
کاهش ایمان به مدلهای زبانی شبهخدایی
نقطه اوج مدلهای زبانی بزرگ؟
 سید محمدجواد فیاض
سید محمدجواد فیاض- ۱۲ مهر ۱۴۰۴
وقتی فعالان حوزه فناوری درباره کندی پیشرفت مدلهای زبانی بزرگ صحبت میکنند، اغلب آن را با صنعت گوشیهای هوشمند مقایسه میکنند.
روزهای نخست ChatGPT همانقدر انقلابی به نظر میرسید که معرفی نخستین آیفون اپل در سال ۲۰۰۷. اما حالا پیشرفتهای تازه در مرز هوش مصنوعی بیشتر شبیه ارتقای جزئی یک گوشی جدید است تا یک تحول واقعی. آخرین نسخه OpenAI یعنی GPT-5 نمونه بارزی از این وضعیت است؛ همانقدر بیهیجان پذیرفته شد که معرفی آیفون ۱۷ در ۹ سپتامبر سال جاری میلادی.
کاهش سرعت پیشرفت در حوزه هوش مصنوعی مولد یک نشانه است که LLMها چندان مطابق با تبلیغات و انتظارات عمل نکردهاند. اما شاید نشانه مهمتر، رشد جایگزینهای کوچکتر و چابکتری است که در دنیای کسبوکار محبوبیت یافتهاند. بسیاری از شرکتها ترجیح میدهند مدلهای سفارشی داشته باشند که بتوانند دقیقاً برای نیازهای خاصشان تنظیم کنند. این مدلها که «مدلهای زبانی کوچک» (SLM) نامیده میشوند، بسیار ارزانتر از LLMهای همهمنظوره هستند؛ آن هم در حالی که هوش شبهخدایی (God-like) این مدلهای غولپیکر اغلب غیرضروری جلوه میکند. همانطور که «دیوید کاکس» (David Cox)، مدیر تحقیقات مدلهای هوش مصنوعی در IBM میگوید: «چتبات واحد منابع انسانی شما لازم نیست فیزیک پیشرفته بلد باشد.»
علاوه بر اینکه اجرای SLMها روی سیستمهای داخلی شرکتها به همان سادگی اجرای آنها روی خدمات ابری است، این مدلها برای عاملهای هوش مصنوعی (AI agents) که وظایف کاری را در کنار یا به جای انسانها انجام میدهند نیز مفیدتر به نظر میرسند. اندازه کوچکترشان باعث میشود برای استفاده در گوشیهای هوشمند، خودروهای خودران، رباتها و دیگر دستگاههایی که کارایی انرژی و سرعت در آنها حیاتی است، مناسبتر باشند. اگر این مدلها به اندازه کافی قابلاعتماد شوند، میتوانند تصمیم اپل و دیگر تولیدکنندگان دستگاهها را در عدم سرمایهگذاری سنگین روی LLMهای ابری توجیه کنند.

البته تعریف دقیقی از مرز میان مدلهای کوچک و بزرگ وجود ندارد. تفاوت اصلی در تعداد پارامترها است؛ یعنی همان تنظیمات عددی در مغز یک مدل که به درک دادهها کمک میکند. LLMها صدها میلیارد پارامتر دارند و در مقابل، SLMها ممکن است با ۴۰ میلیارد یا کمتر آموزش ببینند و در نمونههای بسیار کوچک حتی کمتر از یک میلیارد پارامتر دارند.
پیشرفت در شیوههای آموزش SLMها باعث شده توانایی آنها به LLMها نزدیک شود. این روزها مدلهای کوچک بیشتر توسط خود مدلهای بزرگتر آموزش داده میشوند، نه اینکه خودشان کل وب را بگردند و یاد بگیرند. شرکت Artificial Analysis (فعال در ارزیابی مدلها) گزارش داده که در مجموعهای از آزمایشها، مدلی ۹ میلیارد پارامتری به نام Nvidia Nemotron Nano عملکردی بهتر از مدلLlama که ۴۰ برابر بزرگتر است داشته است. چنین سبقتگیریهایی حالا به روندی معمول بدل شده است. به گفته «موهیت آگراوال» (Mohit Agrawal) از شرکت تحقیقاتی Counterpoint: «مدلهای کوچک امروزی بسیار توانمندتر از مدلهای بزرگ سال گذشته هستند.»
