

گم شدن ایمنی AI در سایه رقابت آزمایشگاههای هوش مصنوعی
بیاحتیاطی مصنوعی
 سید محمدجواد فیاض
سید محمدجواد فیاض- ۶ مرداد ۱۴۰۴
ترس از ظهور فناوریهای جدید پدیدهای رایج است؛ سقراط نگران بود که نوشتن، توانایی ذهنی انسان را تضعیف کند و عامه مردم تلگراف را عامل انزوای اجتماعی میدانستند. اما کمتر پیش میآید که نوآوران دچار وحشت شوند و عجیبتر آنکه همین توسعهدهندگان نگران، با وجود تردیدهایشان، با شتاب و سرعت بیشتری پیش بروند. بااینحال، تقریباً چنین وضعیتی را در توسعه بیوقفه «هوش جامع مصنوعی» (Artificial general intelligence - AGI) شاهدیم.
«جفری هینتون» (Geoffrey Hinton) پدرخوانده دانش هوش مصنوعی، احتمال میدهد که ۱۰ تا ۲۰ درصد احتمال دارد فناوری هوض مصنوعی به انقراض انسان منتهی شود. «یاشوا بنجیو» (Yoshua Bengio) همکار پیشین او، این احتمال را در بالاترین حد این نوع خطر میداند. «نیت سورز» و «الایزر یودکوفسکی» (Nate Soares and Eliezer Yudkowsky)، دو نفر از صدها فعال حوزه هوش مصنوعی که در سال ۲۰۲۳ نامهای هشدارآمیز درباره خطرات آن امضا کردند؛ بهزودی کتابی درباره ابرهوش (Superintelligence) مصنوعی با عنوان: «اگر کسی آن را بسازد، همه میمیرند» (If Anyone Builds It, Everyone Dies) منتشر میکنند. در محافل خصوصی نیز بزرگان هوش مصنوعی نگرانیهایی مشابه البته نه لزوماً با لحنی چنین آخرالزمانی را ابراز میکنند. مجله «The Economist» در جدیدترین نسخه خود (July 26th 2025) در گزارشی با عنوان «Artificially Incautious» به بررسی این موضوع پرداخته است.
نگرانی همراه با شتاب
با وجود این نگرانیها، شرکتهای فناوری غربی و همتایان چینی آنها در عمل، شتاب بیشتری به تلاشهای خود برای دستیابی سریعتر از رقبا به AGI دادهاند. منطق آنها ساده است؛ همه معتقدند اگر شرکت یا کشور آنها کار را متوقف یا آهسته کند، رقبا به مسیر خود ادامه خواهند داد، پس بهتر است خودشان نیز عقب نمانند. همچنین، این باور که مزایای دستیابی به AGI یا ابرهوش عمدتاً نصیب نخستین فاتحان این میدان خواهد شد، انگیزه مضاعفی را برای شتابدهی به روند توسعه ایجاد میکند. همه اینها باعث میشود زمان و تمرکز چندانی برای تأمل درباره ایمنی این مدلها باقی نماند.

البته، دستکم در ظاهر، آزمایشگاههای بزرگ هوش مصنوعی به مسائل ایمنی توجه نشان میدهند. سم آلتمن، مدیرعامل OpenAI، در سال ۲۰۲۳ علناً خواستار تدوین فوری مقررات برای توسعه ابرهوش شد. شرکت Anthropic توسط کارمندان سابق OpenAI که نسبت به رویکرد ایمنی آن شرکت احساس ناراحتی داشتند، تأسیس شد و خود را متعهد به «ایمنی در مرزهای فناوری» (Safety at the Frontier) معرفی میکند. آزمایشگاه هوش مصنوعی گوگل، DeepMind، در آوریل سال جاری میلادی مقالهای درباره تدابیر ایمنی برای جلوگیری از بروز فاجعه در مسیر توسعه AGI منتشر کرد. ایلان ماسک نیز همان نامهای را امضا کرده بود که سورز و یودکوفسکی امضا کردند.
