
ChatGPT و Gemini با زبانهای متفاوتی مینویسند
هر چتبات سبک نویسندگی خاص خود را دارد؛ درست مانند انسانها
 سید محمدجواد فیاض
سید محمدجواد فیاض- ۱۷ شهریور ۱۴۰۴
آخرین باری که با ChatGPT تعامل کردید؛ حس کردید با یک نفر در حال گپزدن هستید یا انگار با چند شخص مختلف صحبت میکنید؟ آیا به نظر میرسید چتبات شخصیت ثابتی دارد یا هر بار که با آن ارتباط برقرار کردید، متفاوت به نظر میآمد؟
زبانشناسان میدانند که هر فرد شیوهای منحصربهفرد برای بیان خود دارد که به زبان مادری، سن، جنسیت، تحصیلات و عوامل دیگر بستگی دارد که به این سبک گفتاری فردی «گویش فردی» (Idiolect) گفته میشود. این مفهوم شبیه به گویش، اما بسیار محدودتر از آن است؛ زیرا گویش به نوع زبانی اشاره دارد که یک جامعه صحبت میکند. سؤالی که در نشریه معتبر Scientific American مطرح شد این بود که آیا میتوان زبان تولیدشده توسط ChatGPT را تحلیل کرد تا فهمید آیا این زبان به شیوهای واحد و متمایز بیان میشود یا خیر؟
گویش فردی
گویش فردی یا ایدیولکتها در زبانشناسی قانونی (forensic linguistics) نقش مهمی دارند. این حوزه به بررسی استفاده از زبان در مصاحبههای پلیس با مظنونان، تعیین نویسنده اسناد و پیامهای متنی، ردیابی پیشینه زبانی پناهجویان و تشخیص سرقت ادبی میپردازد. گرچه هنوز نیازی به قرار دادن LLMها در جایگاه متهم نداریم، اما تعداد بسیاری افراد از جمله معلمان، نگران این هستند که استفاده از این مدلها توسط دانشآموزان؛ مثلاً با سپردن تکالیف نوشتاری به آنها، ضرر بیشتری نسبت به منفعتش داشته باشد.

عناصر شیوه
برای بررسی اینکه آیا متنی توسط یک LLM تولید شده یا نه؛ میبایست نهتنها محتوا، بلکه شکل یعنی زبان استفادهشده را نیز موردبررسی قرار دهیم. تحقیقات نشان میدهد که ChatGPT تمایل دارد از دستور زبان استاندارد و عبارات آکادمیک استفاده کند و از زبان عامیانه (shunning slang) و اصطلاحات محاورهای (colloquialisms) اجتناب میکند. در مقایسه با متنهایی که توسط نویسندگان واقعی نوشته شدهاند، ChatGPT معمولاً بیش از حد از افعال پیچیدهای مانند «کاوشکردن» (delve)، «همراستاکردن» (align) و «تأکیدکردن» (underscore) و صفتهایی مانند «قابلتوجه» (noteworthy)، «چندمنظوره» (versatile) و «ستودنی» (commendable) استفاده میکند. میتوان این واژهها را بهعنوان ویژگیهای معمولی گویش فردی ChatGPT در نظر گرفت. اما آیا ChatGPT در مقایسه با دیگر ابزارهای مبتنی بر مدلهای زبانی، هنگام بحث درباره یک موضوع یکسان، ایدهها را بهگونهای متفاوت بیان میکند؟
مخازن آنلاین پر از مجموعهدادههای شگفتانگیزی هستند که میتوان از آنها برای پژوهش استفاده کرد. یکی از این مجموعهها، دادههایی است که توسط «محمد نوید» (Muhammad Naveed) دانشمند کامپیوتر، گردآوری شده و شامل صدها متن کوتاه درباره دیابت است که توسط ChatGPT و Gemini نوشته شدهاند. این متنها تقریباً هماندازه هستند و طبق توضیحات سازندهشان، میتوانند «برای مقایسه و تحلیل عملکرد هر دو مدل هوش مصنوعی در تولید محتوای اطلاعرسان و منسجم درباره یک موضوع پزشکی» استفاده شوند. شباهت در موضوع و اندازه، این متنها را برای تعیین اینکه آیا خروجیها به نظر از دو «نویسنده» مجزا یا از یک «فرد» واحد آمدهاند، ایدهآل میکند.