عملکرد بهتر باعث شده مشتریان سازمانی به SLMها روی بیاورند. شرکت تحقیقاتی Gartner میگوید نقصهای شناختهشده LLMها مثل «توهم» (hallucination) موجب خستگی کاربران شده است. در عوض، کسبوکارها به دنبال مدلهای تخصصی هستند که با دادههای صنعت خودشان بهینهسازی شده باشند. پیشبینی میشود امسال تقاضای سازمانی برای این مدلهای تخصصی دو برابر سریعتر از LLMها رشد کند. در بلندمدت، گارتنر انتظار دارد که بسیاری از این مدلهای سفارشی توسط خود شرکتها توسعه داده شوند.
یکی دیگر از دلایل محبوبیت SLMها، دلایل اقتصادی است. شرکتها از رویکرد «هر چه هزینهاش شد مهم نیست» در روزهای نخست هوش مصنوعی مولد فاصله گرفته و حالا بیشتر به نرخ بازگشت سرمایه توجه میکنند. هرچند ممکن است همچنان از LLMها برای وظایف مهم استفاده کنند، اما میدانند که برای کارهای سادهتر میتوانند از SLMها بهره ببرند. یکی از سرمایهگذاران برجسته حوزه فناوری انی موضوع را با یک مثال ساده توضیح میدهد: «شاید برای پرواز از سانفرانسیسکو به پکن نیاز به یک بوئینگ ۷۷۷ داشته باشید، اما برای پرواز از سانفرانسیسکو به لسآنجلس نه. استفاده از سنگینترین مدلها برای همه مسائل منطقی نیست.»
برای توضیح جنبه اقتصادی موضوع، کاکس به محصولی به نام Docling اشاره میکند که در IBM توسعه یافته است. این ابزار فایلهای PDF مثل رسیدها را به دادههای قابل ذخیرهسازی تبدیل میکند.Docling روی یک مدل بسیار کوچک با حدود ۲۵۰ میلیون پارامتر اجرا میشود و به گفته کامش این ابزار مفید است، اما اگر قرار بود روی یک LLM اجرا شود، از نظر هزینه بهصرفه نبود.
مدلهای کوچک همچنین میتوانند روی تراشههای ارزانتر اجرا شوند. کوچکترین مدلها حتی میتوانند از واحد پردازش مرکزی (CPU) استفاده کنند، نه واحد پردازش گرافیکی (GPU) که شرکت انویدیا را به باارزشترین کمپانی جهان تبدیل کرده است. این نکته میتواند یک مزیت فروش بزرگ باشد، چرا که به گفته کاکس GPUها مثل فراریهای وسواسی هستند که همیشه در تعمیرگاه به سر میبرند.
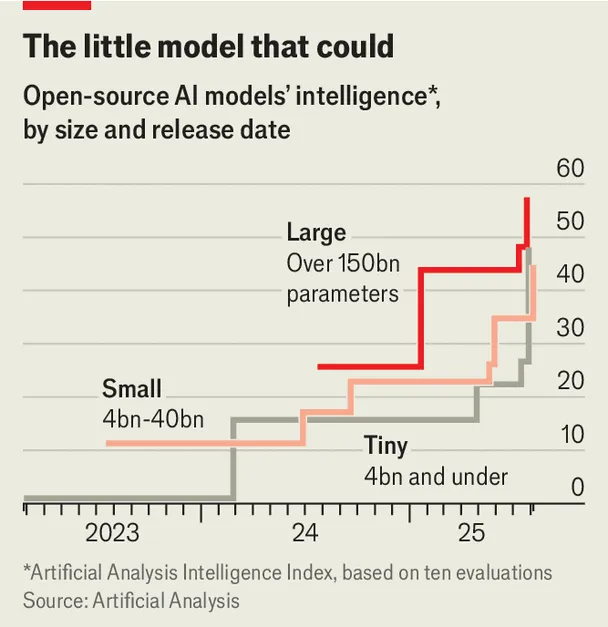
با افزایش استفاده شرکتها از عاملهای هوش مصنوعی، جذابیت SLMها باز هم بیشتر خواهد شد. مقالهای کمتر دیدهشده که در ماه ژوئن سال جاری میلادی توسط بخش تحقیقاتی انویدیا منتشر شد، به صراحت اعلام میکند: «مدلهای کوچک، نه بزرگ، آینده هوش مصنوعی عاملمحور هستند.» این مقاله یادآوری میکند که در حال حاضر بیشتر عاملهای هوش مصنوعی توسط LLMها و در بستر سرویسهای ابری پشتیبانی میشوند. سرمایهگذاریهای عظیمی که روی زیرساخت ابری هوش مصنوعی انجام میشود، نشان میدهد بازار فرض میکند که LLMها همچنان موتور اصلی این عاملها باقی خواهند ماند. اما