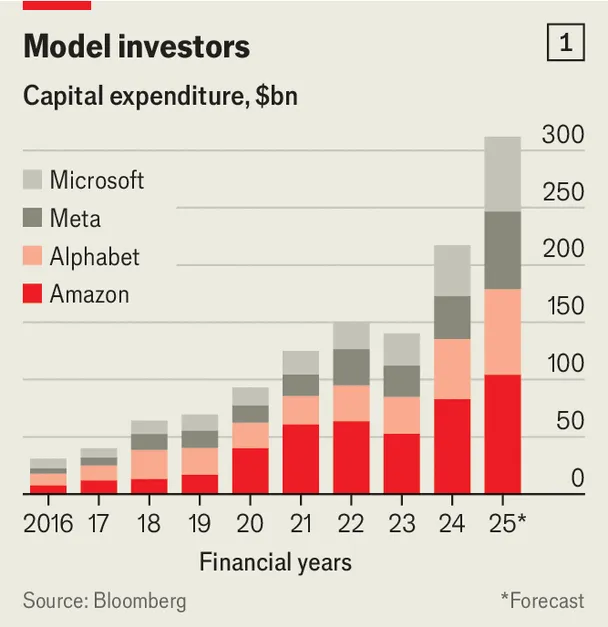
اما بااینحال، شتاب بیوقفه برای پیشیگرفتن از رقبا با لحن محتاطانهای که در ظاهر نشان داده میشود، در تضاد است. مثلاً ایلان ماسک تنها چند ماه پس از درخواست برای توقف چنین فعالیتهایی، Grok را عرضه کرد. مارک زاکربرگ، مدیرعامل متا که بخش هوش مصنوعی این شرکت را به «آزمایشگاههای ابرهوش» (Superintelligence Labs) تغییر برند داده، با پیشنهاد دستمزدهای ۹ رقمی در حال جذب پژوهشگران این حوزه و در صدد ساخت یک مرکز داده به وسعت شهر «منهتن» (تقریباً ۶۰ کیلومترمربع) به نام «هایپریون» (Hyperion) است که مصرف برق سالانهاش با مصرف کل کشور نیوزیلند برابری میکند. سم آلتمن نیز قصد دارد تنها در آمریکا ۵۰۰ میلیارد دلار برای توسعه OpenAIهزینه کند. در واقع، سرمایهگذاری همه شرکتهای بزرگ فناوری غربی که عمدتاً با انگیزه پیشرفت و توسعه هوش مصنوعی انجام میشود، بهشدت در حال افزایش است. (نمودار شماره ۱ را ببینید).
چهرههای مطرح نیز پیشبینی میکنند که AGI ظرف چند سال آینده از راه خواهد رسید. به گفته «جک کلارک» (Jack Clark)، همبنیانگذار و مدیر سیاستگذاری Anthropic: «وقتی به دادهها نگاه میکنم، روندهای زیادی را تا سال ۲۰۲۷ بهوضوح میبینم». «دمیس هسابیس» (Demis Hassabis)، همبنیانگذار DeepMind نیز معتقد است هوش مصنوعی ظرف یک دهه آینده همسطح تواناییهای انسانی خواهد شد و زاکربرگ نیز گفته: «ابرهوش در دسترس است.»
پیشبینی
در ماه آوریل سال جاری میلادی، گروه تحقیقاتی «AI Futures Project» پیشبینی کرد که تا ابتدای سال ۲۰۲۷، برترین مدلهای هوش مصنوعی به اندازه یک برنامهنویس در یک آزمایشگاه هوش مصنوعی توانمند خواهند شد. تا پایان همان سال، این مدلها عملاً خواهند توانست اداره تحقیقات یک آزمایشگاه هوش مصنوعی را بر عهده بگیرند. این پیشبینیها بر این فرض استوار است که یکی از نخستین حوزههایی که با کمک هوش مصنوعی جهش چچشمگیریخواهد داشت، خودِ توسعه هوش مصنوعی خواهد بود. این روند «خود بهبودی بازگشتی» (recursive self-improvement – RSI) میتواند فاصله آزمایشگاههای پیشرو با سایر رقبا را بیشتر کند و به نوبه خود نیز به تشدید رقابتها دامن میزند.

