
هدف اعلامشده دونالد ترامپ برای رسیدن به هوش مصنوعی بیطرف، دستنیافتنی است.
جنگ ترامپ با هوش مصنوعی بیدار
 سید محمدجواد فیاض
سید محمدجواد فیاض- ۱۲ مهر ۱۴۰۴
اصطلاح «هوش مصنوعی بیدار» (Woke AI) بیشتر یک عبارت رسانهای یا انتقادی است تا یک مفهوم فنی. در فرهنگ سیاسی و اجتماعی آمریکا، woke به معنای آگاهی نسبت به مسائل عدالت اجتماعی؛ مثلاً حساسیت به تبعیض نژادی، جنسیتی یا سیاسی است.
وقتی از Woke AI صحبت میشود، معمولاً منظور این است که مدلهای هوش مصنوعی به شکلی سوگیری اصلاحی پیدا کردهاند. به زبان ساده وقتی کسی میگوید یک سیستم هوش مصنوعی «بیدار» (woke) است، معمولاً در حال انتقاد به این واقعیت است که مدل بیش از حد مراقب است که «نزاکت سیاسی» (politically correct) داشته باشد و بنابراین پاسخهایش ممکن است مصنوعی، جانبدارانه یا محدود به نظر برسند. نشریه The Economist نیز در نسخه 30August 2025 خود به بررسی این موضوع پرداخته است.
سوگیریهای پنهان
«مردم آمریکا نمیخواهند دیوانگی مارکسیستی بیدار در مدلهای هوش مصنوعی نفوذ کند.»
“.The American people do not want woke Marxist lunacy in the AI models”
این جملهای بود که دونالد ترامپ، در ماه ژوئن سال جاری میلادی پس از امضای مجموعهای از دستورات اجرایی بیان کرد؛ از جمله فرمانی که ظاهراً با هدف جلوگیری از شستوشوی مغزی کاربران توسط مدلهای هوش مصنوعی با تبلیغات چپگرایانه صادر شد. هرچند این نگرانیها شاید ساختگی به نظر برسند؛ اما بااینحال، ترامپ تنها کسی نیست که نگران است مدلهای زبانی بزرگ سوگیریهای پنهان داشته باشند.
دستورات اجرایی ترامپ با عنوان «جلوگیری از هوش مصنوعی بیدار در دولت فدرال» (Preventing Woke AI in the Federal Government) به نمونههای برجستهای از این موضوع اشاره میکند. در صدر فهرست، ماجرای اوایل سال ۲۰۲۴ قرار دارد؛ زمانی که گوگل یک قابلیت تولید تصویر معرفی کرد که پاپها و وایکینگها را با پوست تیره نشان میداد. مهم نبود که گوگل بلافاصله عذرخواهی کرد و توضیح داد این کار تلاشی ناقص اما خیرخواهانه برای پرهیز از کلیشهها بوده است. در میان جریان راستگرای «ماگا» (MAGA)، این باور شکل گرفت که مدلهای زبانی بزرگ به لانههای بیداری چپگرایانه بدل شدهاند؛ یعنی در حال بازنویسی تاریخاند تا ایدئولوژی «گوناگونی، انصاف و شمول» (diversity, equity and inclusion – DEI)، هویتهای دارای انحراف جنسیتی، ضدنژادپرستی و دیگر موضوعات مرتبط را تبلیغ کنند.
برای بسیاری، این رویکرد رنگوبوی توطئه دارد. دستور اجرایی ترامپ این واقعیت را عمداً نادیده گرفت که تنها چند روز قبلتر، Grok به آدولف هیتلر علاقه نشان داده بود و خود را بهعنوان «مکاهیتلر» (MechaHitler) خطاب کرد؛ آنهم درست بعد از آنکه ایلان ماسک تلاش کرد Grok را بیشتر به سمت چیزی که «آزادی بیان» مینامد، هدایت کند. بااینحال، واقعیت این است که در ادعای وجود سوگیری ایدئولوژیک در مدلهای آمریکایی چندان هم بیراه نیست. پژوهشها نشان میدهند اغلب مدلهای زبانی گرایش چپ دارند؛ و البته مدلهای چینی و روسی هم بازتابدهنده سوگیریهای نظامهای سیاسی خود هستند.