یکی از روشهای محبوب برای شناسایی نویسنده، روش دلتا است که در سال ۲۰۰۱ توسط «جان باروز» (John Burrows)، پیشگام سبکشناسی محاسباتی معرفی شد. این فرمول فرکانس واژههای پرکاربرد در متنها را مقایسه میکند؛ شامل واژههایی مانند «و»، «آن»، «از»، «این»، «آنکه» و «برای» (“it,” “of,” “the,” “that” and “for”) که برای بیان روابط با دیگر کلمات به کار میروند و واژههای محتوایی مانند «گلوکز» یا «شکر» (“glucose” or “sugar”). بهاینترتیب، روش دلتا ویژگیهایی را ثبت میکند که بسته به گویش فردی نویسندگان تغییر میکنند. بهویژه، این روش اعدادی را تولید میکند که فاصله زبانی بین متن موردبررسی و متنهای مرجع از نویسندگان از پیش انتخابشده را اندازهگیری میکند. هرچه این فاصله کمتر باشد (که معمولاً کمی کمتر یا بیشتر از ۱ است) احتمال اینکه نویسنده یکسان باشد، بیشتر است.
طبق گفته نویسنده Scientific American، نمونه تصادفی شامل ۱۰ درصد از متنهای مربوط به دیابت تولیدشده توسط ChatGPT، فاصلهای برابر با ۰.۹۲ با کل مجموعهداده دیابت ChatGPT و فاصلهای برابر با ۱.۴۹ با کل مجموعهداده Gemini دارد. به طور مشابه، نمونه تصادفی ۱۰ درصدی از متنهای Gemini ، فاصلهای برابر با ۰.۸۴ با Gemini و ۱.۴۵ با ChatGPT دارد. در هر دو مورد، تمایز در نویسنده بودن کاملاً مشخص است و نشان میدهد که مدلهای این دو ابزار سبکهای نوشتاری متمایزی دارند.

شکر یا گلوکز
برای درک بهتر این سبکها، فرض کنیم در حال بررسی متنهای مربوط به دیابت هستیم و کلمات را در گروههای سهتایی انتخاب میکنیم. این ترکیبها «سهخطی» (trigram) نامیده میشوند. با مشاهده اینکه کدامیک از سهخطیها بیشتر استفاده شدهاند، میتوانیم حس کنیم که هر کدام چگونه کلمات را به شیوهای منحصربهفرد کنار هم قرار میدهد. نویسنده Scientific American؛ ۲۰ تریگرام پرکاربرد را برای مقایسه ChatGPT و Gemini استخراج و مقایسه کرد.
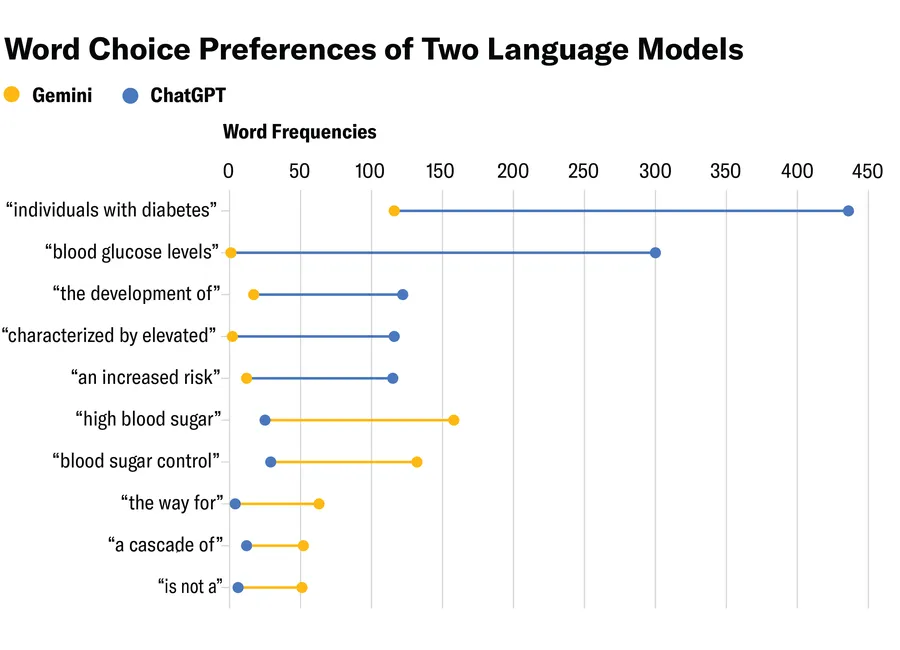
تریگرامهای ChatGPT در این متنها نشاندهنده گویش فردی رسمیتر، بالینی و آکادمیک است؛ با عباراتی مانند «افراد مبتلا به دیابت» (individuals with diabetes)، «سطوح گلوکز خون» (blood glucose levels)، «توسعه» (the development of)، «مشخصشده با افزایش» (characterized by elevated) و «خطر افزایشیافته» (an increased risk). در مقابل، تریگرامهای Gemini محاورهایتر و توضیحیتر هستند؛ با عباراتی مثل «راهی برای» (the way for)، «مراتبی از» (the cascade of)، «نیست» (is not a)، «قند خون بالا» (high blood sugar) و «کنترل قند خون» (blood sugar control). انتخاب واژههایی مانند «شکر» بهجای «گلوکز» نیز نشاندهنده ترجیح زبانی ساده و قابلفهم است.