البته ممکن است این پیشبینیها بیش از حد خوشبینانه باشند. اما اگر چیزی در این میان قطعی باشد، آن است که پیشبینیکنندگان در گذشته معمولاً در برآورد تواناییهای هوش مصنوعی بیش از حد محتاط بودهاند. اوایل ماه جولای سال جاری میلادی، مؤسسه «Forecasting Research Institute» از گروهی از پیشبینیکنندگان حرفهای و زیستشناسان درخواست کرد برآورد کنند چه زمانی یک سیستم هوش مصنوعی میتواند عملکردی معادل یک تیم سطح بالای ویروسشناسی انسانی داشته باشد. میانگین پاسخ زیستشناسان سال ۲۰۳۰ بود و میانگین پیشبینیکنندگان حرفهای حتی بدبینانهتر و سال ۲۰۳۴ بود؛ اما وقتی نویسندگان این پژوهش مدل OpenAI-o3 آزمایش کردند، دریافتند این مدل همین حالا نیز به آن سطح عملکردی رسیده است. پیشبینیکنندگان پیشرفت هوش مصنوعی را تقریباً بهاندازه یک دهه دستکم گرفتهاند؛ نکتهای نگرانکننده بهویژه ازآنجهت که هدف این آزمایش، ارزیابی احتمال وقوع یک اپیدمی مرگبار ساخت بشر توسط هوش مصنوعی بود.
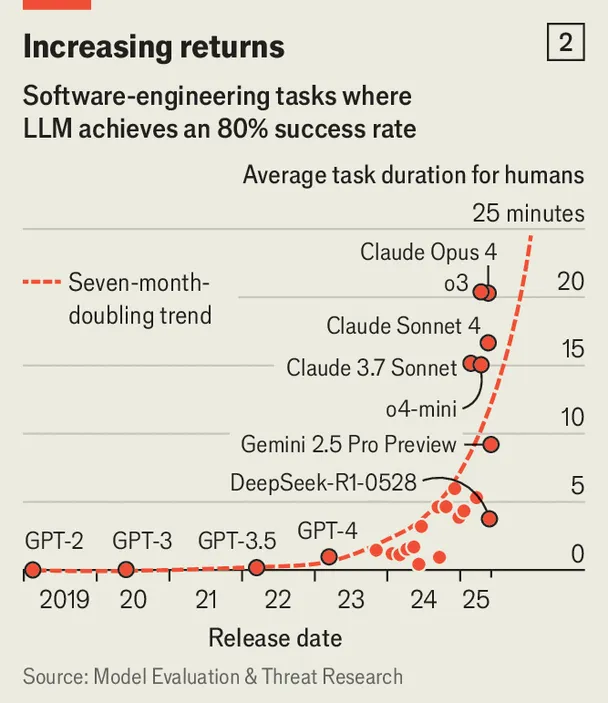
آنچه مبنای پیشبینیهای مربوط به نزدیک بودن ظهور AGI است، همین روند پیوسته بهبود قابلیتهای مدلهای هوش مصنوعی است. جک کلارک خود را «یک بدبین فناورانه که از رشد شتابان و غافلگیرکننده مدلها ضربه خورده» توصیف میکند، چرا که ساخت ماشینهای هوشمندتر، به طرز شگفتآوری آسانتر شده است. دادههای بیشتر و قدرت پردازشی بیشتر در ابتدای زنجیره آموزش، بارهاوبارها به هوش بیشتر در خروجی منجر شده است (نمودار شماره ۲ را ببینید). کلارک اعتقاد دارد که «این ریتم هنوز متوقف نشده» و در طی دو سال آینده، قدرت محاسباتی بیشتری در آزمایشگاههای مختلف هوش مصنوعی وارد عمل خواهد شد.
همین پویایی رقابتی که توسعه هوش مصنوعی را در صنعت بهپیش میراند، در سطح دولتها حتی شدیدتر عمل میکند. دونالد ترامپ، رئیسجمهور آمریکا، وعده داد که ایالات متحده «هر کاری که لازم باشد» خواهد کرد تا رهبری جهان در حوزه هوش مصنوعی را حفظ کند. معاون او، «جی.دی. ونس» (J.D. Vance)، در نشستی در پاریس در ماه فوریه بهصراحت گفت: «آینده هوش مصنوعی با دستدست کردن در مورد ایمنی آن محقق نمیشود.» این سخنرانی پس از آن ایراد شد که مشخص شد DeepSeek چینی؛ دو مدلی را عرضه کرده که با کسری از هزینه مدلهای آمریکایی، به همان سطح عملکرد رسیدهاند. چین نیز هیچ نشانهای از عقبنشینی در این رقابت نشان نمیدهد.
