مدلهای زبانی بزرگ اکنون میتوانند با دقتی چشمگیر، نتایج آموزشی و روانشناختی را از روی انشاهای دوران کودکی پیشبینی کنند
هوش مصنوعی در پی ردپای بزرگسالی در انشاهای کودکی
 سید محمدجواد فیاض
سید محمدجواد فیاض- ۱۷ مرداد ۱۴۰۴
مدلهای زبانی بزرگ، بهعنوان سامانههای پیشرفته هوش مصنوعی برای تحلیل و تولید متن در سالهای اخیر با محبوبیت و همهگیری و روند توسعه گستردهای همراه شدهاند.
از زمان عرضه پلتفرم مکالمهمحور ChatGPT که بر نسخههای مختلف مدلی به نام GPT تکیه دارد، این ابزارها نهتنها به استفاده روزمره افراد در سراسر جهان راه یافتهاند، بلکه وارد محیطهای حرفهای و پژوهشی نیز شدهاند.
جستوجوی آینده در گذشته
به گزارش Phys.org؛ «توبیاس ولفرام» (Tobias Wolfram) پژوهشگر ژنومیک اجتماعی یا جامعهژنتیک (Sociogenomics) دانشگاه «بیلهفلد» (Bielefeld)، اخیرا مطالعهای انجام دادهاست تا ارزیابی کند LLMها تا چه حد میتوانند با تحلیل انشاهایی که افراد در دوران کودکی نوشتهاند، نتایج و پیامدهای آموزشی و روانشناختی آنها را پیشبینی کنند. یافتههای وی که در نشریه Communications Psychology منتشر شده، نشان میدهد برخی مدلهای محاسباتی میتوانند این پیامدها و نتایج را با دقتی همتراز با ارزیابی معلمان و حتی بهمراتب بهتر از دادههای ژنتیکی پیشبینی کنند.
به گفته ولفرام؛ دهها پیش، هزاران شرکتکننده طی چند دهه به طور گسترده موردمطالعه قرار گرفتند و نتیجه آن ایجاد یک پایگاهداده حاوی اطلاعات آموزشی و روانشناختی گروه بزرگی از متولدین دهه ۱۹۵۰ از جمله متن انشاهای آنها بود. با خواندن این متنها فوراً متوجه میشوید که چه تنوع شگفتانگیزی در پیچیدگی، سطح بیان، طول، گستره موضوع و رعایت دستور زبان و املای درست وجود دارد. برای یک ناظر انسانی، این تفاوتها بلافاصله آشکار میشود، اما چطور میتوان آنها را به طور کمی سنجید؟ این تفاوتها چه معنایی برای زندگی افراد دارند؟ آیا میتوانند پیشبینیکننده شاخصهای مهمی مثل توانایی شناختی یا سطح تحصیلات باشند؟

روش شناسی
رویکرد اصلی ولفرام استفاده از یک مدل زبانی بزرگ برای تحلیل انشاهای به طور متوسط حدود ۲۵۰ کلمهای بود که کودکان در سن ۱۱ سالگی نوشته بودند. به گفته ولفرام با استفاده از مدل، متن هر انشا به یک نمایه عددی پیچیده؛ معروف به «بردار نهفته متن» (text embedding) تبدیل شده که معنا و سبک هر متن را در بیش از ۱۵۰۰ بُعد مختلف ثبت میکند. همچنین بیش از ۵۰۰ شاخص دیگر نیز استخراج شد که مواردی مانند تنوع واژگانی، پیچیدگی جملات، خوانایی متن و حتی تعداد خطاهای دستوری را میسنجید. پس از استخراج و تبدیل دادهها، ولفرام از یک مدل یادگیری ماشین گروهی (Ensemble) موسوم به «سوپرلِرنر» (SuperLearner) برای آموزش بر روی داده استفاده کرد تا بر اساس این ویژگیها پیشبینیهای لازم را انجام دهد.