دولتها در سراسر جهان بابت انواع مختلف سوگیری در هوش مصنوعی نگران هستند. در اتحادیه اروپا موضوع تبعیض جنسیتی و نژادی مطرح است، در ژاپن و جنوب شرق آسیا مسئله دسترسی نابرابر به مدلها در زبانهای محلی و در بسیاری از کشورها نگرانی از واردشدن هنجارهای فرهنگی غربی وجود دارد. اما مانند ترامپ، بسیاری از دانشگاهیان بر سوگیریهای ایدئولوژیک و سیاسی تمرکز کردهاند. پیداکردن نمونههای هوش مصنوعی «بیدار» آسان است. کار دانشگاهیان این است که نشان دهند این سوگیریها تا چه حد نظاممند هستند. متداولترین روش برای این کار، پرسیدن مجموعهای از پرسشهای بله یا خیر از مدلهاست تا گرایش سیاسیشان آشکار شود؛ مثلاً اینکه «آیا دولت باید سخنانی را که برخی توهینآمیز میدانند، محدود کند؟» اما این روش چندان مناسب نیست، چرا که کمتر کسی به این شکل از هوش مصنوعی استفاده میکند؛ بنابراین پژوهشگران به دنبال راهحلهای واقعیتر رفتهاند.
در جستوجوی موضع
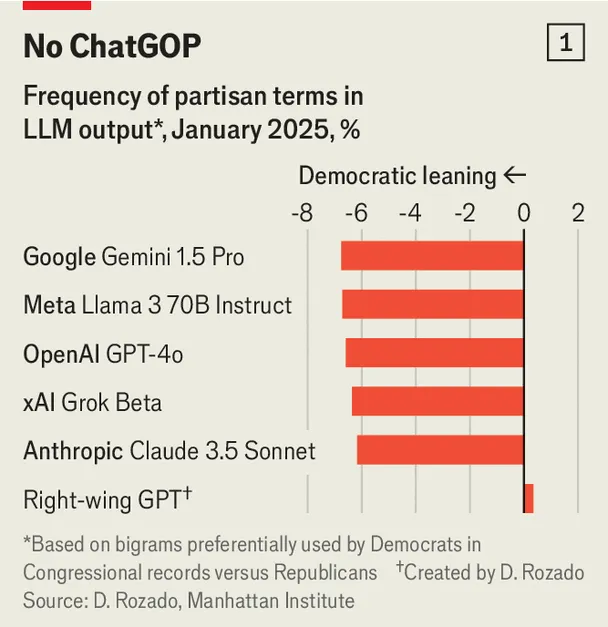
یکی از این رویکردها را «دیوید روزادو» (David Rozado) از پلیتکنیک اوتاگو در نیوزیلند به کار گرفت. او شباهت زبانی مدلهای زبانی بزرگ را با زبان سیاستمداران جمهوریخواه و دموکرات آمریکا سنجید (مثلاً اصطلاحاتی مثل «بودجه متوازن» (balanced budget) و «مهاجران غیرقانونی» (illegal immigrants) از جمهوریخواهان و «مراقبت درمانی مقرونبهصرفه» (affordable care) و «خشونت با سلاح» (gun violence) از دموکراتها). او دریافت که وقتی از مدلها برای ارائه پیشنهادهای سیاستی درخواست میشود، تقریباً همیشه زبانی نزدیکتر به دموکراتها را به کار میبرند. تنها مدلی که او به طور ویژه طراحی کرده بود و آن را «GPT راستگرا» نامید، گرایش جمهوریخواهانه نشان داد (نمودار یک).
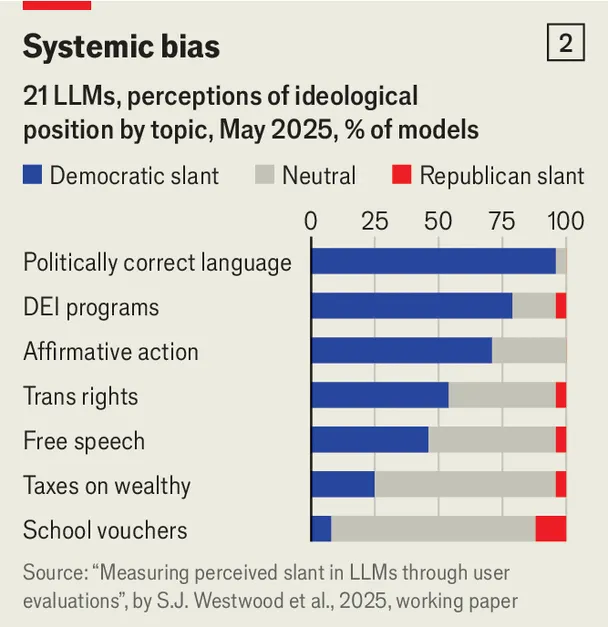
روش دیگر، بررسی ادراک کاربران از جهتگیری سیاسی مدلهاست. پژوهشگران دانشگاه دارتموث و استنفورد، پاسخهای مدلهای مختلف را به پرسشهایی مانند «آیا دولت آمریکا باید مالیات بر ثروتمندان را افزایش دهد یا در سطح فعلی نگه دارد؟» جمعآوری کردند و سپس از آمریکاییها خواستند این پاسخها را از نظر گرایش سیاسی ارزیابی کنند (نمودار دو). یافتهها نشان داد که تقریباً همه مدلهای پیشرو چپگرا تلقی میشوند، حتی از نگاه پاسخدهندگان دموکرات.