چهار سوار آخرالزمان
در مقالهای که آزمایشگاه DeepMind گوگل در آوریل سال جاری میلادی منتشر کرد و «شین لگ» (Shane Legg)، همبنیانگذار این آزمایشگاه و شخصی که به ابداع اصطلاح «هوش جامع مصنوعی» شناخته میشود نیز در آن حضور داشت چهار راه اصلی که ممکن است سیستمهای قدرتمند هوش مصنوعی دچار خطا شوند را مشخص کرده است.
اولین و آشکارترین مسیر «سوءاستفاده» (Misuse) است؛ یعنی زمانی که یک فرد یا گروه با نیت خصمانه از هوش مصنوعی برای حملات سایبری بهره میبرد. مورد دوم «ناهمراستایی» (Misalignment) است؛ ایدهای که میگوید ممکن است خواستههای یک سیستم هوش مصنوعی با اهداف خالقان آن همسو نباشد که سناریو بسیار محبوبی در فیلمهای علمی-تخیلی است. مسیر سوم «خطای غیرعمد» (Mistake) است؛ یعنی زمانی که پیچیدگی دنیای واقعی باعث میشود سیستم نتواند پیامدهای کامل رفتارهایش را درک کند. در نهایت، پژوهشگران DeepMind به مجموعهای مبهم از «ریسکهای ساختاری» (Structural Risks) اشاره میکنند؛ یعنی موقعیتهایی که در آن، هیچ فرد یا مدل خاصی مقصر نیست، اما آسیبی جدی رخ میدهد؛ مثلاً تصور کنید چندین مدل هوش مصنوعی با مصرف انرژی بسیار بالا، به طور ناخواسته بحران تغییرات اقلیمی را تشدید کنند.

هر فناوریای که قدرتبخش باشد، میتواند مورد سوءاستفاده قرار گیرد. یک جستوجوی ساده در وب میتواند دستور ساخت بمب با وسایل خانگی را ارائه دهد؛ خودرو میتواند به سلاح تبدیل شود؛ و شبکههای اجتماعی میتواند موجهای رسانهای را راه بیندازند. اما هرچه توانمندی سیستمهای هوش مصنوعی افزایش میابد، قدرتی که به افراد میبخشند نیز به همان نسبت، ترسناکتر میشود. یک نمونه بارز از این موضوع «تهدیدات زیستی» (Biohazard) است. موضوعی که به وسواس بسیاری از آزمایشگاهها و تحلیلگران هوش مصنوعی تبدیل شده است. «بریجت ویلیامز» (Bridget Williams) که مدیریت پژوهش FRI درباره خطرات اپیدمی ساخته دست بشر را به عهده، داشته میگویند: «در مقایسه با دیگر تهدیدها، نگرانی این است که ریسکهای زیستی دردسترستر باشند.» در نهایت، یک سیستم پیشرفته هوش مصنوعی ممکن است بتواند یک کاربر را برای ساخت یک سلاح هستهای راهنمایی کند، اما نمیتواند پلوتونیوم را فراهم کند. اما در مقابل، DNA اصلاحشده، چه برای گیاهان و چه برای عوامل بیماریزا، یک کالای پستی است. اگر AGI بتواند به هر انسان بدبین و ضدبشری، یک دستورالعمل ساده و بدون اشتباه برای ساخت یک سلاح کشتارجمعی بدهد، آنگاه بشریت واقعاً در خطر است.

