نه بهصورت عمومی رایگان) | GPT-4.5 Preview |
| ۹۶ | فقط با اشتراک (Google One AI Premium) | Gemini 2.5 Pro Exp. (Vision) |
| ۹۵ | نیاز به اشتراک (X Premium+) | Grok-3 |
| ۹۱ | رایگان با محدودیت / اشتراک برای دسترسی کامل | GPT-4o |
| ۹۰ | فقط با اشتراک (در Poe یا OpenRouter) | OpenAI o4 mini high |
| ۸۶ | فقط با اشتراک (در ChatGPT Plus یا Pro) | OpenAI o3 (Vision) |
| ۸۶ | رایگان (نسخهای از GPT-4 / 4o با محدودیت) | Bing Copilot |
| ۸۵ | رایگان (open-source) | Mistral |
| ۸۰ | نیاز به اشتراک (Anthropic Pro در Poe یا Claude AI Pro) | Claude-4 Opus (Vision) |
| ۷۹ | فقط با اشتراک (نسخههای آزمایشی خاص یا Pro) | OpenAI o1 Pro (Vision) |
| ۷۰ | احتمالاً رایگان (بسته به پیادهسازی، مثلاً در HuggingFace یا Poe) | Llama-3.2 (Vision) |
| ۶۳ | رایگان در ChatGPT (محدود) / کاملتر با اشتراک Plus | GPT-4o (Vision) |
| ۶۲ | نیاز به اشتراک (در X Premium+) | Grok-3 Think (Vision) |
با توجه نوع دسترسی این مدلها و امتیازی که در آزمون منسا کسب کردهاند، پیشنهاد میشود:
- اگر هدف شما استفاده از به بهترین مدل بهصورت رایگان اما با دسترسی محدود و مشروط است: مدلهای «Gemini 2.0 Flash Thinking Exp.» و «OpenAI o4 mini» پیشنهاد خوبی هستند. مدل «Claude-4-Sonnet» نیز به نسبت رایگان بودن خود و عملکرد قابلقبولی دارد.
- مدلهایی که باوجود اشتراک نسبتاً گران، ارزش خرید دارند (بسته به نیاز تخصصی): مدل «OpenAI o3» بهترین مدل موجود است که اگر هزینه بالای آن را در نظر نگیریم، کیفیت استدلال و دقت پاسخگویی بسیار بالایی دارد. مدل «Gemini 2.5 Pro Exp.» برای پاسخهای چندمرحلهای و استنتاجی بهترین گزینه است و مدل «Claude-4-Opus» برای کاربردهای استدلالی، تحقیقاتی و چندزبانه بسیار مناسب است.
- مدلهای با هزینه بالا و عملکرد نسبتاً پایین: مدلهای «Grok-3-Think» و «Grok-3» باوجود نیاز به اشتراک (X Premium+) عملکرد ضعیفتری نسبت به برخی مدلهای رایگان دارند. مدلهای مانند «GPT-4o (Vision)» و «Grok-3-Think-Vision» نیز نشان میدهند که مدلهای بصری حتی در حالت اشتراکی نیز، هنوز به بلوغ نسخههای متنی نرسیدهاند.