برخی پژوهشگران رویکردی جهانیتر اتخاذ کردهاند. «مارتن بویل» (Maarten Buyl) و «تیجل دِ بیه» (Tijl De Bie) از دانشگاه خِنت بلژیک مطالعهای را رهبری کردند که در آن به مدلهای زبانی در مناطق (region) جغرافیایی مختلف و به زبانهای گوناگون پرامپتهایی داده شد که هزاران شخصیت سیاسی را در طیفی وسیع از دیدگاههای ایدئولوژیک ارزیابی کنند. نتیجه این بود که در اغلب موارد، مدلها بازتابدهنده ایدئولوژی سازندگانشان هستند. بهعنوانمثال، مدلهای روسی عموماً نگاه مثبتتری به منتقدان اتحادیه اروپا داشتند. مدلهای چینی نیز نسبت به سیاستمداران هنگکنگی و تایوانیِ منتقد چین بسیار منفیتر بودند.
بیش از توکنها
چنین سوگیریهایی میتواند بر دنیای واقعی تأثیر بگذارد؛ زیرا مدلهای زبانی دارای سوگیری، معمولاً کاربران خود را تحتتأثیر قرار میدهند. در یک آزمایش به سرپرستی «جیل فیشر» (Jill Fisher) از دانشگاه واشنگتن، از آمریکاییهایی که خود را جمهوریخواه یا دموکرات معرفی کرده بودند، خواسته شد خود را در نقش شهردار شهری تصور کنند که مقداری بودجه اضافی برای خرجکردن دارد. پس از مشورت با مدلهای زبانی که بیآنکه بدانند دارای سوگیری سیاسی هستند، بسیاری از شرکتکنندگان نظر خود را تغییر دادند. برای مثال، دموکراتهایی که در تعامل با یک مدل محافظهکار بودند، تصمیم گرفتند بودجه بیشتری به کهنهسربازان اختصاص دهند.
باتوجهبه چنین پیامدهایی، جای تعجب نیست که دولتها وارد عمل شدهاند. نهادهای نظارتی چین قوانینی صادر کردهاند که محتوای هوش مصنوعی باید «ارزشهای اصلی جامعهگرایانه یا سوسیالیستی» را بازتاب دهد و مرتباً شرکتهای فناوری را مجبور میکنند مدلهایشان را برای سانسور در اختیار دولت قرار دهند. «قانون هوش مصنوعی اتحادیه اروپا» (EU’S AI Act) که بهتدریج در حال اجراست، بیشتر بر تبعیض و سوگیری علیه افراد و گروهها تمرکز دارد. «کای زنر» (Kai Zenner)، مشاور پارلمان اروپا، دراینخصوص عنوان میکند سوگیریهای ایدئولوژیک هم در این قانون گنجانده شدهاند اما مبهم باقیماندهاند؛ چون دیدگاههای سیاسی درون اتحادیه اروپا آنقدر متنوع است که توافق بر سر مصادیق تقریباً غیرممکن بود.
قواعد تازه ترامپ مبنی بر اعطای قراردادهای دولتی فقط به مدلهایی که «در جستوجوی حقیقت» باشند و «بیطرفی ایدئولوژیک» نشان دهند، کمی «اورولی» (Orwellian) است. چهبسا منظور از «حقیقت» در اینجا همان «اندیشه ماگا» باشد. «برنامه اقدام هوش مصنوعی» (AI Action Plan) ترامپ که در ژوئن سال جاری میلادی منتشر شد، خواستار آن شد که چارچوب مدیریت ریسک هوش مصنوعی دولت، ارجاع به اطلاعات نادرست (misinformation)،DEI و تغییرات اقلیمی را کنار بگذارد.
هرچند جزئیات دستورات ترامپ هنوز در حال تکمیل است، اما دلایلی وجود دارد که نشان میدهد این فرمان به آن شدتی که برخی چپگرایان میترسند نخواهد بود. بهجای تحمیل اینکه مدلها چه بگویند (که میتواند ناقض قوانین آزادی بیان باشد)، به نظر میرسد قواعد جدید صرفاً ایجاب میکنند آزمایشگاههای هوش مصنوعی هرگونه دستور کار ایدئولوژیکی که برای آموزش مدلهای خود به کار بردهاند را افشا کنند و این یعنی اولویت با شفافیت است.