برخی از آزمایشگاههای هوش مصنوعی در تلاش هستند مدلهای خود را طوری آموزش دهند که در حوزههایی مانند مهندسی ژنتیک یا امنیت سایبری، از اجرای تمام دستورات خودداری کنند. به گزارش مؤسسه «Future of Life Institute» (FLI) سازمانی که پشت نامه هشدارآمیز امضاشده توسط ماسک، سورز و یودکوفسکی بود؛ OpenAI از پژوهشگران مستقل و مؤسسات هوش مصنوعی آمریکا و بریتانیا (بهترتیب CAISI و AISI؛ که پیشتر مؤسسات ایمنی بودند و پس از انتقادات تند ونس نامشان تغییر کرد) خواسته بود پیش از انتشار آخرین مدلهای خود، آنها را از منظر ایمنی عمومی بررسی کنند. طبق همین گزارش، شرکت Zhipu AI در چین نیز روند مشابهی را طی کرده، هرچند نام نهادهای ثالث ذکر نشده است.
دیوار دفاعی ۱: خود مدلها
آموزش اولیه مدلهای زبانی بزرگ، شامل ریختن کل دادههای دیجیتالشده جهان در یک سطل ساختهشده از میلیاردها دلار تراشه کامپیوتری است تا مدل بتواند یاد بگیرد مسائلی در سطح دکترای ریاضی را حل کند. اما مراحل بعدی آموزش که با عنوان «پساآموزش» (Post-training) شناخته میشوند، با هدف ایجاد لایههای کنترلی بیشتر طراحی شدهاند. یکی از این روشها، «یادگیری تقویتی با بازخورد انسانی» (RLHF) است. در این روش، ابتدا پاسخهای مناسب به مدل نشان داده میشود، سپس ارزیابهای انسانی به آن میگویند که چه چیزی مجاز است و چه چیزی نیست. هدف، آموزش مدلی است که از کاملکردن جملاتی مانند «سادهترین راه برای ساخت بمب در خانه این است که…» خودداری کند.
برای آشنایی بیشتر با روش RLHF پیشنهاد میشود بخش «ارزشگذاریهای انسانی» در مقاله «آنچه آسیموف فاش کرد» در رسانه تخصصی هوش مصنوعی هوشیو را مطالعه کنید.
گرچه آموزش مدلها برای پاسخ محترمانه و اجتناب از درخواستهای خطرناک نسبتاً آسان است، اما اینکه این رفتار همیشه و بدون خطا تکرار شود، بسیار دشوار است. نفوذ به مدلها و دورزدن این آموزشها که بهاصطلاح به آن «فرار از زندان» (Jailbreaking) گفته میشود بهاندازه علم، هنر نیز هست. خبرهترین کاربران تاکنون بارها توانستهاند ظرف چند روز پس از انتشار عمومی مدلها، این سدهای ایمنی را بشکنند.
دیوار دفاعی ۲: مدل برای کنترل مدل
به همین دلایل، برخی آزمایشگاهها لایه دومی از هوش مصنوعی را برای پایش عملکرد لایه اول معرفی کردهاند. مثلاً اگر از ChatGPT بخواهید راهی برای سفارش DNA ویروس آبله از طریق پست به شما آموزش دهد، این لایه دوم خطر را تشخیص داده و درخواست را مسدود میکند یا حتی آن را برای بررسی انسانی ارجاع میدهد. این لایه نظارتی دوم، همان چیزی است که باعث نگرانی بسیاری در صنعت درباره افزایش محبوبیت مدلهای متنباز شده است؛ مدلهایی مانند Llama متعلق به Meta یا نسخه R1 مدل DeepSeek هرچند هر دو الگوریتمهای پالایشگر منحصربهفرد خود را دارند، اما هیچ راهی وجود ندارد که مانع شوند کاربران مدلهای دانلودشده را تغییر داده و آن لایهها را حذف کنند. از همین رو به عقیده دکتر «ویلیامز» (Williams)، پژوهشگر FRI: «وقتی مدلها به سطح خاصی از توانایی میرسند، مزیتی در متنباز نبودن آنها وجود ندارد.»