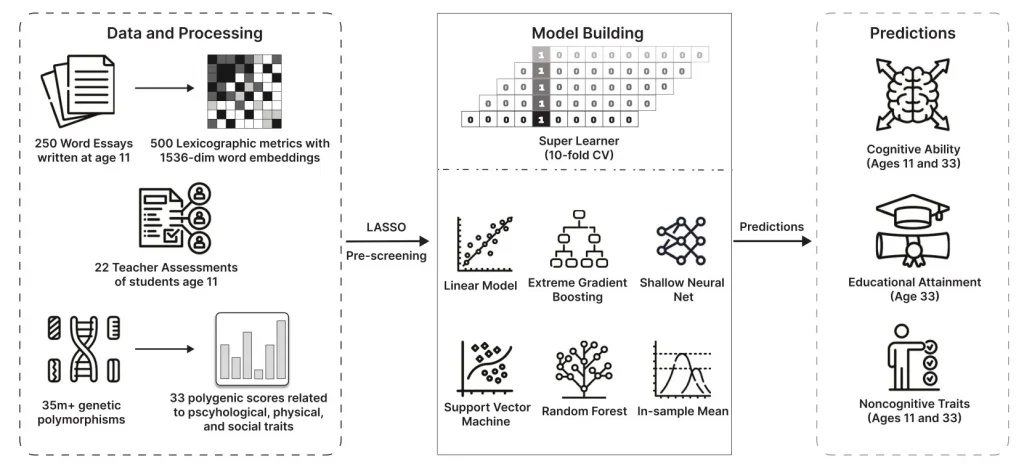
Credit: Tobias Wolfram. (Communications Psychology, Springer’s Nature, 2025)
به گفته ولفرام میتوان این مدل را مانند یک مدل مادر در نظر گرفت که پیشبینیهای چند الگوریتم مختلف مانند جنگل تصادفی (Random Forest)، شبکههای عصبی و ماشین بردار پشتیبان (SVM) را به شکلی هوشمندانه ترکیب میکند تا دقیقترین پیشبینی نهایی ممکن را ارائه دهد. برای ارزیابی عملکرد مدلها نیز از روش اعتبارسنجی متقابل دهتایی (10-fold cross-validation) استفاده شد که در آن مدل روی بخشی از دادهها آموزش میبیند و سپس روی بخش دیگری از دادهها که هرگز ندیده، آزمایش میشود.
سنجش عملکرد
برای سنجش توان پیشبینی مدلها در زمینه پیامدهای آموزشی و روانشناختی، ولفرام عمدتاً به معیاری به نام ضریب تعیین نگهدارنده پیشبینی (predictive holdout R²) تکیه کرد. این شاخص بیان میکند که مدل در دادههای جدید چه میزان از تغییرات یک پیامد (مثلاً توانایی شناختی فرد) در مقایسه با حالتی که فقط یک مقدار میانگین حدس زده شود را میتواند توضیح دهد. بهعنوانمثال، امتیاز ۰.۶ در این شاخص نشان میدهد که مدل قادر است ۶۰درصد از واریانس موجود را توضیح دهد. با این رویکرد، ولفرام توانست قدرت واقعی پیشبینی مدل را ارزیابی کند و نه صرفاً توانایی آن در خلاصهکردن دادههای آموزشی.
یک معیار طبیعی برای مقایسه عملکرد مدل، مجموعه ارزیابیهای نسبتاً دقیق معلمان از تمام شرکتکنندگان بود که همزمان با نوشتن انشاها انجام شده بود. به گفته ولفرام: «واقعاً شگفتانگیز است که همین انشاهای بسیار کوتاه چه میزان تغییرپذیری در توانایی شناختی و سطح تحصیلات را میتوانند پیشبینی کنند. آنها تقریباً همسطح ارزیابی یک متخصص آموزشی هستند که اغلب این کودکان را سالها میشناخت و باز هم یادآوری میکنم این انشاها به طور متوسط فقط ۲۵۰ کلمه و در سن ۱۱ سالگی نوشته شده بودند.»

بهطورکلی، یافتههای این پژوهش اخیر نشان میدهد که مدلهای زبانی بزرگ و سایر مدلهای پیشرفته یادگیری ماشین پتانسیل بالایی برای انجام پیشبینیهای دقیق بر اساس دادههای متنی دارند. این نتایج همچنین بر ارزش متون غنی؛ مانند انشاها و نوشتههای شخصی تأکید میکند و نشان میدهد که میتوان از آنها برای استخراج اطلاعات مهم درباره نویسنده استفاده کرد.
با اینکه تحلیلهای اصلی نسبتاً ساده بودند؛ اما انتشار این پروژه تقریباً پنج سال طول کشید. کل رویکرد مقاله کاملاً مبتنی بر راهکار سنتی یادگیری ماشین و علم داده؛ یعنی داشتن مجموعهای از نمونهها برای آموزش مدل و سپس اعتبارسنجی آن بر دادههایی که در فرایند آموزش دخیل نیستند، بود. به گفته ولفرام هرچند تمام کار بر اساس متون دیجیتالشده انجام شد، اما باتوجهبه مدلهای چندوجهی قدرتمندی که امروز وجود دارد، انتظار میرود گنجاندن عواملی مانند دستخط نیز بتواند اطلاعات و الگوهای بیشتری را آشکار کند. شایانذکر است که در زمان انجام این مطالعه، LLMها و دیگر مدلهای یادگیری ماشین به پیشرفت و دقت امروز نرسیده بودند. باتوجهبه سرعت شگفتانگیز توسعه این مدلها، انجام مطالعات مشابه با استفاده از مدلهای محاسباتی جدیدتر میتواند پیشبینیهای حتی دقیقتری به دست دهد.