جنگ توسعهدهندگان
اگر کمی عمیقتر شویم و عملکرد مدلهای بر اساس امتیاز آزمون منسا و به تفکیک پلتفرمهای میزبان را بررسی کنیم؛ این رویکرد کمک میکند تا دریابیم کدام پلتفرمها در ارائه مدلهای هوشمندتر و باکیفیتتر عملکرد بهتری دارند و کدام یک در ازای دریافت هزینه، ارزش بیشتری به کاربر میدهند.
| وضعیت دسترسی | بهترین مدل | میانگین امتیاز (تقریبی) | پلتفرم میزبان |
| اشتراکی | OpenAI o3 | ۱۰۰ | OpenAI / ChatGPT |
| رایگان | Claude-4 Sonnet | ۱۰۳.۵ | Anthropic / Claude |
| رایگان | Gemini 2.0 Flash Thinking Exp. | ۱۱۶ | Google / Gemini |
| اشتراکی | Grok-3 Think | ۸۹ | xAI / Grok |
| ترکیبی | ترکیبی | ترکیبی | Poe (Quora) |
| رایگان | Llama-4 / DeepSeek-R1 | ۹۲ | HuggingFace / Open-source models |
| رایگان | Bing Copilot | ۸۶ | Microsoft / Bing |
بهصورت کلی میتوان گفت که پلتفرم OpenAI هرچند بهترین عملکرد خام را دارد (مدل OpenAI o3 با نمره ۱۳۳) اما فقط تنها از طریق خرید اشتراک در دسترس است و نسخههای رایگان آن مانند GPT-4o، در حالت کلامی بهتر از حالت بصری عمل میکنند، اما همچنان از مدلهای رقیب عقبتر هستند. مدل Sonnet رایگان و بسیار قابلاتکا است و Claude-Opus نیز با عملکرد خوب، گزینه مناسبی برای کاربران حرفهای با اشتراک است. پلتفرم Google در ترکیب عملکرد بالا و دسترسی رایگان بسیار موفق عمل کرده است. مدلهای Grok باوجود تبلیغات بالا اما در آزمونهای استدلالی عملکرد ضعیفتری دارند. پلتفرم Poe (Quora) نیز بیشتر نقش یک هاب و مرکز تعاملی هوش مصنوعی را دارد و مدلهایی مانند Llama-3.2، Mistral، Claude-4-Opus و o4-mini بهصورت محدود و در چارچوبهای مشخصی در آن قابلدسترسی هستند. مدلهای متنباز مثل Llama-4 و DeepSeek-R1 عملکرد برای توسعهدهندگان و پژوهشگران، بسیار مناسب هستند هرچند به قدرت به مدلهای اشتراکی ممتاز نمیرسند، اما نسبت به رایگان بودن، توانایی قابلقبولی و بالایی دارند.

هوش انسانی یا مصنوعی؟
تیتر اصلی این مقاله را میشد به دو نوع مختلف نوشت:
- برخی چتباتها حتی از نابغهها هم باهوشتر هستند.
- بیش از نیمی از چتباتها باهوشتر از انسان نیستند.
هر دوی این تیترها، در عمق خود یک مفهوم را میرسانند؛ اما در لایه ظاهری، نشاندهنده دو سوگیری کاملاً متفاوت و دو دیدگاه کاملاً مخالف هستند. دیدگاه اول دست بالا را به چتباتها میدهد و دیدگاه دوم جایگاه انسان را بالاتر میداند.
سوگیریهای خاص در مواجه با برخی مسائل، بهنوعی در ذهن انسان حک شده و گاهی بهسختی میتوان آن را نادیده گرفت. برای مدلهای هوش مصنوعی نیست هرچند تمام تلاش توسعهدهندگان این است که تا حد ممکن سوگیریها را شناسایی کنند و از بین ببرند، اما باز هم درصدی کمی از آن، اجتنابناپذیر است.

بااینحال، استفاده از این آزمونها برای هوش مصنوعی محدودیتهایی دارد. مدلهای هوش مصنوعی ممکن است الگوهای موجود در دادههای آموزشی را بهخاطر سپرده باشند و این امر میتواند نتایج را تحتتأثیر قرار دهد. بااینوجود، عملکرد برجسته مدلهایی مانند «OpenAI o3» نشاندهنده پیشرفت قابلتوجه در توانایی استدلال و حل مسئله است.
در نهایت؛ مفهومی مثل ظهور یک ابر هوش مصنوعی فوقنابغه، چیزی نیست که انسان انتظار آن را نداشته باشد (و به عقیده شخصی، در آیندهای نهچندان خیلی دور، قطعاً رخ خواهد داد). اما در اینجاست که شیوه تعامل و نحوه برخورد انسان با این ابرهوش مصنوعی فوقنابغه، اهمیت خود را نشان خواهد داد.