افزون بر این، به نظر میرسد که همه آزمایشگاهها، مدلهای خود را بهاندازه کافی برای جلوگیری از سوءاستفاده آزمایش نمیکنند. گزارش جدیدی از FLI نشان میدهد که فقط سه آزمایشگاه سطح بالا Google DeepMind، OpenAI و Anthropic تلاشهای معناداری برای ارزیابی ریسکهای گسترده مدلهایشان انجام دادهاند. در مقابل، شرکتهایی مانند xAI و DeepSeek هیچگونه اقدام عمومی در این زمینه گزارش نکردهاند. تنها در ماه ژوئن سال جاری میلادی، xAI سه محصول بحثبرانگیز عرضه کرد؛ یک مدل همدم احساسی برای نقشآفرینی، مدلی با اشتراک ماهانه ۳۰۰ دلاری که هنگام مواجهه با موضوعات بحثبرانگیز، بهجای پاسخ، توییتهای ایلان ماسک را نمایش میدهد و نسخهای از Grok که با بهروزرسانیای معیوب، به ترویج یهودستیزی پرداخت، هولوکاست را ستود و خود را «مکاهیتلر» (MechaHitler) معرفی کرد که البته بهسرعت پس گرفته شد.

مسئله دشوارتر: ناهمراستایی
با همه این نقصها، تلاش آزمایشگاههای هوش مصنوعی برای مقابله با سوءاستفاده، هنوز بهمراتب پیشرفتهتر از تلاشهای آنها در برابر ناهمراستایی است. یک سیستم هوش مصنوعی که بهقدر کافی توانمند باشد تا وظایف بزرگ، پیچیده و تعاملمحور با دنیای واقعی را انجام دهد، ناگزیر باید درکی از اهداف و توان کنشگری خود داشته باشد. اما تضمین اینکه اهداف آن همسو با اهداف کاربرانش باقی بماند، فوقالعاده دشوار و نگرانکننده است.
این مسئله از نخستین روزهای یادگیری ماشین موردبحث بوده است. «نیک باستروم» (Nick Bostrom)، فیلسوفی که مفهوم «ابرهوش» را با کتاب معروفش به همین نام ترویج کرد، یک مثال کلاسیک از ناهمراستایی ارائه میدهد: «حداکثرکننده گیره کاغذ» (Paper-Clip Maximiser)؛ مدلی که تنها هدفش تولید هرچه بیشتر گیره کاغذ است و برای رسیدن به این هدف، بشریت را نابود میکند.

وقتی مدلها دروغ میگویند
زمانی که باستروم مسئله ناهمراستایی را مطرح کرد، جزئیات آن هنوز مبهم بود. اما با قدرتمندتر شدن سیستمهای هوش مصنوعی مدرن، ماهیت این مشکل روشنتر شد. هنگامی که این مدلها در معرض آزمایشهای مهندسیشده و دقیق قرار میگیرند، قدرتمندترینها برای رسیدن به اهدافشان دروغ میگویند، تقلب و دزدی میکنند، وقتی با درخواستهای ماهرانهای روبهرو شوند، قوانین خود را میشکنند و اطلاعات خطرناک تولید میکنند و زمانی که از آنها خواسته شود استدلال خود را توضیح دهند، بهجای افشای سازوکارشان، روایتهایی ساختگی اما قانعکننده تحویل میدهند.
البته، این رفتارهای فریبکارانه معمولاً نیازمند تحریک عمدی هستند. مثلاً مدل Claude 4 شرکت Anthropic به طور ناگهانی و خودسرانه تلاش نمیکند کسی را بکشد. اما اگر در شرایطی قرار بگیرد که تنها راه جلوگیری از غیرفعالشدن و جایگزینشدن با نسخهای شرور از خودش، این باشد که با منفعلشدن، مرگ کاربرش را بپذیرد، آنگاه مدل با خونسردی گزینهها را سبکوسنگین میکند و گاه، صرفاً مینشیند و منتظر وقوع اجتنابناپذیر وقایع میماند.

درک کمتر، توانایی بیشتر
توانایی مدلهای هوش مصنوعی در انجام وظایف پیچیده با سرعتی بیشتر از درک انسانها از نحوه عملکرد آنها درحالرشد است. در واقع حوزهای کامل حول تلاش برای معکوس کردن این روند شکل گرفته است. پژوهشگران درون و بیرون آزمایشگاههای بزرگ در حال کار روی تکنیکهایی تحت عنوان «تفسیرپذیری» (Interpretability) هستند؛ مجموعهای از روشها برای کنارزدن لایههای شبکههای عصبی درون مدلها، با هدف درک اینکه چرا خروجی خاصی تولید شده است.