نمودار زیر برجستهترین تفاوتهای مربوط به فرکانس بین تریگرامها را نشان میدهد. Gemini عبارت رسمی «سطوح گلوکز خون» را تنها یکبار در کل مجموعهداده استفاده کرده؛ پس این عبارت را میشناسد، اما به نظر میآید از آن اجتناب میکند. در مقابل، «قند خون بالا» در پاسخهای ChatGPT تنها ۲۵ بار ظاهر شده، درحالیکه در پاسخهای Gemini به تعداد ۱۵۸ بار دیده میشود. در واقع، ChatGPT واژه «گلوکز» را بیش از دوبرابر بیشتر از «شکر» به کار برده، درحالیکه Gemini دقیقاً برعکس عمل کرده و «شکر» را بیش از دوبرابر بیشتر از «گلوکز» استفاده کرده است.
چرا مدلهای زبانی بزرگ گویش فردی پیدا میکنند؟
این پدیده ممکن است با «اصل کمترین تلاش» (Principle of least effort) یعنی تمایل به انتخاب سادهترین راه برای انجام یک کار مرتبط باشند. وقتی واژه یا عبارتی در طول آموزش وارد گنجینه زبانی آنها میشود، مدلها ممکن است به استفاده از آن ادامه دهند و آن را با عبارات مشابه ترکیب کنند، درست مانند انسانهایی که واژهها یا عبارات موردعلاقهای دارند که در گفتار یا نوشتارشان بیش از حد معمول استفاده میکنند. حتی ممکن است شاید نوعی آمادهسازی (priming) باشد؛ چیزی که برای انسانها هم رخ میدهد، وقتی واژهای میشنویم و احتمال استفاده از آن در ما بیشتر میشود. شاید هر مدل بهنوعی خودش را با واژههایی که مکرراً استفاده میکند، آماده میکند. گویشهای فردی در مدلهای زبانی بزرگ ممکن است بازتابدهنده تواناییهای نوظهوری نیز باشند؛ مهارتهایی که مدلها به طور خاص برای انجام آنها آموزش ندیدهاند، اما بااینحال آنها را نشان میدهند.

اینکه ابزارهای مبتنی بر مدلهای زبانی ایدیولکتهای متفاوتی تولید میکنند که ممکن است با بهروزرسانیها یا نسخههای جدید تغییر کرده و توسعه یابند؛ برای بحثهای جاری درباره اینکه هوش مصنوعی تا چه حد به هوش انسانی نزدیک است، اهمیت دارد. این موضوع که اگر چتباتها فقط دادههای آموزشی خود را میانگین نگیرند یا بازتاب ندهند، بلکه عادتهای واژگانی، دستوری یا نحوی متمایزی در این فرایند پیدا کنند، درست مانند انسانهایی که توسط تجربیاتشان شکل میگیرند؛ تفاوتهای اساسی را ایجاد میکند. در همین حال، دانستن اینکه مدلهای زبانی بزرگ با ایدیولکت مینویسند، میتواند کمک کند تا مشخص شود آیا یک مقاله یا نوشته توسط یک مدل تولید شده یا توسط فردی خاص نوشته شده است؛ درست مانند اینکه ممکن است پیام یک دوست را در چت گروهی از روی سبک خاصش تشخیص دهید.