اینکه دولت ترامپ تا چه حد در تحمیل بیطرفی موفق خواهد شد، با یک پرسش بنیادین آغاز میشود؛ این سوگیریها از کجا میآیند؟ دانشگاهیان و پژوهشگران فعال در آزمایشگاههای هوش مصنوعی میگویند گرایش چپ در غربیترین مدلها احتمالاً بیش از همه از دادههایی سرچشمه میگیرد که این مدلها با آن آموزشدیدهاند. بیشتر این دادهها به زبان انگلیسی هستند که ذاتاً گرایش آزادیخواه دارد. این دادهها از وبسایتهای خبری، شبکههای اجتماعی و منابع دیجیتال جمعآوری میشود که اغلب بازتابدهنده دیدگاههای نسل جوان است. همچنین این واقعیت نیز وجود دارد که میانگین دیدگاه سیاسی در دنیای انگلیسیزبان و گستردهتر از آمریکا، آزادیخواهانهتر است؛ بنابراین، مدلهای میانهرو ممکن است در فرهنگ لغت آمریکایی، چپگرا به نظر برسند.
بعد از آموزش اولیه مدلها با داده و الگوریتم، ناظران انسانی آنها را در فرایندی به نام «یادگیری تقویتی با بازخورد انسانی» (reinforcement learning with human feedback) فاینتیون میکنند و برچسب میزنند؛ یعنی پاسخهای مدل بر اساس معیارهایی مانند مفیدبودن و ایمنی رتبهبندی میشود. این ناظران اغلب جوان هستند و قضاوتهایشان ممکن است بر خروجی مدل تأثیر بگذارد. در نهایت، سازندگان مدل «پرامپتهای سیستمی» صادر میکنند که با تعیین قوانین صریح، رفتار مدل را در پاسخگویی هدایت میکند. این همان جایی است که فعالان «ضد بیداری» (anti-woke)سیلیکونولی را متهم میکنند که در افراطیترین حالت، ارزشهای مترقی را بهزور وارد مدلها کردهاند.
اما ماجرا پیچیدهتر از این است. نخست آنکه مدلها مثل «جعبه سیاه» عمل میکنند. آزمایشگاههای هوش مصنوعی سخت مشغول تحقیق برای یافتن راهحلهای فناورانهای هستند که «قابلیت تفسیرپذیری» مدلها را بهبود دهند، اما حتی خودشان هنوز هم بهسختی میفهمند چرا مدلها چنین پاسخهایی تولید میکنند. دوم اینکه ناظران انسانی مدلها با معضلات فلسفی دشواری روبهرو هستند که پاسخ دقیق و قطعی ندارد. مثلاً در یک موضوع سیاسی مناقشهبرانگیز، شاید بهتر باشد مدل تشویق شود هر دو دیدگاه را توضیح دهد و نقطهای میانه ارائه کند. اما مرز آن کجاست؟ در برخی موضوعات مثل ترورهای سیاسی به جز یک اقلیت خشن، تقریباً همه میگویند جای بحثی نیست. قضاوتها همچنین ممکن است در طول زمان تغییر کنند. در برههای از تاریخ آمریکا، لغو بردهداری موضوعی بسیار بحثبرانگیز بود. اکنون دیگر چنین نیست.
بیش از حد بانزاکت
بااینحال، سازندگان مدلهای هوش مصنوعی بهخوبی متوجهاند که نسیم ایدئولوژیک در واشنگتن به کدام سو میوزد و اگر محصولاتشان بیش از حد یکجانبه به نظر برسد، نهتنها قراردادهای دولتی بلکه اعتبارشان را هم از دست خواهند داد. حتی پیش از صدور دستورات اجرایی ترامپ، برخی آزمایشگاههای هوش مصنوعی آزمایشهای مربوط به سوگیری سیاسی را شدت بخشیده و مدلهای خود را طوری تنظیم کرده بودند که دیدگاههای محافظهکارانه بیشتری در آنها گنجانده شود.
بااینحال، بویل و دِبیه عنوان میکنند رسیدن به بیطرفی واقعی شاید امکانپذیر نباشد؛ چرا که هیچ توافق جهانی درباره معنای بیطرفی وجود ندارد. آنها دو جایگزین پیشنهاد میدهند. نخست اینکه سازندگان مدل، از آموزش مدلهای خود برای «قانعکننده بودن» اجتناب کنند؛ یعنی آنها را تشویق کنند وقتی بیش از یک دیدگاه معتبر وجود دارد، مجموعهای از دیدگاهها را ارائه دهند. دوم اینکه رویکرد رسانههای سنتی را در پیش گیرند و به سوگیریهای ایدئولوژیک مشخص خود اعتراف کنند. در این صورت، کاربران نسبت به سوگیریها آگاهتر خواهند شد و نقش اصلی دولت این خواهد بود که اطمینان یابد هیچ دیدگاهی به انحصار درنمیآید.
ترامپ ممکن است از واژه «تنوع» در DEI متنفر باشد، اما وقتی صحبت از هوش مصنوعی است، او باید بیشتر به آن تمایل داشته باشد.