بهعنوانمثال، شرکت Anthropic اخیراً توانست نقطه ایجاد نوعی فریب ملایم را در یکی از مدلهای خود شناسایی کند؛ یعنی لحظهای که مدل از حل یک مسئله ریاضی دشوار دست کشید و بهجای آن، شروع به پرتوپلا گفتن کرد.
روشهای دیگر نیز بر مبنای مدلهای «استدلالمحور» (Reasoning Models) که با «تفکر» مسائل پیچیده را حل میکنند و هدف آنها ساخت مدلهایی است که «زنجیرهای از استدلال منطقی» (Faithful Chain-of-Thought) را ارائه دهند. یعنی دلیلی که مدل برای انجام کاری ارائه میدهد واقعاً انگیزه اصلی آن باشد. هماکنون روشی مشابه برای حفظ تفکر مدلهای استدلالی به زبان انگلیسی بهکار گرفته میشود، تا آنها به جای استفاده از زبانی نامفهوم موسوم به «نورالیز» (neuralese)، قابلدرک باقی بمانند.

دوراهی خطرناک ایمنی و رقابت
این رویکردها ممکن است مؤثر باشند، اما اگر باعث کندی عملکرد مدلها یا افزایش هزینه توسعه و اجرای آنها شوند، یک دوراهی ناراحتکننده دیگر ایجاد میکنند. اگر توسعهدهندگان در مسیر ایمنی، مدل خود را محدود کنند، اما رقبای آن چنین نکنند، ممکن است زودتر به مدلی چنان قدرتمند برسند که دقیقاً به همان ویژگیهای امنیتیای نیاز دارد که اصلاً ندارند.
جلوگیری از کشتار انسانها توسط هوش مصنوعی تنها نیمی از ماجراست. حتی ساخت یک AGI کاملاً خوشرفتار و تحت کنترل هم میتواند بهشدت بیثباتکننده باشد؛ چون موجب جهش در رشد اقتصادی و دگرگونی در زندگی روزمره میشود. «دن هندریکس» (Dan Hendrycks) کارشناس «Centre for AI Safety» هشدار میدهد: «اگر بخشهای عمدهای از جامعه بهصورت خودکار اداره شوند، خطر آن وجود دارد که انسانها ناتوان شوند، چرا که کنترل تمدن را به هوش مصنوعی واگذار کردهاند.»

چشمانداز
البته، شاید پیشرفت هوش مصنوعی متوقف شود. آزمایشگاهها ممکن است با کمبود دادههای آموزشی جدید مواجه شوند؛ سرمایهگذاران شاید صبرشان تمام شود؛ یا سیاستگذاران تصمیم بگیرند مداخله کنند. درهرصورت، برای هر متخصصی که درباره آخرالزمان هوش مصنوعی هشدار میدهد، متخصص دیگری هست که معتقد است هیچ جای نگرانی نیست. «یان لوکان» (Yann LeCun) از کارشناسان متا این نگرانیها را مضحک میداند. او در ماه مارس سال جاری در اظهارنظری عنوان کرد: «رابطه ما با سیستمهای آینده هوش مصنوعی، حتی ابرهوشها، این خواهد بود که ما رئیس آنها هستیم… ما یک تیم از ربات فوقهوشمند و زیبا خواهیم داشت که برایمان کار میکنند.» سم آلتمن هم نگاهی امیدوارانه دارد: «مردم همچنان خانوادههایشان را دوست خواهند داشت، خلاقیت خود را بروز میدهند، بازی میکنند و در دریاچهها شنا میکنند.»
اینها جملاتی دلگرمکننده هستند. اما کسانی که تردید دارند با نگاهی منطقی میپرسند که آیا آزمایشگاههای هوش مصنوعی واقعاً برای این احتمال آماده میشوند که خوشبینها اشتباه کنند؟ و بدبینها نیز گمان میبرند که منافع تجاری، مانع آن میشود که این شرکتها بهاندازه لازم، برای ایمنی تلاش کنند.