مقاله این فرض را به چالش میکشد و استدلال میکند SLMها به اندازه کافی قدرتمند هستند تا وظایف عاملمحور را انجام دهند و از نظر اقتصادی بسیار بهصرفهترند. برای نمونه، یک مدل با ۷ میلیارد پارامتر میتواند ۱۰ تا ۳۰ برابر ارزانتر از مدلی باشد که تا ۲۵ برابر بزرگتر است. در این سناریو، SLMها میتوانند رویکردی شبیه لگو را در توسعه عاملها وارد کنند؛ یعنی شرکتها به جای یک هوش واحد عظیم، مجموعهای از مدلهای کوچک و تخصصی را کنار هم بچینند.
البته انویدیا اذعان میکند این مقاله بیانگر استراتژی رسمی شرکت نیست. به گفته «کاری بریسکی» (Kari Briski)، یکی از مدیران ارشد انویدیا، مشتریان تجاری به مدلهایی «در همه اندازهها و شکلها» نیاز دارند. بریسکی عنوان میکند مدلهای بزرگ برای سختترین وظایف همچنان کارآمدتر از مدلهای کوچک هستند. افزون بر این، بهبود مستمر LLMها نیز اهمیت دارد، چون رفتهرفته به معلمهای بهتری برای آموزش SLMها تبدیل میشوند.
چه SLMها در نهایت جایگزین LLMها شوند یا نه؛ آنچه مسلم است افزایش تنوع است. LLMهای همهچیزدان همچنان در برنامههای مصرفی مانند ChatGPT نقش مهمی خواهند داشت. با این حال حتی OpenAI نیز تمرکز خود را تغییر داده است. GPT-5 شامل مدلهایی با اندازهها و تواناییهای مختلف است که بسته به پیچیدگی وظیفه، از آنها استفاده میکند.
با توانمندتر شدن SLMها، ممکن است اعتبار «هوش مصنوعی دروندستگاهی» (on-device AI) نیز بیشتر شود. سال گذشته اپل هنگام معرفی بسته هوش مصنوعی خود به نام Apple Intelligence سرمایهگذاران را ناامید کرد، چرا که عملکرد ضعیفی داشت. سهام این شرکت در ۹ سپتامبر سال جاری میلادی، همزمان با معرفی آیفون ۱۷، سقوط کرد، بخشی از آن به این دلیل بود که خبری از پیشرفت Apple Intelligence نبود. اما به گفته آگراوال، رویکرد اپل؛ یعنی اجرای برخی وظایف روی خود آیفون با SLMها و سپردن کارهای سختتر به فضای ابری ممکن است شکلی از آینده باشد و میافزاید: «قدرت اپل آنقدر زیاد است که حتی اگر در مراحل اولیه مسابقه هوش مصنوعی از قافله عقب مانده باشد، همیشه میتواند سوار کشتی بعدی شود.»
در حال حاضر بیشتر توجهها همچنان بر LLMهاست. غولهای ابری مانند مایکروسافت و گوگل مدلهای بسیار کوچک هم ساختهاند، اما باور به ماندگاری وضع موجود، هزینههای سرسامآوری را که آنها برای ساخت مراکز داده و آموزش بزرگترین مدلها خرج میکنند، توجیه کرده است. با این حال ممکن است این رویکرد کوتاهنگرانه باشد. با توجه به مزایای نسبی SLMها، راهبرد محتاطانه اپل شاید در بلندمدت منطقیتر از آن چیزی باشد که امروز به نظر میرسد.
گزارش حاضر در نسخه 13September 2025نشریه The Economist منتشر شده است.





